- The paper introduces CodexGraph, a unified framework that bridges LLMs and code repositories via graph databases to enhance query precision.
- It employs a two-phase indexing process with shallow indexing and edge completion to robustly capture and link code symbols across files.
- It demonstrates competitive benchmark performance and practical utility in code navigation, debugging, testing, and generation applications.
CodexGraph: Bridging LLMs and Code Repositories via Code Graph Databases
Introduction
"CodexGraph: Bridging LLMs and Code Repositories via Code Graph Databases" (2408.03910) presents an innovative approach to enhancing the interaction between LLMs and code repositories through the utilization of graph database interfaces. Existing solutions for LLM-codebase interaction often rely on similarity-based retrieval or task-specific tools, each with notable limitations. Similarity-based methods exhibit low recall rates in intricate coding tasks, while manual tools necessitate extensive expert knowledge and lack generalizability across diverse applications. The CodexGraph system introduces a novel solution by integrating LLM agents with graph databases, leveraging the structured properties of these databases and the flexibility of graph query languages to enable precise context retrieval and code navigation.
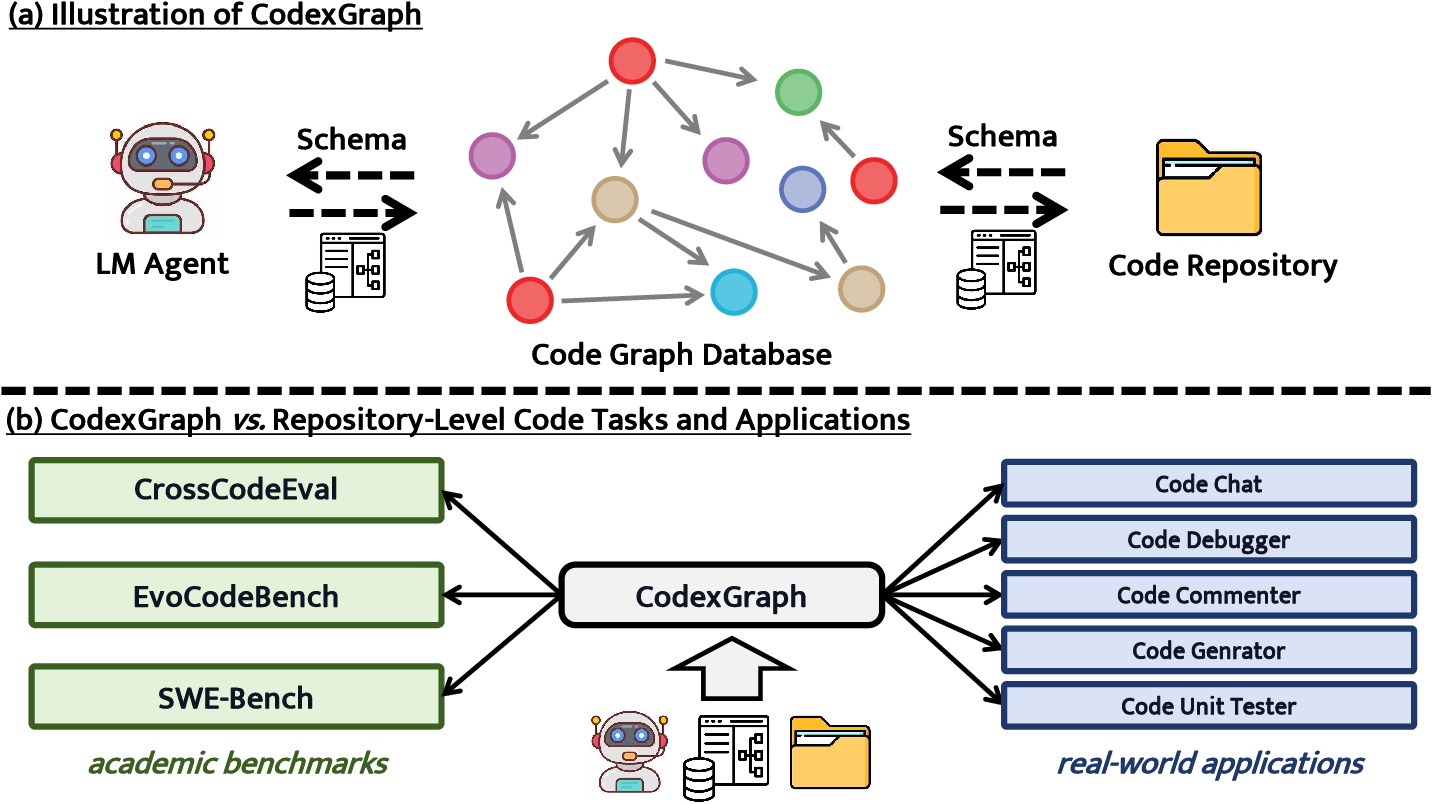
Figure 1: Using a unified schema, CodexGraph employs code graph databases as interfaces that allow LLM agents to interact seamlessly with code repositories.
Methodology
CodexGraph utilizes a unified schema to abstract code repositories into code graphs, where nodes represent source code symbols and edges denote relationships among these symbols. The construction of the code graph database involves two phases: shallow indexing and edge completion. Initially, static analysis extracts symbols and relationships from each Python file in a single pass, capturing essential nodes and their meta-information. The subsequent phase refines cross-file relationships, addressing dependencies and establishing comprehensive connections through a depth-first search.
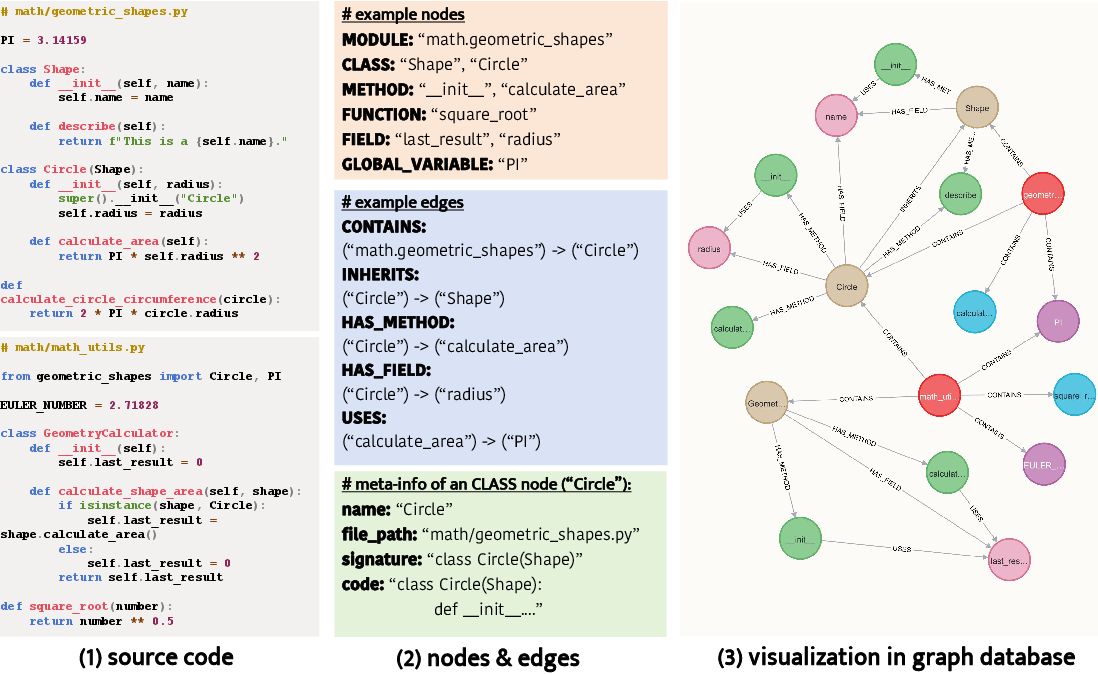
Figure 2: Illustration of the process for indexing source code to generate a code graph based on the given graph database schema.
CodexGraph features an LLM interaction pipeline that integrates an iterative query strategy and a "write then translate" mechanism. The primary LLM agent generates natural language queries based on user input and contextual understanding, while a translation LLM agent transforms these queries into executable graph queries. This division of labor enhances the system's ability to construct valid queries, facilitating accurate code structure-aware searches.
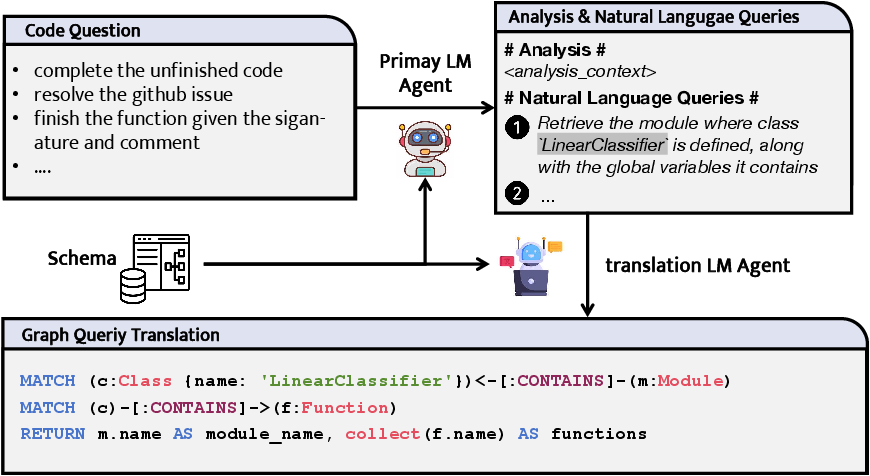
Figure 3: The primary LLM agent analyzes the given code question, writing natural language queries. These queries are then processed by the translation LLM agent, which translates them into executable graph queries.
Experimental Evaluation
CodexGraph's performance is evaluated across three benchmarks: CrossCodeEval, SWE-bench, and EvoCodeBench. Experimental results indicate that CodexGraph achieves competitive results across diverse tasks due to its code structure-aware retrieval capabilities. It consistently outperforms non-RAG approaches and demonstrates adaptability across multiple benchmarks, affirming its general applicability. The system benefits from the expansive action spaces provided by the graph database interfaces, though it incurs additional token consumption.
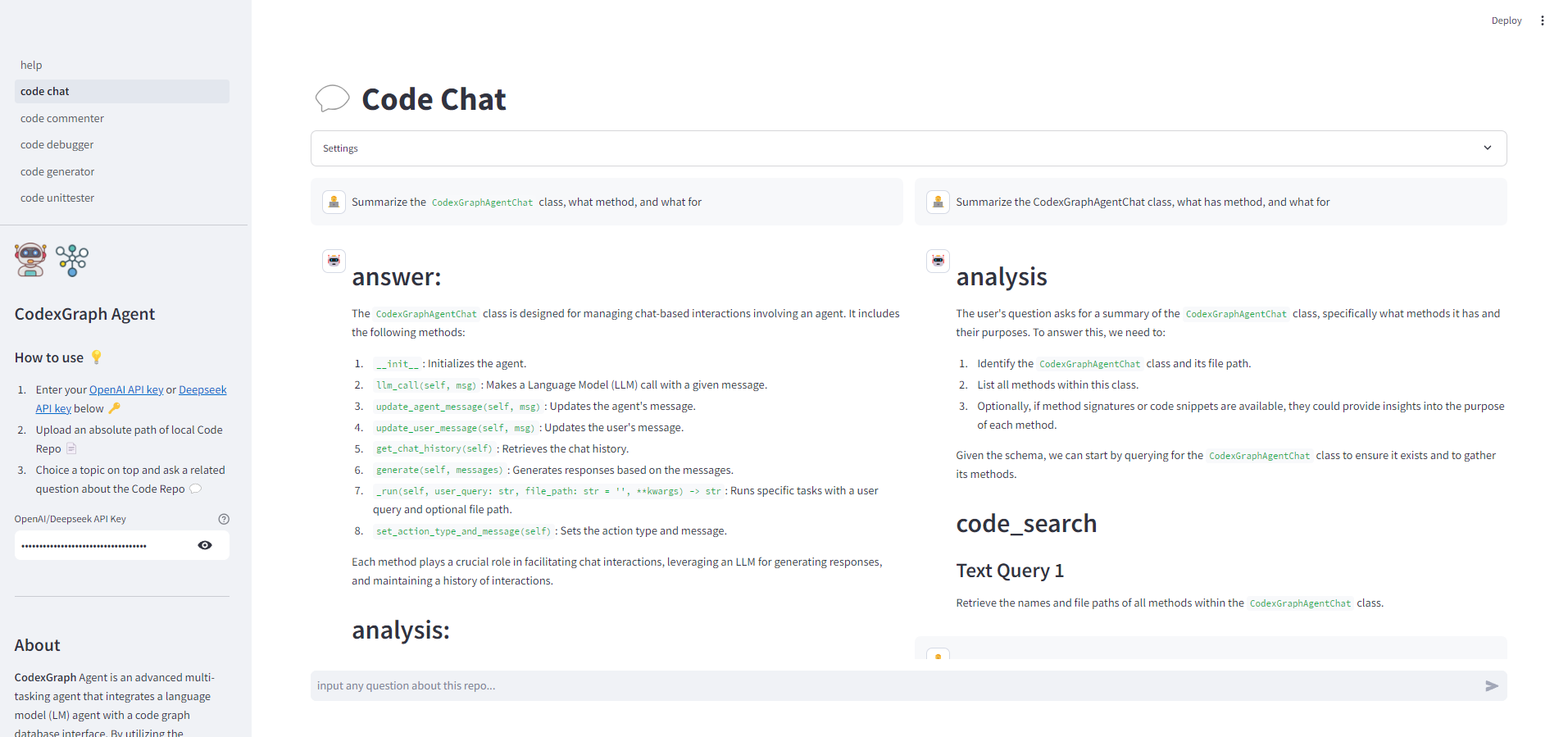
Figure 4: WebUI for the Code Chat, used for answering any questions related to code repositories.
Real-World Application
To demonstrate practical utility, CodexGraph extends to five real-world applications: Code Chat, Code Debugger, Code Unittestor, Code Generator, and Code Commentor. These applications address complex coding challenges by employing iterative reasoning, code understanding, and query-driven information retrieval. The integration within the ModelScope-Agent framework showcases CodexGraph's versatility in enhancing code navigation, debugging, testing, generation, and commenting.
Figure 5: WebUI for Code Debugger, Code Unittestor, Code Generator, and Code Commentor.
Conclusion
CodexGraph significantly expands the capabilities of LLMs in interacting with code repositories, overcoming the limitations of existing approaches. By bridging the gap between LLMs and repository-level tasks via graph database interfaces, CodexGraph enhances code retrieval accuracy and efficiency. The demonstrated performance across academic benchmarks and practical applications highlights its potential in automated software engineering. Future work may focus on extending CodexGraph to additional programming languages and refining its database indexing and schema completeness for broader applicability.