- The paper introduces the UARM framework that uses calibrated quantile regression with conformal calibration to estimate uncertainty in reward models.
- It presents heteroscedastic advantage reweighting to downweight unreliable samples, thereby stabilizing group-based policy optimization in RLHF.
- Empirical results on multiple datasets show enhanced prediction metrics and reduced error rates, reinforcing robustness in LLM alignment.
Uncertainty-Aware Reward Modeling for Stable RLHF
The paper "Uncertainty-Aware Reward Modeling for Stable RLHF" (2606.19818) addresses two central vulnerabilities inherent in contemporary RLHF pipelines for LLMs: (1) reward models (RMs) are deterministic point estimators incapable of quantifying the reliability of their reward predictions, and (2) group-based relative policy optimizers, notably GRPO, blindly amplify unreliable reward signals via intra-group standardization. These flaws are exacerbated as policies explore responses substantially out-of-distribution with respect to RM training data, incentivizing reward hacking where optimization trajectories exploit spurious, high-reward, low-confidence outputs. The authors show that uniform treatment in GRPO can penalize genuinely aligned responses while disproportionately favoring confusing, uncalibrated ones.

Figure 1: GRPO's uniform standardization amplifies unreliable rewards, assigning excessive advantage to low-confidence outputs while penalizing genuinely aligned responses.
UARM Methodology
The proposed Uncertainty-Aware Reward Modeling (UARM) framework is decomposed into two phases to stabilize RLHF by exploiting calibrated reward uncertainty. The offline phase equips the reward model with per-sample interval estimates via quantile regression and conformal calibration; the online phase integrates this uncertainty as a reliability weight in GRPO advantage calculation, suppressing unreliable samples.
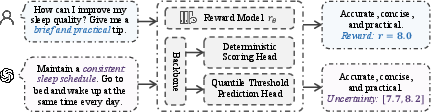
Figure 2: UARM architecture: offline quantile-based conformal calibration for per-sample uncertainty estimation, followed by heteroscedastic reweighting in the GRPO advantage during online RL optimization.
The RM is parameterized to output K+1 conditional quantiles [q^0(x),...,q^K(x)] for each prompt-response pair x, trained jointly via pinball loss. The median quantile serves as the point reward, while the union of consecutive interquantile intervals forms calibrated prediction intervals. Conformal prediction ensures that these intervals provide asymptotic conditional coverage, yielding a robust, instance-wise uncertainty measure via the interval width. This is operationalized by a conformity score over a held-out calibration set, permitting controlled coverage guarantees under exchangeability and unimodality assumptions.
Heteroscedastic Advantage Reweighting
UARM interprets the calibrated interval width as observation noise, converting it to a heteroscedastic variance estimate for each sample. The intra-group reward variance is decomposed into signal and noise components, with the latter reflecting measurement uncertainty. The uncertainty-aware GRPO advantage is defined as:
A~i=σsignal2+σnoise,i2σsignal2⋅σsignalri−μ
where the reliability prefactor systematically suppresses the contribution of high-uncertainty samples, preventing their reward-driven amplification in policy updates. When noise is uniform, this formulation collapses to standard GRPO.
Empirical Analysis
Experiments were conducted on HelpSteer, UltraFeedback, and PKU-SafeRLHF datasets. UARM was benchmarked against model-based uncertainty quantification (MC-Dropout, Deep Ensembles, DER, Packed Ensemble, TorchNaut, MCNF) and distribution-free interval estimators (SCP, CQR, WCP, ACI, SCCP, Clear, CPCP). Evaluation used uncertainty-ranked regression metrics (R2@50, MSE@50, MAE@50) computed on the 50% most confident samples, probing the reward model's calibration and precision.
Across all datasets, UARM exhibits superior uncertainty-ranked prediction performance, attaining the highest R2@50 and lowest MSE@50/MAE@50 values, substantially outperforming baselines. For instance, UARM improves R2@50 from 0.527 to 0.543 (HelpSteer), 0.770 to 0.794 (UltraFeedback), and 0.955 to 0.985 (PKU-SafeRLHF), with pronounced error reduction, especially on safety-critical tasks. This corresponds to more accurate reward estimation and improved sample selection for downstream optimization. The results validate that UARM's conformal quantile-based uncertainty signals are more discriminative and reliable than ensembles or marginal coverage estimators.
Implications and Future Directions
UARM represents a theoretically principled and computationally efficient approach to integrating calibrated reward uncertainty into RLHF, mitigating reward hacking by suppressing spurious outliers in group-based policy optimization. Its heteroscedastic reweighting mechanism is directly compatible with GRPO and incurs negligible overhead relative to ensemble-based UQ. This interface between predictive interval calibration and reinforcement learning advantage computation is generalizable to other value-function-free RLHF architectures and potentially broader RL applications subject to noisy, overoptimizable signals.
Practically, UARM advances the stability and trustworthiness of LLM alignment, particularly as policies explore responses far from RM training distribution. Theoretically, this approach strengthens guarantees around uncertainty quantification in reward-driven optimization, reinforcing the role of conditional coverage in RL.
Future work should consider adaptive online calibration under distribution shift, integration with other policy optimization schemes (beyond GRPO), and further theoretical analysis of its convergence properties and robustness to reward hacking. There is also scope for examining its impact in larger-scale, cross-domain RLHF, and on the generalization and safety of agentic LLMs.
Conclusion
The paper delivers a rigorous approach to reward model uncertainty quantification and its direct application to stable RLHF via UARM. By coupling calibrated quantile intervals with heteroscedastic advantage weighting, UARM both detects and suppresses unreliable reward signals, resolving critical vulnerabilities present in deterministic reward estimation and standard group policy optimizers. Empirical results demonstrate its effectiveness across multiple preference datasets, and the framework offers foundational improvements in the design of robust and reliable RLHF pipelines for LLM alignment.