- The paper presents a novel closed-form model for GRPO, mapping reward trajectories to a stochastic damped oscillator for improved interpretability.
- It details how key factors like momentum, off-policy lag, and group size quantitatively affect training dynamics and stability transitions.
- Empirical validation across multiple LLMs confirms the model's predictions, offering actionable diagnostics for reward hacking and failure modes.
Introduction and Motivation
The paper "Predictable GRPO: A Closed-Form Model of Training Dynamics" (2606.30789) introduces a mechanistically grounded, closed-form theory for training dynamics under Group Relative Policy Optimization (GRPO), a reinforcement learning (RL) protocol widely used to post-train LLMs for enhanced reasoning capabilities. Previous work often relied on empirical curve-fitting with little interpretability regarding the underlying training mechanics, leaving hyperparameter selection dominated by heuristic trial-and-error. Here, the authors provide a first-principles model, formulating GRPO training as a stochastically driven damped oscillator, whose parameters are fixed analytically by hyperparameters and a measurable curvature scale, rather than being inferred post hoc.
Theoretical Framework
The central theoretical advance is the mapping of the mean reward trajectory under GRPO to the dynamics of a stochastic second-order system. Assuming the expected reward summarizes the policy (mean-field assumption), the update rule underlying GRPO—including momentum, off-policy lag, and group size effects—reduces to a driven damped oscillator. Specifically:
- Momentum introduces inertia, promoting the system to second-order dynamics.
- Off-policy lag, associated with staleness in policy updates, erodes effective damping and introduces delay dynamics.
- Group size manifests as a "noise temperature," with stochastic fluctuations in the reward scaling as $1/G$.
The model provides algebraic expressions for the system's effective mass, damping, and stiffness in terms of learning rate, momentum, refresh interval, KL anchoring, and the curvature at the fixed reward point. Importantly, the framework subsumes previously empirical single-exponential fits as the overdamped limit of this second-order system, and it mechanistically explains features such as the "slow-start" phase in training curves, which elude first-order descriptions.
The dynamical reduction gives rise to several concrete, testable assertions:
- Plateau, Timescale, and Exponents: The plateau, approach rate, and size exponent seen in prior fits are assigned mechanistic meaning as the fixed point, inverse stiffness, and curvature-exponent, respectively.
- Transition Between Regimes: The system predicts a sharp threshold in the policy refresh interval for stability, beyond which the deterministic reward dynamics become underdamped or unstable, manifesting as oscillatory or divergent behavior.
- Group-Size Invariance and Fluctuations: The mean reward trajectory is invariant to group size at leading order, but the stationary fluctuations scale as $1/G$.
- Distinction of Failure Modes: Diagnostics disentangle reward hacking, advantage degeneracy, policy concentration, and dynamical instability, which are otherwise conflated in single reward curves.
The model's parameters, and thus its predictions, are pinned by measurable coefficients rather than retrospective fits.
Empirical Validation
Experiments span three instruction-tuned and reasoning-distilled LLMs—Nemotron-Mini-4B, DeepSeek-LLM-7B-Chat, and DeepSeek-R1-Distill-Qwen-1.5B—trained on GSM8K with G∈{4,16}. Main observations include:
Empirical diagnostics further distinguish between reward hacking (decoupling of train and eval rewards), mode collapse (degeneration in advantage computation), policy concentration (policy entropy decline), and dynamical instability (divergent gradient norms), thereby localizing when and where the closed-form model applies.
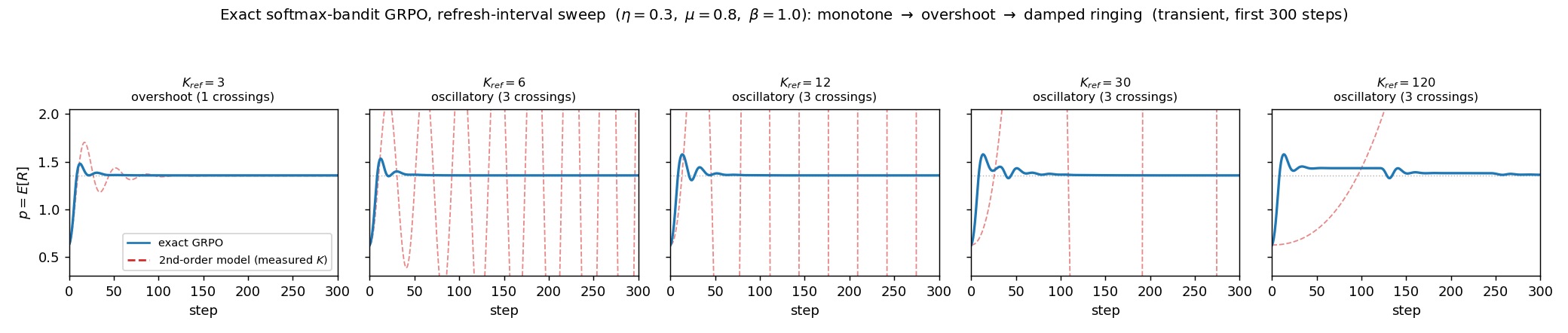
Oscillatory Regimes and Phase Boundaries
A controlled exact reduction in a softmax-bandit scenario, where the mean-field assumption holds precisely, is used to exercise the underdamped and unstable regimes. By varying the policy refresh interval, the predicted monotone-to-oscillatory transition is observed. The empirical monotone–oscillatory frontier aligns tightly with the analytically predicted phase boundary based on independently measured curvature, corroborating the theoretical stability threshold.
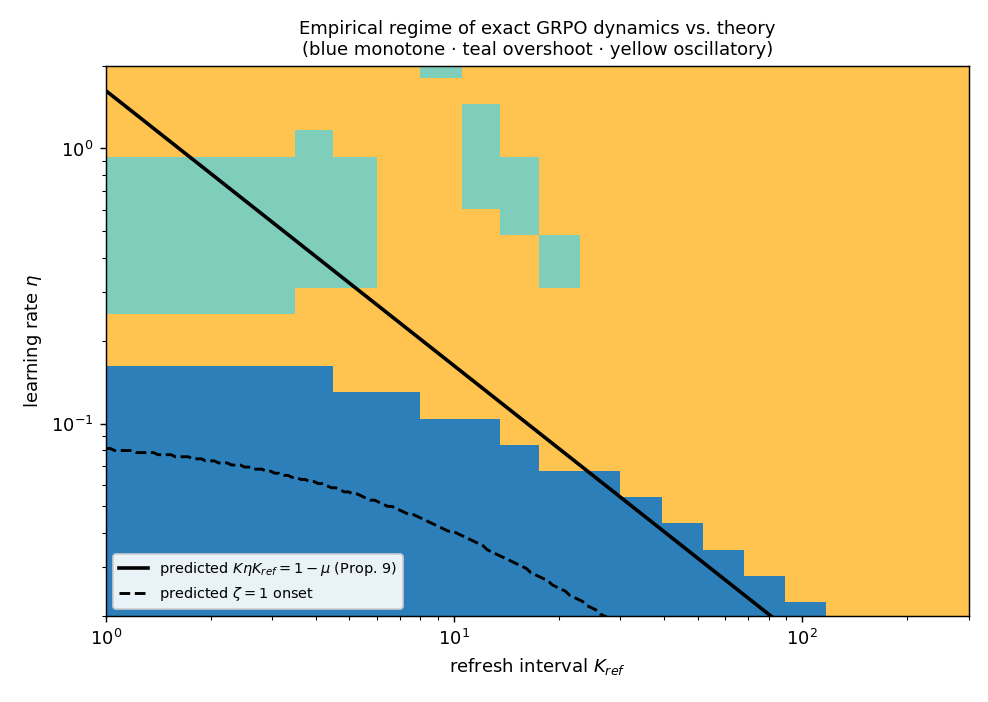
Figure 2: Empirical regime map for the exact softmax-bandit GRPO dynamics; the observed monotone–oscillatory transition boundary closely tracks the analytic stability line predicted from local curvature and optimizer settings.
Practical and Theoretical Implications
The mechanistic model not only forecasts training curves from configuration but provides actionable criteria for the selection of hyperparameters—particularly learning rate, momentum, and refresh interval—by explicitly quantifying regions of stability and efficient convergence. This clarity can reduce compute costs by minimizing the trial-and-error explorations typical in RL post-training. The diagnostics developed further allow practitioners to identify and interpret distinct failure mechanisms, guiding intervention strategies.
Theoretically, the model deepens our understanding of the high-level statistical mechanics of large-scale RL training. It connects observed scaling laws and saturation phenomena to underlying dynamical systems, suggesting potential routes for analytic understanding of higher-order effects (such as residual group-size dependence) and nonlocal phenomena (global, rather than local, curvature influences).
Future Directions
Several avenues arise naturally from this research:
- Deep-Network Demonstration: Extending the explicit testing of underdamped and unstable regimes within deep/network-scale settings, where the mean-field assumption is only approximate.
- Beyond Leading Order: Modelling the empirically observed residual group-size dependence in within-group advantage spread, moving past the temperature-only narrative.
- Global Dynamics: Analysing nonlocal, prelinear trajectories to enclose the entire course of training, including the emergence of mode concentration and advantage degeneration.
- Scaling Exponents: Relating the curvature-scaling exponents predicted by the reduced-order model to underlying properties of model scaling and neural tangent kernel (NTK) regimes.
Conclusion
"Predictable GRPO: A Closed-Form Model of Training Dynamics" (2606.30789) delivers a substantive shift from descriptive to predictive modelling of RL training in LLMs by grounding empirical reward-saturation laws in the mechanistic dynamics of a stochastically-driven damped oscillator. The derived closed-form connects configuration directly to learning behavior, rigorously delineates stability regimes, and enables nuanced diagnostics of training pathologies. These contributions enhance both the scientific and practical handling of compute-intensive RL post-training for LLMs and set the stage for further theoretical advancements in the field.