GRPO, Dr. GRPO, and DAPO Are Three Operations on One Number: The Group-Standard-Deviation Identity
Published 30 Jun 2026 in cs.LG, cs.AI, cs.CL, and stat.ML | (2607.00152v1)
Abstract: Three of the most popular methods for training LLMs to reason look like three different tricks. They are not. All three adjust a single number: standard deviation, reflecting how much a prompt's sampled answers disagree. When such a model is trained, it answers each problem many times, and an automatic checker marks every answer right or wrong. The standard deviation of those marks measures the disagreement: largest when the answers split evenly between right and wrong, and zero when they all agree. Group Relative Policy Optimization (GRPO) divides by this number, GRPO Done Right (Dr. GRPO) drops the division, and Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) discards the groups where it is zero. Each is presented as its own fix, yet this paper proves they are three settings of one dial. That dial is not cosmetic: for right-or-wrong rewards, the disagreement is exactly the size of the training update, the group-standard-deviation identity. A split group teaches the most, while a unanimous group teaches nothing and falls silent. The same result says which problems deserve the most weight and how many tries each one needs. This paper confirms the intuition on a large real difficulty dataset (Big-Math) and in a controlled training run. What looks like a harmless normalization step is the dial that decides where learning happens and how strongly.
The paper demonstrates that GRPO, Dr. GRPO, and DAPO are unified via the group-standard-deviation identity, clarifying how per-prompt gradient magnitudes are determined.
It introduces a group-size law that links prompt difficulty to the sample size needed for reliable gradient estimates, providing a diagnostic tool for training efficiency.
Empirical validations confirm that normalization and silent-group handling significantly influence gradient distribution and learning speed in LLM reinforcement learning.
GRPO, Dr. GRPO, and DAPO: Formal Unification via the Group-Standard-Deviation Identity
Introduction and Context
The paper "GRPO, Dr. GRPO, and DAPO Are Three Operations on One Number: The Group-Standard-Deviation Identity" (2607.00152) elucidates the theoretical foundation underpinning three leading RLVR (reinforcement learning with verifiable rewards) algorithms used for supervising LLMs on reasoning-intensive tasks. Historically, Group Relative Policy Optimization (GRPO), Dr. GRPO ("Done Right"), and Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) have been presented as distinct algorithmic innovations, each purported to address specific technical bottlenecks in RL finetuning of LLMs, such as difficulty weighting, training efficiency, and robustness to prompt uncertainty.
This work demonstrates that these three algorithms are not fundamentally disjoint. Instead, they represent different manipulations of the same scalar: the standard deviation (σ) of per-prompt group rewards—binary signals from an external verifier assigned over multiple model-sampled responses to a single prompt. It is this "group-standard-deviation identity" that quantitatively characterizes the learning signal from a batch of sampled answers per prompt. The implications are concrete for algorithm choice, group sampling design, and theoretical clarity.
The Group-Standard-Deviation Identity
The primary technical result is that, when training with binary rewards (Ri∈{0,1}) over G samples, the per-prompt gradient update for GRPO is exactly
g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)
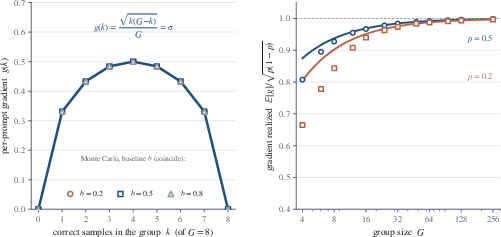
where σ=k(G−k)/G (for k correct out of G samples), and sˉ± are the mean scores for correct/incorrect responses, respectively. Thus, the magnitude of the update is determined by within-group disagreement: maximal at a k=G/2 split (highest uncertainty), zero in unanimous groups. This lets the three algorithms be written as manipulations of this scalar:
GRPO: Divides by σ—favors variance stabilization, and emphasizes learning where Ri∈{0,1}0 is small, i.e., at the hard and easy extremes.
Dr. GRPO: Removes the division—directly ascends the expected success rate, with flat weighting across difficulty.
DAPO: Discards groups with Ri∈{0,1}1, i.e., silent groups lacking right-vs-wrong contrast.
Figure 2: The group-standard-deviation identity, showing that the per-prompt gradient magnitude is maximized at intermediate Ri∈{0,1}2 values and vanishes for unanimous groups.
Group Size, Gradient Fidelity, and Sample Efficiency
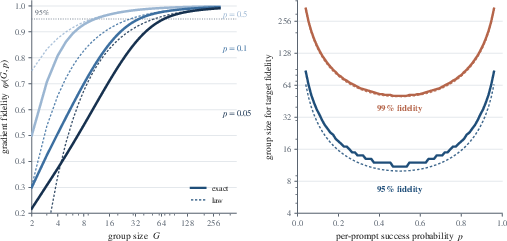
The paper formalizes a law relating prompt difficulty Ri∈{0,1}3 and required group size Ri∈{0,1}4 for desired fidelity in realizing the large-group (asymptotic) gradient:
Group-size law: To achieve fidelity Ri∈{0,1}5, the required group size is
Ri∈{0,1}6
This shows that, for hard prompts (Ri∈{0,1}7), Ri∈{0,1}8 must be much larger to obtain sufficient mixing in sampled responses, enabling informative gradient estimates. Conventional settings (e.g., Ri∈{0,1}9) are sample-efficient for medium-difficulty prompts but severely under-sample hard/easy tails.
Figure 4: Gradient fidelity G0 increases rapidly with group size for moderate G1, but requires very large G2 for extremal G3.
The Silent-Group Rate and DAPO's Strategy
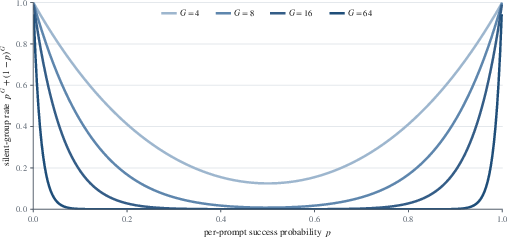
"Silent groups"—those for which all sampled answers agree—yield zero learning signal. Their frequency is:
G4
This fraction is significant for both very easy and very hard prompts, explaining why DAPO discards such groups and oversamples until G5 ("dynamic sampling").
Figure 1: Probability of encountering a silent group increases rapidly for extremal G6 and moderate G7, motivating adaptive sampling or discard strategies.
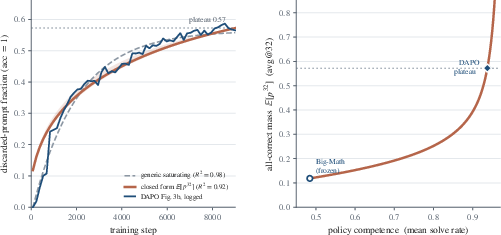
DAPO's logged fraction of discarded groups can be predicted by G8. Empirical confirmation on real data (Big-Math) and a simulated training loop substantiate these closed-form predictions.
Figure 3: DAPO's discarded-prompt fraction closely matches the closed-form prediction based on the silent-group mass.
Objective Choices and Difficulty Bias
Averaging the group-std identity over samples leads to:
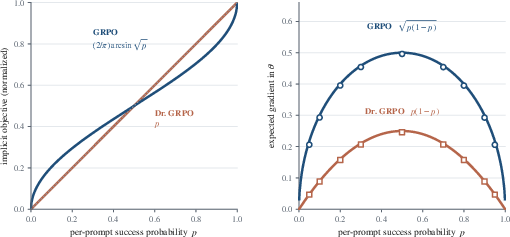
GRPO: Optimizes the arcsine surrogate objective G9, whose gradient is weighted by g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)0, emphasizing improvement where g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)1 is extremal.
Dr. GRPO: Optimizes the expected accuracy objective (g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)2), uniformly weighting difficulty.
The empirical effect is that GRPO's standardization redistributes training pressure, heavily amplifying gradient mass assigned to the easiest/hardest prompts—quantified as a 1.78g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)3 increase on Big-Math for extreme difficulties.
Figure 5: Comparison of raw success rate and the arcsine transform, along with per-prompt expected gradients, confirming the difficulty-dependent bias.
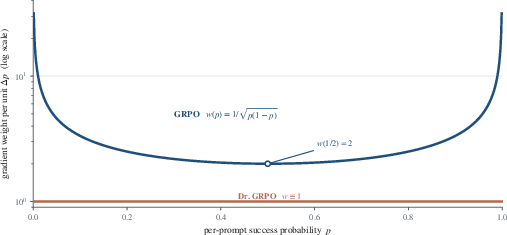
Figure 6: Difficulty weight g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)4 (log scale) diverges at g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)5 for GRPO, versus flat weighting for Dr. GRPO, elucidating the origin of the "question-level difficulty bias".
Real-World Prompt Difficulty Distribution and Empirical Validation
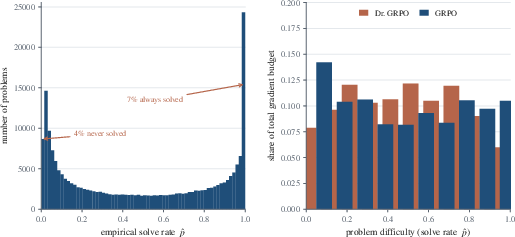
Utilizing the Big-Math dataset (215k+ problems; empirical Llama-3.1-8B solve rates), the authors demonstrate that both the gradient reweighting induced by normalization and the silent-group rates are substantial in practice. For g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)6, g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)7 of prompts are silent. The reweighting allocated to extremal difficulties by GRPO is nearly double that of Dr. GRPO in the large-group limit.
Figure 7: Left—Real difficulty distribution is bimodal. Right—Relative share of gradient budget by difficulty, showing GRPO's disproportionate allocation to extreme prompts.
Controlled Training Run: Predictions and Measured Dynamics
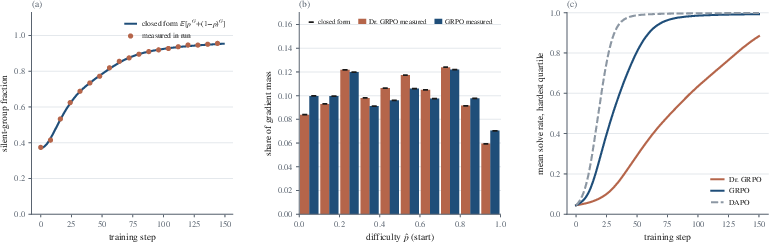
A controlled experiment with simulated Bernoulli-logit prompts confirms:
The measured silent-group fraction matches the closed-form prediction with g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)8.
The observed distribution of gradient mass by prompt difficulty matches theoretical expectations for both GRPO and Dr. GRPO.
Trajectories for hard prompts diverge: GRPO enables much more rapid mastery of hard cases, while Dr. GRPO lags, confirming the dynamic effect of the difficulty bias.
Figure 8: Empirical validation of closed-form predictions in live training: silent-group rates, gradient allocation by difficulty, and learning speed for hard prompts.
Theoretical and Practical Implications
This unification implies several practical and theoretical consequences:
Closed-form diagnostics: Practitioners can calculate, pre-training, how effective their group-size and sampling policies will be for their expected prompt difficulty distribution.
Objective and compute tradeoffs: The normalization step (dividing by g=G1i∑Ai∇θlogπθ(yi)=σ(sˉ+−sˉ−)9) offers a direct lever to shift training pressure—for better or worse—toward hard/easy prompts, and away from the medium-difficulty bulk.
Silent-group handling: Discarding or adaptive resampling (à la DAPO) is theoretically grounded; excessive silent groups highlight inefficiency in group-size selection or difficulty misalignment.
Efficiency gains and fairness: Uniform σ=k(G−k)/G0 is efficient for moderate σ=k(G−k)/G1 but misallocates effort elsewhere; adaptive σ=k(G−k)/G2 or reweighting may yield better training/compute balance.
Potential future work: The group-wise accounting framework may extend naturally to non-binary rewards, off-policy or KL-penalized updates, and alternative advantage constructions (e.g., rank-based, quantile, or clipped rewards), suggesting systematic ways to analyze and optimize RL algorithms for LLMs.
Conclusion
By establishing and validating the group-standard-deviation identity, this paper reframes GRPO, Dr. GRPO, and DAPO as related algorithmic points along a single control axis: the operation on the standard deviation of per-prompt group rewards. This clarity transforms three independently motivated techniques into a unified framework, yielding theoretical closed-form predictions for group-size planning, difficulty reweighting, and silent-group prevalence. The work enables precise diagnostic and design tools for practitioners while advancing clean theoretical understanding of RLVR optimization under realistic large-scale LLM training constraints.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.