- The paper proposes a novel framework using RL in the semantic (language) space to decompose and sequence pretrained skills.
- It demonstrates that semantic RL outperforms traditional action-space RL, attaining up to 80% success in complex, long-horizon tasks.
- The approach leverages contextual language prompts and dynamic candidate selection to rapidly adapt pre-trained VLA models for real-world challenges.
Adapting Generalist Robot Policies with Semantic Reinforcement Learning
Introduction and Motivation
Generalist robot policies, notably vision-language-action (VLA) models, have enabled broad skill repertoires in robotics by leveraging large-scale pretraining on diverse data. However, solving complex, long-horizon tasks that fall outside the pretraining distribution remains challenging. The canonical RL approach—optimizing directly over low-level robot actions—presupposes a base policy whose action distribution already closely approximates a task-optimal behavior. For novel or compositional tasks requiring decomposition and grounding in physically realizable skills, this assumption often fails.
This paper introduces a paradigm shift by proposing to steer pretrained VLAs at deployment via RL operating on the semantic space of language prompts, rather than the action space. By treating language prompts as semantic actions, RL can efficiently probe and compose existing skills encoded within a VLA’s policy. This enables structured exploration and efficient adaptation, especially in settings where the VLA’s zero-shot performance is insufficient for the task requirements.
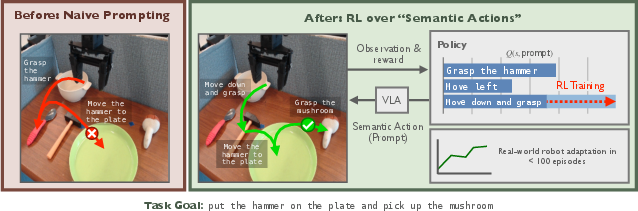
Figure 1: RL over language prompts leverages pretrained semantics to discover effective task-solving compositions, allowing adaptation in under 100 episodes.
Methodology: RL in Semantic Action Spaces
The central contribution is a framework for learning a semantic RL policy that selects language commands as actions. Each RL step involves selecting a language instruction, inputting it to the VLA, and executing the resultant behavior on the robot. The process induces a semantic Markov Decision Process (semantic MDP), where the “action” is a language prompt and the VLA serves as a (potentially complex) transition function from language to low-level behavior.
Naïvely optimizing over unconstrained natural language is intractable, so the candidate prompt space is dynamically restricted using state-of-the-art vision-LLMs (VLMs) to generate contextually relevant language instructions. However, VLMs lack deployment grounding; their selected prompts may not yield effective or safe behaviors. Thus, the RL agent learns a Q-function over (state, prompt) pairs, optimizing for task progress and correcting for VLM hallucinations or misalignments with the real system.
This approach contrasts with prior methods: residual RL and methods like DSRL [wagenmaker2025steering] operate directly in the action space and are fundamentally limited by the initial policy's action distribution. Hierarchical and prompt-sequencing approaches that use VLMs for decomposition lack robust grounding mechanisms and do not improve from direct feedback.
Experimental Results
The proposed framework is evaluated across challenging, long-horizon tasks in both simulation (Libero-10 [liu2023libero]) and real-world deployment on a WidowX robot. Tasks require multistep object manipulation, compositional skills, and overcoming OOD scenarios.
Key findings:
- RL over semantic actions improves the VLA’s performance from near-zero to up to 80% success within 60–100 episodes, significantly outpacing traditional action-space RL and adaptive language prompting baselines.
- The approach enables novel capabilities, such as decomposing and sequencing pre-trained skill repertoires for tasks not solvable by direct prompting or fixed-action RL steering methods.
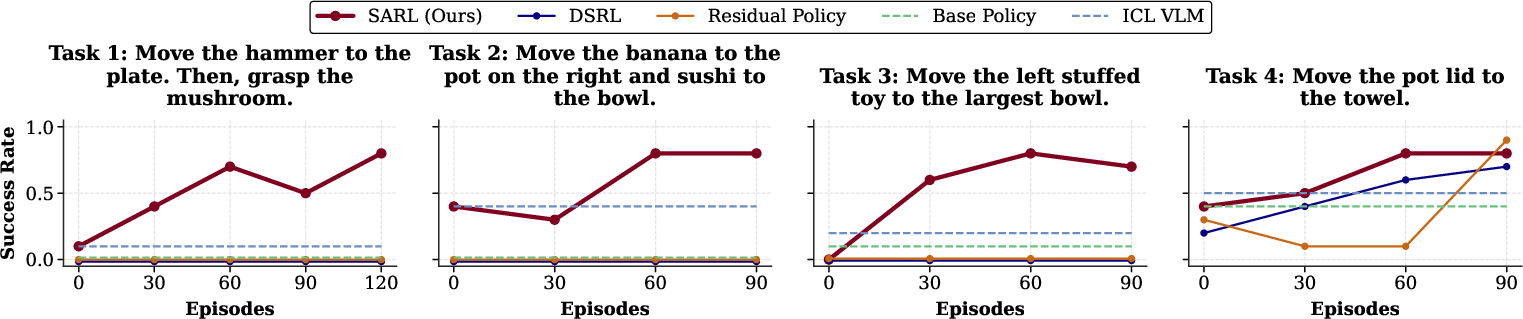
Figure 3: Improvement in policy success rates using semantic RL across four real-world tasks, surpassing DSRL and ICL VLM-based steering.
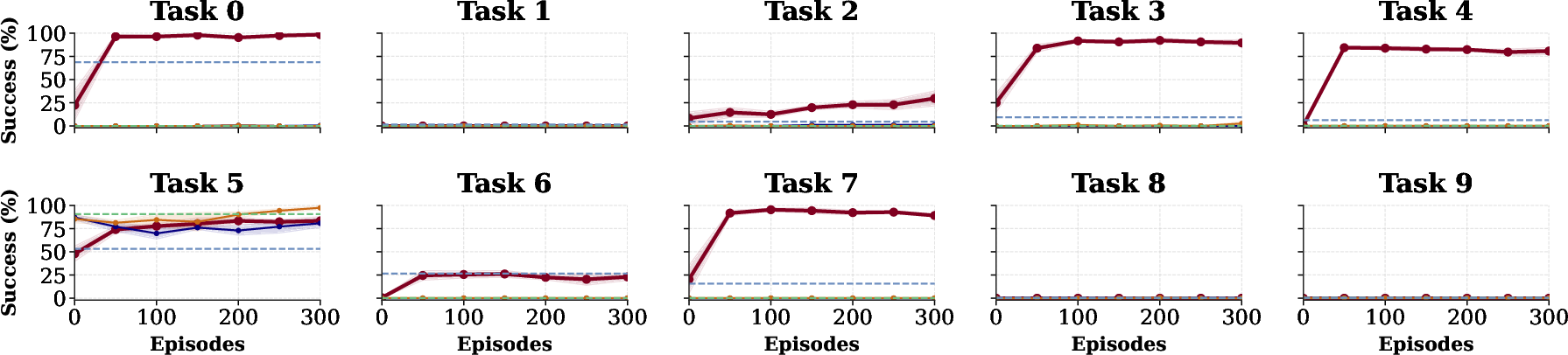
Figure 2: Consistent outperformance over DSRL and action-space methods on long-horizon Libero-10 tasks, with sample-efficient adaptation observed.

Figure 4: Experimental suite includes challenging object manipulation on the physical WidowX platform and simulated Libero-10 tasks.
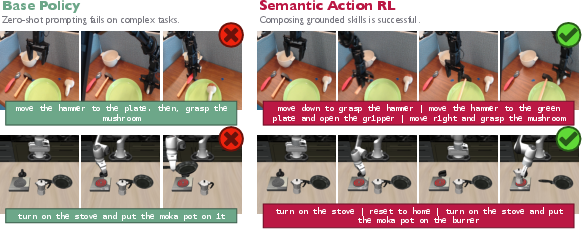
Figure 5: Zero-shot VLA fails on long-horizon tasks; semantic RL learns to sequence transferable skills for robust performance.
Notably, standard action-space RL approaches (DSRL, residual RL) only succeed when the base VLA action distribution already covers the necessary behaviors. For complex, unseen tasks, these methods become ineffective due to misspecified priors and limited exploration funnels. In contrast, semantic RL explores the behavioral prior more globally, synthesizing new compositions by discovering effective prompt sequences.
On the other hand, VLM-instructed prompting can decompose goals but lacks the grounded, empirical feedback loop required for robust adaptation, as VLMs neither have access to in situ robot feedback nor learn from failures. The semantic RL policy, trained over repeated interaction, learns to associate semantic instructions with their real-world consequences, adjusting to avoid ineffective or unsafe actions.

Figure 6: VLM prompting yields semantic but ungrounded behaviors; semantic RL learns to issue instructions that are both contextually appropriate and physically effective.
Theoretical and Practical Implications
The work provides a strong empirical demonstration that the design of a robot’s action space—semantic (language) versus physical (motor/torque)—critically determines the tractability and efficiency of adaptation for out-of-distribution or compositional tasks. RL operating in the semantic space leverages structured priors and ensures that exploration is both meaningful and physically realizable. This both constrains and accelerates learning, especially with expressive VLAs.
Theoretical implications include highlighting the compositionality and transfer benefits of leveraging pretrained skill libraries via language, as well as the distinctions between hierarchical policy architectures and prompt-space RL for embodied control. Practically, the framework paves the way for robust deployment-time adaptation in service robots, industrial automation, and any scenario where task requirements can outstrip original pretraining data.
Limitations include the reliance on VLMs for semantic action candidate generation—incurring inference overhead—and the dependence on a diverse and grounded VLA policy. If the VLA cannot express a wide range of behaviors, semantic RL is similarly bottlenecked.
Future Directions
- Scaling to Richer Semantic Spaces: Future advances in VLMs and generative LLMs could further enhance the diversity and precision of candidate prompts, enabling even richer task decompositions.
- Combining Semantic and Action-Space RL: An interesting avenue is integrating semantic-action RL with action-level fine-tuning for tasks requiring both high-level composition and low-level skill acquisition.
- Efficient Generalization Across Embodiments: The compositional structure attained through semantic RL could facilitate efficient cross-platform transfer and meta-RL for varied robot morphologies.
- Language-Grounded Safety and Verification: Semantic RL introduces a new axis of abstraction for safe robot learning, enabling natural integration of human-in-the-loop corrections.
Conclusion
This work demonstrates that RL over the language prompt space of generalist robot policies enables sample-efficient, robust adaptation to complex and long-horizon tasks. By leveraging pretrained semantics via VLA models, the proposed approach achieves expressive exploration and rapid deployment-time learning on systems where action-space RL fails. These results both refine the design space for adaptive embodied intelligence and highlight language as a powerful interface for future generalist robotics (2606.31958).

