Memory Bank: Claim–Evidence Graph
This presentation introduces the Memory Bank as a formally structured, persistent graph architecture that explicitly encodes relationships between claims and evidence. We explore how this paradigm transforms fact-checking, agent memory, and retrieval systems by making evidence traceability, attribution scoring, and multi-hop reasoning both transparent and auditable. Through concrete examples from state-of-the-art systems, we reveal how bipartite graph abstractions solve critical explainability and verification challenges.Script
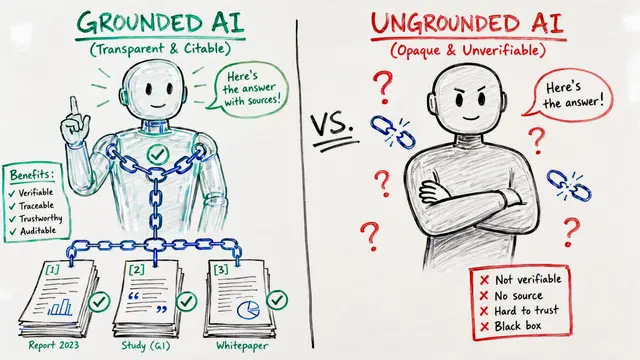
Every claim an AI system makes should trace back to explicit evidence. Yet most systems treat verification as a black box, hiding the exact relationships between what they assert and what supports it. The Memory Bank as a Claim–Evidence Graph makes these connections mathematically precise, persistent, and auditable.
The foundation is a directed graph where claims and evidence live as separate node types. Each edge carries a weight and a semantic label, whether that evidence supports, contradicts, or remains ambiguous about the claim. Advanced systems like Hindsight layer in belief nodes, temporal links, and causal relationships, creating a rich multiplex structure that captures not just what is claimed, but how confidence evolves over time.
How do we actually build one of these memory banks from raw text?
ClaimVer's pipeline is canonical. First, an Large Language Model extracts atomic claims from the source text. Then, for every claim, a retrieval module searches a knowledge graph or document corpus for candidate evidence. Finally, verification assigns categorical labels—attributable, extrapolatory, contradictory—and computes a match score that combines semantic similarity with entity overlap. These scores aggregate into a global Knowledge Graph Attribution Score, asymmetrically penalizing negative evidence to reflect epistemic caution.
On the left, attribution metrics quantify evidence strength. ClaimVer's approach multiplies claim and match scores into a global aggregate, while ADORE enforces coverage thresholds per report section, stopping retrieval only when every section meets a minimum evidence density. On the right, persistent indexing makes the memory bank auditable. Every evidence item, Large Language Model rationale, entity resolution, and belief update is logged and queryable, so downstream systems can trace any claim back to its exact support set with timestamps and confidence annotations.
These structured memory banks solve real problems. In fact-checking, systems like ClaimVer and VeGraph make every verification step transparent, allowing human auditors to inspect exactly which evidence justified each label. In enterprise settings, ADORE coordinates multiple specialized agents around a shared memory bank, enforcing systematic evidence completeness under document overflow. And in agentic systems, Hindsight demonstrates that graph-based memory provides epistemic clarity and belief revision capabilities that flat vector stores simply cannot match, yielding measurably higher accuracy over long task horizons.
The Memory Bank as a Claim–Evidence Graph transforms verification from an opaque judgment into a mathematically precise, auditable structure. Every claim, every piece of evidence, and every reasoning step becomes traceable, persistent, and queryable. Visit EmergentMind.com to explore these architectures further and create your own AI-generated presentations.