The Y-Combinator for LLMs: Solving Long-Context Rot with Lambda-Calculus
This presentation explores a paradigm shift in long-context reasoning for language models. Instead of relying on unpredictable code generation, lambda-RLM introduces a typed functional runtime grounded in lambda-calculus, where recursion is expressed as a fixed-point combinator. Neural inference is strictly confined to bounded leaf subproblems while all orchestration occurs through deterministic combinators. This architectural separation delivers formal guarantees on termination and complexity while achieving dramatic improvements in accuracy (up to 21.9 points) and speed (4.1x faster) across diverse long-context tasks.Script
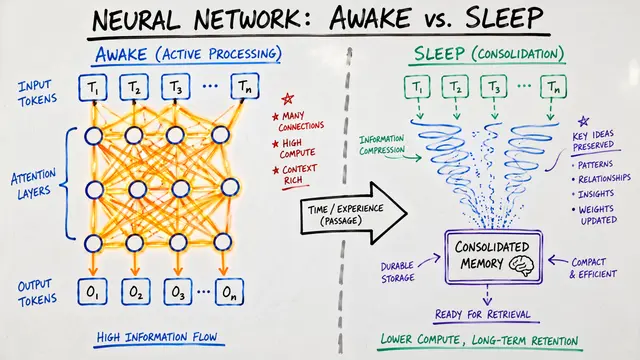
Language models struggle with long contexts, producing unpredictable execution traces, non-terminating loops, and malformed outputs when processing large codebases or documents. The researchers behind lambda-RLM recognized that the root problem wasn't the models themselves, but the chaotic way we orchestrate their reasoning.
Traditional recursive language models ask the model to both solve subproblems and decide how to divide them, creating a dangerous coupling. When a model generates its own control flow, you get unpredictability at every recursive step. Lambda-RLM breaks this coupling by delegating all orchestration to a library of deterministic combinators rooted in lambda-calculus.
Instead of stochastic control, the authors built a functional runtime where recursion becomes formally analyzable.
The paradigm shift is architectural. On the left, models synthesize their own recursion with no formal properties. On the right, lambda-RLM uses typed combinators where the Y-combinator handles recursion, and deterministic operators like Split, Map, and Reduce compose the solution. The model becomes a bounded oracle invoked only at leaf subproblems, never touching control flow.
Because control flow is pre-decided by a planner, you get mathematical guarantees. Termination is proven by construction since problem size always decreases. The number of model calls has a closed-form bound, and there's even an optimal partition size: k equals 2 minimizes cost under token-based pricing models.
The empirical results validate the theory decisively. Lambda-RLM wins in 81 percent of configurations across nine model variants and four long-context tasks. Weak models see accuracy jumps exceeding 21 points, while latency drops by more than 4x. For pairwise reasoning tasks with quadratic complexity, the gains reach 28.6 points with over 6x speedup. The gap widens precisely where structural complexity increases, exactly as the theory predicts.
Lambda-RLM proves that separating neural understanding from symbolic orchestration isn't just elegant, it's essential for reliable long-context reasoning. When recursion becomes a formally analyzable program instead of an emergent accident, we finally get the guarantees production systems demand. Visit EmergentMind.com to explore this work further and create your own research videos.