- The paper introduces a revised scaling formula using Cauchy–Schwarz bounds to maintain accuracy under variable input scaling.
- It empirically demonstrates that the new scale-invariant method (OS II-prop) achieves robust accuracy similar to accurate mode while preserving fast throughput.
- The integrated theoretical analysis and experimental validations pave the way for reliable mixed-precision matrix multiplication in diverse scientific applications.
Improved Scaling in Fast Mode of Ozaki Scheme II: A Technical Assessment
Introduction
Ozaki Scheme II constitutes a generalization and refinement of techniques for emulating high-precision matrix multiplication via low-precision hardware, prominent within contexts of accelerating scientific computing on modern GPUs. The growing performance gap between low-precision (FP8/INT8) and high-precision (FP32/FP64) units motivates such emulation, enabling scientific workloads to capitalize on high-throughput matrix engines that would otherwise only serve machine learning pipelines. This paper critically investigates the scaling step in Ozaki Scheme II, focusing on the fast mode, identifies a fundamental scale invariance flaw, and introduces an improved, scale-invariant formula. The proposed method realizes robust accuracy matching that of accurate mode while maintaining the higher throughput inherited from fast mode.
Background and Analysis of Previous Schemes
Ozaki Scheme II utilizes the Chinese Remainder Theorem (CRT) to decompose high-precision matrix multiplication into a sequence of low-precision integer GEMMs. The conversion from floating-point to integer matrices relies upon scaling factors (μ,ν) chosen to preserve CRT recovery, constrained by the uniqueness threshold (product entries must not exceed P/2 where P is the product of moduli). Two main scaling modes exist:
- Accurate mode: Determines scaling factors using an auxiliary INT8 GEMM, directly bounding the actual product and achieving maximal allowed use of integer range. Computational overhead is significant due to the extra GEMM.
- Fast mode: Estimates scaling factors using the Cauchy--Schwarz inequality, forgoing the auxiliary GEMM. This yields considerable acceleration, but as the paper demonstrates, the scaling formula was not scale-invariant and could fail CRT uniqueness under certain input scalings.
The absence of scale invariance means that multiplying the original matrices by a scalar factor can either overly compress the representable integer range—degrading accuracy for large scalars—or trigger recovery failure (entries exceeding P/2) for small scalars. This is analytically validated and demonstrated numerically.
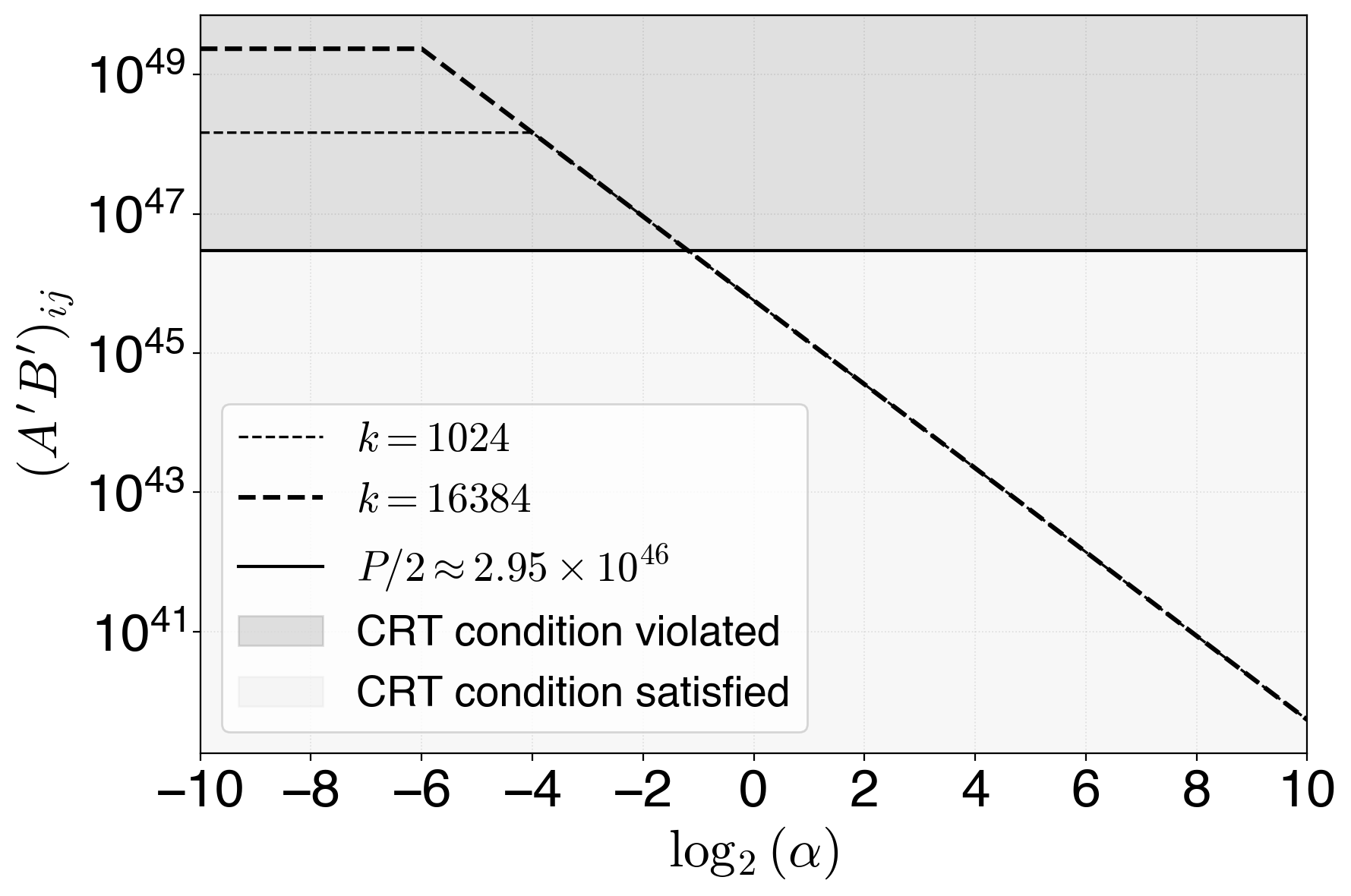
Figure 1: (A′B′)ij in the original fast mode as a function of scaling factor α=2s for all-one input matrices, showing violation of the CRT uniqueness threshold (“CRT recovery failure”) for some α.
The core contribution is a revision of the fast mode scaling formula: instead of the earlier approach that leads to a variable effective integer width depending on input scaling, the proposed formula tightly derives the maximal, scale-invariant power-of-two scaling factors directly from the CRT uniqueness condition and the Cauchy--Schwarz bound. All logarithm evaluations are carefully bounded considering floating-point implementation error.
The refined approach maintains both analytical and practical adherence to the scale-invariance property: for any scalar multiple of the input matrices, the bit width of the scaled integer matrices is maintained, and entries never violate the CRT constraint.
Experimental Results
Accuracy Characteristics
Comprehensive experiments on NVIDIA GH200 GPUs reveal that the original fast mode exhibits degraded accuracy or outright failure depending on input scaling and problem size, consistent with the theoretical flaw identified. In contrast, the proposed method—named OS~II-prop—matches the robust accuracy of accurate mode (OS~II-accu) across all tested scalar multiples and matrix classes.
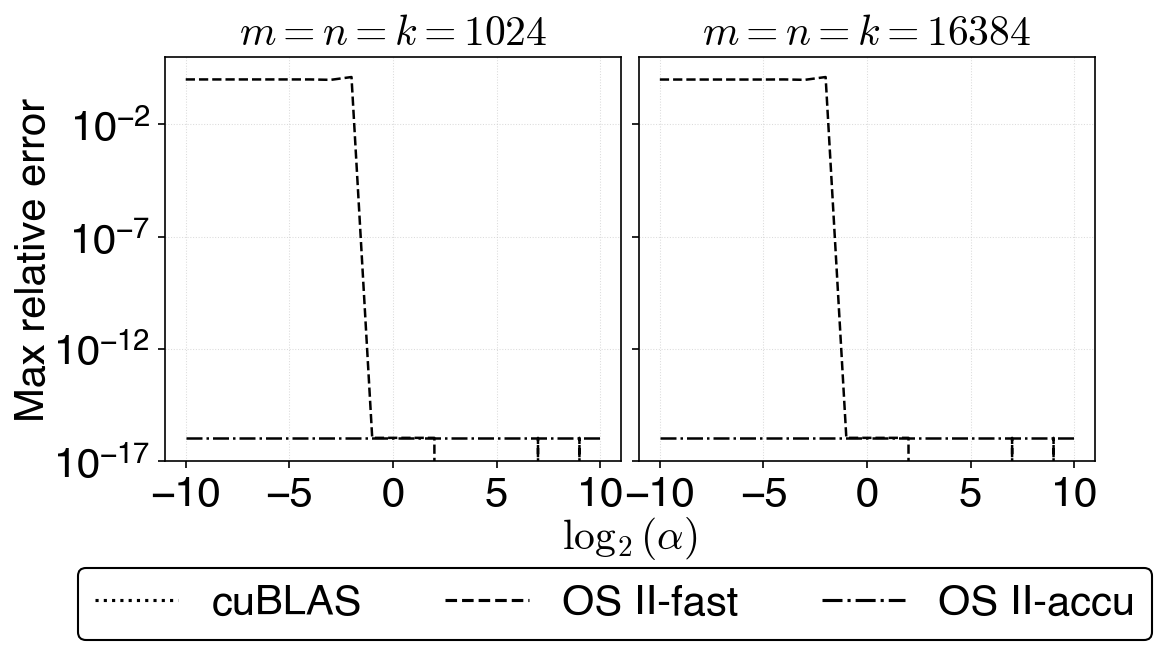
Figure 3: Maximum relative error of DGEMM versus input scaling (α=2s) for random and all-ones matrices, demonstrating breakdowns in OS~II-fast but not in OS~II-prop or OS~II-accu.
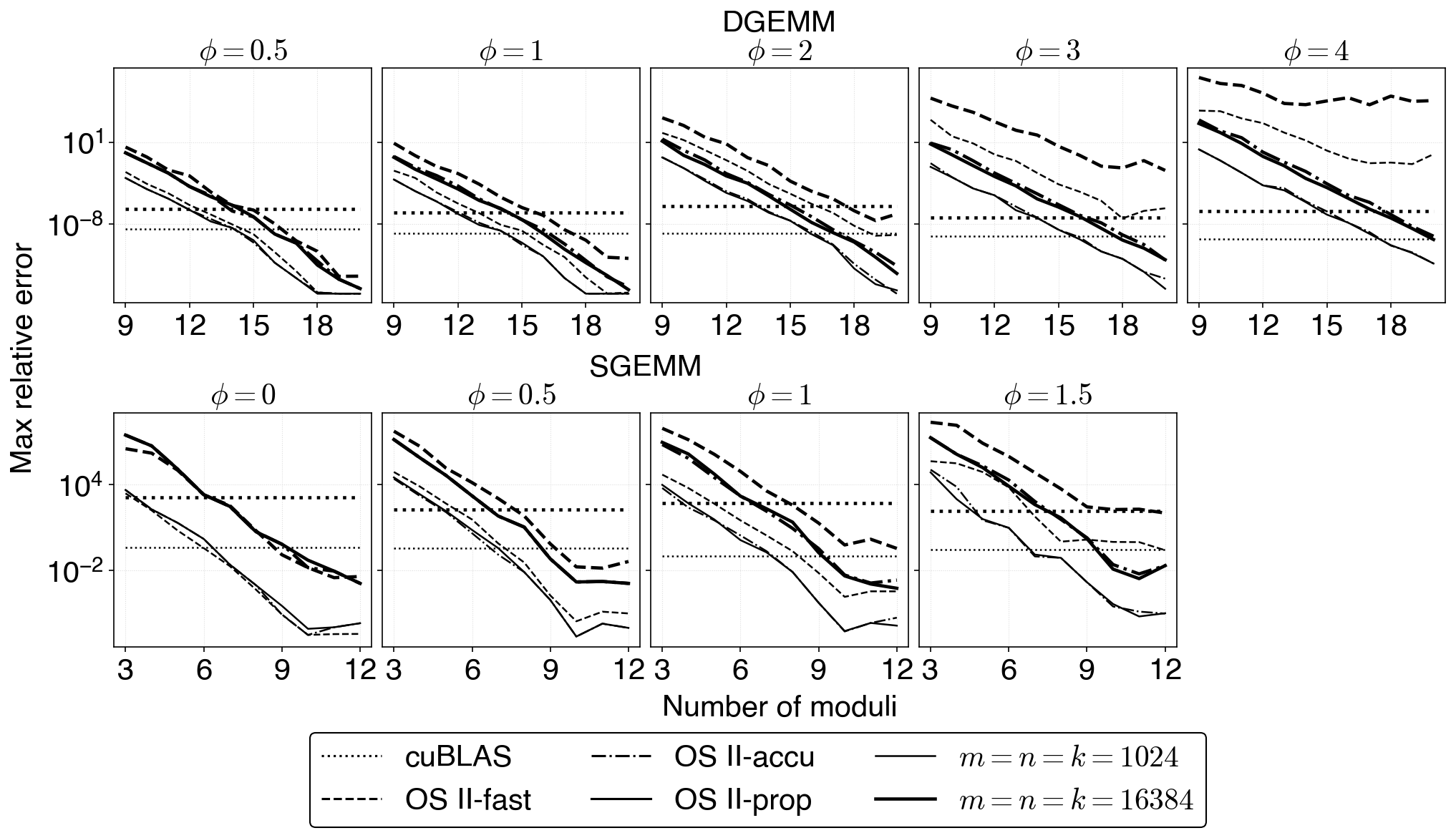
Figure 2: Error comparison across number of moduli N for different ϕ (spread of input magnitudes), showing OS~II-prop matching OS~II-accu even for ill-conditioned inputs.
Throughput Scaling
Throughput is benchmarked for varying problem dimensions, moduli count, and matrix stochasticity levels. The new method retains fast mode’s substantial speed advantage over accurate mode, with only negligible discrepancies in extremely degenerate parameter regions (e.g., small P/20, large P/21).
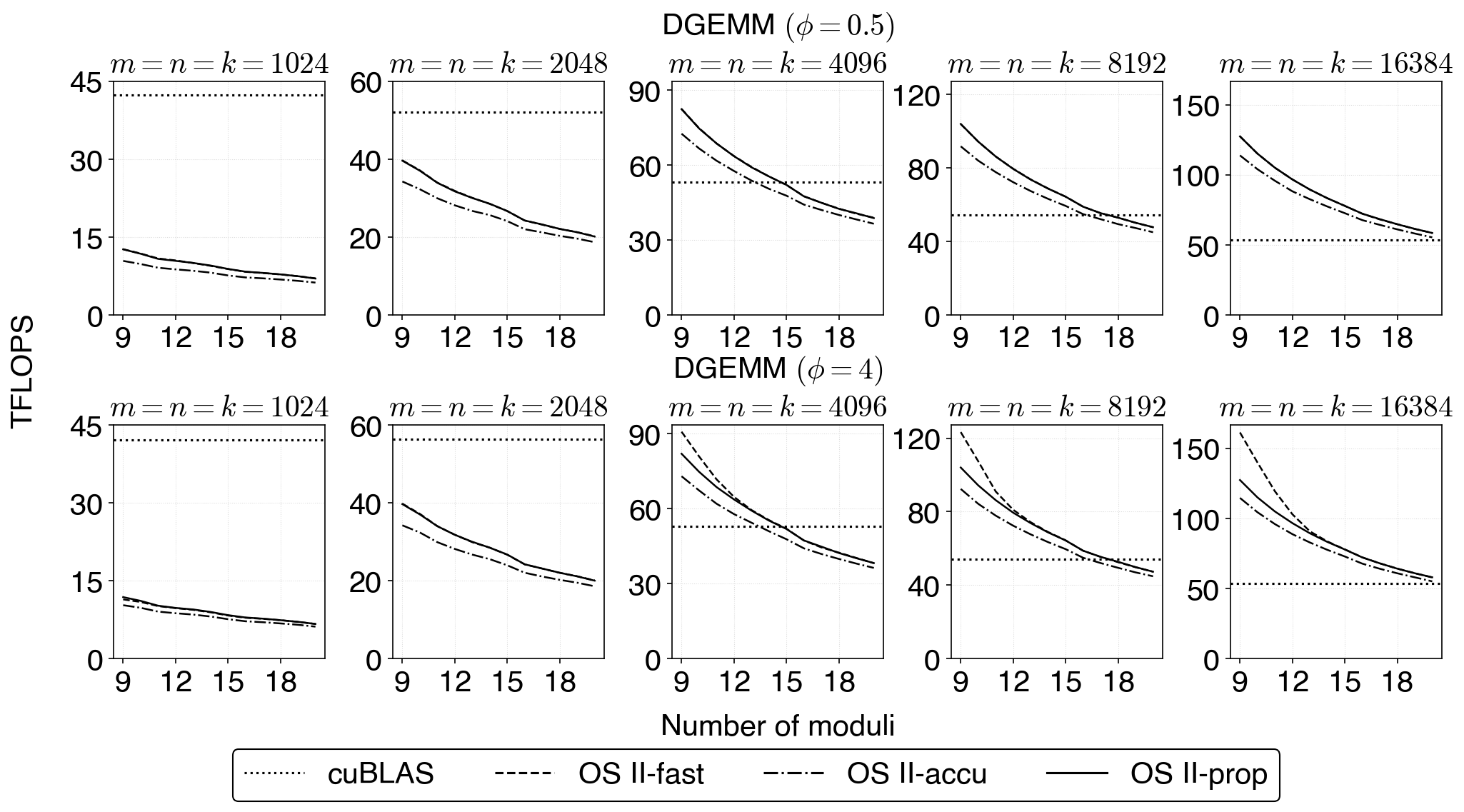
Figure 4: DGEMM throughput (TFLOPS) for varying matrix size and difficulty, with OS~II-prop matching OS~II-fast and exceeding OS~II-accu.
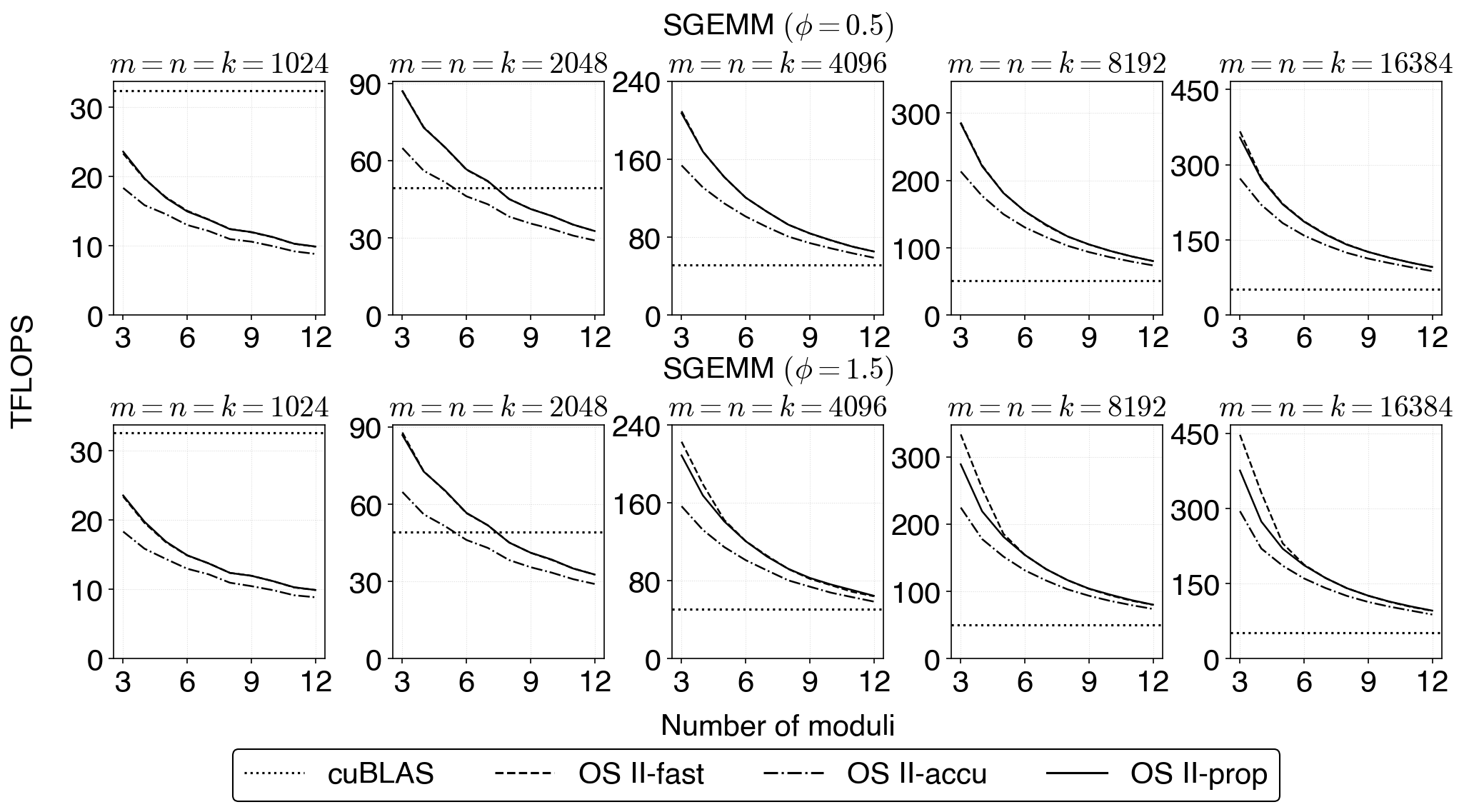
Figure 5: SGEMM throughput curves with the same trend—no throughput penalty for OS~II-prop relative to OS~II-fast.
Accuracy–Throughput Trade-Off
A salient advantage of OS~II-prop is the superior position in the accuracy–throughput trade-off plane. For equivalent error thresholds, the proposed method attains higher throughput than accurate mode, and crucially, does so even in parameter regimes where OS~II-fast fails to meet accuracy requirements (e.g., for large input dynamic range).
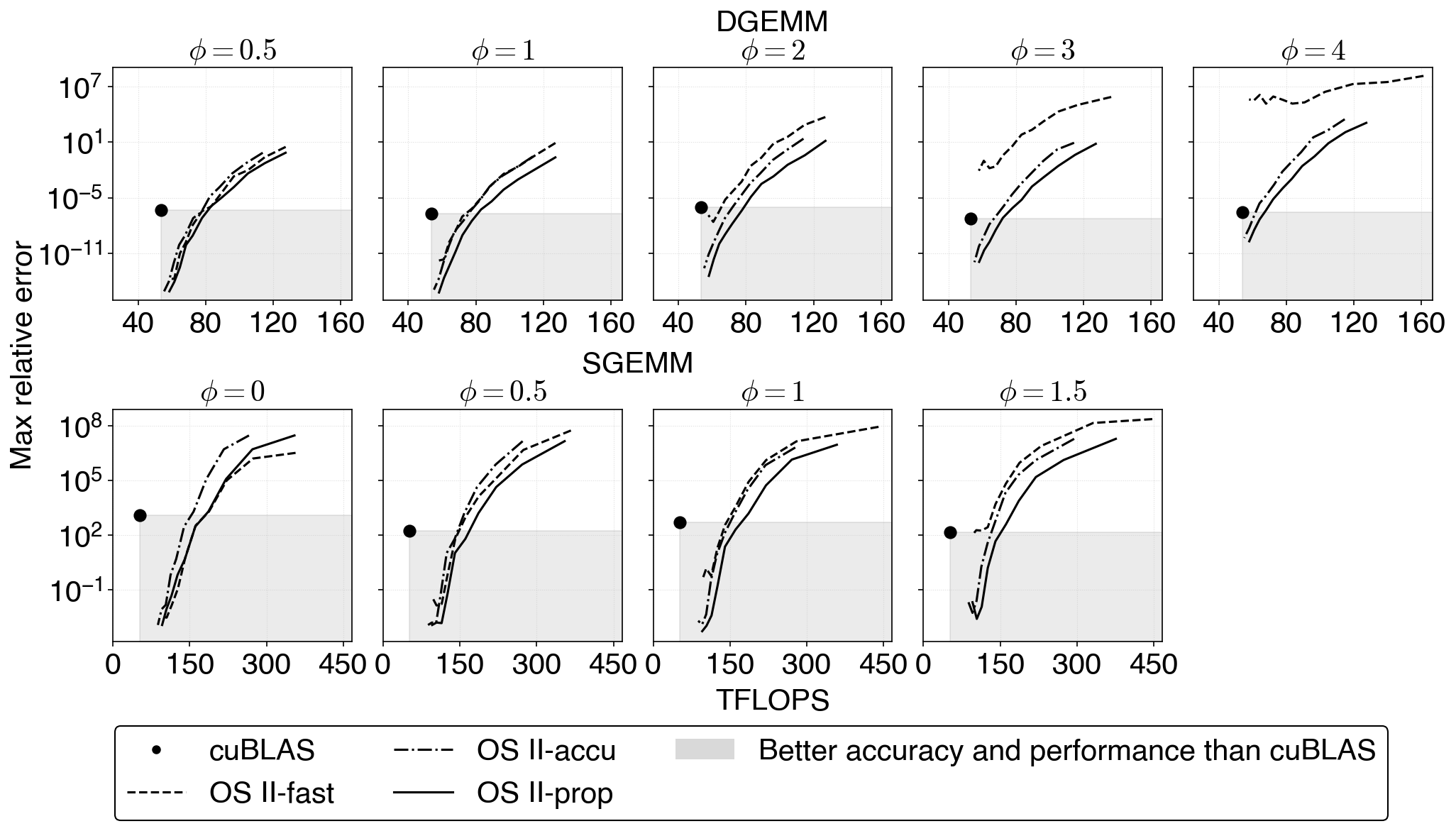
Figure 6: Accuracy–throughput Pareto curves for DGEMM and SGEMM; OS~II-prop consistently dominates accurate mode and achieves cuBLAS-surpassing accuracy and throughput.
Implications and Future Directions
The elimination of scale variance in the scaling process is nontrivial—the refined method is universally robust, parameter-insensitive, and endows Ozaki Scheme II with practical reliability for general scientific applications. This has immediate impact on highly mixed-precision scientific computing pipelines, such as in quantum circuit simulation and ab initio quantum chemical methods employing matrix products beyond ML/AI (2606.29129).
On the practical front, integration of this scale-invariant scaling into open-source libraries (e.g., GEMMul8) can facilitate turn-key deployment of accurate, high-throughput emulated precision on next-generation accelerator architectures (GH200, B200, etc.). The methods are directly applicable to other matrix types (ZGEMM, CGEMM), within both INT8 and FP8 contexts, opening avenues for complex-valued and mixed-precision emulation with reliability guarantees.
On the theoretical side, a rigorous error analysis parallel to that available for accurate mode (Uchino et al., 30 Jan 2026) is identified as future work, which would further ground correctness claims and facilitate adoption in mission-critical scientific computing.
Conclusion
A scale-invariant, Cauchy--Schwarz-based scaling formula for fast mode in Ozaki Scheme II has been formulated, analyzed, and empirically validated. The new scheme eliminates prior pitfalls related to input scaling, achieves the accuracy of accurate mode, and sustains the computational efficiency of fast mode. As AI HPC architectures continue to emphasize low-precision units, robust mixed-precision emulation via Ozaki Scheme II is poised for widespread adoption in diverse computational science domains. Further extensions to complex and FP8 engines, and formal error analyses, remain promising directions.

