Scaling Test-Time Compute to Achieve IOI Gold Medal with Open-Weight Models
Abstract: Competitive programming has become a rigorous benchmark for evaluating the reasoning and problem-solving capabilities of LLMs. The International Olympiad in Informatics (IOI) stands out as one of the most prestigious annual competitions in competitive programming and has become a key benchmark for comparing human and AI-level programming ability. While several proprietary models have been claimed to achieve gold medal-level performance at the IOI, often with undisclosed methods, achieving comparable results with open-weight models remains a significant challenge. In this paper, we present \gencluster, a scalable and reproducible test-time compute framework that attains IOI gold-level performance using open-weight models. It combines large-scale generation, behavioral clustering, ranking, and a round-robin submission strategy to efficiently explore diverse solution spaces under limited validation budgets. Our experiments show that the performance of our proposed approach scales consistently with available compute, narrowing the gap between open and closed systems. Notably, we will show that GenCluster can achieve a gold medal at IOI 2025 for the first time with an open-weight model gpt-oss-120b, setting a new benchmark for transparent and reproducible evaluation of reasoning in LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching an AI to solve very hard programming competition problems (like those at the International Olympiad in Informatics, IOI). The authors built a system called GenCluster that helps an open-source AI model reach “gold medal” level at IOI by letting it try many ideas, group similar solutions, and smartly pick which ones to submit—while following the same strict rules humans face in the contest.
Key Objectives
- Can an open-weight (publicly available) AI reach IOI gold medal performance?
- How do we choose the best solutions when we’re only allowed a limited number of submissions per problem?
- Does letting the AI use more compute at test time (think longer and try more ideas) steadily improve results in a reliable way?
- Which picking and ranking strategies work best for tough coding problems?
How They Did It (Methods)
Think of the process like coaching a big team of players and choosing the best few to compete.
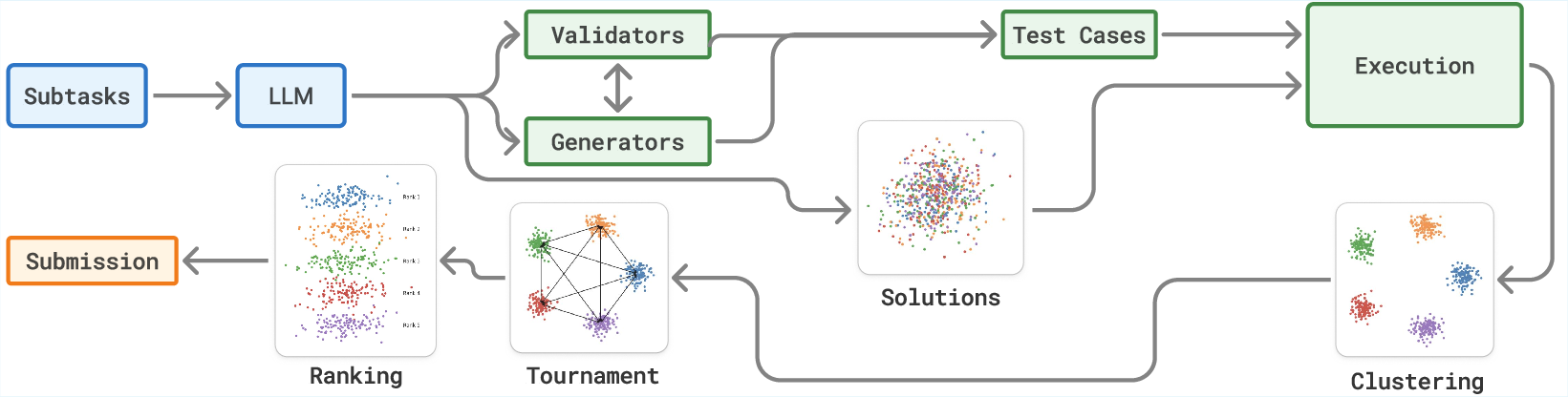
Step 1: Generate many solutions in parallel
The AI writes a lot of different code answers for each subtask (a sub-problem inside an IOI problem). Because each solution is independent, this can be done in parallel (like many teammates practicing at once). Broken or non-compiling code is filtered out.
Step 2: Behavioral clustering (group by how they act)
To avoid checking every single solution in detail, the system groups solutions that behave the same on test inputs.
- The AI first creates many test inputs (like practice questions) and “validators” (referees that check the inputs are valid for the subtask).
- If most validators agree an input is valid, it’s kept.
- All candidate solutions run on these inputs. Solutions that produce the same outputs are grouped into a “cluster.”
- Clusters with errors are removed. Now you have fewer groups that each represent a style of behavior.
Analogy: If you give everyone the same set of practice problems, you can group the students who consistently get the same answers—this lets you compare groups instead of comparing every student individually.
Step 3: Tournament ranking (pick the strongest clusters)
You can’t submit everything, so you need a smart ranking.
- From each cluster, pick a representative solution (the one with the longest “thinking trace,” which often means it reasoned more deeply).
- Run many pairwise “matches” (like a sports tournament) where an LLM judge compares two representatives and picks which looks better.
- Count wins. Clusters with more wins are ranked higher.
- Randomize the order in comparisons to reduce bias.
Analogy: It’s like a round-robin sports league where teams play several games; teams with more wins are seeded higher.
Step 4: Round-robin submission (play within the contest rules)
IOI allows a maximum of 50 submissions per problem. The system:
- Starts with the hardest subtasks (usually the final ones).
- Submits one solution at a time, cycling through the top-ranked clusters.
- Inside a cluster, it starts with the solution that has the longest reasoning trace.
- Once a subtask reaches its maximum possible score, it moves on.
Analogy: You have limited “shots on goal,” so you rotate your best players from the top teams to maximize the chance of scoring without wasting attempts.
What is “test-time compute”?
This means giving the model more resources while it’s answering (not during training). Think of it as “letting the AI think longer and explore more ideas,” then using a smart process to pick the best ones.
Main Findings and Why They’re Important
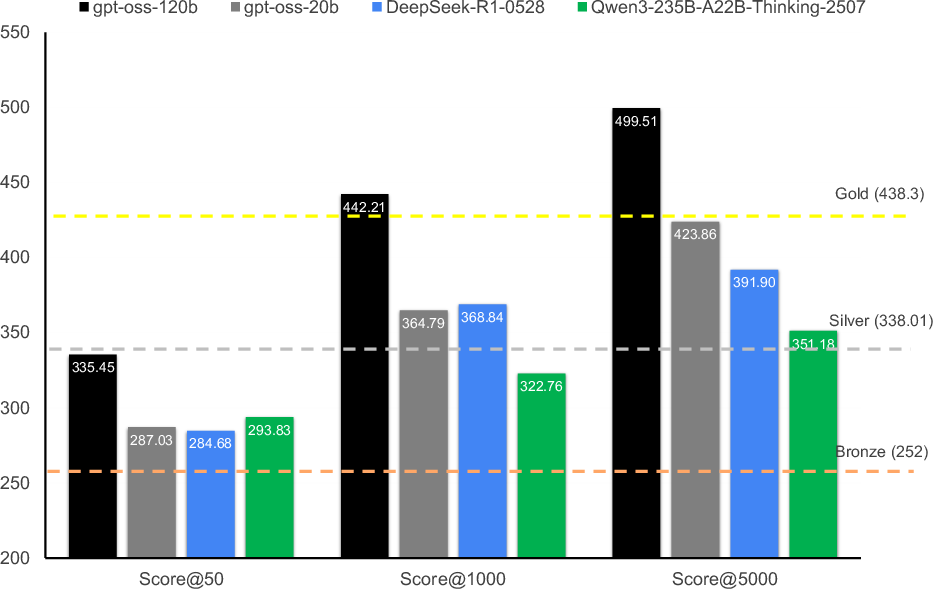
- Gold medal with open weights: Using GenCluster, the open-weight model gpt-oss-120b reached gold-level performance on IOI 2025 while following the 50-submission limit. This is the first reported gold with a fully open-weight setup.
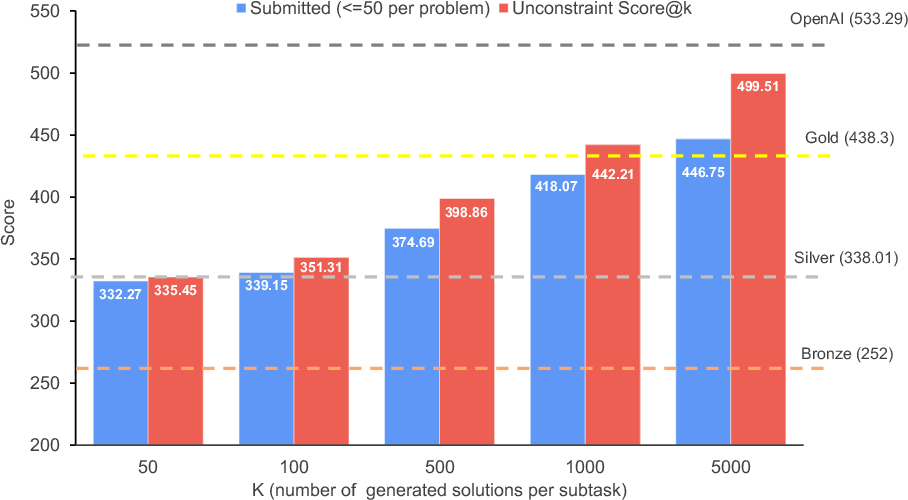
- More compute helps consistently: Generating more candidate solutions per subtask steadily improved scores. With 5000 generations, the submitted score rose to about 447 (out of 600), crossing the gold threshold.
- Smart selection beats simple tricks: Methods like “choose the longest reasoning” or “random pick” did much worse. GenCluster’s clustering plus tournament ranking clearly outperformed alternatives.
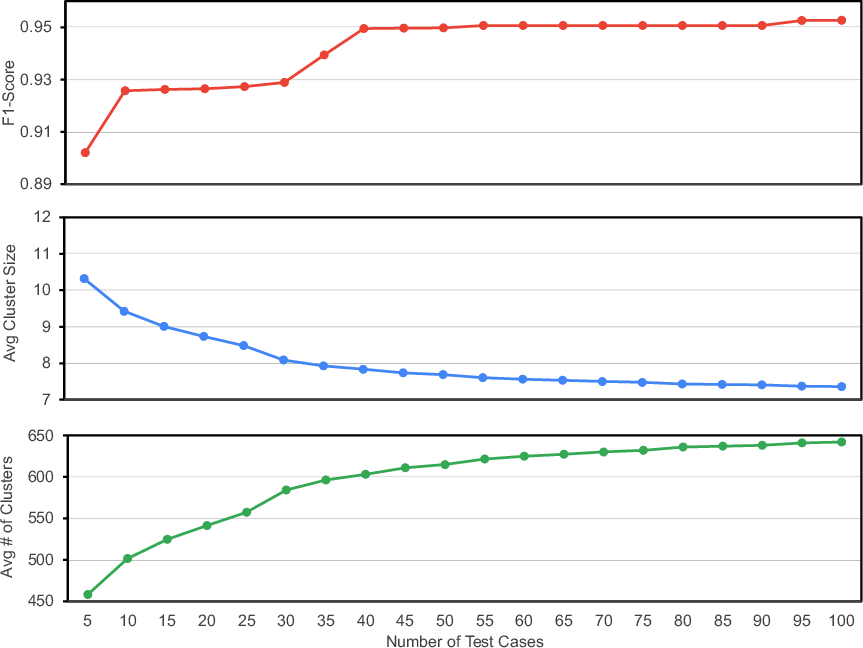
- Better tests make cleaner clusters: Creating more valid test inputs improved cluster purity (good solutions grouped together, bad ones grouped elsewhere). However, it also made more, smaller clusters—so ranking well becomes more important as you scale up.
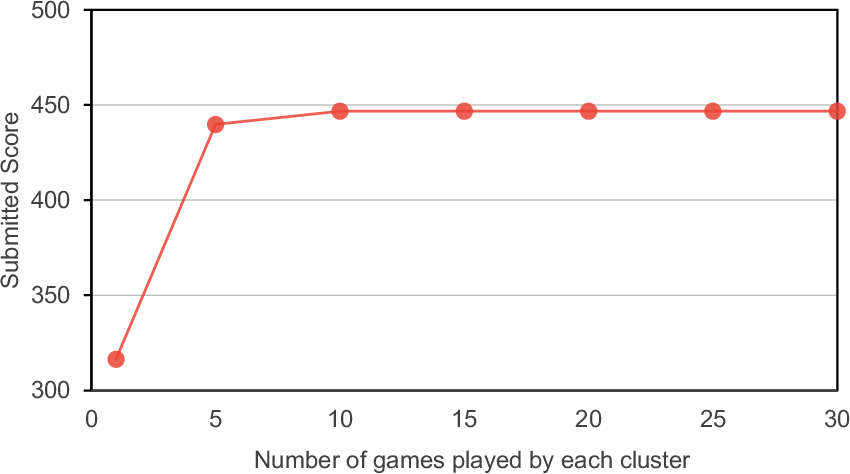
- Enough tournament rounds matter: Running more matchups between clusters improves rankings but saturates around 10 games per cluster, suggesting there’s a sweet spot for efficiency.
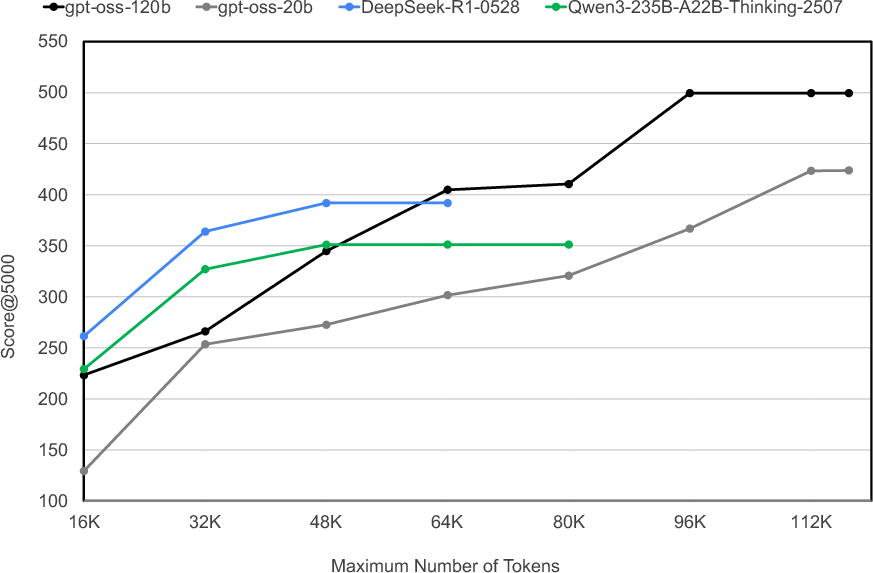
- Longer reasoning often helps: Models that can produce longer, more detailed reasoning traces tended to perform better on tough problems when given larger generation budgets.
These results matter because they show a transparent, reproducible way to get very strong performance on elite programming tasks without relying on closed, proprietary systems.
Implications and Impact
- Transparent benchmarking: GenCluster offers a clear, reproducible method to evaluate and improve AI reasoning on real, hard tasks like IOI.
- Narrowing the open vs. closed gap: It shows that open-weight models can approach, and potentially surpass, proprietary systems when given smart test-time strategies.
- Practical contest strategy: The round-robin submission and tournament ranking are directly useful for any setting with limited submissions or evaluations.
- Generalizable approach: The idea—generate many candidates, group by behavior, rank with structured comparisons, submit strategically—could be applied to other problem-solving areas (math competitions, algorithm design, or even real-world planning with constraints).
- Path to “beyond gold”: Since performance keeps improving with scale, further advances in ranking, judging, and test generation may push open models beyond gold-level results.
In short, GenCluster is like building a disciplined team around an AI: you let it try lots of ideas, organize them smartly, have them compete fairly, and then submit the best performers. This teamwork approach turns raw computational power into reliable contest-winning performance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work.
- Compute transparency and cost–performance: No disclosure of hardware, GPU-hours, wall-clock time, memory footprint, or energy use per problem; no Pareto curves for score vs compute to assess compute-optimality.
- Contest-time realism: The method enforces the 50-submission cap but not the real IOI time budget; no analysis of what is achievable within standard contest time (e.g., 5 hours) under practical cluster throughput.
- Generalization beyond a single contest: Evaluation is limited to IOI 2025; no cross-year IOI (e.g., 2018–2024), ICPC, or Codeforces live-contest tests to assess robustness to distribution shift.
- Data contamination safeguards: No decontamination audit for gpt-oss-120b or others; unclear whether IOI tasks, graders, or similar problems appear in training data; no leakage checks or ablations with decontaminated models.
- External validity of LLM-generated tests/validators: LLM-built generators/validators are not verified against formal specs; no coverage metrics, mutation/fuzzing-based audits, or ground-truth validator comparisons.
- Validator threshold choice: The 75% validator-agreement threshold is heuristic; no sensitivity analysis, adaptive thresholding, or empirical error profile (false accept/reject) of generated validators.
- Clustering by exact output equality: No handling of semantic equivalence, nondeterminism, or interactive protocols; no exploration of alternative similarity metrics (e.g., graded distances, behavioral embeddings).
- Test-set size vs end-to-end score: While cluster purity is reported, the paper does not quantify how increasing test cases translates to submitted score gains and compute overhead; no adaptive sampling strategy.
- Ranking methodology: Tournament ranking lacks theoretical grounding and baselines like Bradley–Terry/Plackett–Luce/Elo; no active-dueling or sample-efficient match scheduling; no calibration of judge uncertainty.
- LLM-as-a-judge bias: Only position bias is mitigated; no tests for verbosity bias, style bias, self-judging bias (same model judging its own outputs), or cross-model/human adjudication for calibration.
- Choice of cluster representative: “Longest reasoning” is the only non-random proxy evaluated; no comparisons to alternatives (e.g., intra-cluster self-consistency, static analysis quality, coverage, runtime stability).
- Submission policy design: The round-robin, hardest-to-easiest policy is not ablated; no bandit-style budget allocation, dynamic stopping rules, or per-subtask budgeting based on predicted payoff.
- Subtask structure exploitation: Subtasks are treated independently; no reuse of candidate code across related subtasks, hierarchical solving, or joint optimization to amortize search.
- Language diversity: Only C++ is used; no study of language ensembles (e.g., C++/Python/Java) to boost diversity, compile success, or runtime reliability; no compiler/flag sensitivity analysis.
- Failure-mode analysis: Absent breakdowns of TLE/MLE/RE/WA by cause; no systematic error taxonomy or diagnostics guiding targeted generation/ranking improvements.
- Scaling beyond 5k generations: No exploration of asymptotic behavior, diminishing returns, or inference scaling laws; unclear if more generations close the constrained–unconstrained gap.
- Throughput engineering: Missing details on distributed scheduling, batching, queuing, and I/O bottlenecks; no guidelines for achieving target latency/throughput in practice.
- Grader availability and fidelity: Assumes access to official graders; no treatment of settings without graders or with limited feedback; no study of feedback granularity mismatches vs real contest environments.
- Interactive and output-only tasks: Handling of interactive protocols, judge I/O, and stateful behavior is unspecified; unclear how clustering/validators extend to interaction-heavy tasks.
- Sandbox and determinism: No documentation of sandbox security, reproducibility across OS/container/compilers, or mitigation of undefined behavior and nondeterministic runs.
- Reproducibility artifacts: Exact prompts (solution/test-generator/validator/judge), seeds, runner scripts, and environment configs are not released in-text; figures reference prompts but lack verbatim text.
- Environmental impact: No accounting of carbon footprint; no discussion of sustainability trade-offs vs score improvements.
- Training/fine-tuning leverage: No experiments on light domain fine-tuning, preference optimization for judges, or verifier training; unclear how much headroom exists beyond TTC.
- Alternative ranking signals: No integration of fuzzing coverage, static analysis warnings, dynamic invariants, contract checks, or formal verification to augment the judge.
- Majority-vote failure modes: Majority-based heuristics underperform, but the paper does not analyze why or propose noise-aware/self-consistency variants robust to low correctness base rates.
- Cross-model ensembles: No study of multi-model sampling (e.g., gpt-oss + Qwen + DeepSeek) to increase behavioral diversity and improve clustering/ranking.
- Token-length policy and budgeting: No adaptive per-sample stopping or joint optimization of “number of samples vs tokens per sample” under fixed compute; no cost-aware decoding strategies.
- Overfitting to generated test distribution: Risk that candidates optimize to LLM-generated tests/validators rather than true grader distribution; no adversarial/independent holdout test audit.
- Statistical uncertainty: Limited runs (e.g., single run at K=5000) and no confidence intervals or significance tests for key comparisons and ablations.
- Iterative repair and self-editing: Generation is one-shot per candidate; no iterative program repair, constraint-guided patching, or feedback-driven editing within the submission budget.
- Strong TTC baselines: Comparisons omit advanced best-of-N pipelines (e.g., synthesis+repair+fuzzing loops, learned verifiers, formal solvers) that could contextualize the absolute gains of GenCluster.
Practical Applications
Overview
This paper introduces GenCluster, a scalable and reproducible test-time compute (TTC) framework that boosts open‑weight LLMs on complex code-generation tasks by:
- Parallel candidate generation (best‑of‑N sampling).
- LLM-generated test input creators and validators.
- Behavioral clustering using program outputs.
- LLM-as-judge pairwise tournaments to rank clusters.
- Round‑robin submission to optimize under strict evaluation budgets.
Below are practical applications derived from these methods, organized by deployment horizon.
Immediate Applications
The following applications can be implemented with current open‑weight models, modest engineering, and standard compute infrastructure.
- Software Engineering — AI “Best‑of‑N” Code Synthesis Plugin for CI/CD
- Use case: Generate many candidate implementations for tickets (functions, modules), auto-compile, run against LLM-generated tests/validators, cluster by behavior, and submit top-ranked candidates for human review.
- Tools/products/workflows:
- “GenCluster for Code” CI action (GitHub/GitLab).
- Sandboxed compilation/execution service with output hashing and clustering.
- Tournament ranking microservice (LLM-as-judge, position randomization).
- Assumptions/dependencies: Reliable sandboxing, sufficient compute (GPU/CPU), access to graders or unit tests; guardrails for LLM-as-judge bias.
- Software Maintenance — Automated Patch Candidate Generator with Behavioral Clustering
- Use case: For failing tests or bug reports, generate diverse patches, validate across randomized input generators and multiple validators, rank via tournaments, and propose the best patch.
- Sector: Software; DevTools.
- Dependencies: High-fidelity test generators; secure execution; change-impact analysis.
- Testing and Quality Assurance — LLM-generated Fuzzing and Validator Suites
- Use case: Prompt models to produce randomized test inputs and independent validators, accept only inputs validated by a supermajority, then use them to stress programs.
- Sector: Software QA; Security.
- Products: “Validator Factory” for API/services; differential testing harnesses.
- Assumptions: Validator correctness and diversity; deduplication; coverage measurement.
- Education — Autograding and Tutoring for Algorithmic Programming
- Use case: For assignments/problems, auto-generate validated test sets, cluster student submissions by behavior, tournament rank exemplars, and provide targeted feedback.
- Sector: Education; CS courses; coding bootcamps.
- Workflow: LMS plugin (Moodle/Canvas); grader integration; per‑subtask scoring.
- Assumptions: Clear constraints; fair assessments; academic integrity checks.
- Competitive Programming Training — Coach and Practice Environment
- Use case: Simulate contest constraints (submission caps), generate solution candidates, and expose students to ranking/tournament workflows; benchmark against IOI-like subtasks.
- Sector: Education; eSports in programming.
- Tools: “Contest Simulator” with round‑robin submission strategy.
- Dependencies: Accurate task porting; time/memory limits; compile/runtime safety.
- Research Benchmarking — Reproducible TTC Evaluations for Reasoning LLMs
- Use case: Open-weight leaderboards that report compute budgets (K generations, token limits), clustering metrics (purity, top‑K inclusion), and constrained vs. unconstrained scores.
- Sector: Academia; ML Ops.
- Products: Public benchmarking harness; result cards with compute disclosure.
- Assumptions: Community norms for compute reporting; dataset licensing.
- Data Science/MLOps — Multi-candidate Pipeline/Notebook Generation with Validator Tests
- Use case: Generate multiple ETL/model training pipelines; validate with metric checks (e.g., schema, accuracy thresholds), cluster by outputs/metrics, rank and suggest top candidates.
- Sector: Software; Data platforms.
- Dependencies: Domain-specific validators (metrics, drift checks); reproducible environments.
- Personal Developer Productivity — Local “Best‑of‑N” Script/Function Builder
- Use case: On laptops/workstations, generate multiple code snippets for utilities, run quick validators, and select the top cluster representative to paste into projects.
- Sector: Daily life; Indie dev.
- Assumptions: Smaller K due to limited compute; lighter validators; user supervision.
Long-Term Applications
These applications require further research, scaling, domain-specific safety cases, or policy/regulatory development.
- Safety-Critical Software Generation (Embedded/Medical/Automotive)
- Use case: Generate and select software for high-stakes systems using rigorous validators and formal checks, cluster by behavior across scenario suites, and rank via robust judges.
- Sector: Healthcare; Automotive; Aerospace.
- Tools/products: TTC + formal verification integration; DO‑178C/IEC 62304 workflows.
- Assumptions/dependencies: Certified toolchains; formal methods; traceable validators; regulatory approvals; deterministic execution.
- Robotics and Autonomy — Multi-Plan Generation with Behavioral Clustering
- Use case: Produce many candidate motion/mission plans, simulate across randomized scenario generators and validators, cluster by emergent behavior, and rank plans via tournaments.
- Sector: Robotics; Industrial automation.
- Products: “PlanCluster” for robot task planning; sim‑to‑real validators.
- Assumptions: High-fidelity simulators; safety constraints; robust LLM-as-judge or reward models; handling position bias.
- Finance — Strategy/Policy Candidate Generation with Validator Risk Checks
- Use case: Generate trading/investment strategies, validate on diverse market scenarios and risk constraints, cluster by portfolio outcomes, and rank under regulatory limits.
- Sector: Finance.
- Tools: Risk-aware validators; backtest generators; tournament ranking with calibrated scores.
- Assumptions: Compliance and auditability; leakage controls; model risk governance.
- Energy and Operations Research — Schedule/Dispatch Optimization via TTC
- Use case: Generate many feasible schedules (grid dispatch, staff rostering), validate constraints, cluster by outcome metrics, and rank via tournaments under evaluation budgets.
- Sector: Energy; Logistics; Manufacturing.
- Products: “ScheduleCluster” optimizer; constraint-aware validator generators.
- Assumptions: Accurate constraints; scalable simulators; fairness across scenarios.
- Policy and Governance — Standards for TTC Transparency and Compute Disclosure
- Use case: Create guidelines for reporting inference compute, candidate pool sizes, ranking strategies, and safety checks in competitive benchmarks and procurement.
- Sector: Policy; Public sector; Standards bodies.
- Outputs: Benchmarking protocols; compute reporting standards; audit trails.
- Assumptions: Multi-stakeholder coordination; open benchmarks; independent auditing.
- TTC Orchestrator Platforms — Managed Services for Scalable Best‑of‑N Inference
- Use case: Offer cloud services that parallelize generation, run validators, cluster outputs, and perform tournaments with reproducible logs and cost controls.
- Sector: Cloud; DevTools.
- Products: “GenCluster Cloud” with GPU scheduling, token budget management, and secure sandboxes.
- Assumptions: Cost optimization; security for running untrusted code; SLAs.
- Robust Judging and Verifiers — Bias-Resistant LLM-as-Judge and Generative Verifiers
- Use case: Advance methods to reduce position/recency bias, calibrate scores, and combine LLM judges with reward models and formal checks for reliable ranking at scale.
- Sector: ML research; Evaluation.
- Assumptions: High-quality judge training; meta-evaluation datasets; adversarial testing.
- Agentic Systems — Multi-Plan Selection for Generalist AI Assistants
- Use case: Integrate GenCluster-style TTC into autonomous coding/DevOps agents: generate many plans/actions, validate via environment tests, cluster by outcomes, and select top candidates.
- Sector: Software; Robotics; General AI.
- Assumptions: Safe autonomy frameworks; robust environment simulators; cost-aware inference scaling.
Cross-Cutting Assumptions and Dependencies
- Compute availability and cost: GenCluster benefits from large candidate pools (K up to thousands) and long reasoning token limits; scaling requires GPUs and orchestration.
- Secure sandboxing: Running many candidate programs demands isolated, resource-limited environments to mitigate security risks.
- Validator quality: The efficacy of clustering and ranking hinges on diverse, correct test generators and independent validators; supermajority acceptance (e.g., 75%) is a practical heuristic but may need domain tuning.
- LLM-as-judge reliability: Tournament outcomes can be affected by position/recency bias; randomized ordering and multiple games (≥10) help but do not eliminate limitations.
- Domain graders: Availability of trusted graders (like IOI’s) or formal checks is crucial for high-stakes and regulated domains.
- Reproducibility/transparency: Public reporting of compute budgets, ranking methods, and constraints improves trust and comparability across systems.
Glossary
- behavioral clustering: Grouping candidate programs by similar behavior on generated tests to reduce and organize candidates. "behavioral clustering, ranking, and a round-robin submission strategy"
- Chain-of-Thought reasoning: An inference technique where models generate explicit intermediate reasoning steps to improve accuracy. "extended chain-of-thought reasoning"
- cluster purity: A measure of how well clustering separates correct from incorrect solutions (higher is better). "cluster purity (F1-score)"
- F1-score: The harmonic mean of precision and recall; used here to quantify clustering quality. "We evaluate cluster purity using the F1-score"
- generative verifiers: LLMs or generators used to judge or score candidate solutions for selection. "generative verifiers for scoring and selection"
- generation budgets: The number of candidate generations allotted per problem or subtask. "improves scores with increased compute and larger generation budgets"
- grader: The official program that executes and scores submissions under contest constraints. "the graders officially provided by IOI"
- LLM-as-a-judge: Using an LLM to compare and evaluate solutions directly. "the LLM-as-a-judge paradigm"
- LLM-based tournament: A ranking scheme where an LLM performs pairwise comparisons between cluster representatives. "rank clusters using an LLM-based tournament"
- majority voting: A selection heuristic that chooses the answer produced by most candidates. "majority voting can trivially identify the correct answer"
- open-weight models: Models whose weights are publicly available for use and replication. "using open-weight models"
- partial round-robin tournament: A competition format where each candidate plays a subset of others to estimate relative quality. "a partial round-robin tournament"
- recency bias: A judging bias where more recently seen items are favored. "To mitigate recency bias"
- reasoning length: The length of the model’s generated reasoning trace; used as a proxy for correctness. "ranked by their reasoning length"
- representative solution: The single solution chosen to represent a cluster during tournament comparisons. "the representative solution from each cluster"
- round-robin submission strategy: Cycling through ranked clusters to submit one solution at a time under a submission cap. "a round-robin submission strategy"
- Score@K: The best achievable score when selecting from K generated candidates without submission limits. "reported using the Score@K metric"
- Submitted Score: The achieved score when respecting the competition’s cap on the number of submissions. "the Submitted Score, which respects the 50-submission limit"
- subtask: A constrained portion of a problem evaluated and scored independently within IOI problems. "Each of the six problems is decomposed into its constituent subtasks"
- test generator: A program that creates randomized inputs satisfying subtask specifications. "100 test generator functions"
- test-time compute: Extra computational effort at inference to improve outputs (e.g., more sampling, verification, or selection). "Test-time compute refers to allocating additional computational resources during inference"
- thinking trace: The model’s internal chain of reasoning tokens for a solution. "the solution with the longest thinking trace"
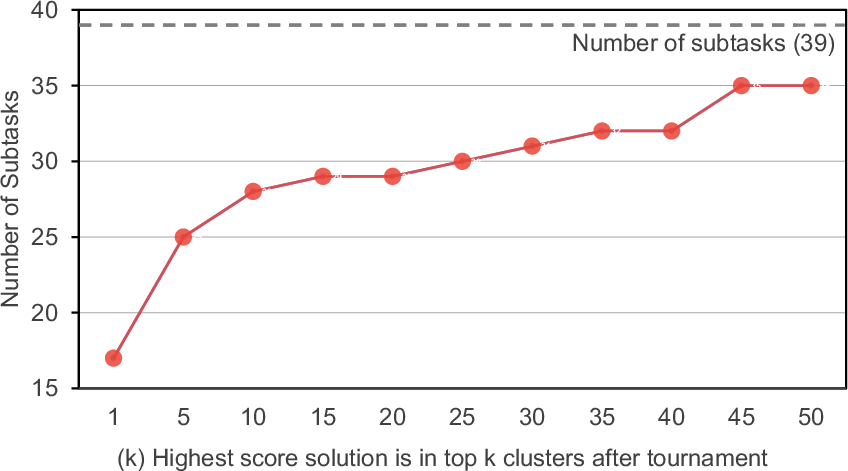
- top- inclusion: A metric checking whether the best solution appears among the top K ranked clusters. "Quality of cluster ranking measured by top- inclusion."
- Unconstrained Score@K: Score assuming no submission cap, taking the best among K candidates. "the Unconstrained Score@K, which assumes no submission cap"
- validation budgets: Limits on how much validation or checking can be performed per problem. "under limited validation budgets"
- validator: A program that checks whether a generated input satisfies the subtask’s constraints. "produce multiple independent validators"
- verification budget: Limits on the amount of verification (e.g., running tests) allowed during inference. "particularly those with a limited verification budget"
Collections
Sign up for free to add this paper to one or more collections.

