PRISM: Transforming AI Reasoning with Step-Level Correctness
This presentation explores PRISM, a breakthrough framework that addresses the critical bottleneck in deep reasoning systems: population enhancement. By integrating Process Reward Models to provide step-level correctness signals, PRISM transforms iterative refinement from random exploration into principled error correction. We examine how PRISM achieves state-of-the-art accuracy on rigorous mathematics and science benchmarks while maintaining compute efficiency, demonstrate its robust directional correction dynamics, and reveal how it enables smaller models to match the performance of much larger systems.Script
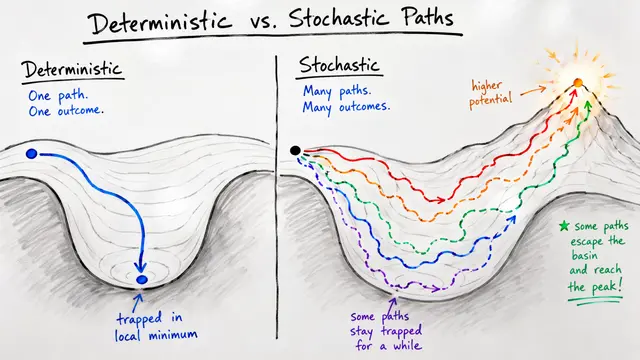
Most deep reasoning systems share a hidden weakness: they can't tell when they're making progress. Refinement becomes a random walk, and adding more compute often just changes answers rather than improving them. PRISM breaks this cycle by embedding step-level correctness signals throughout inference.
The researchers identified population enhancement as the critical failure point in DeepThink architectures. Without reliable correctness feedback, systems can't distinguish refinement from degradation. Correct but infrequent reasoning paths get diluted by majority consensus, and additional inference compute primarily churns through alternatives rather than climbing toward truth.
PRISM replaces this random exploration with a principled optimization strategy.
PRISM treats candidate reasoning traces as particles in an energy landscape shaped by Process Reward Model scores. During each refinement cycle, scoring identifies promising trajectories, resampling reallocates probability mass toward high-quality candidates, and stochastic refinement proposes corrections that are accepted based on score improvements. Solution aggregation shifts from frequency-based voting to PRM-score voting, ensuring correctness wins even when it's the minority view.
This NetFlip analysis reveals PRISM's most striking property: genuine directional error correction. The tall positive bars show that PRISM consistently converts incorrect reasoning into correct solutions as refinement deepens. Competing methods hover near zero or go negative, meaning their updates are essentially coin flips that degrade correct answers as often as they fix wrong ones. PRISM's Process Reward Model transforms refinement from a stochastic rewrite into a climb toward correctness.
On rigorous mathematics and science benchmarks, PRISM achieves state-of-the-art accuracy while consistently lying on the Pareto frontier for compute efficiency. A 20 billion parameter model using PRISM matches or exceeds the performance of 120 billion parameter baselines. The framework delivers its largest improvements to weaker models, enabling them to punch dramatically above their weight class.
PRISM demonstrates that explicit step-level correctness signals are foundational for scalable reasoning. By making refinement directional rather than exploratory, it transforms inference-time compute into genuine progress. Visit EmergentMind.com to explore the full paper and create your own research videos.