RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Abstract: LLMs excel at function- and file-level code generation, yet generating complete repositories from scratch remains a fundamental challenge. This process demands coherent and reliable planning across proposal- and implementation-level stages, while natural language, due to its ambiguity and verbosity, is ill-suited for faithfully representing complex software structures. To address this, we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph. RPG replaces ambiguous natural language with an explicit blueprint, enabling long-horizon planning and scalable repository generation. Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch. It operates in three stages: proposal-level planning and implementation-level refinement to construct the graph, followed by graph-guided code generation with test validation. To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks. On RepoCraft, ZeroRepo produces repositories averaging nearly 36K LOC, roughly 3.9$\times$ the strongest baseline (Claude Code) and about 64$\times$ other baselines. It attains 81.5% functional coverage and a 69.7% pass rate, exceeding Claude Code by 27.3 and 35.8 percentage points, respectively. Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a big problem: getting AI systems to build complete software projects (called “repositories”) from scratch, not just single functions or files. The authors introduce a new way to plan and organize these projects called the Repository Planning Graph (RPG). They also present a system named ZeroRepo that uses RPG to create large, working codebases step by step, with tests to check everything works.
What questions does the paper try to answer?
- How can we move from vague ideas in natural language (“make a machine learning library”) to a clear, reliable plan for a full software project?
- Can a structured blueprint (the RPG) help AI build bigger, more accurate repositories compared to planning with plain text?
- Does this approach scale—can it keep adding useful features and code without falling apart?
- How well does it work on real-world projects?
How does the approach work? (Explained with everyday ideas)
Think of building a city:
- Natural language plans are like someone describing a city with long paragraphs—easy to misunderstand and hard to keep consistent.
- RPG is like a detailed city blueprint: it shows neighborhoods, buildings, rooms, roads, and how water and electricity flow between them. It’s precise and easy to follow.
ZeroRepo uses RPG in three main stages:
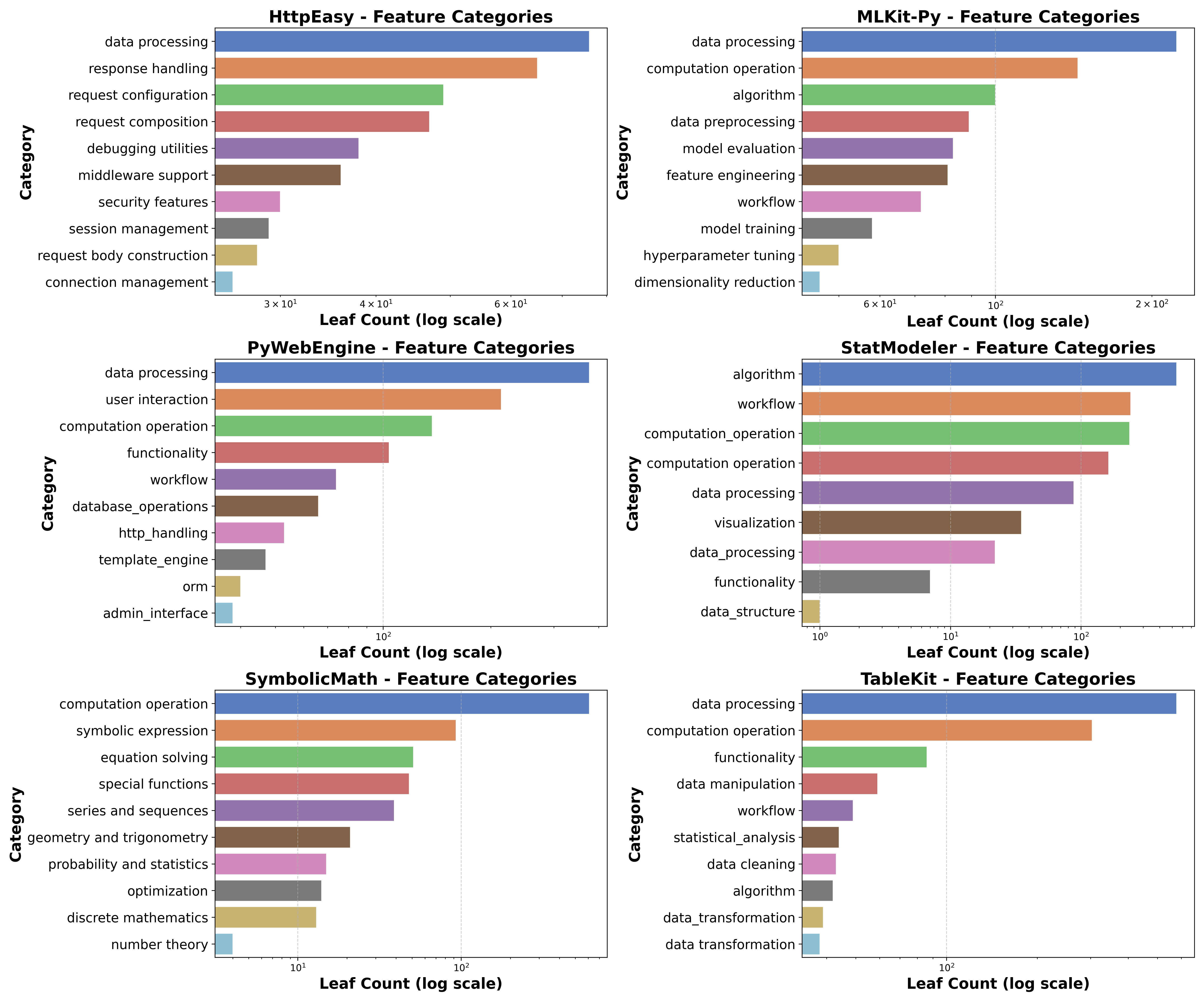
- First, it decides what the city needs (proposal-level planning). It searches a huge “feature catalog” (an organized list of ~1.5 million software features) to pick the right capabilities, like “data loading,” “training,” or “evaluation,” and groups them into modules.
- Second, it designs how the city is built (implementation-level planning). It lays out folders and files (like districts and buildings), defines functions and classes (rooms and machines), and draws lines showing how data moves between parts (like pipes and cables).
- Third, it builds and tests the city (graph-guided code generation). It follows the RPG’s order—build foundations first, then the rest. For each function or class, it writes tests, implements code, runs the tests, and fixes problems before moving on.
Key technical ideas translated:
- “Nodes and edges” in the graph: nodes are the parts (modules, files, functions); edges are the connections (who uses what, where data flows).
- “Topological order”: build dependencies first—like laying water pipes before installing a sink.
- “Test-driven development (TDD)”: write a test for a feature, build the feature, and only accept it when the test passes.
- “Feature tree”: a catalog that helps pick the right features so planning isn’t random or incomplete.
What did they find, and why does it matter?
They built a new test benchmark called RepoCraft, based on six real, well-known Python projects (like scikit-learn and pandas), and created 1,052 tasks to check correctness.
Here’s what ZeroRepo achieved:
- It generated large repositories—around 36,000 lines of code on average—much bigger than other systems (about 3.9× larger than the strongest competitor).
- It covered most of the needed features (81.5% coverage) and passed many tests (69.7% pass rate), improving vastly over the strongest baseline system (by 27.3 and 35.8 percentage points).
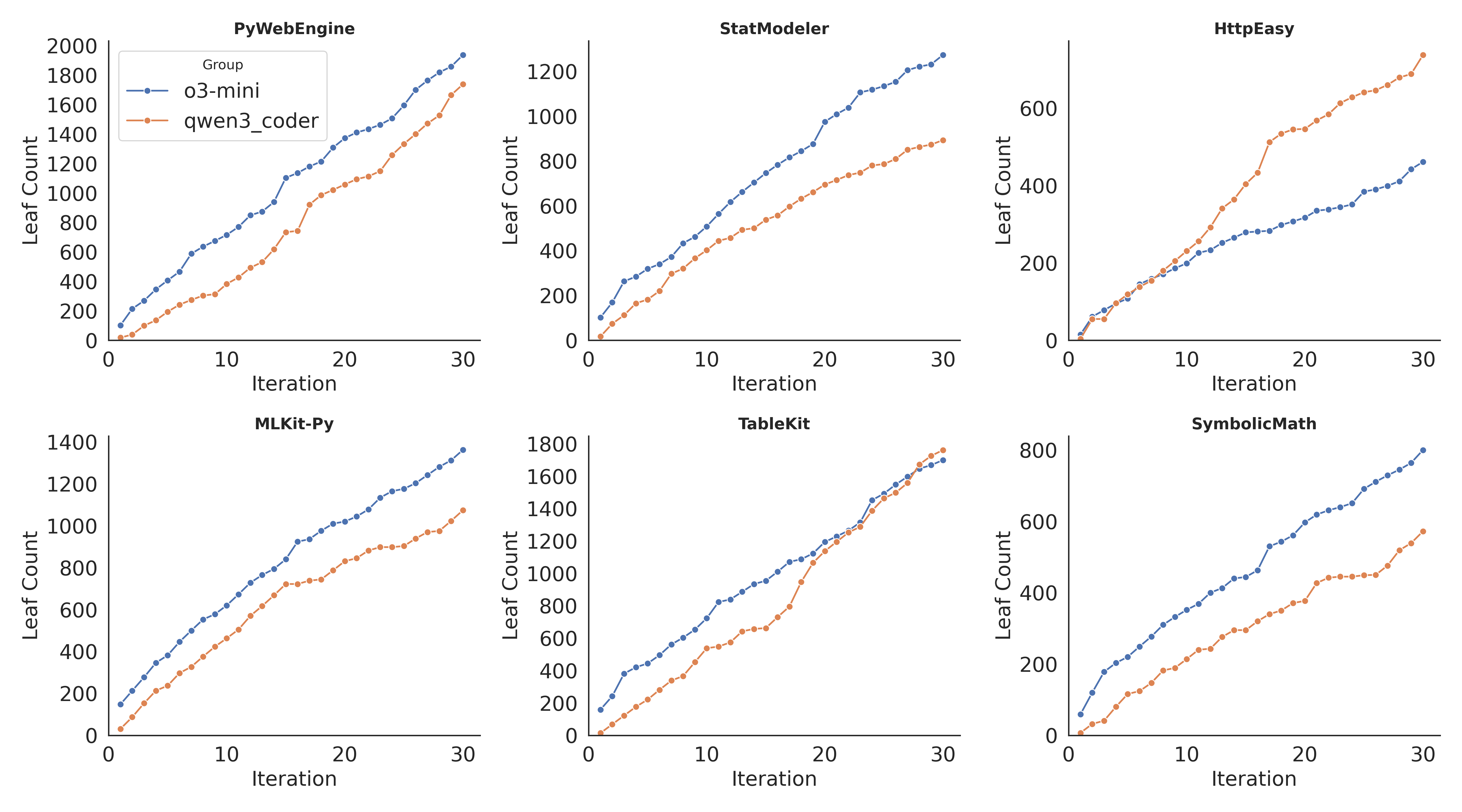
- It kept growing steadily: as planning continued, it added more features and code almost linearly (meaning growth stayed smooth and reliable).
- It helped the AI find where to fix problems faster. Because the RPG shows structure and dependencies clearly, the system could pinpoint issues and repair them more quickly than when using plain text plans.
Why this matters:
- Moving from messy text to a precise blueprint makes long, complicated projects more manageable and consistent.
- It shows AI can plan and build complex software step by step, scaling up without getting lost.
- The method makes codebases more trustworthy because testing is built into the process.
What’s the bigger impact?
This work suggests a shift in how AI should plan software:
- Use a structured, visual-like blueprint (the RPG) instead of long natural language notes.
- Keep the plan and the code in sync over time, so the project stays coherent as it grows.
- Apply this to many domains—libraries, tools, and apps—where long-term, large-scale development is needed.
If adopted widely, RPG-style planning could help AI teams and tools build bigger, more reliable software faster, with clearer designs, fewer mistakes, and better tests from the start.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several areas unresolved; the most salient are:
- Formal specification of RPG: The paper does not provide a precise, machine-checkable semantics for RPG nodes/edges (types, invariants, constraints), nor algorithms for detecting/repairing graph inconsistencies (cycles, dangling dependencies, schema violations) or for proving correctness of graph-to-code mappings.
- Graph evolution and versioning: It is unclear how RPG is updated over long horizons (diffs, merges, rollbacks), how code drift relative to the graph is detected, and how conflicts between evolving graph plans and existing code are resolved.
- Generalization beyond Python: All results are on six Python projects; the approach’s applicability to statically typed or compiled ecosystems (e.g., Java, C++, Rust), polyglot monorepos, build systems, and event-driven or asynchronous architectures is not evaluated.
- Coverage vs. quality: Functionality coverage counts category presence, not depth or completeness of implementation within categories; metrics that capture granularity, fidelity, and nontrivial algorithmic breadth are missing.
- Novelty utility and validity: “Novelty” is defined as features outside the taxonomy, but there is no assessment of whether these are useful, non-duplicative, or coherent; no human validation or utility scoring is reported.
- Security and reliability: There is no evaluation of security (vulnerability scanning, input sanitization), reliability under adverse inputs, or resilience to dependency failures—especially critical for web frameworks like Django.
- Performance and resource efficiency: The paper does not measure runtime performance, memory footprint, scalability on large inputs, or computational efficiency of generated repositories relative to human baselines.
- Maintainability and code quality: No analysis of code health (cyclomatic complexity, duplication, code smells, lint/type coverage, documentation completeness), CI readiness, packaging, dependency hygiene, or long-term maintainability.
- Evaluation pipeline bias: Automatic validation uses o3-mini both to generate and to evaluate; the extent of self-model bias, false positives/negatives, and sensitivity of the majority-vote validator is not quantified (precision/recall, calibration curves).
- Gold Projects ceiling: The evaluation pipeline achieves only 81% pass on human repositories, implying nontrivial evaluator error; the impact of this ceiling on reported improvements and ranking is not modeled.
- Fairness to baselines: ZeroRepo leverages a proprietary Feature Tree and graph tools unavailable to baselines; the paper does not control for advantage by giving baselines comparable structured priors or graph representations.
- Reproducibility of the Feature Tree: The 1.5M-node EpiCoder Feature Tree’s availability, construction methodology, coverage gaps, domain biases, and maintenance guarantees are not documented; results may not be reproducible without it.
- Explore–exploit subtree selection: The search policy (k-values, expansion criteria, stopping rules) lacks ablation and theoretical guarantees; failure modes (overfitting to ontology biases, missed niche features) are not analyzed.
- LLM-driven refactoring reliability: Module partitioning by “cohesion/coupling principles” is done by LLMs without quantitative validation against software metrics or comparisons to human architects; reproducibility and variance across seeds/backbones are unknown.
- File and interface mapping heuristics: The method for grouping features into files/classes (clustering criteria, thresholds) is under-specified; risks of over-consolidation, poor separation of concerns, or brittle interfaces are not measured.
- Data-flow typing and enforcement: Although data-flow edges are “typed,” there is no formal type system, static/dynamic checks, or enforcement mechanisms to ensure interface adherence across modules.
- Handling cross-cutting concerns: The topological traversal design does not address logging, configuration, caching, observability, authentication/authorization, or DI/IoC patterns commonly required in production repositories.
- Circular and latent dependencies: The approach assumes acyclic topological traversal; strategies for resolving cycles, late-binding dependencies, or plugin/extension points are not discussed.
- Test generation and coverage: TDD relies on docstrings and adapted ground-truth tests; coverage of generated tests, mutation scores, and how missing/poor docstrings affect correctness validation are not reported.
- Task adaptation risks: Adapting ground-truth tests to generated interfaces may inadvertently weaken tests or introduce mismatches; the rate of test adaptations that change intended semantics is not quantified.
- Error attribution reliability: Majority-vote diagnosis of environment vs. implementation errors lacks quantitative evaluation (confusion matrix, error taxonomy), raising uncertainty about reported pass rates.
- Cost and scalability: Token usage is reported, but end-to-end wall-clock time, GPU/CPU requirements, monetary cost per repository, and scalability to larger projects (>100K LOC) or longer iterations (>30) are not provided.
- Localization ablation rigor: The graph-guided localization ablation reports mean±SD steps on one repo; statistical significance, generalization across projects/tasks, and wall-clock time savings are not shown.
- Failure analysis: No breakdown of where ZeroRepo still fails (by module/category, error types), hindering targeted improvement; especially relevant given the gap to Gold Projects.
- Human-in-the-loop workflows: The paper does not specify how developers inspect/edit RPGs, override decisions, or incorporate feedback; UI/UX, explainability, and collaborative workflows remain open.
- External dependency management: Strategies for pinning versions, handling API changes, license compliance, and vulnerability/compatibility scans of third-party packages are not evaluated.
- Ethical and data leakage concerns: Paraphrasing repository names may not prevent pretraining leakage; there is no audit of training contamination or assessment of potential code copying by the models.
- Robustness to noisy/contradictory specs: How RPG construction resolves incomplete, conflicting, or evolving requirements (conflict detection, negotiation, re-planning) is not defined.
- Scheduling and parallelization: Topological execution for large graphs raises scheduling questions (parallel build/test, resource allocation) that are not addressed; potential bottlenecks and heuristics are absent.
- Open-source reproducibility: Complete release status of ZeroRepo, RPG tooling, RepoCraft assets, and the Feature Tree (code, data, seeds, configs) is not specified; reproducibility and community benchmarking pathways remain unclear.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the Repository Planning Graph (RPG), ZeroRepo’s graph-guided workflows, and the RepoCraft benchmark insights.
- RPG-backed repository scaffolding for enterprise prototyping
- Sector: software, fintech, edtech, internal tools
- Stakeholders: industry (platform engineering, product teams)
- What: Use RPG to transform high-level specs into modular repo skeletons with folders, files, interfaces, and data flows; traverse the graph for incremental TDD-based implementation.
- Tools/products/workflows: “ZeroRepo-as-a-Service” for internal prototyping; VS Code/JetBrains plugin to generate and visualize RPG manifests; CI job to ensure graph/topology consistency.
- Assumptions/dependencies: Access to capable LLMs; structured specs; vector DB + feature ontology (e.g., EpiCoder Feature Tree); unit-test infra; Python-first focus (multi-language support may be partial).
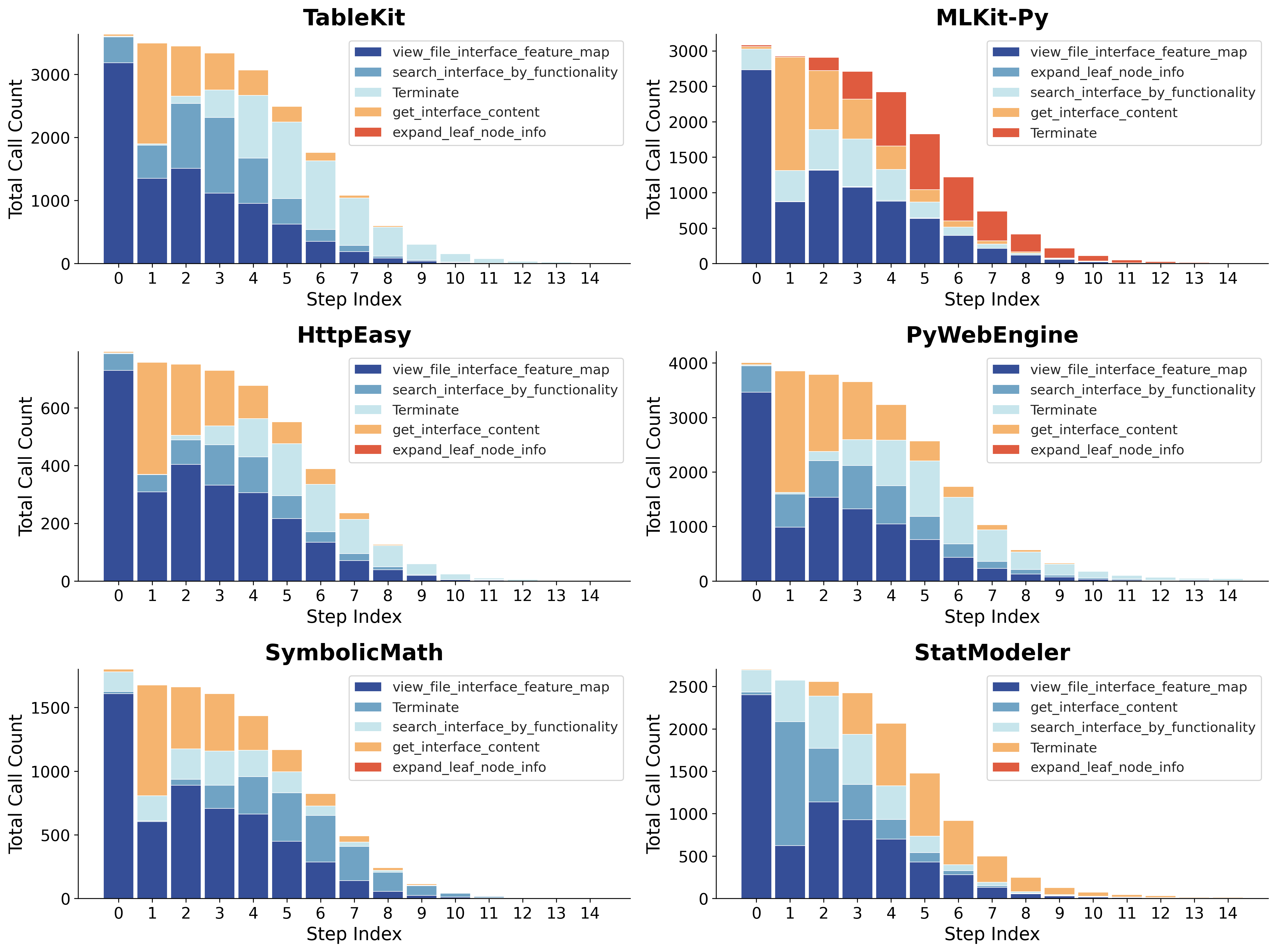
- Graph-guided debugging and issue localization
- Sector: software (DevOps, QA), robotics software stacks
- Stakeholders: industry, academia
- What: Adopt RPG to accelerate localization (30–50% fewer steps in experiments) by tracing dependencies and inter-module flows; pair with unit/regression/integration tests aligned to graph nodes.
- Tools/products/workflows: “RPG Debugger” that overlays call graphs, data-flow constraints, and file orderings; GitHub App that annotates PRs with affected subgraphs.
- Assumptions/dependencies: Adequate test coverage; repo instrumentation; graph-to-code mapping maintained as code evolves.
- Repository comprehension and onboarding aids
- Sector: software, education
- Stakeholders: industry (new hires), academia (students)
- What: RPG offers a compact visual and textual blueprint of capabilities, dependencies, and interfaces to help new contributors understand large repos quickly.
- Tools/products/workflows: Graph viewers, onboarding wizards, AI-assisted “tour guides” that traverse RPG in topological order.
- Assumptions/dependencies: Up-to-date RPG manifests; integration with code hosting and documentation.
- Graph-driven code review and architectural governance
- Sector: software, healthcare IT, finance (regulated), energy (grid software)
- Stakeholders: industry, policy teams
- What: Enforce modular boundaries and interface contracts via RPG; detect drift, tight coupling, and violations before merging.
- Tools/products/workflows: CI checks for graph-consistency; “Architectural Policy” rules tied to RPG edges; pre-merge impact reports.
- Assumptions/dependencies: Policy definitions encoded as graph constraints; team adoption; reliable mapping for multi-repo monorepos.
- Automated test planning aligned to capabilities
- Sector: software, robotics
- Stakeholders: industry QA, academia (software testing)
- What: Derive unit/integration test scaffolds from RPG leaf nodes and data-flow edges; prioritize testing based on dependency criticality.
- Tools/products/workflows: Test generators from docstrings; dependency-aware test prioritization; regression gating per subgraph.
- Assumptions/dependencies: Docstrings or specs per function/class; test runner integration; guardrails for flaky tests.
- Legacy codebase “RPG-ification” for modernization and refactoring
- Sector: software modernization, public-sector IT
- Stakeholders: industry, policy/IT governance
- What: Reverse-engineer existing repos into RPG to identify modules, data flows, and refactoring opportunities; plan migration paths.
- Tools/products/workflows: Static analysis + LLM synthesis to build RPG; refactor plans (split modules, unify interfaces).
- Assumptions/dependencies: Static analysis coverage; partial automation with human-in-the-loop; multi-language parsing.
- Benchmarking and evaluation with RepoCraft
- Sector: academia, R&D labs
- Stakeholders: researchers, educators
- What: Use RepoCraft tasks and metrics to evaluate end-to-end repo generation, coverage, correctness, and scalability.
- Tools/products/workflows: Course assignments; research baselines; reproducible scoring harnesses.
- Assumptions/dependencies: Compute resources; consistent evaluation pipeline; mitigation of training data leakage.
- Internal feature discovery and roadmapping via RPG novelty tracking
- Sector: software product management
- Stakeholders: industry (PMs/tech leads)
- What: Track coherent “novel” features proposed by the planning graph to inform roadmaps and ideation.
- Tools/products/workflows: RPG diffing between iterations; novelty dashboards tied to capability taxonomy.
- Assumptions/dependencies: Feature ontology coverage; review workflow to filter spurious or nonviable proposals.
- Education: structured programming assignments with RPG blueprints
- Sector: education (CS curricula)
- Stakeholders: academia, edtech providers
- What: Students build repos from specs using RPG planning; instructors grade coverage and correctness via graph-aligned tests.
- Tools/products/workflows: Classroom plugins; automated feedback on modularity and dependency design.
- Assumptions/dependencies: Adapted rubrics; safe LLM usage policies; anti-plagiarism checks.
- Documentation and software SBOM extensions with execution semantics
- Sector: policy/compliance (software supply chain), healthcare IT, finance
- Stakeholders: regulatory/compliance teams
- What: Augment SBOMs with RPG edges capturing data flows and interface contracts for traceable changes and audits.
- Tools/products/workflows: SBOM + RPG exporters; change-impact reports; compliance dashboards.
- Assumptions/dependencies: Standards alignment; auditor acceptance; handling proprietary components.
Long-Term Applications
The following applications require further research, scaling, standardization, or domain-specific integration before widespread deployment.
- Production-grade autonomous repository generation
- Sector: software, robotics, embedded systems
- Stakeholders: industry (R&D), platform engineering
- What: End-to-end repo synthesis for complex, multi-language systems with strong correctness guarantees.
- Tools/products/workflows: ZeroRepo extended to polyglot stacks; formal verification integrated into graph constraints.
- Assumptions/dependencies: Stronger LLMs; formal methods; richer ontologies; robust integration tests; safety cases.
- Regulated software pipelines with traceable RPG artifacts
- Sector: healthcare (clinical decision support), finance (risk engines), energy (grid control)
- Stakeholders: policy makers, compliance officers, engineering leaders
- What: Require RPG manifests as part of certification; link safety claims to graph nodes and test evidence.
- Tools/products/workflows: “Graph-of-Record” standards; audit trails from node-level tests; regulator toolkits.
- Assumptions/dependencies: New standards; auditor training; legal frameworks; strong data governance.
- Standardization of RPG as an open planning artifact
- Sector: policy/standards, software ecosystem
- Stakeholders: standards bodies (e.g., ISO, IEEE), open-source foundations
- What: Define schemas, APIs, and interchange formats for RPG across tools and languages.
- Tools/products/workflows: Open spec; reference implementations; compliance test suites.
- Assumptions/dependencies: Community consensus; interoperability with SBOMs and architecture description languages.
- Continuous planning and evolution (“always-on” RPG)
- Sector: software, DevOps
- Stakeholders: industry
- What: Live RPG that co-evolves with code changes, CI signals, and telemetry; auto-proposes refactors and tests.
- Tools/products/workflows: Graph-driven observability; evolution policies; auto-generated PRs.
- Assumptions/dependencies: Reliable change detection; developer trust; safeguards to prevent churn.
- Security posture and supply chain risk modeling via RPG
- Sector: cybersecurity
- Stakeholders: industry, public sector
- What: Identify vulnerable dependency paths, high-risk modules, and blast-radius estimates using graph edges and flows.
- Tools/products/workflows: Risk scoring on subgraphs; attack-path simulators; automated mitigations.
- Assumptions/dependencies: Vulnerability data integration; accurate dependency models; incident response linkage.
- Domain-specific ontologies beyond general software (clinical, financial, robotic)
- Sector: healthcare, finance, robotics
- Stakeholders: industry, academia
- What: Extend the feature tree with domain capabilities (e.g., HL7/FHIR, FIX protocols, ROS stacks) for precise planning.
- Tools/products/workflows: Domain embeddings; curated taxonomies; specialized test suites.
- Assumptions/dependencies: Expert curation; licensing; privacy/compliance constraints.
- Human–AI co-design environments for large teams
- Sector: enterprise software, open-source foundations
- Stakeholders: industry, OSS communities
- What: Collaborative RPG editors, role-based reviews, and graph-aware workflows across distributed teams.
- Tools/products/workflows: Multi-user RPG IDEs; change negotiations at the graph level; decision logs linked to nodes.
- Assumptions/dependencies: Access control models; UI/UX maturity; cultural adoption.
- Graph-level reinforcement learning to optimize repository evolution
- Sector: research, advanced DevOps
- Stakeholders: academia, R&D
- What: Treat RPG as a state space; learn policies that improve modularity, test coverage, and performance over time.
- Tools/products/workflows: RL pipelines; simulation environments (RepoCraft++); reward shaping via quality metrics.
- Assumptions/dependencies: Stable metrics; scalable simulators; computational budgets.
- Educational co-pilots that teach architecture and modular design
- Sector: education, edtech
- Stakeholders: academia, learners
- What: Tutors that help students plan large projects via RPG, critique designs, and auto-generate practice tasks.
- Tools/products/workflows: Graph-based lesson plans; formative feedback tied to dependency correctness.
- Assumptions/dependencies: Pedagogical validation; access policies; bias mitigation.
- Cross-repo integration planners (microservices and monorepos)
- Sector: software (platforms), cloud
- Stakeholders: industry
- What: RPG-based orchestration across services; plan interfaces and contracts spanning repos.
- Tools/products/workflows: Multi-repo graphs; service contract generators; integration test orchestrators.
- Assumptions/dependencies: Service discovery; API catalog integration; versioning discipline.
- Code search and reuse driven by graph semantics
- Sector: developer tooling
- Stakeholders: industry, OSS
- What: Search by capability, data-flow shape, or interface contract; suggest reusable modules aligned with target RPG nodes.
- Tools/products/workflows: Semantic graph search; reuse recommendations; license-aware integration.
- Assumptions/dependencies: High-quality metadata; licensing compliance; deduplication.
- Multi-language and multi-modal expansion (data + UI + ops)
- Sector: full-stack software, MLOps
- Stakeholders: industry
- What: RPG spanning backend, frontend, ML pipelines, infra-as-code; unify planning across modalities.
- Tools/products/workflows: Polyglot graph schemas; cross-layer test generation; deployment-aware edges.
- Assumptions/dependencies: Language-agnostic standards; robust orchestration; advanced model capabilities.
Glossary
- BaseEstimator: A base class abstraction used to unify interfaces across algorithm implementations. "For example, algorithms can be unified under a BaseEstimator class to ensure standardized interaction with preprocessing and evaluation modules."
- Cohesion and coupling: Software engineering principles guiding modular design by maximizing internal relatedness and minimizing inter-module dependencies. "The LLM partitions functionalities into cohesive modules following software engineering principles of cohesion and coupling."
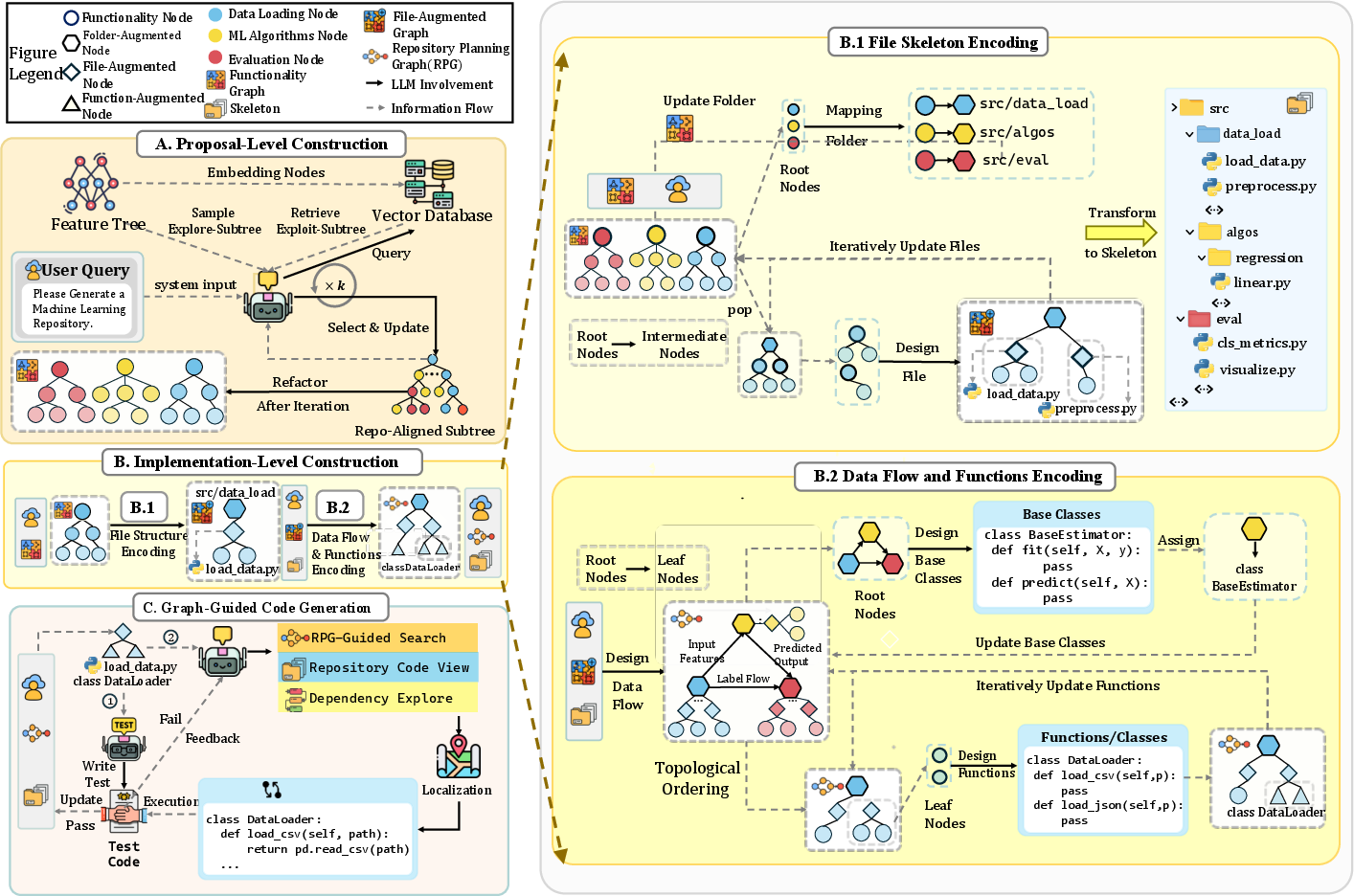
- Data-Flow Encoding: The process of specifying inter- and intra-module input–output relations in the planning graph to ground interfaces in execution semantics. "Data-Flow Encoding"
- Dependency exploration: A graph-guided technique for tracing related modules and interactions to localize or debug code. "(3) dependency exploration, tracing edges to reveal related modules and interactions."
- EpiCoder Feature Tree: A large-scale hierarchical ontology of software capabilities used as a structured prior for functionality grounding. "To stabilize planning, we ground functionality selection in the EpiCoder Feature Tree, a large-scale ontology of over 1.5M software capabilities."
- Explore–exploit strategy: A balanced search approach that alternates between retrieving highly relevant features and exploring diverse regions to build a repo-aligned subtree. "ZeroRepo incrementally expands the subtree via an exploreâexploit strategy."
- File-augmented graph: A planning graph enriched with explicit folder and file assignments to anchor downstream design and implementation. "By embedding file structure in the graph, we preserve semantic cohesion, reduce cross-file coupling, and obtain a file-augmented graph that anchors downstream design."
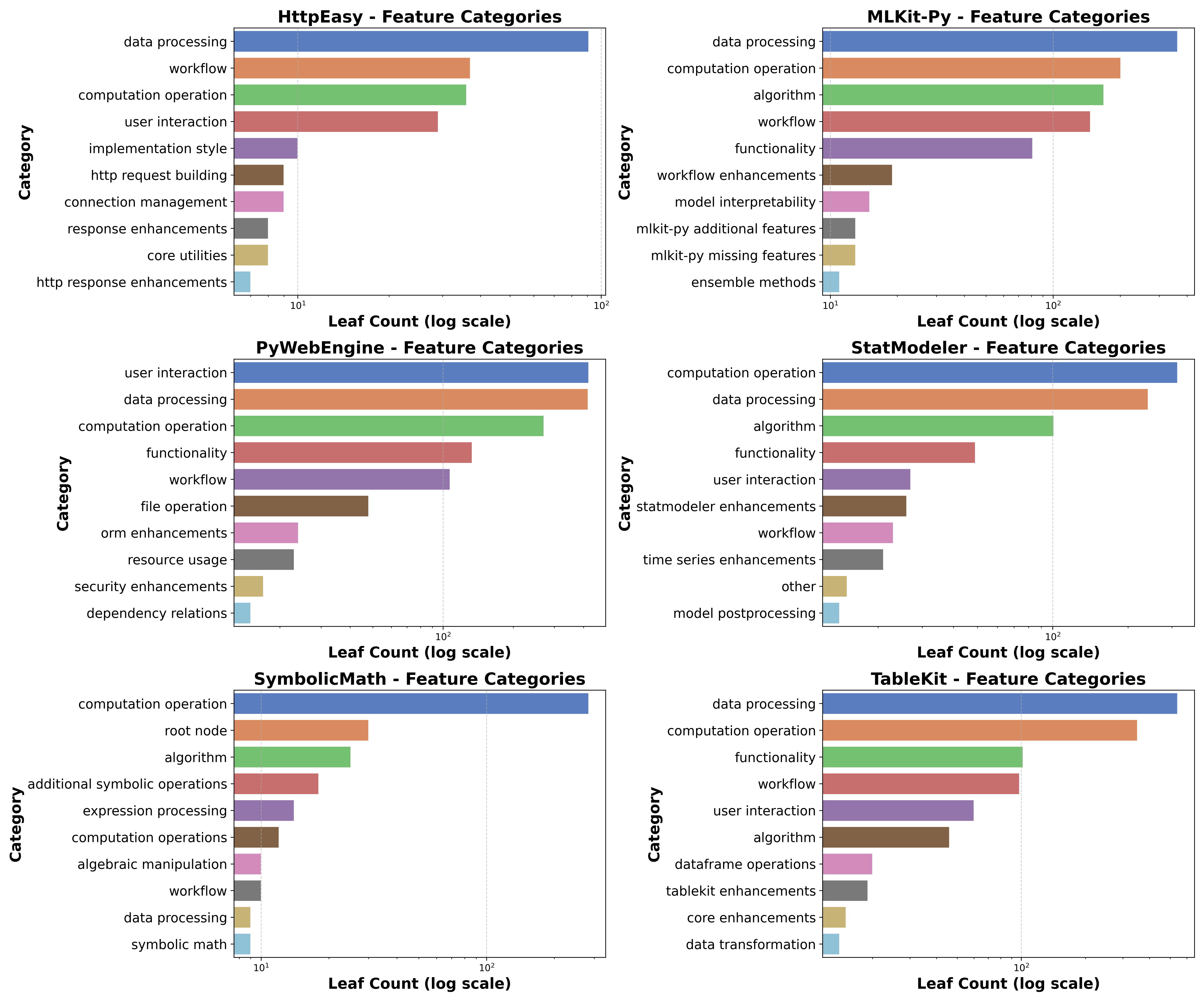
- Functionality Coverage: A metric measuring the proportion of documented functional categories represented by the generated system. "Functionality Coverage"
- Functionality Novelty: A metric quantifying the proportion of generated functionalities that fall outside the reference taxonomy. "Functionality Novelty"
- Graph-Guided Code Generation: A code synthesis process that traverses the planning graph in dependency order, applying tests and edits per node. "Graph-Guided Code Generation traverses the RPG in topological order, applying test-driven development with graph-guided localization and editing to iteratively implement and validate components."
- Graph-Guided Localization and Editing: A two-stage workflow that first localizes targets via the graph’s structure and then edits associated code. "Graph-Guided Localization and Editing"
- Integration tests: Tests validating that components or modules work together correctly according to planned data flows and contracts. "completed subgraphs undergo integration tests to ensure consistent data flows and contracts across modules."
- Inter-module edges: Graph edges that encode data flows and execution dependencies between modules. "Inter-module edges (black arrows in Figure~\ref{fig:feature_graph}) encode data flows between modules, such as outputs from Data Loading feeding into ML Algorithms and then into Evaluation."
- Intra-module edges: Graph edges that capture ordering and dependencies within a module, often at the file level. "Intra-module edges (gray dashed arrows) capture file-level orderings; for instance, load_data.py precedes preprocess.py, with outputs propagated to preprocessing."
- Majority-vote diagnosis: A lightweight ensemble-based procedure to distinguish real implementation errors from test or environment issues. "A lightweight majority-vote diagnosis distinguishes genuine implementation errors from environment or test issues, automatically handling the latter and returning the former for repair through the localizationâediting workflow."
- Near-linear scaling: A growth behavior where functionality and code size increase roughly proportionally with planning iterations. "Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization."
- Ontology: A structured representation of concepts and their relationships used to organize and retrieve software capabilities. "a large-scale ontology of over 1.5M software capabilities."
- Proposal-Level Construction: The stage that organizes and refines requirements into a functionality graph grounded in a feature ontology. "Proposal-Level Construction organizes and refines requirements into a functional graph by retrieving nodes from a large-scale feature tree."
- RepoCraft: A benchmark comprising real-world projects and tasks for evaluating end-to-end repository generation. "To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks."
- Repository Planning Graph (RPG): A persistent, unified graph representation encoding capabilities, structure, data flows, and functions for repository-scale planning. "we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph."
- Repository skeleton: The folder and file layout instantiated from the planning graph to map modules into executable structures. "instantiating a repository skeleton that maps functional modules into executable structures, resulting in a file-augmented graph."
- Stratified sampling: A sampling method that preserves representation across hierarchical test categories to ensure coverage. "apply stratified sampling to ensure representative coverage."
- Test-driven development (TDD): A development practice where tests are specified before implementation and used iteratively to validate correctness. "At each leaf node, test-driven development (TDD) is applied: a test is derived from the task specification, after which the corresponding functions or classes are implemented and validated against it; failing cases trigger revisions until the test passes."
- Topological order: An ordering of nodes ensuring dependencies are implemented before dependents. "Collectively, these edges impose a topological order that aligns functional decomposition with code organization, ensuring coherence between global execution semantics and local implementation."
- Vector database: A storage system for embeddings that supports similarity search with associated metadata for efficient retrieval. "each feature node is embedded into a vector representation, with its full hierarchical path stored as metadata in a vector database."
- Voting Rate: An accuracy metric denoting the fraction of tasks validated by majority-vote semantic checks. "Voting Rate, the fraction validated by majority-vote semantic checks."
- ZeroRepo: A graph-driven framework that constructs and exploits the RPG to generate repositories from scratch. "Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch."
Collections
Sign up for free to add this paper to one or more collections.