PatchAlign3D: Local Feature Alignment for Dense 3D Shape Understanding
This presentation explores PatchAlign3D, a novel approach that transforms how we understand 3D shapes at a local, part-level detail. By directly aligning 3D patch features with semantic descriptions through a two-stage training process, the method eliminates costly multi-view rendering while achieving competitive zero-shot segmentation performance. We'll examine the core innovation, its training strategy, and why this streamlined approach matters for practical 3D understanding tasks.Script
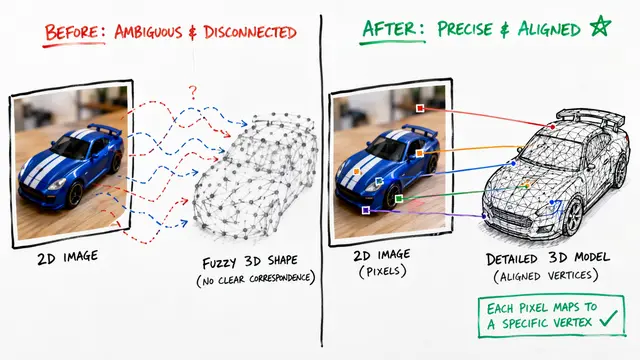
Most 3D models excel at recognizing entire objects but struggle when you ask them to identify specific parts like a chair's armrest or a lamp's shade. The researchers behind PatchAlign3D asked a fundamental question: why do we need expensive multi-view rendering when the 3D geometry already contains the information we need?
Current approaches treat 3D shapes like photographs, rendering them from many angles to extract features. This detour through 2D space works but adds complexity and computation time that practical applications in robotics and augmented reality cannot afford.
PatchAlign3D takes a different path by working directly with 3D point cloud patches.
The method works in two coordinated stages. First, it distills knowledge from proven 2D vision models into a 3D transformer that processes point cloud patches. Then it aligns these geometric features with language descriptions of object parts, teaching the model to recognize that a cluster of points corresponds to concepts like handle or base.
What makes this work is the patch-level tokenization strategy. By treating local regions of the 3D shape as distinct tokens, the transformer can learn fine-grained features while the multi-positive contrastive approach handles the reality that part boundaries in training data are often imprecise.
The proof arrives in the benchmarks.
Tested on five major benchmarks, PatchAlign3D consistently beats methods that rely on multi-view rendering. The accuracy gains matter, but the speed improvement transforms what's practical: a single forward pass replaces dozens of rendered views.
The researchers acknowledge real limitations. Noisy part labels in existing datasets constrain what the model can learn, and the fixed patching strategy doesn't adapt to different point cloud characteristics. But the architecture is designed for evolution: adaptive patches, larger training sets, and fusion with broader 3D foundation models all represent natural next steps.
For applications that operate in three dimensions—robotic manipulation, augmented reality interfaces, automated 3D modeling—this direct approach removes a fundamental bottleneck. Instead of converting 3D data into 2D images and back, the model reasons in the native geometry of the problem.
PatchAlign3D proves that the path to understanding 3D shapes doesn't need to pass through 2D space. Visit EmergentMind.com to explore more cutting-edge research and create your own videos.