Actions Speak Louder than Prompts: A Large-Scale Study of LLMs for Graph Inference
Abstract: LLMs are increasingly used for text-rich graph machine learning tasks such as node classification in high-impact domains like fraud detection and recommendation systems. Yet, despite a surge of interest, the field lacks a principled understanding of the capabilities of LLMs in their interaction with graph data. In this work, we conduct a large-scale, controlled evaluation across several key axes of variability to systematically assess the strengths and weaknesses of LLM-based graph reasoning methods in text-based applications. The axes include the LLM-graph interaction mode, comparing prompting, tool-use, and code generation; dataset domains, spanning citation, web-link, e-commerce, and social networks; structural regimes contrasting homophilic and heterophilic graphs; feature characteristics involving both short- and long-text node attributes; and model configurations with varying LLM sizes and reasoning capabilities. We further analyze dependencies by methodically truncating features, deleting edges, and removing labels to quantify reliance on input types. Our findings provide practical and actionable guidance. (1) LLMs as code generators achieve the strongest overall performance on graph data, with especially large gains on long-text or high-degree graphs where prompting quickly exceeds the token budget. (2) All interaction strategies remain effective on heterophilic graphs, challenging the assumption that LLM-based methods collapse under low homophily. (3) Code generation is able to flexibly adapt its reliance between structure, features, or labels to leverage the most informative input type. Together, these findings provide a comprehensive view of the strengths and limitations of current LLM-graph interaction modes and highlight key design principles for future approaches.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores how LLMs can understand and make decisions using graphs. A graph is like a network: dots (called “nodes”) connected by lines (called “edges”). For example, people connected by friendships, products connected by “bought together,” or web pages connected by links. The main job studied here is “node classification,” which means guessing the category of a node (like “spam or not,” “topic of a paper,” or “type of product”) using the node’s text and its connections.
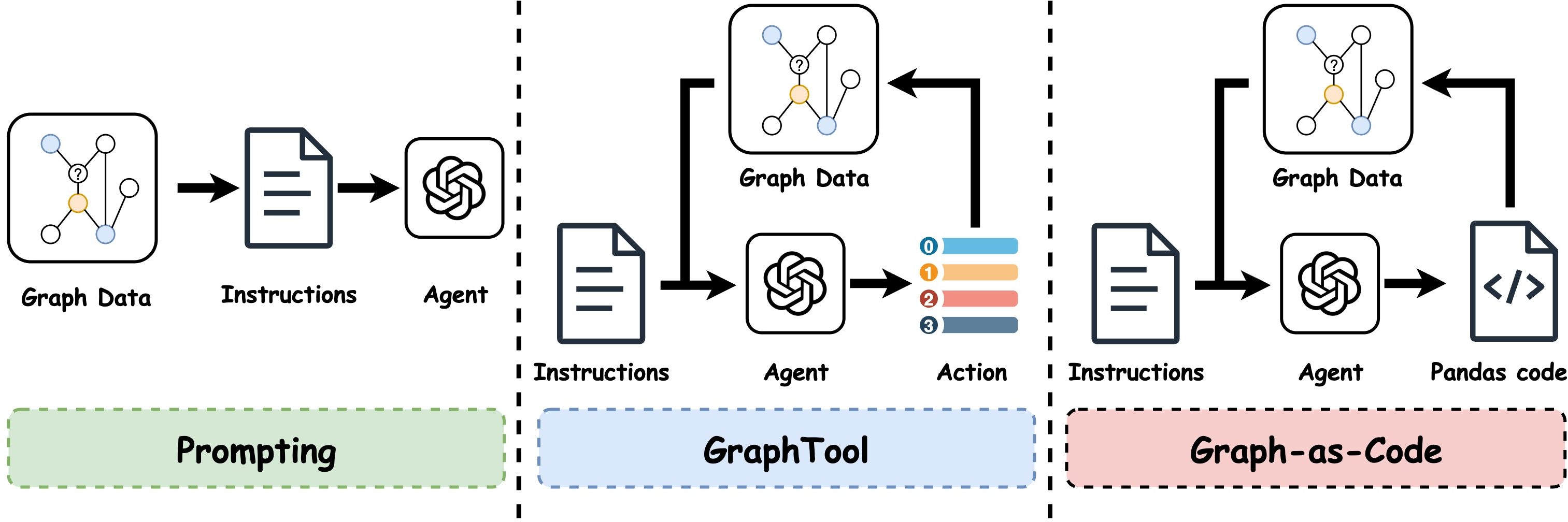
The authors compare three ways LLMs can work with graphs:
- Turning the graph into text and asking the LLM directly (Prompting).
- Letting the LLM ask for specific pieces of graph info step-by-step (Tool-use).
- Having the LLM write short programs to query the graph and its text (Graph-as-Code).
They test these methods across many datasets and situations to figure out what works best and why.
The Main Questions
The paper asks simple but important questions:
- Which way of interacting with graphs helps an LLM make the most accurate predictions?
- Do these methods work well on different kinds of graphs (where similar nodes connect vs. where different nodes connect)?
- How do long pieces of text (like product descriptions or user bios) affect performance?
- What does the LLM rely on most: the text features, the connections (structure), or known labels from some nodes?
- Does model size or “reasoning” ability change the results?
Key Terms Explained
- Graph: A network of nodes (things) connected by edges (relationships).
- Node classification: Assigning a label (like a category) to a node.
- Features: Text attached to a node (titles, descriptions, profiles).
- Structure: Who connects to whom (the pattern of edges).
- Labels: Known categories for some nodes (used as hints/examples).
- Homophily: “Birds of a feather flock together.” Nodes connect mostly to similar labels.
- Heterophily: “Opposites attract.” Nodes connect to different labels.
- Token limit/context window: The LLM’s memory for a single request; if you stuff in too much text, it runs out of space.
How They Studied It
To make fair comparisons, the authors tested across many axes:
- Different interaction modes:
- Prompting: Serialize a node and its neighborhood into text and ask the LLM to predict.
- Tool-use (ReAct-style): The LLM thinks aloud, then chooses actions like “get neighbors” or “get a node’s text” or “get labels,” repeating until ready to predict.
- Graph-as-Code: The LLM writes and runs small code snippets to query a neat table version of the graph (columns like node_id, features, neighbors, label). It can combine steps efficiently.
- Different datasets: Citation networks, web-link graphs, e-commerce product graphs, and social networks. Some have short texts (titles), others have long texts (descriptions, bios).
- Different structures: Homophilic graphs (similar nodes connect) and heterophilic graphs (different nodes connect).
- Different LLM settings: Varying sizes and reasoning features.
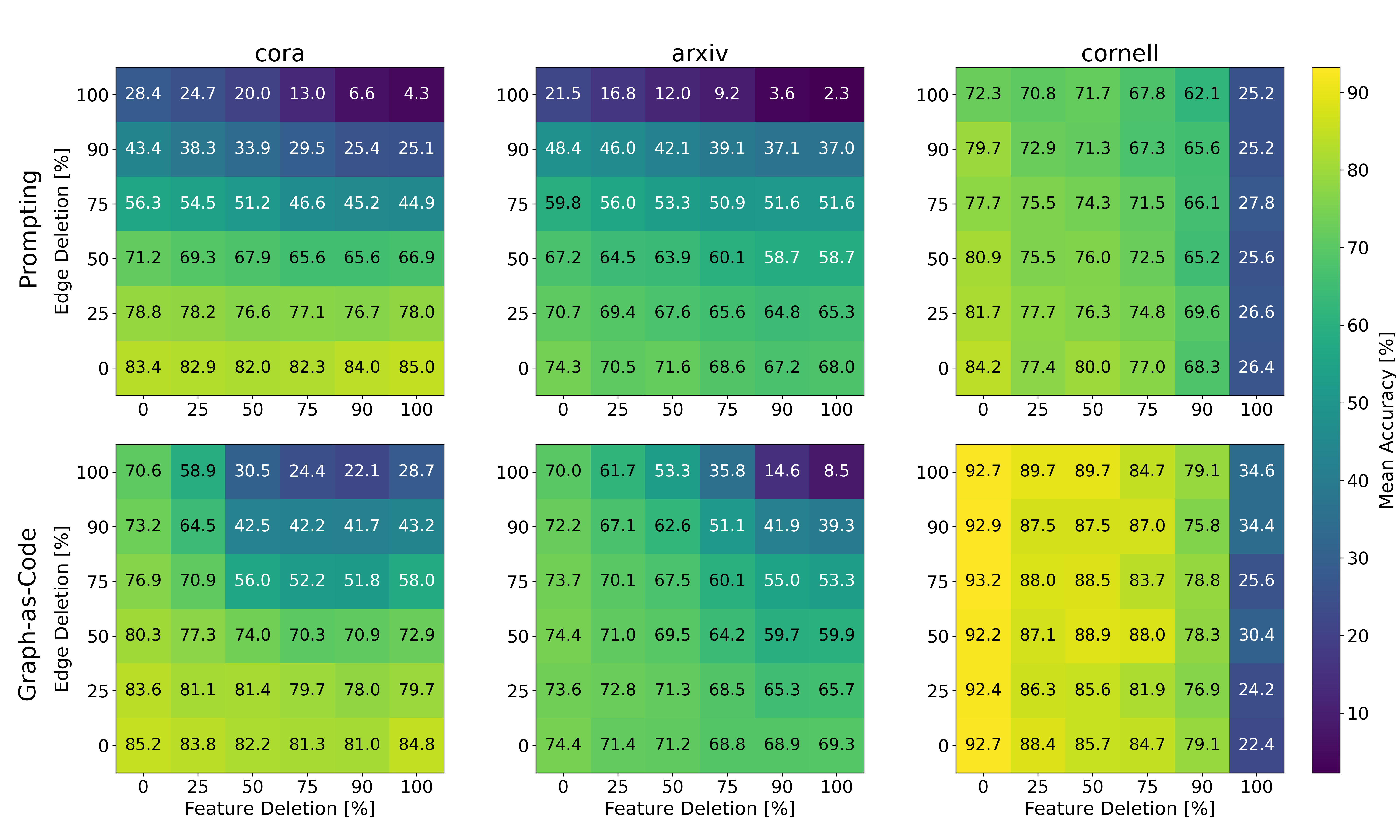
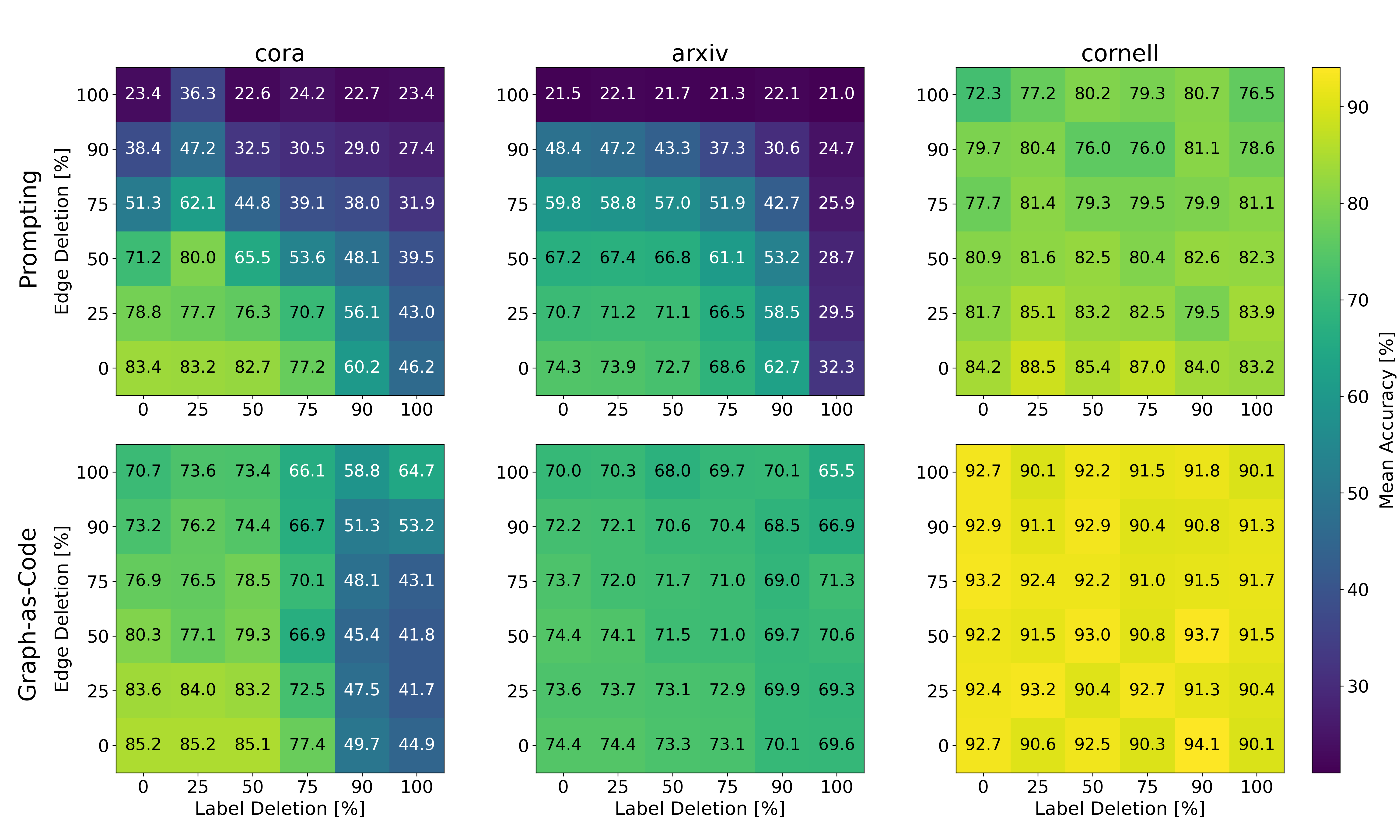
To see what the LLM truly depends on, they did “ablation” tests—systematically removing parts of the input:
- Truncating text features (making them shorter).
- Deleting edges (removing connections).
- Removing known labels. They then plotted accuracy heatmaps to show how each method’s performance changes under these removals.
What They Found (and Why It Matters)
Here are the key results, explained simply:
- Graph-as-Code wins overall, especially on big, text-heavy graphs.
- Why: Prompting can run out of memory fast when nodes have long descriptions or many neighbors. Writing code lets the LLM fetch just what it needs, in fewer, smarter steps.
- All methods still work on heterophilic graphs (where neighbors may be very different).
- Why: Even when local connections aren’t helpful, LLMs can lean on text features and non-local patterns. This challenges the common belief that LLMs fail when homophily is low.
- Graph-as-Code is flexible and robust.
- It adapts to the most useful signal:
- If text features are rich, it focuses on text.
- If labels are available, it uses them.
- If text is short or labels are missing, it uses structure wisely.
- In contrast, pure Prompting often needs both structure and labels visible in the prompt and is more fragile when any one source gets trimmed.
- When prompt size hits the token limit, Prompting and Graph-as-Code behave differently.
- Prompting’s accuracy can drop sharply because it must pack everything into one big message.
- Graph-as-Code can avoid the limit by selectively querying what matters, keeping performance high.
- On short-text, homophilic graphs, Prompting and Graph-as-Code are close.
- Why: Short features and simpler neighborhoods fit nicely into prompts, so Prompting doesn’t get squeezed by the token limit.
Implications and Impact
- For practitioners:
- Prefer Graph-as-Code when graphs have long text or many connections. It’s more scalable and stable.
- Don’t avoid LLMs just because your graph is heterophilic—these methods still work well.
- If data is messy or partially missing, Graph-as-Code’s adaptability makes it a safer choice.
- For researchers:
- Designing LLM workflows that act (use tools or code) can beat pure prompting, especially in realistic, text-rich settings.
- Future methods should focus on selective retrieval and compositional reasoning, not bigger prompts.
- Studying dependencies (features vs. structure vs. labels) reveals how to tailor methods to each graph’s strengths.
In short: Actions (smart querying and code) beat big prompts. Letting LLMs “do things” with graphs—like calling tools or writing small programs—makes them more accurate, flexible, and robust, especially in the complex, text-heavy graphs we see in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research.
- Comparative baselines: No systematic comparison against strong graph ML methods (e.g., text-aware GNNs, Graph Transformers, Label Propagation with text encoders, R-GCN, HGT); quantify how LLM modes stack up against SOTA across the same datasets and constraints.
- Task generalization: Focused solely on node classification; assess whether findings persist for link prediction, edge classification, community detection, and graph-level prediction.
- Scalability and cost: Absent measurement of token usage, number of tool/code steps, latency, memory footprint, and monetary cost per mode; evaluate scalability to large, dense, or million-node graphs.
- Model dependence and reproducibility: Primary results rely on a single (closed-source) model (o4-mini) with limited details; provide full cross-family analysis (open vs. closed-source, reasoning vs. non-reasoning), context-window sizes, and release complete prompts/APIs for reproducibility.
- Code execution safety and correctness: Unspecified sandboxing, resource limits, and error handling for Graph-as-Code; evaluate risks of code injection, non-determinism, runtime failures, and auditing capabilities in production settings.
- Label exposure and leakage: Although held-out labels are set to None, rigorously verify no indirect leakage (e.g., via neighbors’ text or metadata); analyze sensitivity to labeled-set size, label noise, class imbalance, and multi-label classification.
- Perturbation realism: Ablations use random edge deletions and text truncation; evaluate realistic corruptions (missing-not-at-random edges, adversarial rewiring, noisy or misleading text, distribution shift) and targeted attacks.
- Heterophily coverage: Heterophilic benchmarks are low-degree web graphs; test high-degree heterophilic graphs and multi-relational settings to validate claims beyond current regime.
- Graph heterogeneity: Experiments use unweighted, single-relation graphs; extend to directed, weighted, temporal/dynamic, heterogeneous, bipartite, and knowledge graphs with typed edges/relations.
- Feature modality breadth: Node features are text-only; assess multimodal nodes (images, tables, structured attributes) and how each interaction mode leverages non-text features.
- Prompting sensitivity: Limited exploration of prompt formats; quantify robustness to template wording, ordering, serialization choices, chain-of-thought, and instruction tuning; analyze long-context models explicitly.
- Agent variants: Tool-use is restricted to ReAct-style with fixed actions; compare with Plan-and-Execute, Reflexion, memory-augmented agents, and graph-aware RAG to understand planning/memory effects.
- Neighborhood depth and global structure: Prompting capped at 2 hops; investigate deeper neighborhoods, global graph structure exploitation, and whether Graph-as-Code can reliably capture long-range dependencies.
- Evaluation metrics: Accuracy-only focus; add macro/micro F1, AUROC, calibration (ECE), confidence estimation, error bars/significance tests, and fairness metrics across subpopulations.
- Error analysis: Minimal failure-mode characterization; break down performance by node degree, homophily level, text length, class frequency, and community structure to pinpoint weaknesses.
- Production viability: No study of streaming/dynamic graphs, cold-start nodes, caching, batching/throughput, or end-to-end pipeline integration and monitoring.
- Dataset curation risks: Potential label leakage via class names or category terms in node text; assess multilingual graphs, cross-domain generalization, and standardized, leakage-aware splits.
- Training regimes: Methods appear zero-shot/inference-only; evaluate instruction tuning, task-specific finetuning, and adapter-based training for each interaction mode.
- Token-limit policy: Token budgets and sampling strategies (for budget prompts) are under-specified; conduct sensitivity analyses to context-window size, neighbor sampling policy, and truncation heuristics.
- Nature of code reasoning: Unclear whether Graph-as-Code produces nontrivial algorithms vs. simple retrieval/aggregation; systematically characterize generated code patterns and their contribution to accuracy.
- Theory and principled analysis: Provide formal conditions under which each mode (prompt/tool/code) should dominate (e.g., as functions of homophily, degree, feature length, label density) and explain observed robustness theoretically.
- Privacy and compliance: Running generated code over sensitive graphs raises privacy and governance questions; define auditing, access control, and compliance mechanisms for real deployments.
Glossary
- context window: The maximum number of tokens an LLM can process in its input at once; exceeding it limits model effectiveness. "due to context window limitations."
- diagonal degree matrix: A square matrix with node degrees on the diagonal and zeros elsewhere, used in graph normalization. "a diagonal degree matrix"
- Graph-as-Code: An interaction mode where the LLM generates and executes code over a graph API to retrieve and compose structural and textual information for reasoning. "Graph-as-Code achieves the strongest overall performance, with especially large gains on long-text or high-degree graphs where prompting quickly exhausts the token budget."
- Graph Neural Networks (GNNs): Neural architectures designed to learn from graph-structured data via message passing and aggregation over nodes and edges. "the dominant paradigm for graph understanding, Graph Neural Networks (GNNs)"
- Graph-of-Thought: A paradigm that structures multi-step reasoning as graph-like plans the LLM can adapt and traverse. "Variants such as Plan-and-Execute \citep{wang2023plan}, Reflexion \citep{shinn2023reflexion}, and Graph-of-Thought \citep{besta2024graph} have shown that LLMs can decompose complex tasks into sequences of actions and adapt plans via feedback."
- GraphTool: A ReAct-style tool-calling setup that lets an LLM iteratively query neighbors, features, and labels via predefined actions to perform node classification. "In our basic variation, GraphTool, the following actions are available:"
- GraphTool+: An enhanced GraphTool variant that adds exact-k-hop retrieval actions for more flexible neighborhood access. "We also introduce GraphTool+, which extends the base GraphTool variant with additional exact- hop retrieval actions:"
- heterophily: The tendency for nodes to connect primarily to nodes of different classes, reducing usefulness of local label information. "heterophily is the tendency to connect predominantly with nodes of different classes."
- homophily: The tendency for nodes to connect primarily to nodes of the same class, making local neighborhoods predictive. "Homophily is the tendency of nodes to connect with others of the same class"
- k-hop neighborhood: The set of nodes at exactly k edges away from a target node, often used to provide localized context. "serializes the -hop neighborhood grouped by hop distance"
- Label Propagation (LP): A classical semi-supervised algorithm that spreads known labels over the graph via iterative neighborhood averaging. "Label Propagation (LP) algorithm."
- label space: The set of possible categorical labels in a task; models trained for specific label spaces may not transfer across them. "do not transfer across domains or label spaces"
- LLM orchestration: The design of systems that coordinate LLM reasoning with external tools, APIs, and control loops. "Recent advances in LLM orchestration have introduced tool-calling and ReAct-style paradigms"
- one-hot vectors: Binary vectors with a single 1 indicating a class and 0s elsewhere, used to encode labels. "In LP, node labels are represented as one-hot vectors"
- Plan-and-Execute: A tool-use paradigm where the LLM plans a sequence of actions and executes them to solve complex tasks. "Variants such as Plan-and-Execute \citep{wang2023plan}, Reflexion \citep{shinn2023reflexion}, and Graph-of-Thought \citep{besta2024graph} have shown that LLMs can decompose complex tasks into sequences of actions and adapt plans via feedback."
- Prompting: Supplying task instructions and serialized graph/context as text to an LLM for single-turn inference. "Prompting and Graph-as-Code are closely competitive on short-text homophilic datasets."
- random-walk normalized adjacency matrix: A row-normalized adjacency used to model random walks over the graph for propagation and diffusion. "The (random-walk) normalized adjacency matrix is defined as"
- ReAct: A paradigm that interleaves natural-language reasoning (think) with tool use (act) and result inspection (observe). "Motivated by ReAct"
- Reflexion: A method where the LLM reflects on past actions/outcomes to refine future plans and improve problem-solving. "Variants such as Plan-and-Execute \citep{wang2023plan}, Reflexion \citep{shinn2023reflexion}, and Graph-of-Thought \citep{besta2024graph} have shown that LLMs can decompose complex tasks into sequences of actions and adapt plans via feedback."
- textualization: Encoding graphs as text (e.g., adjacency lists or narratives) so LLMs can process them with prompts. "Textualization and prompting of graphs."
- think–act–observe loop: An iterative cycle where the LLM reasons, issues an action, and incorporates the observed result before continuing. "we frame node classification as an iterative think--act--observe loop."
- token budget: The available number of tokens (context size) for a prompt; exceeding it limits how much graph/context can be included. "prompting quickly exhausts the token budget."
- tool-calling: Allowing an LLM to invoke external tools/APIs during reasoning to retrieve or compute structured information. "tool-calling and ReAct-style paradigms"
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases and workflows derived from the paper’s findings on LLM–graph interaction modes—especially the superiority and robustness of Graph-as-Code—mapped to sectors with specific tools and dependencies.
- Finance (fraud and AML)
- Use case: Early risk scoring and alert triage on transaction/account graphs with rich textual metadata (descriptions, notes, device fingerprints).
- Workflow/product: A Graph-as-Code risk analyst that iteratively writes and executes compact queries (e.g., neighbor exploration, label anchoring, feature summarization) to classify suspicious accounts and prioritize reviews.
- Why now: Graph-as-Code is most effective on long-text, high-degree graphs and remains robust when labels or edges are sparse or noisy.
- Dependencies/assumptions: Access to labeled exemplars, secure code execution sandboxing, graph DB integration (e.g., Neo4j/TigerGraph), governance for PII and audit logs, a reasoning-capable LLM.
- E-commerce (recommendations, catalog integrity, trust & safety)
- Use case: Product categorization, counterfeit detection, seller risk classification using product titles, descriptions, and review graphs.
- Workflow/product: A Catalog Classifier SDK that auto-selects Graph-as-Code for high-degree categories or long descriptions, falls back to prompting for short-text, low-degree niches.
- Why now: Demonstrated gains where prompting hits token limits; heterophily support helps in diverse cross-category link graphs.
- Dependencies/assumptions: Clean product graph (stable IDs), descriptive text available, cost controls for LLM+execution loops, compliance for marketplace moderation.
- Social media (moderation, bot detection, community assignment)
- Use case: Classify accounts into risk buckets (spam, coordinated inauthentic behavior) or topics, leveraging follower/interaction graphs and profile text.
- Workflow/product: A Moderation Agent using Graph-as-Code to compose structural and textual signals and adapt to heterophilic neighborhoods.
- Dependencies/assumptions: Policy guardrails, red-teaming and rate limits for agentic loops, incident response integration.
- Search and information retrieval (web, knowledge bases)
- Use case: Website/page topic classification on web-link networks; wiki or KB curation with long page text and diverse link structures.
- Workflow/product: A Link-Graph Classifier that runs programmatic neighborhood sampling and feature aggregation to avoid token blowups, with audit trails for editorial oversight.
- Dependencies/assumptions: Access to page text and link graphs; deterministic retrieval APIs; editorial workflows for human-in-the-loop validation.
- Cybersecurity (entity and event classification)
- Use case: Classify domains/IPs/process trees in attack graphs; prioritize alerts using event and artifact text.
- Workflow/product: A Threat Graph-as-Code playbook that queries structural motifs and merges textual IOC/context to assign risk labels.
- Dependencies/assumptions: Timely telemetry ingestion, secure sandboxing, latency constraints in SOC pipelines.
- Enterprise knowledge management (IT, customer support, operations)
- Use case: Ticket routing and document tagging in enterprise knowledge graphs (issues, owners, services), combining short titles and longer descriptions.
- Workflow/product: A Routing Agent built on a standardized Graph-as-Code DataFrame API; exposes audit-friendly traces of decisions for compliance.
- Dependencies/assumptions: Connectors to internal graph stores, RBAC, observability to measure accuracy/coverage.
- Healthcare (risk stratification, care-pathway classification)
- Use case: Classify patients/episodes in encounter graphs using clinician notes, medication/visit relationships.
- Workflow/product: A Privacy-aware Graph-as-Code clinical classifier that selectively retrieves essential notes and neighbor context to fit token budgets.
- Dependencies/assumptions: Strong privacy controls and de-identification, clinical validation, labeled cohorts, domain-tuned LLM.
- Education (MOOCs, learning platforms)
- Use case: Classify questions/resources in course knowledge graphs; personalize recommendations with heterogeneous links and long resource text.
- Workflow/product: A Learning Graph Agent that balances feature-rich text and structure using Graph-as-Code; instructors get transparent program traces.
- Dependencies/assumptions: Curated resource graphs, explainability requirements, platform integration.
- Engineering/MLOps orchestration
- Use case: Token-budget-aware mode selection to stabilize accuracy and cost across datasets.
- Workflow/product: An Auto-Mode Selector that uses simple heuristics (feature length, average degree, homophily) to choose between prompting, tool-use, and Graph-as-Code per query.
- Dependencies/assumptions: Telemetry on graph stats; policy-based routing; cost and latency SLAs.
- Academia and R&D
- Use case: Reproduce the paper’s axes-of-variability evaluation and dependency heatmaps (features/labels/edges) when choosing an LLM–graph strategy for a new dataset.
- Workflow/product: Open-source evaluation harness and heatmap generator to probe reliance on features, structure, labels.
- Dependencies/assumptions: Standardized data loaders and consistent label splits; model registry for reasoning/non-reasoning variants.
- Daily life (personal knowledge management)
- Use case: Classify contacts, notes, and emails in a personal relationship/knowledge graph with mixed short/long text.
- Workflow/product: A lightweight Graph-as-Code add-in that runs local programmatic queries for foldering/priority.
- Dependencies/assumptions: Local-first execution, privacy safeguards, small-model support.
Long-Term Applications
Below are higher-impact applications that benefit from scaling, standardization, or further research before broad deployment.
- Standardized Graph-as-Code API/DSL across data platforms
- Vision: A vendor-neutral, typed DataFrame/graph DSL for LLM agents (query, transform, aggregate, label), with certified safety policies.
- Emergent tools: Language bindings for Neo4j, TigerGraph, JanusGraph; integration with LangChain/Semantic Kernel; audit plugins.
- Dependencies/assumptions: Community consensus, secure code execution standards, reproducibility guarantees.
- Self-teaching agents for graph reasoning
- Vision: Toolformer-style models that learn to invoke graph APIs and generate efficient programs via synthetic data and reflexive feedback.
- Emergent tools: “LLM Graph Analyst” that improves planning/execution over time and adapts to dataset regimes (homophilic/heterophilic).
- Dependencies/assumptions: High-quality pretraining corpora, evaluation suites for robustness, compute budgets for iterative fine-tuning.
- Real-time streaming graph inference
- Vision: Deploy Graph-as-Code agents on streaming transaction, social, or telemetry graphs for low-latency classification and anomaly detection.
- Emergent tools: Event-driven orchestration with stateful code snippets, cost-aware scheduling, and sandbox acceleration.
- Dependencies/assumptions: Efficient runtime, memory isolation, observability, fault tolerance.
- Privacy-preserving and federated Graph-as-Code
- Vision: Federated agents operating over distributed graph partitions (finance, healthcare), with TEEs or secure multi-party computation.
- Emergent tools: Federated query planner, policy engine for sensitive fields, compliance-grade audit trails.
- Dependencies/assumptions: Secure hardware/software stacks, regulatory approvals, cross-institution agreements.
- Active learning and label curation loops
- Vision: Agents that quantify uncertainty, selectively request labels, and adapt reliance across structure/features/labels for maximal gain.
- Emergent tools: Human-in-the-loop review portals, budget-aware labeling strategies, automated drift detection.
- Dependencies/assumptions: Annotation platforms, well-defined acquisition functions, feedback governance.
- Cross-task expansion beyond node classification
- Vision: Extend Graph-as-Code to link prediction, community detection, root-cause analysis, and explanation generation on knowledge graphs.
- Emergent tools: Program libraries for motifs, paths, and structural patterns; explainability modules tied to executed code.
- Dependencies/assumptions: Task-specific metrics, large-scale benchmarks, safety checks for agentic analyses.
- Domain-specific graph reasoning models (healthcare, finance, cybersecurity)
- Vision: Specialized LLMs/agents tuned for domain ontologies, terminology, and decision constraints, improving accuracy and reliability.
- Emergent tools: Domain adapters, terminology-aware retrieval, policy-aligned decision traces.
- Dependencies/assumptions: Access to domain data, privacy and compliance, expert validation.
- Regulatory and compliance analytics
- Vision: Adopt Graph-as-Code’s auditable traces in regulated environments (KYC/AML, healthcare), standardizing explainable graph decisions.
- Emergent tools: Compliance dashboards, standardized log formats, auditor toolkits for replay and verification.
- Dependencies/assumptions: Regulator acceptance, robust logging infrastructure, standardized evidence schemas.
- Benchmarks and governance for heterophily/long-context robustness
- Vision: Community benchmarks that stress-test heterophilic graphs and long-text contexts, encouraging methods that avoid token-budget brittleness.
- Emergent tools: Heatmap-based diagnostic suites, dataset cards with homophily/degree/feature-length metadata.
- Dependencies/assumptions: Open datasets with licenses, shared metrics, reproducible splits.
- Cost-aware, dynamic orchestration frameworks
- Vision: Production frameworks that switch modes (prompt, tool, code) in real time based on graph stats, token budgets, and SLA constraints.
- Emergent tools: Routing policies, simulators for cost/latency/accuracy trade-offs, guardrails for agent loops.
- Dependencies/assumptions: Strong telemetry, policy engines, platform support across LLM providers.
Notes on cross-cutting assumptions and dependencies
- Data quality and availability: Success depends on access to meaningful textual features and at least some labeled nodes; sparse or low-quality text reduces gains.
- Token budgets and model capability: Graph-as-Code advantages grow with long text or high degree; if future LLMs reliably exploit very long contexts, prompting may recover some ground, though programmatic access remains efficient and auditable.
- Security and safety: Agentic code execution requires sandboxing, timeouts, allowlists, and audit trails to prevent unsafe operations and enable compliance.
- Integration and interoperability: Requires connectors to graph databases/engines and standardized IDs/APIs; reproducibility and determinism are essential.
- Cost and latency: Iterative think–act–observe loops introduce overhead; orchestration should be cost-aware and adhere to application SLAs.
Collections
Sign up for free to add this paper to one or more collections.