Seedance 2.0: Advancing Video Generation for World Complexity
Abstract: Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Seedance 2.0: Advancing Video Generation for World Complexity”
1) What is this paper about?
This paper introduces Seedance 2.0, a new AI model from ByteDance that can create short videos with sound. Unlike older tools that mainly took a text prompt and produced a simple clip, Seedance 2.0 is designed to handle more complicated, realistic scenes and to follow detailed instructions. It can take in different kinds of inputs—text, images, audio, and even video—and mix them to generate new, coherent audio–video stories.
2) What questions are the researchers trying to answer?
In simple terms, the team set out to answer:
- Can an AI make videos that look and move more like real life, without weird glitches?
- Can it follow complex directions (like a mini film script) and keep characters, styles, and actions consistent?
- Can it create high-quality sound that matches the video perfectly (like lip movements lining up with speech and sound effects happening at the right moment)?
- Can it work well in real creative jobs—such as ads, movie-like scenes, game animations, and social videos—so people can make content faster and cheaper?
3) How did they build and test it?
Seedance 2.0 uses a single, unified model that “speaks” multiple input types. Think of it like a director that understands different languages—text (what to show), images (what things should look like), audio (what it should sound like), and video (how things should move)—and then makes a new scene that blends them all smoothly.
- What the model can take in: up to 3 short videos, 9 images, and 3 audio clips, plus text instructions.
- What it outputs: 4–15 second clips at 480p or 720p, with synchronized, layered audio (voice, effects, background).
To judge how well it works, the team used:
- A new test system called SeedVideoBench 2.0. This combines:
- “Objective” checks by automated tools (e.g., how steady motion is over time).
- “Subjective” reviews by human experts (e.g., does the camera work tell a good story? does it look cinematic?).
- Real-world “face-offs” on Arena.AI, a community site where people watch two anonymous videos side-by-side and vote for their favorite. This shows what viewers actually prefer.
They tested three main tasks:
- Text-to-Video (T2V): you write a prompt; the model makes a video.
- Image-to-Video (I2V): you give an image; the model animates it while keeping the style/identity.
- Reference-to-Video (R2V): you give reference videos/images/audio; the model edits, continues, or combines them into a new video.
Along the way, they explain technical terms with practical focuses:
- “Temporal coherence” = frames fit together smoothly over time (like a flipbook that doesn’t jump around).
- “Multimodal” = using multiple kinds of inputs (text, images, audio, video) together.
- “Binaural audio” = 3D-like, immersive sound you can feel around you in headphones.
4) What did they find, and why is it important?
Seedance 2.0 showed strong improvements across the board:
- More realistic motion and physics: People move naturally, props behave believably, and multi-character scenes stay stable. Close-ups look sharp and consistent.
- Better control and instruction-following: It sticks to detailed prompts (including multi-shot or multi-angle “mini scripts”) and preserves character identity and style over time.
- Stronger multimodal skills: It understands and blends text, images, video, and audio to match things like camera style, pacing, and action beats.
- Higher-quality, better-synced audio: It outputs layered tracks (dialogue, sound effects, background) that line up tightly with visuals—like lips matching speech and impacts matching sounds. It also improved support for different languages, dialects, opera, and singing.
In expert tests and public comparisons:
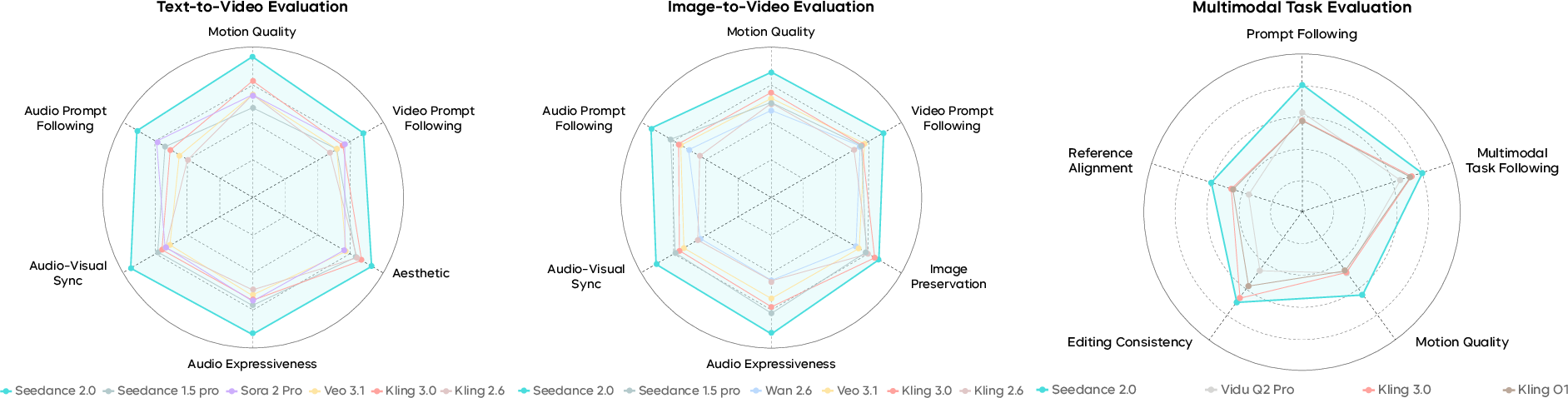
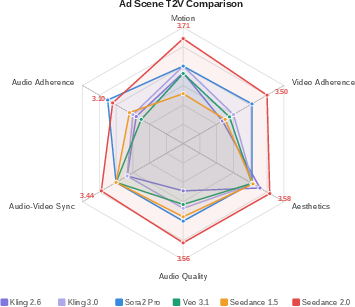
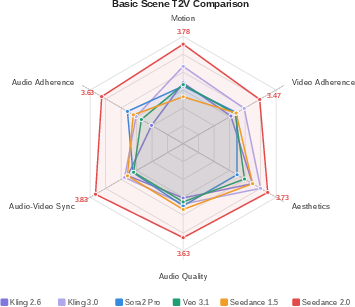
- Seedance 2.0 scored highest across most categories in SeedVideoBench 2.0 for T2V, I2V, and R2V.
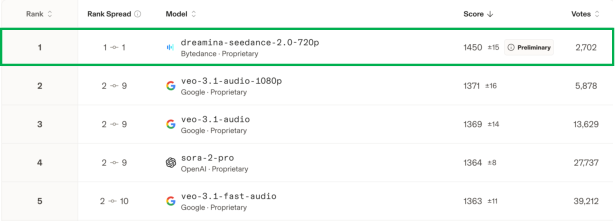
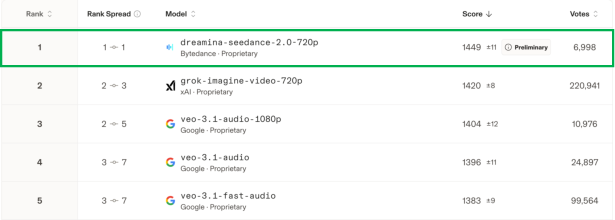
- On Arena.AI (a community preference leaderboard), Seedance 2.0 (720p) ranked #1 for both Text-to-Video and Image-to-Video, even beating some 1080p models—suggesting viewers care more about motion realism and coherence than just resolution.
Why this matters:
- More realistic videos and tighter audio–video sync mean the results are more watchable and professional.
- Stronger control and editing features help creators shape content more precisely, which saves time and reduces cost.
The team also notes remaining issues they’re working on:
- Occasional small distortions, edge-case physics, high-frequency visual noise.
- Audio noise or lip-sync slips in multi-speaker scenes.
- Multi-subject consistency and exact text rendering in complex edits can still improve.
5) What’s the impact, and what comes next?
Seedance 2.0 can help creators—from hobbyists to studios—produce high-quality video faster and more affordably. It’s useful for:
- Ads and brand videos
- Film- and TV-style scenes and effects
- Game animation and trailers
- Social content and commentary videos
Bigger picture:
- Tools like this could change how videos are made, letting more people bring ideas to life without huge budgets or long shoots.
- The team emphasizes safety, saying they use a structured review process to reduce risks and support responsible use.
- Future work aims to better match the real world’s physics and meanings, further improve consistency across complex scenes, and deepen the model’s understanding of both visual and audio storytelling.
In short, Seedance 2.0 moves from “make a short clip from a prompt” toward “be a flexible, reliable mini film studio”—taking in different kinds of guidance, creating more lifelike motion and sound, and helping people tell richer stories with AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper presents strong qualitative and subjective quantitative results for Seedance 2.0, but leaves several technical details, evaluation choices, and capability boundaries unspecified. The following list identifies concrete gaps and open questions future work could address:
- Architecture transparency
- The unified “native multi-modal audio-video joint generation” architecture is not described (e.g., diffusion vs. autoregressive/transformer backbone, latent representations for video/audio, cross-modal fusion mechanisms, conditioning paths, and training objectives for A/V sync).
- No details on how binaural audio is modeled (HRTFs used, ambisonics vs. direct binaural, scene-aware panning) or how spatial audio is conditioned on camera motion and scene geometry.
- Training data and procedure
- Training datasets (scale, domains, licensing, diversity) and data curation for video/audio are not disclosed; no discussion of potential bias sources or coverage (e.g., body types, cultures, minority languages, low-resource audio).
- Absent training hyperparameters and compute profile (iterations, batch sizes, augmentations, optimizers, learning schedules), preventing reproducibility and fair comparison.
- No ablation studies isolating contributions of data, architecture, and training objectives (e.g., what drives motion realism vs. instruction following vs. audio-sync improvements).
- Evaluation design and reproducibility
- SeedVideoBench 2.0 is not released (prompts, data, code, scoring protocols), limiting independent replication and cross-lab comparison.
- Missing statistical rigor for MOS-style results (sample sizes per category, confidence intervals, inter-rater reliability, rater calibration, and controlling for evaluator domain bias).
- Objective metric definitions for “automated motion stability” and “consistency” are not described (features measured, thresholds, error metrics, and ground-truth construction).
- Arena.AI comparisons lack prompt set disclosure, sampling settings, and run-to-run variance; uncertainty remains about prompt domain overlap, selection bias, and match-up randomness.
- Capability boundaries and failure modes
- Duration is limited to 4–15 seconds; long-form narrative coherence, character persistence across scenes, and error accumulation in minute-scale videos are not evaluated.
- Resolution is capped at 720p native; behavior at 1080p/4K, temporal consistency under super-resolution, and scaling laws for fidelity vs. compute are unreported.
- Multimodal input caps (3 videos, 9 images, 3 audio) are fixed without ablation on how performance scales or degrades with more/less references or conflicting signals.
- Known limitations are acknowledged but not systematically quantified: multi-subject identity consistency, text restoration accuracy (esp. non-Latin scripts), complex editing robustness, minor deformation artifacts, high-frequency visual noise, audio distortion, and lip-sync in multi-speaker scenes.
- Robustness under occlusions, fast camera motion, extreme lighting, crowded scenes, challenging interactions (contact, collisions), and out-of-distribution prompts is not characterized.
- The behavior with contradictory or ambiguous instructions across modalities (e.g., mismatched image vs. text vs. audio cues) and strategies for conflict resolution remain unspecified.
- Control strength and weighting across modalities (how users tune text/image/video/audio influence) are not exposed or evaluated for predictability and stability.
- Physical plausibility and 3D consistency
- Claims of improved physics compliance lack objective tests (e.g., contact timing, momentum conservation proxies, foot skating metrics, rigid/soft-body plausibility checks).
- No assessment of 3D spatial consistency across frames/shots (e.g., camera resectioning, depth/pose consistency, multi-view geometry proxies) or whether an internal scene representation is formed.
- Absence of evaluations on physically grounded tasks (e.g., object permanence, accurate hand–object interactions, stable shadows/reflections under moving lights).
- Text and language coverage
- Text rendering and restoration are qualitatively improved but lack OCR-based metrics across scripts (Chinese, Latin, Arabic, Devanagari, etc.) and under motion/occlusion.
- Audio-language breadth beyond Chinese dialects and English is unclear; “minority languages” are unspecified (which languages, proficiency, phoneme coverage, prosody naturalness).
- No analysis of cross-lingual lip-viseme alignment, speaker identity consistency across languages, or code-switching performance.
- Audio generation specifics
- Audio-engineering details are absent: sample rate/bit depth, loudness normalization (e.g., EBU R128), dynamic range control, latency for multi-track mixing, and noise suppression.
- Multi-track independence and controllability (dialogue/BGM/SFX bleed, crosstalk, stem remixing) and support for downstream post-production workflows are not evaluated.
- Spatial audio generalization is not tested under head rotation, different HRTFs, or speaker playback (downmix artifacts, stereo compatibility).
- Editing and continuation workflows
- Precision and stability of local edits (masking quality, boundary flicker, preservation of unedited regions over time) lack quantitative measures.
- Continuation “forward and backward” stitching quality at edit boundaries is not assessed for temporal seams, color/lighting drift, or audio continuity clicks.
- Complex compositing with user-provided footage (color matching, relighting, lens/film emulation) and compatibility with professional pipelines (e.g., integration with NLE/VFX tools) are not documented.
- Latency, throughput, and deployment
- The “Fast” version lacks concrete latency, throughput, and quality trade-off metrics across hardware targets; no guidance on real-time feasibility.
- Memory footprint, inference batchability, and cost-per-second at different resolutions/durations are not reported.
- Fairness, bias, and safety
- Safety framework is referenced but lacks specifics: datasets, red-teaming procedures, adversarial prompt suites, mitigation techniques, and residual risk categories.
- No quantitative audits for demographic fairness (e.g., motion, facial expression fidelity, skin tones, hairstyles, clothing across cultures), or accent/language biases in audio.
- Deepfake risk, watermarking/provenance signaling, and detection/traceability mechanisms are not discussed.
- Data governance for training (consent, copyright, rights management) and safeguards against style cloning of protected voices/music are unspecified.
- Comparative baselines and fairness of comparison
- Competitor configurations (sampling steps, seeds, safety filters, control strengths) and parity controls (resolution, duration) are not fully standardized, risking confounds.
- Lack of per-prompt paired outputs and public release of the exact comparison set prevents third-party verification.
- User controllability and UX
- The paper does not describe explicit controls for cinematography (camera parameters, lens choices), motion curves, beat alignment parameters, or control schedules over time.
- Uncertainty visualization/calibration (how “confident” the model is in following instructions) and user feedback loops for iterative refinement are not specified.
- Environmental impact and efficiency
- Training/inference energy consumption and carbon footprint are not reported; no discussion of efficiency techniques (distillation, caching, reuse of latent features).
- Future research directions (implied but not operationalized)
- “Deep alignment with the physical world” is a stated goal, but concrete research agendas (e.g., incorporating physical simulators, differentiable physics priors, or weakly supervised physical constraints) are not outlined.
- Scaling to long-form, multi-scene narratives with consistent character arcs, props continuity, and story beats remains an open challenge without a stated plan or benchmark.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed today using Seedance 2.0 via Doubao, Jimeng, and Volcano Engine (modelId: doubao-seedance-2-0-260128), or integrated through the Seedance 2.0 Fast variant for lower latency.
- Advertising spot generation and iteration — Sector: Marketing/Advertising
- What: Produce 6–15s product spots and social ads with precise motion, cinematography, and style control; generate multi-track audio (VO, SFX, BGM) tightly synced to visuals.
- Tools/workflow: Script → text-based storyboard → I2V with brand/product reference images → generate multiple variants → export to NLE (e.g., Jianying/CapCut) for color, titles, compliance.
- Assumptions/dependencies: 4–15s duration, 480p–720p native outputs (upscale/stitching may be required for campaigns); clearance for brand assets; platform safety moderation.
- Film/TV previz and pitch sizzle reels — Sector: Media & Entertainment
- What: Rapidly explore shot lists, camera moves, and editing rhythm for scenes; generate multi-shot sequences and continuations to communicate narrative intent.
- Tools/workflow: Text storyboard + concept frames → T2V/I2V multi-shot generation → video continuation for coverage → export to editorial.
- Assumptions/dependencies: Short form outputs require stitching for longer reels; multi-subject consistency is improved but still imperfect; union/guild and crediting policies apply.
- Game cutscene and animation prototyping — Sector: Gaming
- What: Generate motion studies, cutscene beats, and style-consistent animatics from concept art or in-game stills; add placeholder multi-track audio.
- Tools/workflow: I2V with concept art/style refs → cutscene beats (4–15s) → Fast variant for quick iterations → handoff to engine teams.
- Assumptions/dependencies: Final asset fidelity still needs DCC/engine implementation; licensing for any referenced artwork; 720p previews may need upscaling.
- Commentary, explainer, and reaction shorts — Sector: Creator economy, Education
- What: Produce short videos with auto narration, ambient SFX, and beat-matched BGM; improved Chinese dialects, opera, and singing enable regionally tailored content.
- Tools/workflow: Prompt + outline → T2V with embedded VO generation → auto-mixed multi-track audio → platform posting.
- Assumptions/dependencies: Verify factual claims; ensure voice/persona rights for any mimicry; moderate sensitive topics per platform policy.
- E-commerce product showcases — Sector: Retail
- What: Generate product highlight clips showing materials/lighting realism and consistent identity across shots; add multilingual VO for localization.
- Tools/workflow: I2V with product photos (up to 9 images) + style refs → per-locale VO tracks → SKU variant batches.
- Assumptions/dependencies: 15s cap may require multi-clip sequences; truthful representation policies; SKU/brand approvals.
- Corporate training and safety micro-lessons — Sector: Enterprise, Industrial
- What: Create short instructional videos depicting procedures or counterfactual scenarios (e.g., hazards), with synchronized narration and sound effects.
- Tools/workflow: Procedure script → T2V with step-based prompts → audio-visual sync for actions/alarms → LMS upload.
- Assumptions/dependencies: SMEs must validate safety accuracy; scope constrained by duration limits; disclosure that visuals are synthetic.
- Localization, dubbing, and lip-sync — Sector: Media localization
- What: Generate or replace narration tracks in multiple languages/dialects with strong AV sync and spatialized mixing.
- Tools/workflow: Reference video + target language prompts → audio generation with lip-sync alignment → multi-track export.
- Assumptions/dependencies: Obtain consent for voice likeness; check pronunciation quality in low-resource dialects; handle multi-speaker scenes carefully (known lip-sync challenges).
- Newsroom b‑roll and filler content — Sector: Digital media
- What: Produce neutral b‑roll (streetscapes, abstract visuals, transitions) matched to narration tempo.
- Tools/workflow: T2V with pacing cues → auto BGM/SFX → editorial disclosure tags.
- Assumptions/dependencies: Strict editorial standards and labeling for synthetic footage; avoid depicting real events or misrepresentations.
- Post-production audio sweetening — Sector: Audio/Video post
- What: Add ambient, object-interaction, and non-verbal sounds synchronized to legacy footage.
- Tools/workflow: Reference video upload (R2V) → generate SFX/ambience tracks → mixdown in DAW.
- Assumptions/dependencies: Handle audio artifacts in dense multi-speaker scenes; maintain rights for any existing audio stems.
- Branded social AR-style effects and transitions — Sector: Social apps, Consumer effects
- What: Design short stylized effects sequences referencing brand motifs or creator style; tight beat matching to music.
- Tools/workflow: Style reference images + music clip → I2V/R2V → export as template.
- Assumptions/dependencies: 3 audio clip input limit; consistent text rendering still improving; QA for on-device playback.
- Product R&D for spatial audio experiences — Sector: Consumer electronics, Software
- What: Prototype binaural soundscapes and UI earcons synchronized with animations for headphones/AR.
- Tools/workflow: T2V with spatial cues → dual-channel binaural output → user tests.
- Assumptions/dependencies: Headphone/HRTF variability; final tuning still needed in audio middleware.
- Academic benchmarking and human-factors studies — Sector: Academia
- What: Adopt SeedVideoBench 2.0’s task taxonomy and subjective/objective split to evaluate models; run narrative quality assessments and realism discrimination studies.
- Tools/workflow: Recreate fine-grained task sets (reference/edit/extend combination tasks) → expert panel reviews → Arena-style preference tests.
- Assumptions/dependencies: Availability/licensing of SeedVideoBench 2.0 data and protocols; consistent rater training to reduce variance.
- Model auditing and procurement checklists — Sector: Policy, Public sector IT
- What: Use SeedVideoBench 2.0 dimensions (motion stability, AV sync, prompt following, multimodal consistency) as acceptance criteria in RFPs and audits.
- Tools/workflow: Define thresholds per dimension → blind human review plus automated motion stability pipelines → publish scorecards.
- Assumptions/dependencies: Access to comparable test sets; harmonization with local content safety standards; periodic re-testing across versions.
- Small business promotional media — Sector: SMBs
- What: Generate short promos for events, menus, or services with localized VO and consistent brand visuals.
- Tools/workflow: Upload logo/photos → I2V with style prompt → VO in target dialect → schedule posts.
- Assumptions/dependencies: Brand guideline adherence; ensure generated on-screen text accuracy (noted as an area with room for improvement).
Long-Term Applications
These use cases are plausible extensions that will benefit from longer durations, higher resolutions, stronger multi-subject consistency, expanded editing accuracy, or deeper toolchain integration.
- End-to-end virtual production for episodic content — Sector: Film/TV
- What: AI-assisted production of multi-minute scenes with consistent characters, props, and sets across episodes, including iterative edits and continuity management.
- Dependencies: >15s generation, 1080p–4K native output, improved multi-subject and text fidelity; rights management and guild/union frameworks; robust watermarking and audit trails.
- Real-time, interactive storytelling and machinima — Sector: Gaming, Social platforms
- What: On-the-fly generation of cutscenes driven by player choices with coherent multi-shot narratives and live audio mixing.
- Dependencies: Sub-200ms latencies via Seedance 2.0 Fast or on-device inference; streaming architecture; content moderation in interactive settings.
- Personalized education at scale — Sector: EdTech
- What: Auto-generate lesson videos with synchronized narration tailored to learner profile, language/dialect, and pace, including multi-shot explanations and recaps.
- Dependencies: Integration with verified knowledge bases; long-form composition; rigorous alignment/safety to prevent hallucinations; educator-in-the-loop workflows.
- Customer support digital humans — Sector: Customer service, Telecom, Banking
- What: Dialect-aware, lip-synced video agents presenting instructions, KYC steps, or status updates.
- Dependencies: Consent-driven voice/likeness handling; policy-compliant disclosure; improved multi-speaker handling and robust lip-sync; secure data pipelines.
- Synthetic data generation for perception and action — Sector: Robotics, Autonomous systems, Computer vision
- What: Produce physically plausible, richly annotated videos of multi-entity interactions to train models for action recognition, tracking, or AV perception.
- Dependencies: Formal annotation export, controllable physics parameters, domain gap bridging (sim2real), and licensing clarity on synthetic datasets.
- Long-form music videos and concert visualizers — Sector: Music industry
- What: Full-length videos with beat-matched visuals, spatialized audience/venue audio, and consistent visual motifs throughout a song or set.
- Dependencies: Long-duration generation, stable thematic continuity, music licensing integration, and live performance synchronization.
- Cultural preservation and revitalization media — Sector: Arts & Culture
- What: Create educational shorts showcasing regional opera, folk music, and dialect narratives with accurate audio-visual alignment.
- Dependencies: Expert curation to ensure authenticity; datasets covering low-resource dialects; cultural governance frameworks.
- Advanced accessibility media — Sector: Accessibility/Assistive tech
- What: Automatically generate descriptive audio and potentially sign-language overlays synchronized with scene content to improve media accessibility.
- Dependencies: High-accuracy sign-language generation (beyond current scope), standards compliance, and QA by accessibility experts.
- Public sector communications and emergency PSAs — Sector: Government/NGOs
- What: Rapid multilingual PSA generation with clear visuals and synchronized alerts for different regions.
- Dependencies: Strong verification pipelines, bias checks across dialects, stringent safety review, and provenance markers.
- Compliance and risk training at enterprise scale — Sector: Finance, Healthcare, Energy
- What: Scenario-driven training videos simulating edge cases (e.g., fraud attempts, safety incidents) with dynamic narratives.
- Dependencies: Domain-expert validation, audit logs for regulators, higher-resolution outputs for enterprise LMS, and red-teaming for edge-case realism.
- In-vehicle and AR assistants with spatial AV prompts — Sector: Automotive, XR
- What: Contextual visual/audio prompts with spatialized sound for guidance and infotainment.
- Dependencies: On-device inference, robust spatial audio rendering across devices, safety validation in motion-critical contexts.
Cross-Cutting Assumptions and Dependencies
- Technical constraints today: 4–15s clip length; 480p/720p native resolution; up to 3 reference videos, 9 images, and 3 audio clips per job.
- Known failure modes: occasional deformation artifacts; edge-case motion plausibility; audio distortion/noise; lip-sync errors in multi-speaker scenes; multi-subject consistency and text restoration still improving.
- Operational considerations: API access via Doubao/Jimeng/Volcano Engine; compute costs and latency for batch workflows (use Seedance 2.0 Fast for low-latency); need for upscaling and stitching for long-form.
- Legal/ethical: IP and likeness rights for references and voices; platform safety policies; disclosure of synthetic media; jurisdiction-specific regulations for advertising, labor, and consumer protection.
- Workflow integration: Best results when paired with NLE/DAW for finishing; adopt quality gates using SeedVideoBench 2.0 dimensions; human-in-the-loop review for factual, safety-critical, or regulated content.
Glossary
- 180-degree rule: A cinematography guideline that keeps the camera on one side of an imaginary axis between subjects to maintain consistent screen direction; violating it can disorient viewers. Example: "axis-crossing (180-degree rule violations)"
- Ambient / Background Sound: Environmental audio elements that create a sense of space and atmosphere behind primary sound sources. Example: "Ambient / Background Sound"
- Anthropomorphic Motion: Movement assigned to non-human subjects (e.g., objects, animals) that mimics human-like behavior or kinematics. Example: "Anthropomorphic Motion"
- ASMR: An audio production style aiming to elicit tingling or relaxing sensations through subtle, intimate sounds. Example: "Special Effects (ASMR, etc.)"
- Audio-visual sync: The alignment of audio events (speech, effects, music) with corresponding visual actions to avoid perceptual mismatch. Example: "audio-visual sync reaches 68.30%"
- Beat-matching: Synchronizing musical beats or rhythmic accents with edits or on-screen motion. Example: "beat-matching between audio and video is strong."
- BGM: Background music used to support mood, pacing, or narrative without being the primary audio focus. Example: "BGM-to-visual matching"
- Binaural audio: A recording or synthesis technique using two channels and head-related transfer functions to create 3D, headphone-optimized spatial sound. Example: "binaural audio capability"
- Cinematographic language: The set of visual storytelling conventions (shots, angles, movement, editing) used to convey narrative and emotion. Example: "Cinematographic language"
- CLIPScore: A metric based on CLIP embeddings that measures semantic similarity between generated media and prompts or references. Example: "metrics such as FVD or CLIPScore"
- Color grading: The post-production process of adjusting color and tone to achieve a consistent or stylized look. Example: "color grading"
- Counter-reality instructions: Prompts that specify scenes or actions violating real-world physics or plausibility (e.g., surreal or impossible events). Example: "Counter-Reality Instructions"
- Cross-frame consistency: The preservation of visual attributes (identity, layout, appearance) across consecutive frames in a video. Example: "improved cross-frame consistency"
- Cross-modal semantic understanding: The ability to align and interpret meaning across different modalities (e.g., text, image, audio, video). Example: "for cross-modal semantic understanding"
- De novo: From scratch; generation without relying on pre-existing footage. Example: "supporting both de novo video generation"
- Dual-channel audio: Two-channel (stereo) audio output that can convey spatial separation and layering of sounds. Example: "Its dual-channel audio output presents rich and nuanced layers"
- Editing consistency: The extent to which regions not targeted by an edit remain unchanged after processing. Example: "editing consistency"
- Elo: A rating system that ranks competitors based on pairwise outcomes, adapted here to compare model outputs via user preferences. Example: "Elo-style leaderboard"
- Framing / Composition: The arrangement of visual elements within the frame to guide attention and convey meaning. Example: "Framing / Composition"
- FVD: Fréchet Video Distance, an automated metric that evaluates the distributional distance between real and generated video features. Example: "metrics such as FVD or CLIPScore"
- High-amplitude actions: Large, vigorous movements (e.g., sports, combat) with significant displacement and energy. Example: "high-amplitude actions carry strong momentum"
- Lip synchronization: Matching mouth movements to spoken audio so that speech appears natural. Example: "Lip synchronization and action-audio alignment are both strong"
- Multi-Entity Feature Match: The evaluation of how well a model preserves and coordinates attributes across multiple subjects in a scene. Example: "Multi-Entity Feature Match"
- Multi-shot narrative: A sequence of coordinated shots (angles, sizes, movements) that together tell a coherent story. Example: "native, professional multi-shot narrative capability"
- Narrative pacing: The timing and rhythm with which a story’s events and cuts unfold to maintain coherence and engagement. Example: "narrative pacing"
- Non-Verbal Voice: Vocalizations without words (e.g., laughter, sighs, grunts) used to convey emotion or intent. Example: "Non-Verbal Voice"
- Off-Screen Voice: Speech or vocal sounds from a character not currently visible in the frame (voice-over or off-camera). Example: "Off-Screen Voice"
- Photorealism: The quality of resembling real-world imagery with convincing textures, lighting, and detail. Example: "weaker on photorealism and fine detail"
- Physical plausibility: The degree to which motions and interactions obey realistic physical laws. Example: "physical plausibility"
- Physics compliance: Adherence of generated motion and interactions to physical constraints and cause-and-effect. Example: "physics compliance"
- Rank Spread: A leaderboard statistic indicating the range or stability of a model’s rank positions across comparisons. Example: "The Rank Spread of 11"
- Reference alignment: How closely generated outputs match the content or attributes of provided reference inputs. Example: "reference alignment"
- SeedVideoBench 2.0: A comprehensive benchmark and evaluation framework for multimodal video generation and narrative quality. Example: "we upgraded our evaluation framework to SeedVideoBench 2.0."
- Shot sequencing: Planning the order and relationship of shots to structure a scene’s visual narrative. Example: "plan shot sequencing"
- Spatial Scene: Audio evaluation context involving spatial placement and movement of sounds within a scene. Example: "Spatial Scene"
- Surreal Motion: Motion that intentionally departs from real-world behavior to achieve dreamlike or impossible effects. Example: "Surreal Motion"
- Temporal alignment: Precise synchronization of audio events with visual timing and rhythm. Example: "precise temporal alignment"
- Temporal coherence: Consistency of appearance and motion across time so that a video does not jitter or drift. Example: "temporal coherence"
- Vision-LLM: A model trained to jointly process and align visual and textual information for tasks like captioning or generation. Example: "Seed-VL multimodal vision-LLMs"
Collections
Sign up for free to add this paper to one or more collections.

