Generalization at the Edge of Stability: An Attractor-Centric Analysis
This presentation explores a groundbreaking framework for understanding how modern neural networks generalize when trained with large learning rates in the Edge of Stability regime. Moving beyond traditional point-wise analysis of loss minima, the authors model stochastic optimization as a random dynamical system with chaotic trajectories and introduce Sharpness Dimension—a Lyapunov-inspired measure that quantifies the effective dimensionality of the attractor governing generalization. Through rigorous theory and extensive experiments on MLPs, transformers, and grokking phenomena, they demonstrate that this spectral complexity measure outperforms classical sharpness metrics and provides new insights into why overparameterized networks generalize despite operating in inherently unstable regimes.Script
When you train a neural network with a large learning rate, something strange happens. The optimization doesn't settle into a nice stable minimum—instead, it enters a chaotic regime called the Edge of Stability, where trajectories spiral unpredictably and the loss landscape feels more like a turbulent attractor than a fixed point.
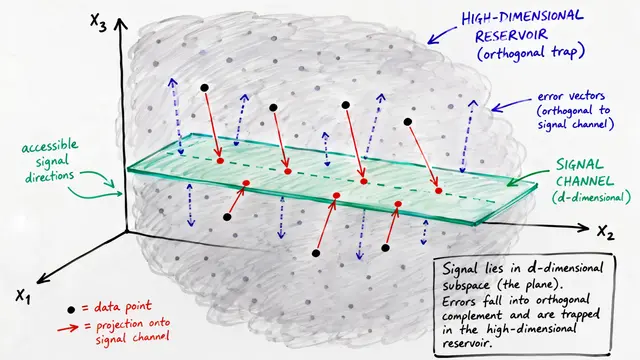
The authors reconceive generalization through the lens of random dynamical systems. Rather than analyzing individual minima, they model the entire solution set as a noise-conditioned pullback attractor—a geometric object whose intrinsic structure governs how well the network will generalize.
They introduce Sharpness Dimension, a spectral complexity measure inspired by Lyapunov theory. It aggregates expansion and contraction rates across the Hessian spectrum to compute the effective dimensionality of the attractor—capturing which directions expand under the optimizer's dynamics and which contract.
When they tested Sharpness Dimension on grokking tasks, where networks suddenly leap from memorization to generalization, the measure tracked these abrupt phase transitions with remarkable precision. Classical sharpness metrics missed the transition entirely, but Sharpness Dimension dropped sharply exactly when test accuracy spiked.
Scaling to GPT-2 on WikiText, Sharpness Dimension consistently predicted generalization gaps across optimizers, learning rates, and batch sizes. Classical sharpness showed weak or even negative correlation, but Sharpness Dimension variants remained robustly predictive—evidence that the full Hessian spectrum, not just the top eigenvalue, controls generalization in chaotic regimes.
This attractor-centric framework reveals why overparameterized networks generalize: even when parameter count is astronomical, the attractor's Sharpness Dimension can be orders of magnitude smaller, capturing the true complexity of the learned solution. To explore the full paper and create your own video summaries of cutting-edge research, visit EmergentMind.com.