- The paper introduces LMMs-Eval, a benchmark suite that standardizes evaluation protocols to address the trade-offs between wide coverage, low cost, and zero contamination.
- It details LMMs-Eval Lite, which utilizes a k-Center subset selection strategy to deliver quick yet reliable performance insights.
- It presents LiveBench, a dynamic evaluation pipeline that mitigates data contamination while integrating human judgments and machine metrics for real-world relevance.
LMMs-Eval: A Comprehensive Evaluation Framework for Large Multimodal Models
Introduction
The paper "LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models" addresses the challenges of evaluating Large Multimodal Models (LMMs). It introduces the LMMs-Eval, a benchmark suite designed for comprehensive and reproducible evaluation of such models across 50+ tasks and 10+ models. Despite advancements in foundational models, the paper highlights a persistent trilemma in LMM evaluation — achieving wide coverage, low cost, and zero contamination simultaneously. The authors propose LMMs-Eval Lite and LiveBench to navigate these constraints effectively.
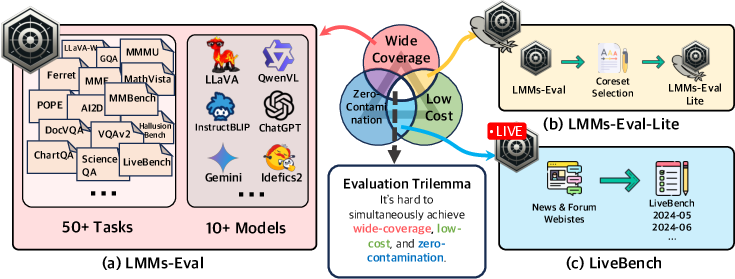
Figure 1: To best navigate the trilemma in LMM evaluation benchmarking, we introduce LMMs-Eval, LMMs-Eval Lite, and LiveBench.
LMMs-Eval: A Unified Benchmarking Suite
Standardized Framework
The LMMs-Eval suite aims to unify evaluation protocols, thus reducing the inefficiencies associated with disparate model evaluation frameworks. By replicating the design of evaluation frameworks like lm-eval-harness, it standardizes data preprocessing, model inference, and evaluation score calculations, thereby facilitating transparent and reproducible evaluation practices.
Scaling Evaluations
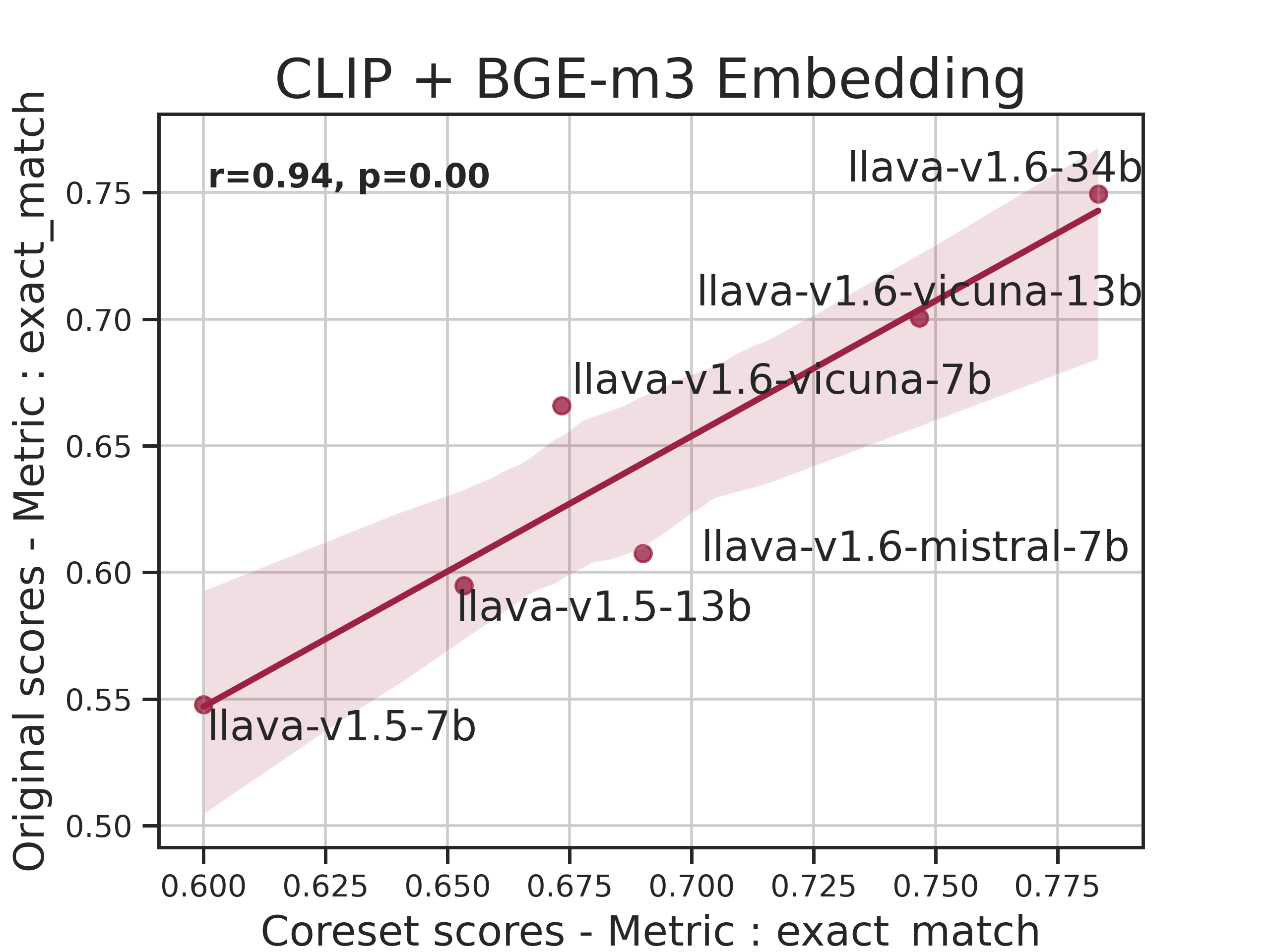
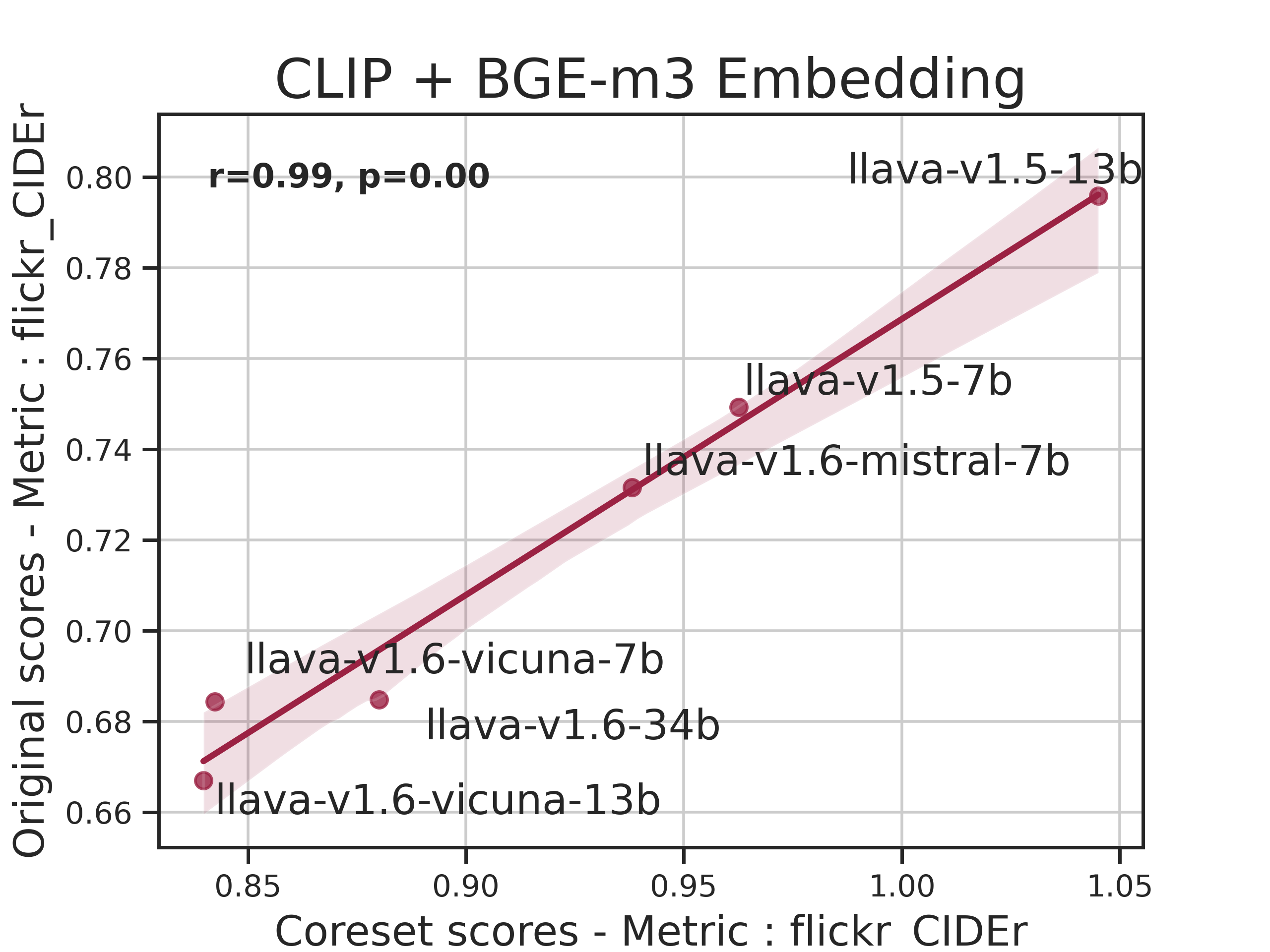
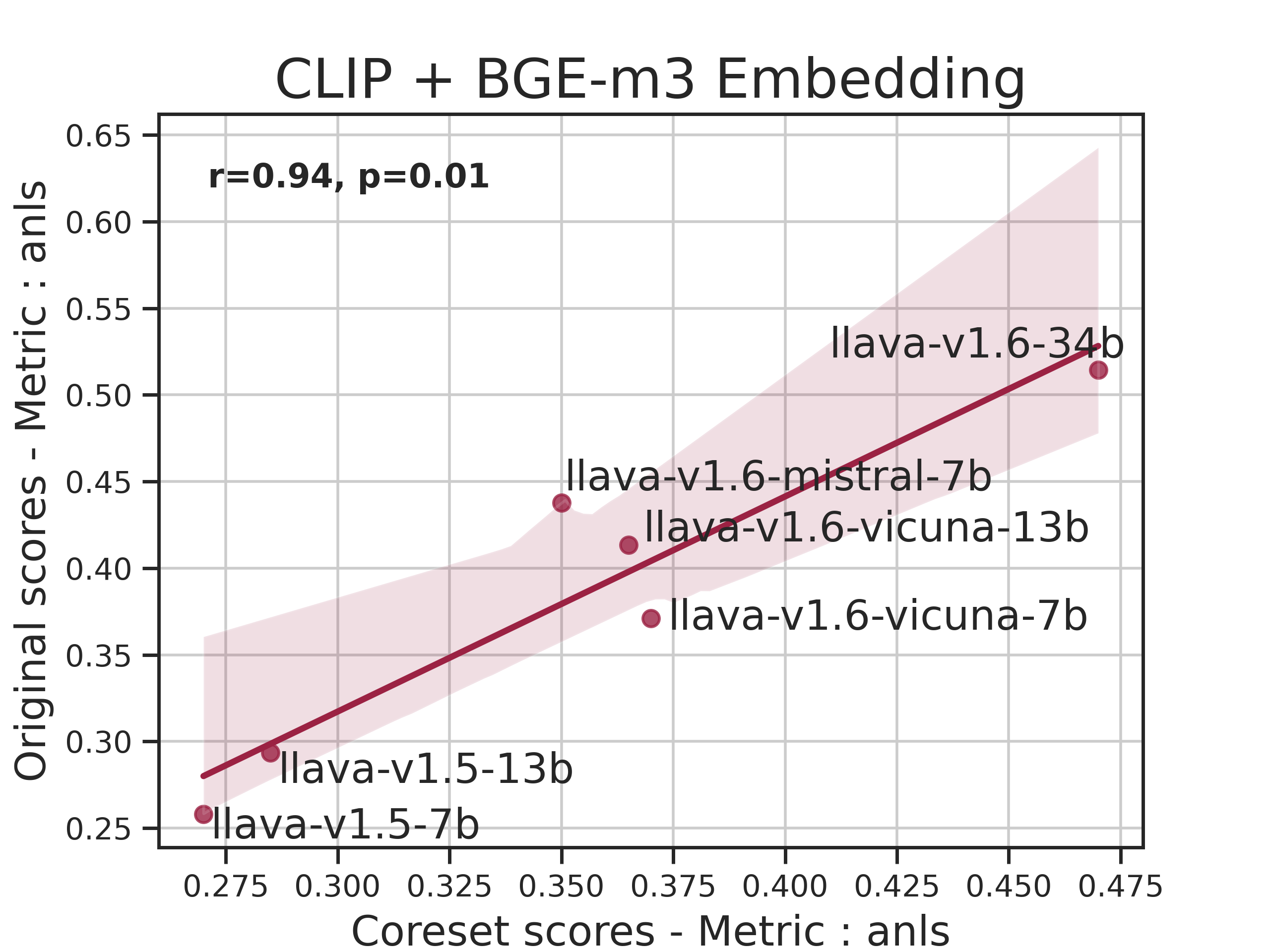
Figure 2: Correlation Graph between scores for our lite set and original scores
The framework supports a wide array of models and datasets, enabling comprehensive evaluation across multiple dimensions. The pursuit of large-scale evaluation highlights the significance of the evaluation trilemma — asserting that only a trade-off can be achieved between wide coverage, low cost, and zero contamination.
LMMs-Eval Lite: Efficient and Broad Evaluation
Lite Benchmark Set
LMMs-Eval Lite selects a representative subset of the original dataset to provide quick and reliable insights during model development. Utilizing a variant of the k-Center problem, the Lite version identifies a data subset such that the evaluated scores remain consistent with those derived from the full dataset.
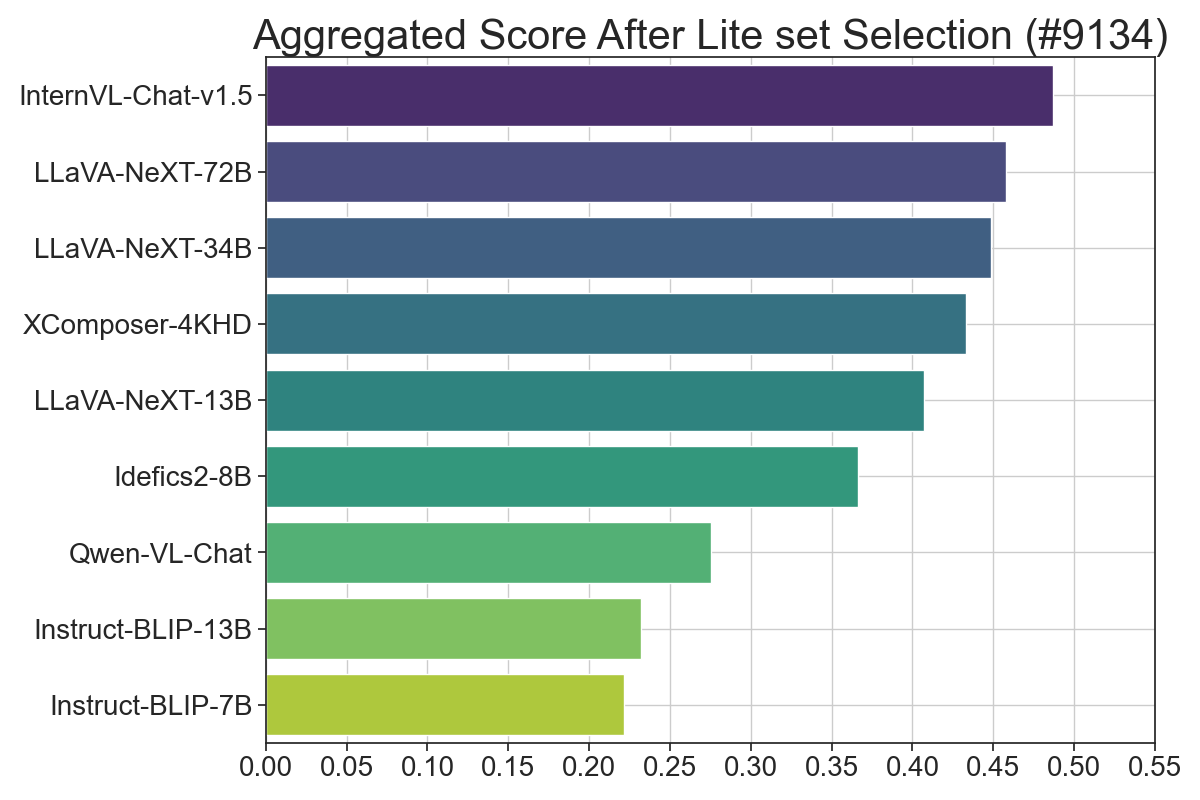
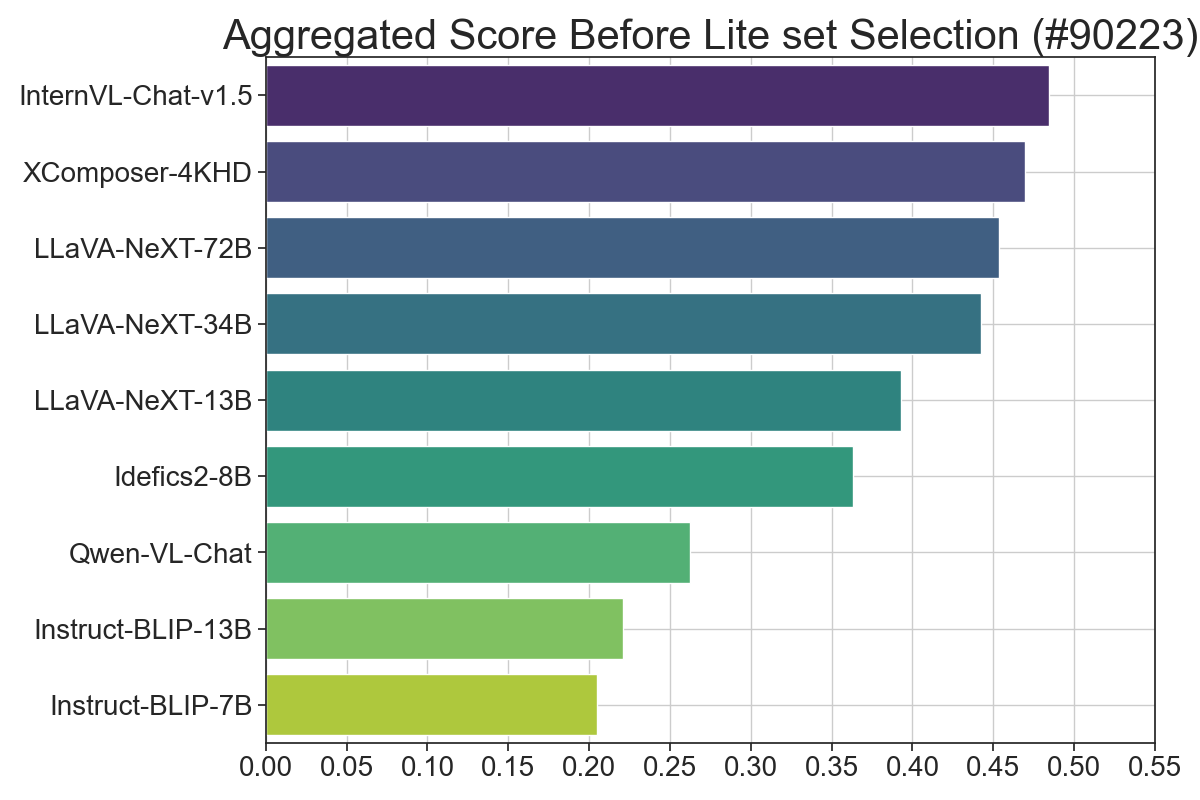
Figure 3: Results of LMMs-Eval Lite across different models. The x-axis represents the weighted average percentage of scores across all datasets.
Aggregated Score Strategy
To yield an overarching signal during model iterations, LMMs-Eval Lite employs a normalization technique. Scores from each dataset are aggregated post-normalization, offering a unified metric indicative of model performance. However, it's emphasized that this metric serves primarily as a guide during model iterations rather than a definitive performance comparison across families.
LiveBench: Dynamic Evaluation for Real-World Relevance
Data Contamination Challenges
The assimilation of datasets during LMM training poses risks of data contamination, as models unknowingly leverage pre-seen benchmark data, thereby skewing results. A comprehensive analysis indicates significant contamination in widely used datasets such as ChartQA, VQAv2, and COCO2014.
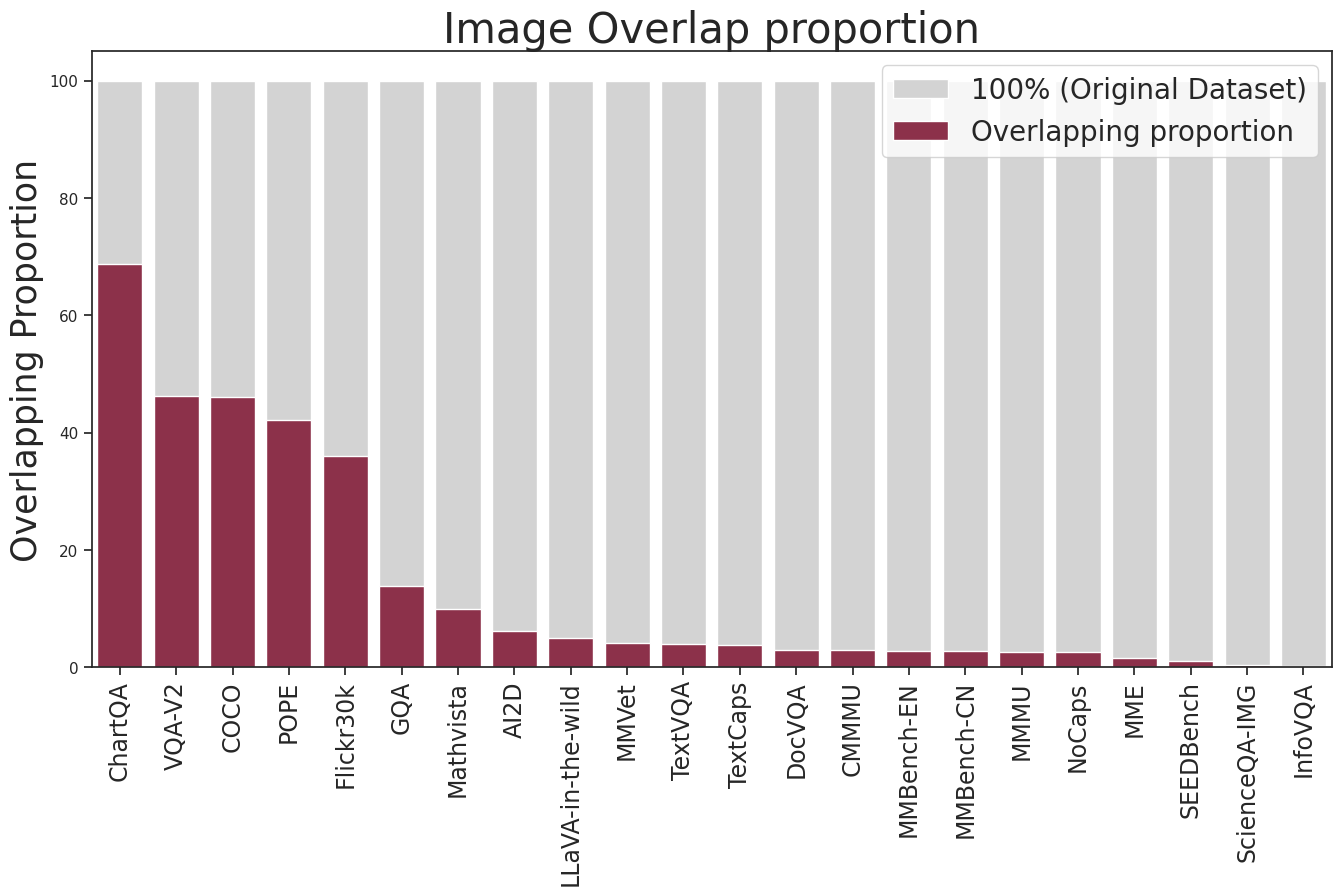
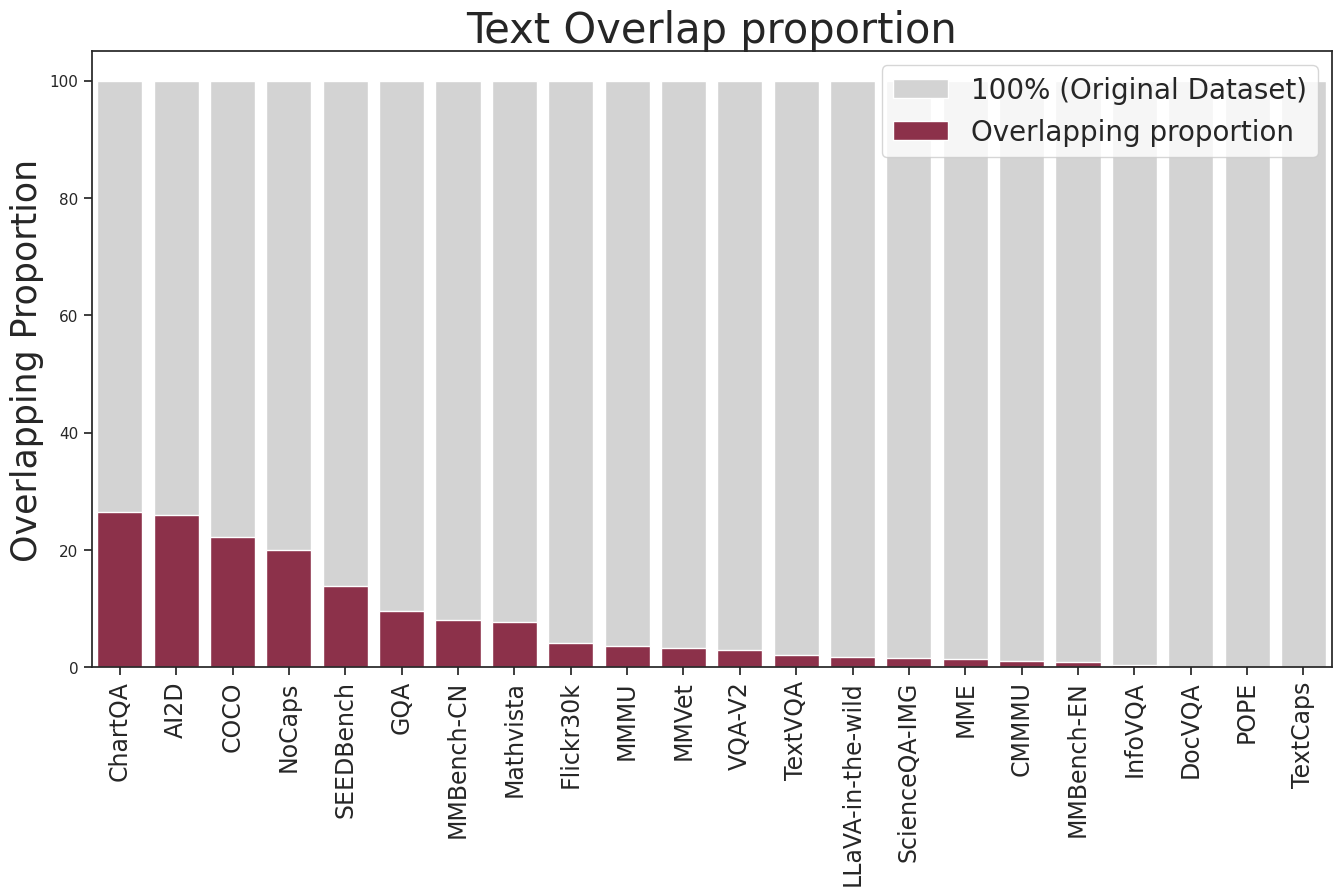
Figure 4: Contamination analysis in current evaluation benchmarks and LLaVA's training data.
Live Evaluation Pipeline
LiveBench introduces a real-time evaluation methodology by curating a dynamic dataset from current news and forum websites. It emphasizes the zero-contamination objective while being resource-efficient. The evaluation metrics incorporate human judgments and diverse machine models, ensuring a holistic assessment of LMM generalization capabilities on contemporary data.
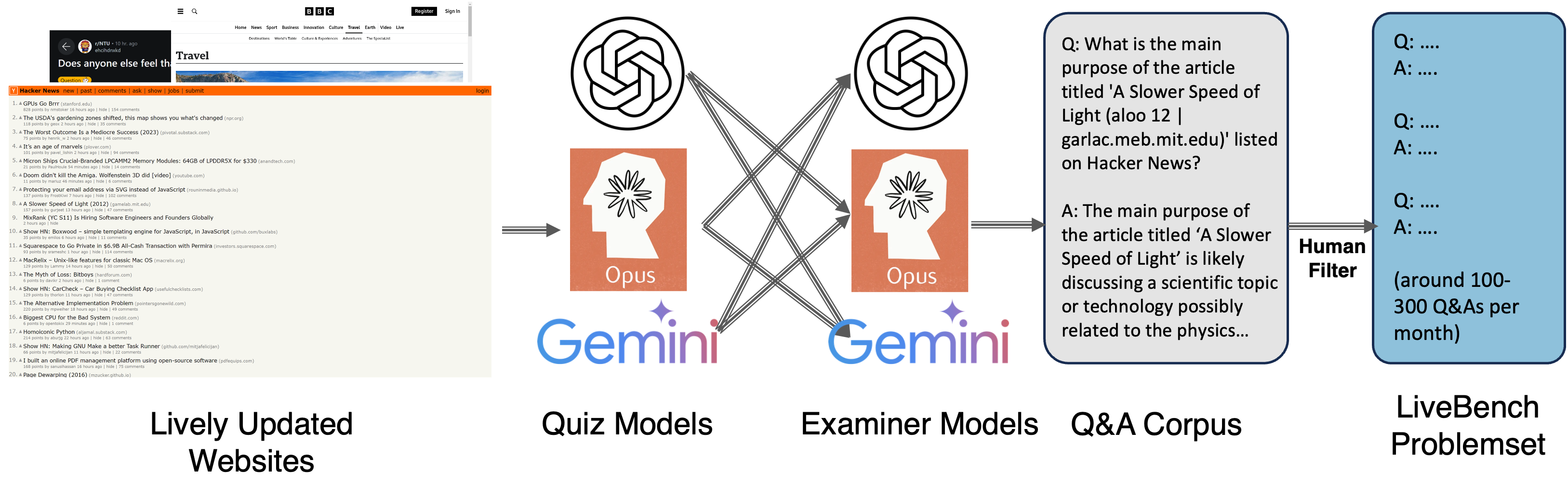
Figure 5: Overview pipeline for LiveBench.
Conclusion
The paper presents a structured approach to tackling the complexities of evaluating Large Multimodal Models through LMMs-Eval. The suite's components — LMMs-Eval, its Lite version, and LiveBench — cater to various aspects of the evaluation trilemma, offering scalable, cost-effective, and currently relevant benchmarks. Future work is anticipated to explore dissolving the limitations posed by evaluation constraints and data contamination, enhancing the fidelity and reliability of LMM assessments.