- The paper derives a unified framework linking LLM policy optimization methods, transitioning from REINFORCE to PPO and advancing to GRPO.
- It demonstrates how structural interventions on trajectory probability and reward functional can stabilize reinforcement learning training and address specific failure modes.
- The study extends the framework to agentic RL and GRPO-OPD hybrids, highlighting opportunities for future research in multi-turn and hybrid reward scenarios.
A First-Principles Framework for LLM Policy Optimization: From Expected Reward to GRPO and Extensions
Introduction and Motivation
This paper presents a unified, first-principles framework for understanding and systematizing the modern landscape of policy gradient methods for LLM optimization. All such methods maximize the expected reward objective J(θ)=Eτ∼pθ(τ)[R(τ)], with the two fundamental axes of algorithmic design and diagnosis being the trajectory probability pθ(τ) ("trajectory side") and the reward functional R(τ) ("reward side"). The authors argue that most reinforcement learning (RL) algorithms and recent structural variants—ranging from REINFORCE to PPO to the modern critic-free GRPO and its extensions—are best understood as principled, minimal interventions on one or both of these axes in response to specific failures in the base estimator.
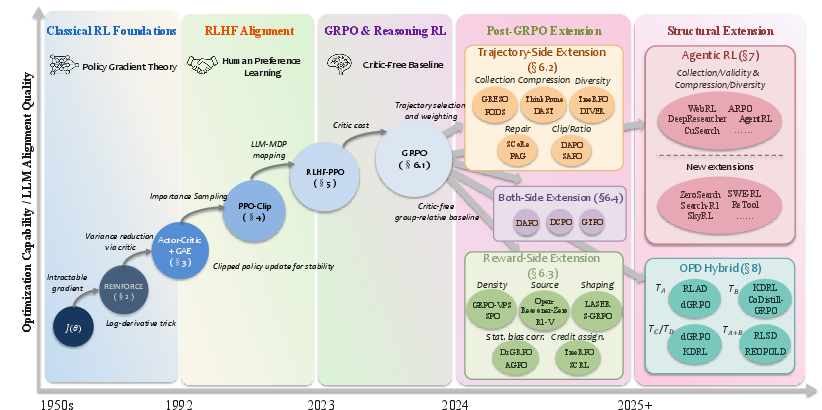
Figure 1: A first-principles landscape of LLM policy optimization delineating the trajectory axis (pθ(τ)) and reward axis (R(τ)), tracing method transitions (REINFORCE → PPO → GRPO) and forking into trajectory-side, reward-side, and coupled extensions; Agentic RL generalizes the trajectory side, GRPO-OPD hybrids generalize the reward side.
From Policy Gradient to GRPO: Structural Organization
The paper begins by reconstructing the classic policy gradient derivation in the language modeling context. The log-derivative trick converts the intractable gradient into a sampling-based estimator, and the REINFORCE and actor-critic architectures implement unbiased or variance-reduced estimators based on reward-to-go and advantage estimation. Proximal Policy Optimization (PPO) further stabilizes and improves data efficiency via trust-region clipping and importance-reweighted data reuse.
A key argument is that LLM generation is an MDP with deterministic transitions and tractable policy gradients. The typical RLHF pipeline (supervised fine-tuning, reward modeling, RL fine-tuning) can thus be mapped precisely onto the two-factor frame, with per-token credit assignment issues made explicit in the token-level reward construction.
The Rise of GRPO and the Two-Axis View
Group Relative Policy Optimization (GRPO) emerges as a critical innovation: by replacing the high-variance, compute-intensive learned critic with a group-relative advantage computed from group-normalized rewards, GRPO achieves strong sample efficiency and mathematical reasoning performance with minimal infrastructure overhead. The paper positions this as a "pure reward-side substitution," leaving the rest of the trajectory logic from PPO or RLHF-PPO intact.
Subsequent variants, surveyed in detail, systematically address trajectory-side (e.g., sample collection, compression/reuse, diversity management, repair) or reward-side (e.g., reward density, bias correction, credit assignment) failures, or deal with coupled failures which require simultaneous intervention. This results in a taxonomy where every method can be precisely located as its modification target and corresponding failure.
Trajectory-Side Variants
Trajectory-axis interventions span methods to increase signal-to-noise ratio via prompt or trajectory selection (GRESO, Prompt Replay/PODS, adaptive allocation), amortize rollout cost (ThinkPrune/DAST, replay-based approaches), or augment group diversity (TreeRPO, DIVER, GAPO, dual-scale regularization). Structural mismatches and inefficiencies, such as per-token versus sequence-level granularity in importance ratios, are addressed by update rule modifications (DAPO, GSPO) and more sophisticated clipping strategies.
Reward-Side Variants
Reward-axis interventions seek to densify, shape, or multi-objectify the reward signal (e.g., process rewards, step/segment-level signals), correct normalization/statistical biases (e.g., Dr.GRPO, AGPO, CPPO), and target the credit assignment pathologies of uniform scalar broadcast (TreeRPO, HighEnt, segment-level or subproblem decomposition). The authors emphasize that the greatest training instabilities (entropy collapse, gradient dilution) are compound phenomena, requiring careful co-design or entirely novel operator placement.
Structural Extensions: Agentic RL and GRPO-OPD Hybrids
The framework is shown to scale to settings where either:
- The trajectory side is expanded—to agentic RL, where trajectories are multi-turn, interleaving tool-use decisions and environment feedback (WebRL, AgentRL, Search-R1). Here, new failure modes such as rollout validity, importance ratio staleness, and high environment cost appear, as do new reward-side challenges, notably temporal credit assignment and complex reward specification.
- The reward side is expanded—to hybrids of GRPO and On-Policy Distillation (OPD). These methods introduce per-token, teacher-driven signals into the reward pipeline without discarding the J(θ) frame. The paper develops an operator-based taxonomy (TA importance ratio, TB advantage, pθ(τ)0 in-expectation distillation, pθ(τ)1 external regularizer), showing how different hybrids stabilize or moderate the regimes where either verifier or teacher signals are degenerate.
Unification, Technical Implications, and Open Problems
The major technical claim supported in the paper is that the two-factor framework is simultaneously unified, diagnostic, and extensible:
- Unification: All surveyed methods (including very recent ones) and their boundaries (e.g., DPO, pure-KL distillation) can be precisely mapped along the two axes, with clear separation of what each fix resolves or leaves open.
- Diagnosis: Every instability—be it entropy collapse, over-optimization, sparse/degenerate learning signal—can be exactly localized, preventing misinterpretation of symptoms and supporting minimal, targeted intervention design.
- Extensibility: The analytical axes support transfer to agentic RL, to reward/teacher hybrids, and (with caveats) to multimodal or diffusion LLMs.
The paper highlights persistent gaps and directions for future work:
- Absence of joint design theory: There is no principled recipe for when or how trajectory and reward side interventions must be paired—most combined approaches are ad hoc, and rigorous characterization of cross-operator transfer or stability is missing.
- Boundary crossings: Mixing or transferring methods (e.g., clipping strategies, advantage bias corrections) between single-turn and agentic or hybrid contexts is nontrivial, with many pathologies newly emergent (e.g., teacher signal degradation, joint signal collapse).
- Operator-level design: The full principled space of how teacher and verifier signals should be mixed or fused remains largely unexplored, particularly with regards to proper in-expectation and out-of-expectation placements.
Conclusion
This work formalizes a two-axis, first-principles framework for LLM policy optimization, unifying recent advances in trajectory and reward factorization, systematic diagnostic of failures, and expansion to multi-turn and hybrid reward settings. The framework provides actionable structure for both practical method development and theoretical investigation and identifies precise locations where further innovation or theoretical support is required.