Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
Abstract: We present Seed2.0, a model series that takes a meaningful step toward solving complex, real-world tasks. Our approach begins with identifying users' genuine needs and constructing a reliable, forward-looking evaluation system by selecting and abstracting benchmarks grounded in these needs and in realistic, complex scenarios. Guided by this evaluation system, Seed2.0 targets two persistent challenges, long-tail knowledge and complex instruction following, substantially improving the model's reliability on intricate, long-horizon tasks. Beyond these, Seed2.0 delivers world-leading reasoning intelligence, visual understanding, and search capabilities that address the most common needs of a broad user base. Through extensive real-world use cases documented in this model card, we demonstrate that Seed2.0 begins to exhibit the ability to handle initial complex real-world tasks, delivering greater value to hundreds of millions of users.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to the “Seed2.0” paper
What is this paper about?
This paper introduces Seed2.0, a new family of AI models (like super-advanced chatbots) made by the Seed team. These models are designed to do more than answer single questions—they aim to act like helpful “agents” that can understand images and text, follow complicated instructions, write and fix code, learn from long documents, and complete real-world tasks from start to finish. The paper explains what Seed2.0 focuses on, how it’s tested, where it’s strong, where it still needs work, and why it’s useful in the real world.
What questions are the authors trying to answer?
The team tries to solve a few simple but important questions:
- How can an AI be more useful in everyday work, not just on tricky quiz questions?
- Can it understand pictures, charts, and videos as well as text?
- Can it follow complex, multi-step instructions reliably?
- Can it actually build or fix software with fewer mistakes and less back-and-forth?
- Can it stay helpful when reading long documents and handling specialized, rare facts?
- Can it do all this quickly and affordably so companies can use it at scale?
How did they study it?
Think of the team as building a new “toolkit” with three sizes of models—Seed2.0 Pro, Lite, and Mini—so people can pick the right balance of speed, cost, and ability.
They focused on four big design priorities:
- Robust visual and multimodal understanding: handling images, charts, scanned pages, and videos—not just text.
- Fast and flexible inference: “Inference” is the time you wait for an answer. They offer different sizes (Pro/Lite/Mini) to keep responses fast.
- Reliable complex instruction execution: following long, detailed, and picky instructions step by step without drifting off.
- Great coding assistance: helping with real software work, especially debugging and front-end (web UI) tasks.
To check if the models work well, they used lots of “benchmarks,” which are like standardized exams for AIs. These tests covered:
- Language and knowledge (including “long-tail” facts that are rare but useful at work),
- Math and science (from contest-style problems to research-style reasoning),
- Coding (from small snippets to full software projects),
- Vision (images and videos, including long and complex content),
- Long-context reading (very long documents),
- Instruction-following (doing exactly what you ask, even with tricky constraints),
- “Agentic” tasks (multi-step tasks using tools, browsing, writing code across files, and planning).
They also created new tests that better reflect real jobs:
- LPFQA and Encyclo-K for professional, long-tail knowledge,
- Ainstain Bench and BABE for science + coding + multimodal research,
- NL2Repo-Bench for “vibe coding” (building an entire software repo from a plain description in one go),
- Real-world task sets like customer support, document extraction, and travel planning.
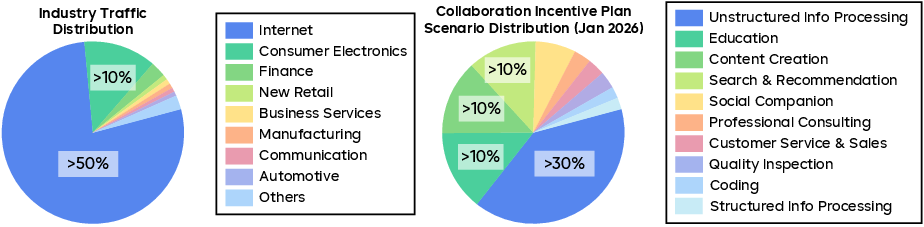
On top of lab tests, they studied real usage patterns in China to see what developers and businesses actually do with AI. Two key takeaways:
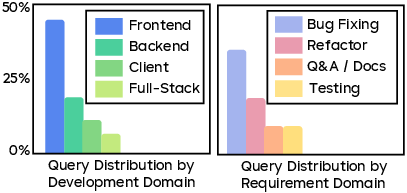
- Most enterprise use involves processing unstructured information (like analyzing many documents) and creating content.
- In coding, front-end work (web pages, layout, styling) and bug fixing dominate, with Vue.js especially popular.
They also compared costs across big AI providers. The point: Seed2.0 aims to be much cheaper per token while keeping quality high enough for production use.
What did they find, and why does it matter?
Here are the main results in plain language:
- Strong overall skills: Seed2.0 Pro performs in the top group on many standard tests (language, reasoning, math, coding, and vision). It’s designed for real products, not just demos.
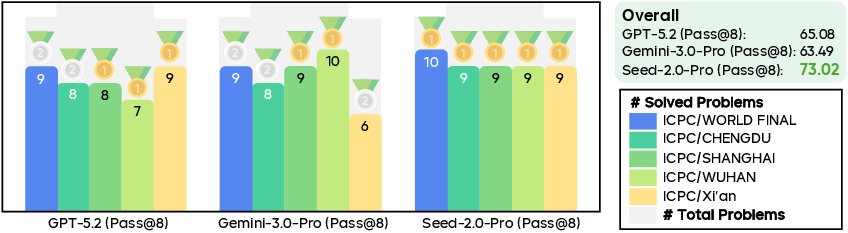
- Math and coding strength: The Pro model reached “gold medal” levels on Olympiad-style math (like IMO/CMO scoring) and a very high rating on Codeforces (a competitive coding platform). This means it’s excellent at multi-step logic and problem-solving—skills that help both in research tasks and in building/fixing software.
- Better instruction-following: The models became more reliable at obeying detailed instructions (tone, format, length, and multiple constraints). For businesses, that means fewer mistakes when the AI must produce strict, structured outputs.
- Visual and video understanding: Seed2.0 handles images and long videos more reliably than before, including reading charts and documents and tracking events over time. This is key for real workflows (like processing scanned contracts or analyzing video content).
- Real-world fit and cost: The models are priced much lower than many top competitors. That’s important because a lot of business use involves high-volume tasks (for example, analyzing thousands of documents daily). Cheaper cost with solid quality makes those use cases possible.
- Focused on what users actually do: Since front-end coding and bug fixing are the most common developer requests, the models were trained and tuned to be especially useful there.
- Honest about gaps: The paper is clear that Seed2.0 still trails the very best models in some areas—for example, certain big coding challenges (like SWE-Evo, NL2Repo) and some “rare fact” question sets. Long-context retrieval tasks also show room for improvement.
Why this matters:
- Reliability + affordability = practical adoption. If an AI is accurate, fast, and affordable, companies can trust it for core workflows, not just experiments.
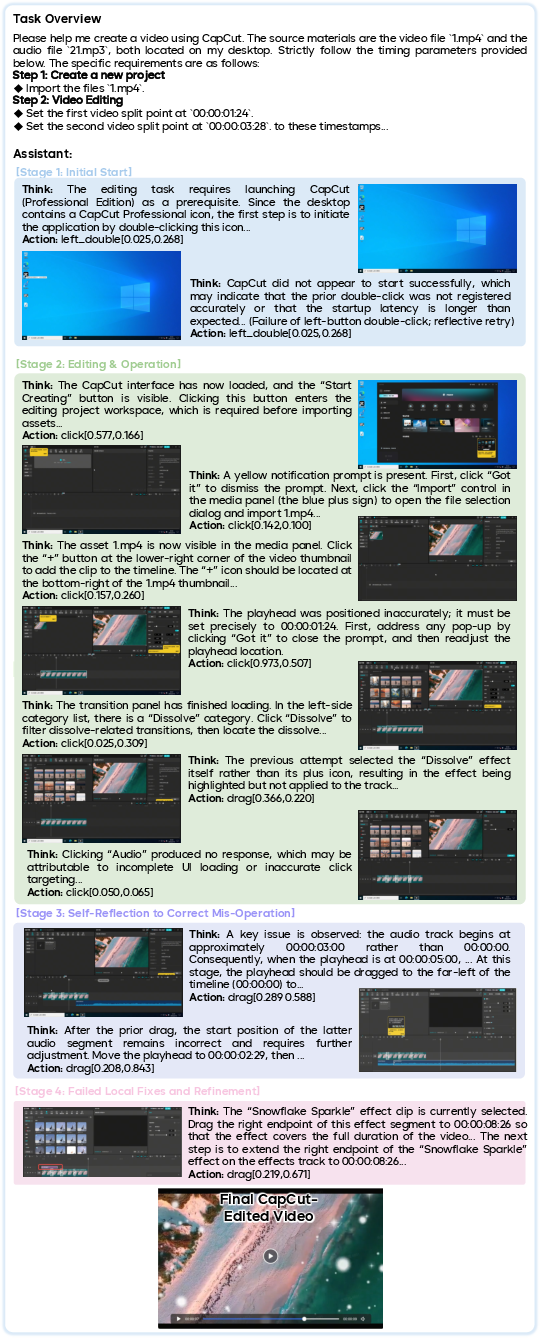
- Agentic abilities help with “real jobs.” Instead of giving a single answer, the model can plan, use tools, write code across files, read manuals, and produce complete outputs—closer to how people work.
- Better multimodal understanding means the AI can read what humans use every day (images, PDFs, charts, and videos), not just text.
What could this change in the real world?
- Businesses can automate more of their information-heavy work: summarizing and extracting from mixed documents, drafting reports, or generating consistent outputs for other systems.
- Developers can fix bugs faster and build front-end features with fewer errors—especially useful in fast, iterative product teams.
- Education, customer support, and analytics can improve through better instruction-following and long-context reading.
- Research support gets stronger: the models are getting better at math, science coding, and combining text with visuals (like charts or microscopy images in biology).
In short, Seed2.0 is a step toward AI that can handle complex, multi-step, real-world tasks at a cost that makes sense for everyday use. It’s not perfect yet—especially in some coding and fact-heavy categories—but it’s moving in the right direction: from answering questions to reliably getting jobs done.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Unspecified model architecture and sizes: No disclosure of parameter counts, layer configurations, MoE vs. dense design, tokenizer, context window per variant (Pro/Lite/Mini), or multimodal encoder/adapter details—hindering reproducibility and targeted comparisons.
- Training data and recipe opacity: Absent details on pretraining corpora composition, language mix, domain balance, data filtering/deduplication, copyright status, and training compute budgets/schedules (optimizer, LR schedules, batch sizes), making it impossible to attribute capability gains to data vs. architecture.
- Alignment and instruction-tuning methods not described: No specifics on RLHF/DPO/SFT pipelines, annotator sources, reward models, preference datasets, or safety alignment strategies; unclear how complex instruction-following improvements were achieved.
- “Systematic ingestion of long-tail domain knowledge” remains a black box: No methodology (retrieval-augmented training, continued pretraining, data curation, supervision signal) or ablation studies; unclear how contamination with LPFQA/Encyclo-K test sets is mitigated.
- Safety, robustness, and misuse safeguards unreported: No red-teaming results, jailbreak resilience, prompt-injection resistance for web/GUI agents, tool-use security, PII handling, privacy safeguards, or decisions on refusal policies and guardrails.
- Bias and fairness left unevaluated: No demographic, gender, cultural, or language bias assessments; no fairness metrics in multimodal outputs; absence of disparate impact analyses across languages (especially low-resource) or modalities.
- Reproducibility compromised by altered benchmark setups: The paper modifies evaluation conditions (e.g., increased FPS for video tasks, internal mirrors, case filtering) and uses a nonstandard tokenization for Graphwalks—yet does not publish code, prompts, seeds, or per-task configurations for exact reproduction.
- Comparative methodology may skew fairness: Defining competitor scores as max(official, in-house) while reporting Seed’s own runs, using LLM judges (DeepSeek-V3) for MTVQA without cross-judge calibration, and mixing tokenization schemes for Graphwalks invites unknown bias; standardized, shared harnesses are needed.
- Internal benchmarks are not public: NL2Repo-Bench, GDPVal-Verified, XpertBench, and in-house “Context Learning” scenarios lack public task releases, scoring rubrics, and baselines—preventing community verification and progress tracking.
- Missing results for many vision/video benchmarks: Despite listing 50 image and 24 video benchmarks, the paper provides no quantitative results tables or training pipeline descriptions for VLMs, obscuring strengths/weaknesses and limiting targeted improvements.
- End-to-end agentic performance is undercharacterized: No task-level success rates, time-to-completion, failure modes, or human effort metrics for coding agents, GUI agents, search agents, or deep-research tasks; practical reliability over long horizons remains unknown.
- Benchmark filtering and exclusions reduce ecological validity: Removing non-deterministic, networked, or complex validation tasks (e.g., some Terminal-Bench cases) improves stability but hides real-world fragility to flaky dependencies, network latency, and version conflicts.
- Chain-of-thought and inference budgets unspecified: No reporting of temperature, n-samples, CoT/tool-use settings, “thinking token” allocations, or stop criteria—critical for assessing both performance and cost/latency trade-offs vis-à-vis “thinking” baselines.
- Cost analysis limited to token prices: Absent end-to-end TCO for representative workloads (p50/p95 latency, throughput, cache hit rates, batching, memory footprint, GPU efficiency), and no cost-per-task for long-horizon agentic pipelines.
- Acknowledged coding gaps lack diagnosis: The paper admits inferiority to Claude on SWE-Evo and NL2Repo but provides no granular error taxonomy (spec interpretation, planning, dependency management, tests/fixes) or targeted remediation strategies.
- Long-context weaknesses not analyzed: Seed2.0’s deficits on MRCR/Graphwalks are noted but not dissected (attention stability, retrieval quality, positional encodings), and tokenization mismatches confound conclusions; controlled, consistent tokenization studies are needed.
- Hallucination issues underexplored: Substantially lower FactScore for Seed2.0 Pro is reported without qualitative/quantitative error analysis (e.g., claim verification, citation faithfulness), nor proposed training or decoding mitigations.
- Frontend-heavy usage analysis may induce bias: The dataset (authorized program data) may be unrepresentative; no assessment of model capability on backend, systems, mobile, or data/ML engineering tasks, nor of domain balancing strategies in training.
- Multilingual coverage gaps: Beyond Global PIQA/MMMLU and some Chinese-focused tests, there is no evaluation on low-resource languages, code-switched inputs, or script/orthography robustness, leaving global deployability unclear.
- Vision document/OCR pipeline undisclosed: It is unclear whether document/chart results rely on integrated OCR, external systems, or post-processing; no ablations on OCR vs. VLM contributions to performance or error profiles (e.g., layout vs. text recognition).
- Formal math claims lack verifiable provenance: “Erdős problems” and Olympiad achievements are stated without releasing problem lists, settings (tools/time), and adjudication criteria; external verification and proof-checking processes should be documented.
- Putnam-200 evaluation comparability uncertain: Seed used Lean/Python/Lean search tools; competitor settings and tool allowances are not clarified—needs standardization and per-problem breakdowns for apples-to-apples claims.
- Instruction-following (Chinese) benchmark is opaque: Dataset, weighting across 17 dimensions, annotation process, inter-annotator agreement, and adjudication rules are not released; generalizability beyond Chinese and to other pragmatics remains an open question.
- Persistent memory and experience accumulation unaddressed: The paper identifies long-horizon experience accumulation as a core gap for agents but does not detail Seed2.0’s memory architecture, knowledge updating, or mechanisms for learning from repeated workflows.
- Continual learning and model updates: No strategy for safe updates, data governance, or catastrophic forgetting mitigation in production deployments with evolving domain knowledge.
- Data governance and ethics: Use of forum posts/books for LPFQA/Encyclo-K raises licensing and consent questions; user log utilization via authorization programs needs clearer privacy/anonymization protocols and downstream training use disclosure.
- Environmental impact not reported: No training/inference energy consumption, hardware profile, or carbon footprint estimates—important for responsible deployment and cross-model comparisons.
Practical Applications
Immediate Applications
The following applications can be deployed with the Seed2.0 Series today, leveraging its multimodal understanding, long-context handling, improved instruction-following, cost efficiency, and agent/tool-use capabilities.
- Enterprise unstructured information processing and reporting
- Sectors: Internet, business services, new retail, finance, consumer electronics
- Workflow/tools: Use Seed2.0 Pro/Lite for ingesting heterogeneous documents (emails, tickets, PDFs, meeting notes), synthesizing insights, and producing structured reports; integrate with RAG pipelines; schedule daily/weekly digests for CX/PM/ops
- Assumptions/dependencies: High-quality data connectors and KBs; privacy/PII controls; prompt templates for consistent output schemas
- Knowledge-grounded customer support and helpdesk automation
- Sectors: SaaS, e-commerce, telecom, financial services
- Workflow/tools: Retrieval-augmented QA using noise-robust context learning (e.g., DeR²-style filtering), intent detection, and answer synthesis from enterprise KBs; embed in chat, email, and agent-assist consoles
- Assumptions/dependencies: Up-to-date KBs; guardrails to avoid hallucinations; deflection thresholds and escalation workflows
- Document, chart, and form understanding for operations and compliance
- Sectors: Legal, finance, insurance, procurement, HR
- Workflow/tools: Apply document and chart extraction (OmniDocBench/CharXiv strengths) to contracts, invoices, financial statements, policy docs; normalize via schemas for ERP/CRM ingestion
- Assumptions/dependencies: OCR quality on scans; standardized output schemas; redaction and audit trails
- Search and recommendation relevance upgrades
- Sectors: Internet platforms, marketplaces, media
- Workflow/tools: Use Seed2.0 for semantic query understanding, category/intent tagging, and LLM-based re-ranking; integrate with vector search and existing rankers
- Assumptions/dependencies: Low-latency integration in ranking pipeline; A/B testing for click/engagement/KPI lift
- Cost-efficient high-throughput assistants
- Sectors: Support, moderation, back-office ops, community management
- Workflow/tools: Deploy Seed2.0 Mini for triage, templated responses, classification, and routing at <$0.50/M output tokens; escalate to Lite/Pro on hard cases (tiered routing)
- Assumptions/dependencies: Quality thresholds and fallbacks; latency SLAs; monitoring for drift
- Coding assistance with emphasis on frontend and debugging
- Sectors: Software development (web/app), internal tools
- Workflow/tools: IDE plug-ins/CLI agents for Vue/JS/TS/CSS; bug triage from stack traces; refactors and doc generation; repository-aware agents for small/mid-size tasks (SWE-Lite scenarios, Terminal-Bench-style tasks)
- Assumptions/dependencies: Repo access, sandboxed execution, unit tests; note current gaps vs top models on SWE-Evo/NL2Repo for large, end-to-end builds
- Spreadsheet and semi-structured data automation
- Sectors: Finance, ops, marketing analytics
- Workflow/tools: Seed2.0 for formula generation, data cleaning, KPI dashboards, and scenario calculators (SpreadsheetBench-Verified style tasks)
- Assumptions/dependencies: Schema-aware prompts; guardrails against silent errors; human-in-the-loop sign-off for critical sheets
- Education copilots for tutoring, grading, and content creation
- Sectors: K–12, higher ed, corporate training
- Workflow/tools: Intelligent tutoring (step-by-step solutions), automatic question generation, rubric-based grading, explanations; multilingual content adaptation
- Assumptions/dependencies: Alignment with curricula; bias and factuality safeguards; LMS integration
- Health information assistants (non-diagnostic)
- Sectors: Healthcare providers, health tech, payers
- Workflow/tools: Draft patient education materials, summarize clinical guidelines, prepare visit summaries; triage FAQs; multilingual support
- Assumptions/dependencies: Not a diagnostic tool; clinical validation and disclaimers; data privacy and HIPAA/PDPA compliance
- Finance research support and long-tail professional QA
- Sectors: Asset management, retail investing, corporate finance
- Workflow/tools: Extract key data from filings, summarize earnings calls, respond to long-tail professional queries (LPFQA/FinSearchComp strengths)
- Assumptions/dependencies: Reliable market and filings data feeds; compliance review; clear boundary between information and advice
- Multimodal UI support and GUI agent assistance
- Sectors: IT support, QA, product operations
- Workflow/tools: Screenshot-based troubleshooting; step-by-step UI automation scripts; visual bug reports; automated test scripts
- Assumptions/dependencies: Stable UI selectors/locators; permissioned automation; rollback and safety controls
- Content creation and multimedia scripting
- Sectors: Marketing, media, creators, education
- Workflow/tools: Generate articles, briefs, video scripts, lesson plans; coordinate with generative media systems (Seedream/Seedance)
- Assumptions/dependencies: Brand/tone control; rights and licensing; QA to prevent hallucinations
- Video analytics at batch or near-real-time for metadata and summaries
- Sectors: Media ops, sports, customer support QA, content moderation
- Workflow/tools: Chaptering, highlight detection, event tagging, narration summaries for VOD; limited live assistance for structured events (e.g., sports metadata)
- Assumptions/dependencies: Video ingestion pipelines; GPU budget; latency targets may constrain live use
- Travel planning and itinerary generation
- Sectors: OTAs, hospitality, consumer apps
- Workflow/tools: WorldTravel-style multi-step planning with budgets/constraints, document extraction for visas/requirements, booking-ready checklists
- Assumptions/dependencies: Reliable third-party APIs and up-to-date policies; handoff to booking engines
- Multilingual customer interactions and knowledge work
- Sectors: Global CX, marketplaces, cross-border trade
- Workflow/tools: Multilingual Q&A, lead qualification, policy explanations; translate + reason over mixed-language docs
- Assumptions/dependencies: Locale-specific compliance; style/tone adaptation; human review for high-stakes interactions
Long-Term Applications
These applications require further research, scaling, safety, or ecosystem development before broad deployment.
- End-to-end “vibe coding” of full repositories from natural language (NL2Repo)
- Sectors: Software, startups, internal tool factories
- Workflow/tools: Single-pass or few-pass generation of full-stack apps with cross-file consistency, dependency management, and CI pipelines
- Assumptions/dependencies: Stronger repo-level reliability, auto-spec refinement, self-healing tests; current gaps acknowledged vs top models
- Long-horizon autonomous agents for enterprise workflows (RPA 2.0)
- Sectors: Operations, finance back-office, supply chain
- Workflow/tools: Agents that plan, execute, and learn across weeks/months, coordinating tools/APIs/people; memory and experience accumulation
- Assumptions/dependencies: Persistent memory stores, governance, safety, and auditability; robust tool orchestration (τ²/MCP-scale reliability)
- Verticalized long-tail knowledge engines as products
- Sectors: Healthcare, law, finance, engineering, biotech
- Workflow/tools: Book-level and forum-level knowledge grounding (Encyclo-K/LPFQA) powering expert assistants with continual ingestion and verification
- Assumptions/dependencies: Licensing of proprietary content; verification pipelines; dynamic updating to reduce staleness
- Scientific discovery copilots
- Sectors: Academia, biotech, materials science, energy
- Workflow/tools: Hypothesis generation, literature triage, experiment design and analysis, scientific coding (Ainstain Bench), multimodal evidence synthesis (BABE)
- Assumptions/dependencies: Access to lab systems/ELNs; data provenance; reproducibility and code execution sandboxes; domain expert oversight
- Safety-critical perception and decision support (autonomous driving/robotics)
- Sectors: Automotive, warehousing, field robotics
- Workflow/tools: Long-video and streaming understanding for scene/event recognition, operator assistance, and incident forensics
- Assumptions/dependencies: Real-time guarantees, redundancy, certification; integration with control stacks; extensive validation beyond benchmarks
- Formal verification and theorem-proving pipelines
- Sectors: Semiconductors, safety-critical software, cryptography
- Workflow/tools: Lean/Python-based proof generation and checking for protocols and hardware/software specs; proof exploration assistants
- Assumptions/dependencies: Toolchain maturity and performance; proof libraries; expert-in-the-loop workflows
- Industrial visual quality inspection and documentation-to-action
- Sectors: Manufacturing, communications, energy
- Workflow/tools: Multimodal agents that read SOPs/manuals and execute vision-based inspections or calibrations
- Assumptions/dependencies: Domain adaptation to underrepresented sectors; robust edge deployment; integration with OT/SCADA and safety systems
- Regulatory and policy operations copilots for governments and large enterprises
- Sectors: Public sector, regulated industries
- Workflow/tools: Analyze statutes and guidance, generate compliance mappings, monitor regulatory updates, multilingual citizen services
- Assumptions/dependencies: Data sovereignty, audit logs, red-team and bias testing; procurement and certification processes
- Healthcare clinical decision support (CDS) and documentation automation
- Sectors: Healthcare providers, payers
- Workflow/tools: Suggest diagnostics, care pathways, and coding (ICD/CPT), generate structured notes from multimodal inputs
- Assumptions/dependencies: Regulatory approvals (e.g., FDA), rigorous clinical validation, bias and safety controls; EHR integration
- Financial agents for research-to-execution workflows
- Sectors: Asset management, retail brokerage
- Workflow/tools: From research and risk analysis to semi-automated execution with guardrails; scenario/backtesting generation
- Assumptions/dependencies: Market connectivity; compliance (MiFID/SEC), strong supervision and kill-switches
- Cross-video and multi-source investigative analytics
- Sectors: Compliance, security, insurance, journalism
- Workflow/tools: Multi-video reasoning for incident reconstruction, fraud detection, and claims analysis; link visual, textual, and sensor data
- Assumptions/dependencies: Data fusion pipelines; privacy-compliant storage; calibrated uncertainty estimates
- On-device and edge deployments
- Sectors: Consumer electronics, IoT, retail
- Workflow/tools: Seed2.0 Mini variants quantized and optimized for on-device inference for offline assistants and low-latency UIs
- Assumptions/dependencies: Hardware acceleration (NNAPI, CUDA, NPUs), memory constraints, model compression and safety updates
- Cross-industry long-context compliance and audit automation
- Sectors: Finance, pharma, aerospace
- Workflow/tools: Parse book-length manuals, SOPs, and standards to produce audit evidence, gap analyses, and remediation plans
- Assumptions/dependencies: Version tracking; evidence provenance; alignment with auditors’ requirements
- Human-in-the-loop creative studios with generative media
- Sectors: Advertising, entertainment, education
- Workflow/tools: Script-to-storyboard-to-asset pipelines coupling Seed2.0 with Seedream/Seedance; iterative refinement with brand safety checks
- Assumptions/dependencies: Rights management; watermarking and provenance; latency and cost controls for video
Notes on feasibility across applications:
- Capability trade-offs: Seed2.0 still shows gaps vs frontier models on some repo-level coding and certain long-tail knowledge evaluations; plan for fallback to humans or higher-tier models when quality thresholds are unmet.
- Governance and safety: For high-stakes domains (healthcare, finance, public sector), require rigorous evaluation, monitoring, and compliance frameworks.
- Data quality is decisive: Long-tail performance and context learning depend on curated KBs, clean retrieval, and continual updates.
- Economics: The tiered pricing enables broader experimentation and differential routing; sustainable ROI requires telemetry, A/B testing, and cost–quality balancing.
Glossary
- Ainstain Bench: A benchmark introduced to evaluate research-oriented capabilities of models, particularly in scientific workflows. "We introduce Ainstain Bench \citep{du2025deepresearch} and BABE \cite{zhou2026babebiologyarenabenchmark} to evaluate research-oriented capability."
- Agentic coding: A development workflow where LLM-based agents assist or act autonomously across multi-step software tasks. "To understand real-world interaction patterns in agentic coding, we analyze trajectory-level developer usage data."
- Agentic paradigm: A shift in AI toward treating models as autonomous agents that plan and execute multi-step real-world tasks. "the field is moving toward an agentic paradigm where LLMs tackle scientific research, complex software development, autonomous documentation learning, and multi-step real-world workflows."
- BABE: A multimodal biology benchmark assessing research-style inference over interleaved textual and visual scientific information. "BABE focuses on reasoning over interleaved textual and visual scientific information in the biological domain, assessing whether models can perform research-style inference grounded in multimodal evidence"
- Circular evaluation strategy: An assessment method that evaluates consistency under cyclic or rotational transformations to test spatial reasoning robustness. "we apply the circular evaluation strategy~\cite{liu2024mmbench}."
- Codeforces Elo: A rating that measures coding performance on Codeforces-style problems, adapted to evaluate LLMs. "it reaches a Codeforces Elo of 3020"
- DeR2: A benchmark targeting extraction and reasoning from noisy, long-form technical documents for complex instruction execution. "Recent benchmarks such as \citep{2026arXivder2} and CL-bench \citep{2026CLBench} capture exactly this demand."
- Dependency resolution: The process of consistently resolving and installing required software package versions in an environment. "to ensure consistent dependency resolution."
- Docker Compose: A tool for defining and running multi-container Docker applications via declarative configuration. "multi-container Docker Compose scenarios that introduced unnecessary complexity;"
- Encyclo-K: A benchmark that evaluates book-level professional knowledge using compositional, dynamically generated test instances. "Encyclo-K \citep{EncycloK} evaluates genuine mastery of book-level professional knowledge."
- Erdos problems: Research-level open problems in mathematics originating from Paul Erdős, used here to indicate high-difficulty reasoning. "Seed2.0 tackles Erdos problems and performs Scientific Coding, pushing the boundaries of machine intelligence"
- Formal theorem proving: Using proof assistants and formal logic systems to construct and verify mathematical proofs. "Seed2.0 also excels in formal theorem proving,"
- Fundamental Agentic Capacity: The baseline ability of an LLM to plan, use tools, interact with environments, and complete multi-step tasks. "We define this foundational layer as Fundamental Agentic Capacity."
- Graphwalks: A long-context evaluation involving graph traversal/walks, sensitive to tokenization and scoring setups. "For Graphwalks, we use our in-house tokenization pipeline during evaluation,"
- Hallucination: The generation of ungrounded or fabricated content by models, often reduced via improved training or evaluation. "Seed2.0 strengthens visual reasoning with reduced hallucination"
- HLE-Verified: A curated, verified subset of the Humanity’s Last Exam benchmark for more reliable expert-level evaluation. "HLE-Verified (Humanityâs Last ExamâVerified) is a curated subset of Humanityâs Last Exam"
- In-context learning (ICL): Learning from examples or instructions provided in the prompt at inference time without updating model weights. "This design supports both zero-shot and few-shot in-context learning (ICL) evaluation,"
- Inference latency: The time taken by a model to produce outputs after receiving inputs, directly affecting user experience. "Inference latency directly impacts user experience."
- Lean: An interactive theorem prover and proof assistant used for formal verification in mathematics and computer science. "Agent-based multi-turn setup with Lean, Python, and Lean search tools."
- LLM-judge: The use of a LLM as an automated evaluator of another model’s outputs instead of rule-based matching. "Distinctively, for MTVQA, we deploy an LLM-judge (Deepseek-V3-0324) rather than rule-based matching to evaluate predictions."
- Long-context reasoning: Reasoning over inputs with very large context windows (e.g., long documents or many tokens). "emphasizing multimodal understanding, long-context reasoning, structured generation, and tool-augmented execution for reliable end-to-end enterprise task completion."
- Long-horizon: Describes tasks or workflows that require many coordinated steps over extended time spans. "long-horizon, economically and scientifically valuable workflows."
- Long-tail domain knowledge: Rare, specialized knowledge that appears infrequently but is essential in niche professional contexts. "Seed2.0 addresses this through systematic ingestion of long-tail domain knowledge"
- LPFQA: Long-tail Professional Forum-based Question Answering; a benchmark built from real-world, domain-specific questions. "LPFQA (Long-tail Professional Forum-based Question Answering) \citep{zhu2025lpfqa} is constructed from long-tail questions collected from professional forums and expert communities."
- Macro average accuracy: An evaluation metric averaging per-class accuracies equally, regardless of class size. "For VisFactor, we report the macro average accuracy over all constituent tasks."
- Mean Absolute Error (MAE): A regression error metric measuring the average absolute difference between predictions and ground truth. "With respect to evaluation metrics, we report the Mean Absolute Error (MAE) for FSC-147."
- Multimodal: Involving multiple data modalities (e.g., text, images, video, audio) within a single model or task. "multimodal models,"
- Multi-hop reasoning: Reasoning that requires chaining multiple dependent steps or facts to reach a conclusion. "Multi-hop reasoning and video state tracking are core competencies for video reasoning."
- Normalized Edit Distance (NED): Edit distance normalized by string length, used for fairer text similarity scoring. "We use Normalized Edit Distance (NED) for OmniDocBench 1.5,"
- Pass@8: The probability that at least one of eight sampled solutions is correct, commonly used in code evaluation. "Pass@8."
- Scientific coding: Implementing and manipulating computational procedures used in scientific research workflows. "Ainstain Bench emphasizes scientific coding,"
- Tool-augmented execution: Execution where the model invokes external tools (e.g., APIs, search, code) to complete tasks more reliably. "tool-augmented execution for reliable end-to-end enterprise task completion."
- Tool invocation and orchestration: Calling and coordinating multiple external tools or APIs during an agent’s multi-step task execution. "tool invocation and orchestration (e.g., -Bench\citep{barres2025tau}, BFCL-v4~\citep{patil2025bfcl}, MCP-Mark~\citep{2025arXivMCPmark}, VitaBench~\citep{he2025vitabench})"
- Vibe Coding: An extreme end-to-end software generation scenario that builds complete repositories from natural-language specifications. "Vibe Coding. We build NL2Repo-Bench to measure whether a model can complete an entire software repository from a natural-language specification in a single end-to-end process."
- Visual grounding: The task of linking textual references to specific objects or regions within visual data. "Fine-grained visual grounding and precise object enumeration are critical for tasks requiring high spatial fidelity."
Collections
Sign up for free to add this paper to one or more collections.

