Masked Depth Modeling for Spatial Perception
An overview of a novel approach that transforms missing depth sensor data into a self-supervised learning signal to achieve dense, metric-scale geometry for robotics.Script
What happens when a robot tries to pick up a glass of water, but its sensors tell it the space is completely empty? This paper addresses critical blindness in spatial perception by turning sensor errors into a learning advantage.
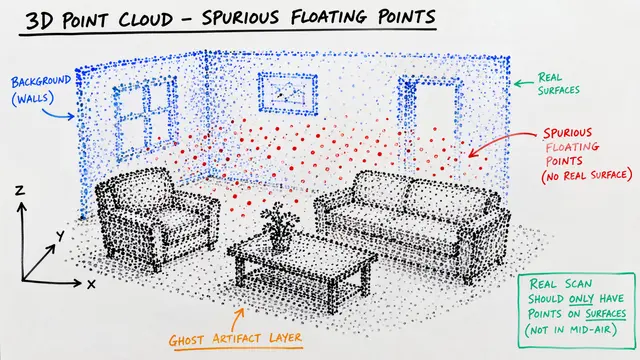
Standard depth cameras struggle with transparency and reflectivity, often returning maps riddled with holes and invalid pixels. This corruption makes it nearly impossible for autonomous systems to reliably interact with everyday objects like windows or polished metal.
Instead of treating these missing regions as useless noise to be discarded, the researchers reframe them as natural masking within a learning problem. They hypothesize that the missing data itself acts as a guide, forcing the model to learn geometry from visual context.
The core method, called Masked Depth Modeling, processes aligned image and depth patches simultaneously using a Vision Transformer. By learning to predict the missing metric depth from the remaining visible context, the model develops a robust understanding of 3D space.
This figure demonstrates the model's capability in a challenging aquarium tunnel, where raw sensors return black voids due to the glass. The system successfully reconstructs the missing surfaces, providing temporally consistent and dense depth maps even on transparent materials.
By successfully converting sensor failure into a supervision signal, this work unlocks new capabilities for robotic manipulation of transparent objects. For more insights on spatial perception, visit EmergentMind.com.