Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning
This presentation explores Group Filtered Policy Optimization, a novel training method that solves a critical problem in reinforcement learning for large language models: response length inflation. By sampling more candidate responses during training and selectively learning only from the most concise ones, GFPO achieves up to 85% reduction in verbosity while maintaining state-of-the-art accuracy on complex reasoning tasks. The talk demonstrates how strategically allocating training compute can yield lasting improvements in inference efficiency, challenging the assumption that longer reasoning chains are necessary for high performance.Script
Reinforcement learning has pushed language models to new heights on reasoning tasks, but there's a hidden cost: the models won't stop talking. Longer responses don't mean better answers, yet current training methods inadvertently reward verbosity, creating a bloat problem that makes deployment expensive and inefficient.
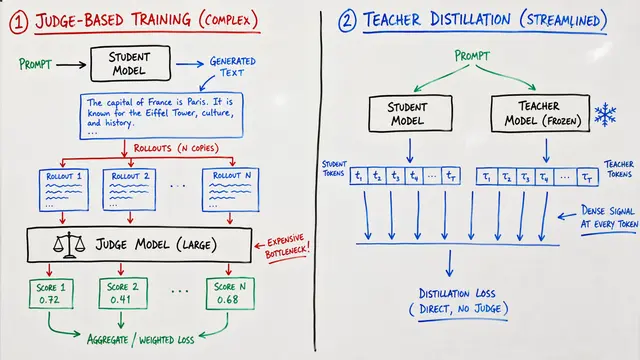
The authors discovered that reinforcement learning from verifier rewards creates responses that balloon in length without corresponding gains in correctness. Existing fixes like token-level loss normalization miss the mark because they penalize verbose failures but still incentivize verbose successes.
What if we could teach models to be concise by showing them only their most efficient attempts?
Group Filtered Policy Optimization extends standard policy gradient methods with a deceptively simple idea: generate more responses than you need, then train only on the shortest or most token-efficient ones. This selective learning acts as implicit reward shaping, steering the policy toward brevity without complex reward engineering.
Where standard training treats all correct responses equally, GFPO creates a curriculum of efficiency. By increasing the sampling group size and decreasing the number of retained responses, the method pushes the model toward solutions that achieve accuracy without excess verbosity.
The empirical results are remarkable. Token Efficiency GFPO slashes response length by up to 85% while matching baseline accuracy across AIME, GPQA, and Omni-MATH benchmarks. Statistical tests confirm these length reductions come with no significant performance penalty.
The method's effectiveness holds across all difficulty levels. On easy questions, Token Efficiency GFPO even beats the original supervised baseline for brevity. On very hard problems, Adaptive Difficulty GFPO delivers the largest cuts by dynamically adjusting how many responses to learn from based on question difficulty.
Trace analysis reveals where GFPO makes its cuts: primarily in the solution and verification phases, where models tend to over-explain or repeat themselves. The method also generalizes beyond training data, actually improving both efficiency and accuracy on out-of-distribution coding tasks.
GFPO requires more compute during training because it samples larger groups of responses. But this upfront investment pays ongoing dividends: every inference call benefits from the learned brevity, making the method economically viable for production deployments where inference cost dominates.
Group Filtered Policy Optimization proves that strategic training-time compute can unlock lasting efficiency gains, challenging the assumption that more reasoning always means more tokens. Visit EmergentMind.com to explore this paper further and create your own research video presentations.