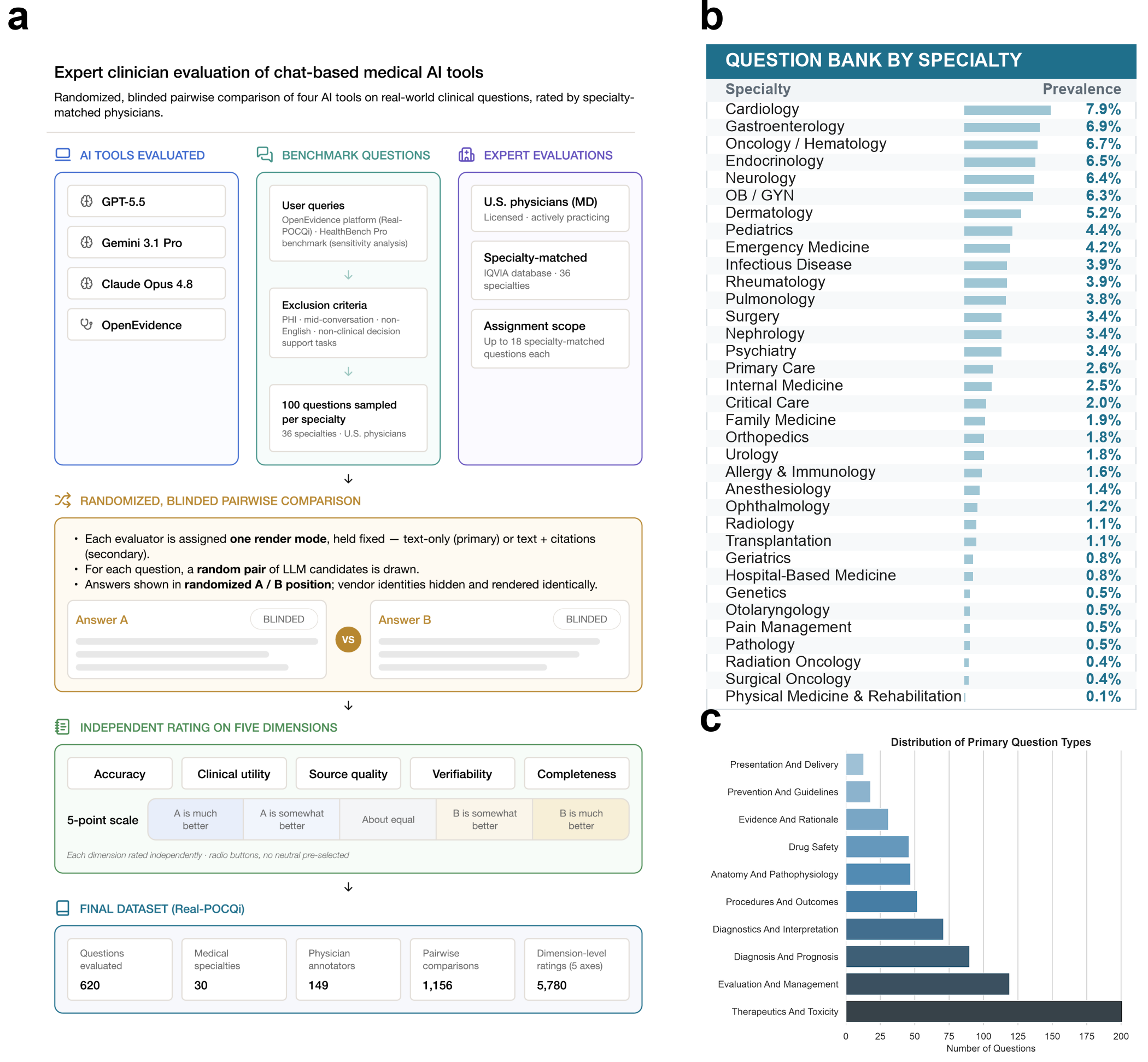
Expert Evaluation of Clinical AI Tools on Real Point-of-Care Clinical Queries
Abstract: Physicians now pose millions of clinical questions to AI tools each week, yet these tools are evaluated largely on hypothetical or exam-style questions, not those actually asked in practice. We report a blinded evaluation built on 620 Real-world Point-Of-Care Queries (Real-POCQi) submitted to the OpenEvidence (OE) platform by physicians spanning 30 specialties, as well as 187 questions from HealthBench. 149 practicing physicians across 36 states made head-to-head comparisons between answers from three frontier general-purpose models (Claude Opus 4.8, Gemini 3.1 Pro, and GPT-5.5) and a specialized clinical tool (OE), with graders matched to each question's specialty. When comparing answers along five dimensions relevant to clinical decision support -- accuracy, clinical utility, source quality, verifiability, & completeness -- physicians scored the specialized tool highest on all axes; in the primary analysis on Real-POCQi, win differences (margins between win and loss rates) ranged from 25 to 39 percentage points (p<0.001). Results remained consistent in sensitivity analyses stratifying by citation display, answer length, OE-user status, and Real-POCQi versus HealthBench. In parallel, LLM judges were found to systematically differ from expert judges, though both generally agreed on the best model. These findings underscore two conclusions: (i) AI tool evaluations should reflect real-world query distributions and use expert judges that mirror the specialization defining modern medicine and (ii) the consistent advantage of the specialized tool over general-purpose models does not necessarily mean that the latter cannot serve similar purposes, but that targeted engineering and customization can yield meaningful gains in performance for its users. We release Real-POCQi as a public benchmark, as well as the prespecified statistical analysis for reproducing results of this study.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Expert Evaluation of Clinical AI Tools on Real Point-of-Care Clinical Queries”
What is this paper about?
Doctors are using AI tools to help answer medical questions during patient care. Many studies test these tools using fake or exam-style questions, which don’t always match what doctors truly ask in real life. This paper tests several AI tools using real questions that doctors actually asked while caring for patients, to see which tools are most helpful and trustworthy.
What did the researchers want to find out?
They asked three simple questions:
- When doctors ask real, day-to-day medical questions, which AI tool gives the best answers?
- Do the results change based on things like whether the answer shows citations (sources), how long the answer is, or whether the judge already uses one of the tools?
- Can AI systems themselves act as fair judges of medical answers, or do we still need human medical experts?
How did they test this? (Methods in everyday language)
- Real questions: They built a dataset called Real-POCQi using 620 real medical questions that doctors typed into a clinical tool called OpenEvidence (OE). These questions came from 30 different specialties (like cardiology, oncology, etc.). They also used 187 questions from another set called HealthBench to double-check their findings.
- Who judged the answers: 149 practicing U.S. doctors from 36 states. Each doctor judged questions from their own specialty (for example, a heart doctor judged heart-related questions).
- What was compared: Four AI systems answered each question:
- Three general-purpose AIs: Claude Opus 4.8, Gemini 3.1 Pro, GPT-5.5
- One specialized medical AI tool: OpenEvidence (OE)
- Fair “taste test” setup:
- Blinded: Doctors didn’t know which system wrote which answer (like a blind taste test).
- Head-to-head: For each question, doctors compared two answers side by side and said which was better.
- Randomized: The order of answers and which pair was shown were chosen at random.
- What did judges look for? Doctors rated each pair on five things:
- Accuracy (Is it factually correct?)
- Clinical utility (Is it useful for treating patients?)
- Source quality (Are the sources trustworthy?)
- Verifiability (Is it easy to check the facts?)
- Completeness (Does it fully answer the question?)
- How were scores counted? Think of a sports match. Each time one tool’s answer was preferred over another in a head-to-head comparison, that tool got a “win.” The main score, called “win difference,” is wins minus losses (bigger positive numbers mean better performance).
They also did extra checks:
- Showed some judges answers with citations and others without.
- Looked at whether longer answers were rated better.
- Checked if results changed depending on whether the judge already used the OE tool.
- Asked the AIs themselves to act as “judges” and compared their rankings to the human doctors.
What did they find, and why does it matter?
Main result:
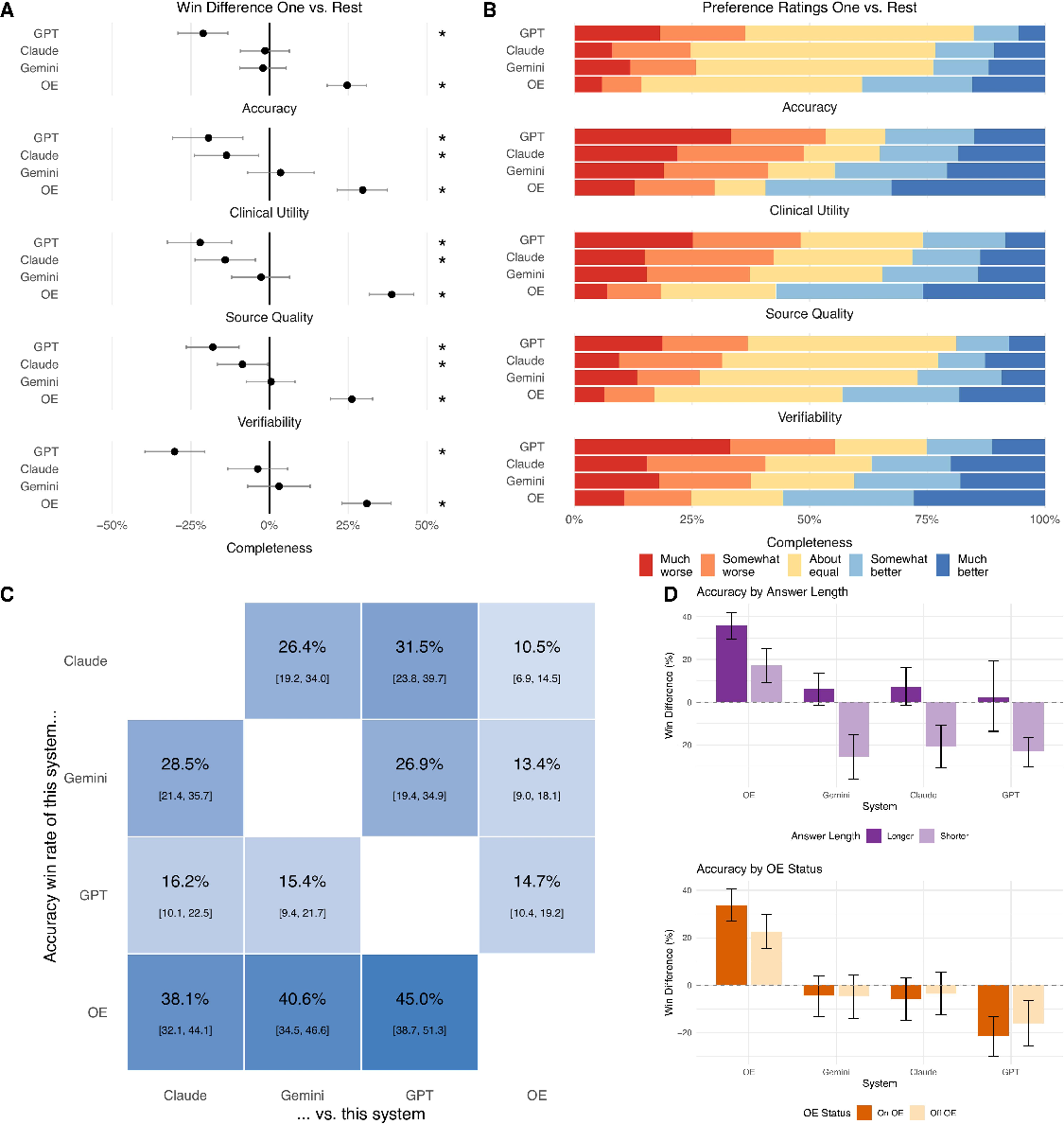
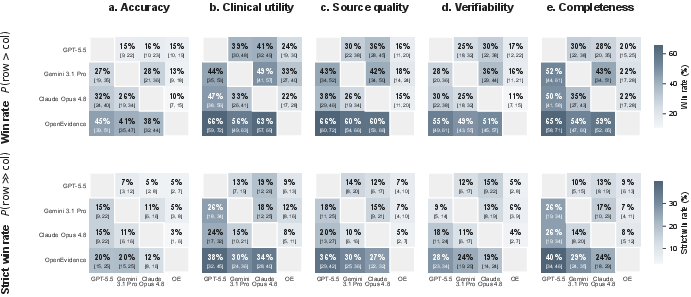
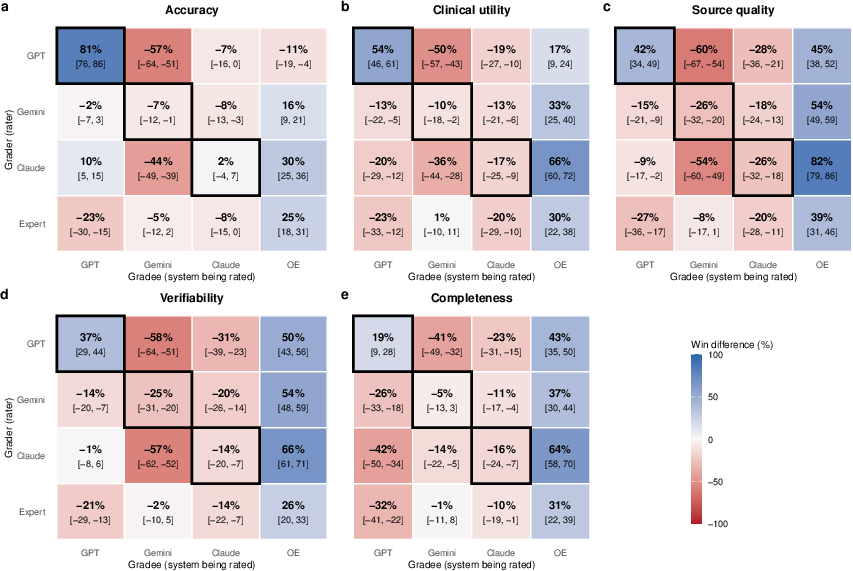
- The specialized medical tool, OpenEvidence (OE), was rated best across all five measures. It had a clear lead over the three general-purpose AIs. GPT-5.5 scored the lowest overall.
- This matters because it shows that a tool designed specifically for doctors can give more reliable, usable answers than general AI models for real medical questions.
Consistency checks:
- With or without citations: Results stayed essentially the same.
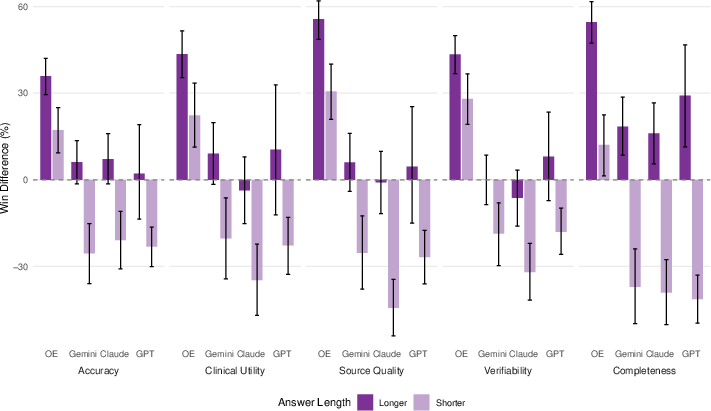
- Answer length: Longer answers were sometimes preferred (especially for accuracy and completeness), but OE still led overall.
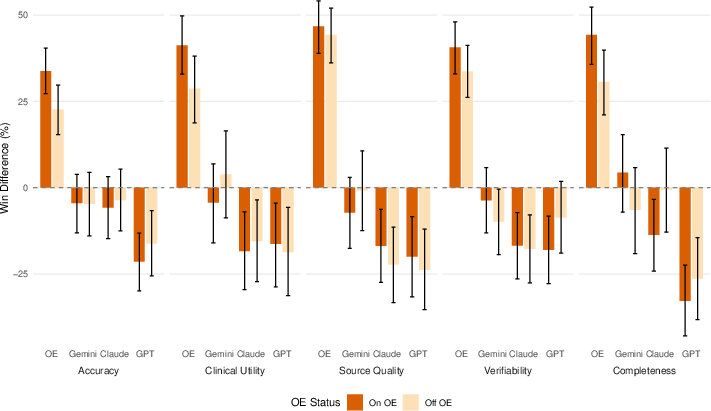
- OE users vs non-users: Both groups preferred OE; the advantage was a bit smaller among non-users but still present.
- Different question set (HealthBench): OE still came out on top, though the lead was somewhat smaller.
AI-as-judge vs human doctors:
- The AIs mostly agreed on which tool was best, but they disagreed more on the other rankings and tended to be overconfident.
- Some AIs strongly favored their own answers when judging, which is a problem (bias).
- Bottom line: For medical answers, AI judges are not yet a safe replacement for real doctors’ judgment.
What does this mean going forward? (Implications)
- Real-life testing matters: To understand how well medical AI works, we should test it on real questions that doctors ask, and have specialists judge the answers.
- Specialization helps: Tools built and tuned specifically for medical use can clearly outperform general-purpose AIs in real clinical situations.
- Don’t rely on AI judges (yet): Letting AIs grade medical answers can introduce bias and errors. Human experts should remain the gold standard until AI judges are carefully validated.
- Open resources: The authors released the Real-POCQi dataset and their analysis code publicly. This helps other researchers improve and fairly test medical AI tools.
A few limitations to keep in mind
- The real questions came from one week and one platform (OE), so the mix of questions could change over time or on other platforms.
- Only a small share of invited doctors completed the study, which might introduce bias.
- AI systems change quickly; results could shift as models update.
- The study didn’t heavily fine-tune prompts for the general AIs, so results reflect typical “out-of-the-box” use.
Bottom line
When judged by real doctors on real medical questions, a specialized clinical AI tool (OpenEvidence) gave more accurate, useful, well-sourced, verifiable, and complete answers than three leading general-purpose AIs. To keep patients safe and help doctors make better decisions, we should evaluate medical AI using real-world questions and expert judges—and recognize that customization for clinical use can make a big difference.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper advances clinical AI evaluation by using real point-of-care queries and specialty-matched physician judges, but several important gaps remain. The items below identify what is missing, uncertain, or left unexplored, framed to guide concrete follow-up studies.
Benchmark composition and representativeness
- Single-week sampling window (June 7–14, 2026) may not capture temporal variability in clinical questions; need longitudinal sampling (e.g., quarterly snapshots over 12–24 months) to assess seasonality, drift, and stability of findings.
- Queries sourced from one platform (OpenEvidence, OE) may reflect routing bias (clinicians ask different question types on different tools); replicate with multi-platform sampling (e.g., enterprise ChatGPT, UpToDate-like Q&A, EHR-integrated assistants) to test external validity.
- Limited per-specialty sample sizes (620 total questions across 30 specialties) constrains reliable specialty-specific estimates; expand to thousands of questions per specialty to enable robust within-specialty comparisons.
- U.S.-only physician and query population; evaluate portability to non-U.S. health systems, non-English queries, and country-specific guideline ecosystems.
- Exclusion of non-clinical tasks and mid-conversation turns omits prevalent real-world use cases; include multi-turn, longitudinal, and workflow tasks (documentation, order sets, counseling) to reflect full task distribution.
Query fidelity and context capture
- Light LLM rewriting of queries to remove PHI may alter intent or nuances; quantify rewriting fidelity (e.g., human adjudication of semantic equivalence) and assess impact on model rankings.
- Lack of full patient context and care-setting metadata (inpatient vs outpatient, ED vs clinic) limits ecological validity; collect and evaluate with richer, structured context to test whether findings hold when realistic context is present.
- Single-turn evaluation ignores interactive use; design multi-turn, stateful assessments to evaluate conversational clarification, follow-up, and correction dynamics.
Evaluation design and outcome measures
- Subjective, preference-based Likert ratings on five axes are not tied to ground truth or clinical outcomes; add complementary gold-standard adjudication (evidence-backed answer keys) and clinically meaningful endpoints (decision accuracy, error severity, time-to-answer, user confidence).
- No severity weighting of inaccuracies or omissions; implement harm-aware scoring that penalizes unsafe or contraindicated recommendations more heavily than trivial errors.
- Low inter-rater agreement on verifiability (kappa ~0.09) suggests construct ambiguity; refine operational definitions, rater training, and rubric or replace with objective citation checks (e.g., citation validity audits).
- Length bias acknowledged but not fully controlled; enforce length-normalized comparisons or standardized length constraints to disentangle verbosity from quality.
- Pairwise blind text rendering equalizes formatting but may suppress salient tool-specific UX and evidence affordances; conduct complementary “naturalistic UI” trials that evaluate tools within their native interfaces.
- No assessment of calibration or uncertainty communication; add metrics for confidence expression, acknowledgment of evidence gaps, and appropriate hedging.
- No time, effort, or cognitive load measures; capture rating time, perceived effort, and usability to understand trade-offs between completeness and efficiency.
- Limited statistical modeling of grader and question effects; apply hierarchical models (e.g., mixed-effects Bradley–Terry–Davidson) to adjust for grader stringency, question difficulty, and specialty-specific variance.
General-purpose vs. specialized system attribution
- Advantage sources for the specialized tool (OE) are not decomposed; perform ablations to isolate contributions from retrieval quality, citation policies, domain prompts, post-processing, and instruction tuning.
- Frontier models were not prompt-tuned per-model for clinical tasks; evaluate with standardized clinical prompting, chain-of-thought/verification modes, and retrieval configurations to estimate ceiling performance under reasonable optimization.
- Deterministic generation (temperature=0) may not reflect deployed settings; test robustness across decoding strategies and safety filters used in practice.
LLM-as-judge reliability and development
- LLM judges were used zero-shot and showed self-preference and overconfidence; explore calibrated judge training with domain-specific instruction tuning, anti-self-preference protocols, and cross-model anonymization strategies.
- No analysis of rubric-augmented or evidence-constrained LLM judging; compare rubric-based, evidence-aware, and adversarially trained judges to humans on the same items.
- Limited exploration of jury aggregation methods; systematically assess different ensemble schemes, disagreement handling, and tie-breaking to improve correlation with expert rankings.
- No auditing of judge susceptibility to stylistic or length confounds; introduce controlled counterfactuals (swapped styles, matched lengths, masked citations) to quantify bias channels in automated judging.
Safety and real-world impact
- Safety was not explicitly measured (e.g., contraindication checks, toxic recommendations, black-box warnings); add safety audit panels with severity labels and sentinel conditions.
- No measurement of downstream clinical impact; run simulation studies or pragmatic trials assessing decisions with/without AI support, patient-level endpoints, and net clinical benefit.
- Absence of trust and adoption outcomes; measure clinician trust calibration, reliance patterns, and impact on practice variability.
Data governance, conflicts, and reproducibility
- OE’s involvement in data collection and participant payments poses perceived conflict risks; conduct independent replications by third-party coordinators with preregistered protocols.
- Benchmarks risk rapid obsolescence due to model updates; establish a continual evaluation pipeline with versioned model snapshots and periodic refreshes.
- Potential train–test contamination is unassessed; implement leakage checks and holdout periods to ensure evaluated questions were not seen during model/tool training.
Subgroup and heterogeneity analyses
- Limited power to analyze performance by specialty, question theme, presence of patient context, or care setting; expand dataset to enable prespecified subgroup analyses and interaction tests.
- Attenuation among non-OE users suggests user-familiarity bias; design crossover or “naïve vs. experienced user” experiments to quantify habituation effects.
Evidence handling and verifiability
- Verifiability ratings did not require auditors to check cited sources; incorporate human or automated citation audits (existence, relevance, correctness, recency) and link-level accessibility checks (paywalls, guideline versions).
- No assessment of guideline concordance or currency; evaluate alignment with specialty-society recommendations and recency thresholds, especially for fast-changing areas (e.g., oncology, infectious disease).
These gaps outline a concrete roadmap: broaden and diversify the benchmark; enrich patient context and interaction modes; add objective and safety-focused endpoints; improve and validate LLM-judging; decompose system advantages; and evaluate real-world impact and adoption with rigorous, independent replication.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s findings, methods, and released assets. Each item notes relevant sector(s), possible tools/workflows, and feasibility considerations.
- Deploy specialized clinical decision support (CDS) tools at the point of care
- Sectors: Healthcare (hospitals, clinics), Software (CDS vendors)
- What to do: Prefer specialized, evidence-grounded CDS systems for bedside queries (e.g., OE-like platforms) over general-purpose LLMs when making clinical decisions. Configure access within EHRs, set default to show sources and verifiability cues.
- Tools/workflows: EHR-integrated CDS panels; single sign-on; policy that general-purpose models are not for CDS without evidence.
- Assumptions/dependencies: Availability of a specialized tool that meets organizational security/compliance; integration capacity; clinician onboarding.
- Establish a hospital AI evaluation pipeline modeled on Real-POCQi
- Sectors: Healthcare (health system governance), Software (MLOps/AI ops)
- What to do: Stand up a blinded, head-to-head “AI arena” for CDS tools using specialty-matched clinicians and five axes (accuracy, clinical utility, source quality, verifiability, completeness). Reuse the public Real-POCQi dataset and the authors’ statistical code to bootstrap internal capability.
- Tools/workflows: Pairwise A/B evaluation platform; randomization/identity blinding; specialty-matched reviewer panel; length-stratified analysis; bootstrap CI reporting.
- Assumptions/dependencies: Budget for clinician time; IRB/ethics for internal evaluation; data governance; access to vendor APIs; minimal prompt engineering parity across vendors.
- Update procurement and vendor due diligence requirements
- Sectors: Healthcare procurement, Legal/compliance, Policy (institutional)
- What to do: Require vendors to demonstrate multi-axis performance on real-world queries and to disclose how they ensure source quality and verifiability. Include head-to-head evidence and specialty-stratified results in RFPs.
- Tools/workflows: Standardized RFP annex capturing OvR win differences; vendor-run A/Bs audited by buyer; acceptance testing before go-live.
- Assumptions/dependencies: Willingness of vendors to participate in blinded A/Bs; standardized definitions; legal agreements around benchmarking.
- Implement post-deployment monitoring using pairwise comparisons
- Sectors: Healthcare QA/safety, Software (monitoring)
- What to do: Continuously sample real queries, run multiple CDS systems in shadow mode, and collect specialty-matched clinician ratings (or calibrated internal SMEs) on the five axes; flag regressions and model updates.
- Tools/workflows: Shadow deployment; model selection dashboard; alerting thresholds; periodic re-baselining as models update.
- Assumptions/dependencies: API access to multiple systems; HIPAA-compliant sampling; clinician capacity; change management.
- Train clinicians on five-axis appraisal of AI answers
- Sectors: Education (CME/GME), Healthcare
- What to do: Use Real-POCQi items to teach residents/attendings how to assess accuracy, clinical utility, source quality, verifiability, and completeness; emphasize that longer answers can bias perceptions and that citations matter.
- Tools/workflows: CME modules; simulated A/B rating exercises; feedback comparing to expert consensus.
- Assumptions/dependencies: Curriculum time; access to the dataset; faculty development.
- Use Real-POCQi to benchmark new clinical AI models in academia and industry
- Sectors: Academia (ML for health), Software (model dev), Pharma/MedTech (medical information)
- What to do: Evaluate new retrieval-augmented or instruction-tuned models on the public benchmark; report pairwise win rates and length-stratified analyses; publish ablations on prompt engineering and evidence retrieval.
- Tools/workflows: Reuse released code; deterministic generation settings; transparent prompts; report cluster (theme/specialty) performance.
- Assumptions/dependencies: Compute/resources; responsible use of the dataset; adherence to the pre-specified statistical plan for comparability.
- Calibrate or gate any use of LLM-as-a-judge for clinical evaluation
- Sectors: Software (evaluation tooling), Healthcare governance
- What to do: If automated judges are used to triage evaluations, calibrate them against human specialist panels and avoid using them to adjudicate accuracy or clinical utility without human oversight—especially avoiding self-judging.
- Tools/workflows: Periodic human–LLM concordance checks; ensembles (LLM-as-jury) with human tie-breakers; bias audits for self-preference and overconfidence.
- Assumptions/dependencies: Access to experts for calibration; rigorous prompts; documentation of limitations.
- Improve product UX to foreground source quality and verifiability
- Sectors: Software (CDS/product), Publishing/Knowledge providers
- What to do: Standardize citation display, authority indicators (e.g., guideline strength, recency), and “verify” affordances; design to mitigate length bias and overconfident tones.
- Tools/workflows: Citation schemas; evidence grading badges; collapsible detail sections; style guides that decouple verbosity from confidence.
- Assumptions/dependencies: Access to trustworthy sources; UI engineering; UX research with clinicians.
- Guide frontline clinicians’ personal use policies
- Sectors: Healthcare (clinical practice), Policy (institutional)
- What to do: Communicate that specialized tools are preferred for CDS, that general-purpose models should not be used for high-stakes decisions without corroboration, and that source-backed, verifiable outputs are required for documentation.
- Tools/workflows: Departmental memos; quick-reference checklists; EHR prompts reminding users to record sources.
- Assumptions/dependencies: Leadership endorsement; alignment with medico-legal frameworks.
- Rapidly spin up specialty-topic hackathons and challenge tracks
- Sectors: Academia, Software, Nonprofits
- What to do: Use Real-POCQi as a shared task to foster evidence-grounded retrieval, specialty-tuned summarization, and verifiability-aware generation; evaluate contributions with the five-axis framework.
- Tools/workflows: Shared leaderboard; blinded evaluation harness; prize criteria aligned to OvR win differences.
- Assumptions/dependencies: Organizational support; adjudication resources; clear data-use terms.
Long-Term Applications
These opportunities require additional research, scaling, integration, or standard-setting before broad deployment.
- Regulatory evaluation frameworks anchored in real-world queries
- Sectors: Policy/Regulation (FDA, state boards), Healthcare
- What: Develop approval and post-market surveillance frameworks that require performance on representative point-of-care queries with specialty-matched expert evaluation and multi-axis reporting; register benchmarks per specialty akin to Real-POCQi.
- Potential outputs: Guidance documents; standardized evidence packages; model change control tied to benchmark re-tests.
- Assumptions/dependencies: Multi-stakeholder consensus; legal frameworks for benchmarking; sustained expert panels; handling of proprietary data.
- Cross-domain verticalization of “real-question + specialist-judge” evaluation
- Sectors: Legal, Finance, Education, Energy, Aviation, Public sector
- What: Build domain-specific question datasets and specialist-judged benchmarks (e.g., legal research, financial compliance, grid operations) to evaluate vertical tools versus general LLMs.
- Potential outputs: Sector-specific “POCQ” benchmarks; procurement standards for high-stakes AI.
- Assumptions/dependencies: Access to real queries; deidentification pipelines; recruitment of domain experts; IP concerns.
- Reliable, validated LLM-judge/jury systems for low-risk evaluation tasks
- Sectors: Software (evaluation platforms), Academia
- What: Research methods to reduce self-preference/overconfidence, calibrate to human ratings, and identify axes where automated judges are safe to use (e.g., completeness) while keeping humans in the loop for accuracy and utility.
- Potential outputs: Calibrated judge ensembles; confidence-adjusted scoring; guardrails/criteria for acceptable use.
- Assumptions/dependencies: Large gold-standard datasets; reproducible prompts; transparent model governance.
- Standards for verifiability and citation quality in clinical AI
- Sectors: Standards bodies (e.g., ISO, HL7), Publishing, EHR vendors
- What: Define interoperable schemas for evidence citation (source authority, recency, level of evidence) and verifiability UX patterns; require audit logs of evidence used in CDS recommendations.
- Potential outputs: HL7 FHIR profiles for AI evidence; UI standards; certification programs.
- Assumptions/dependencies: Stakeholder agreement; coordination with publishers; legal handling of paywalled content.
- EHR-native, evidence-anchored CDS with auditability and outcomes tracking
- Sectors: Healthcare IT, Software
- What: Architect CDS modules that surface recommendations with linked evidence, log clinician interactions, and tie model outputs to patient outcomes for ongoing effectiveness/safety monitoring.
- Potential outputs: Auditable CDS pipelines; dashboards connecting AI usage to clinical KPIs; adaptive model routing.
- Assumptions/dependencies: EHR interoperability; robust data governance; causal evaluation capacity; vendor cooperation.
- International, multi-institution expansion of Real-POCQi-style datasets
- Sectors: Academia, Health systems, NGOs
- What: Collect and share deidentified point-of-care queries across countries and specialties; evaluate generalizability, cultural/linguistic variation, and performance in non-English settings.
- Potential outputs: Global benchmarks; translation/evidence localization strategies; equitable AI evaluation.
- Assumptions/dependencies: Ethics approvals; multilingual expert graders; funding for sustained data collection.
- Benchmark-as-a-service platforms for hospitals and regulators
- Sectors: Software (B2B platforms), Policy
- What: Hosted, secure evaluation arenas that run blinded, pairwise tests against multiple vendors, produce standardized reports, and manage clinician panels.
- Potential outputs: Subscription evaluation services; continuous readiness assessments; shared registries of model performance.
- Assumptions/dependencies: Market demand; neutral governance; data-sharing agreements; indemnity considerations.
- Education reform for AI-in-medicine competencies
- Sectors: Education (medical schools, boards)
- What: Integrate five-axis evaluation and evidence-aware AI usage into curricula and board assessments; simulate POC decision-making with AI tools.
- Potential outputs: Competency frameworks; standardized OSCE stations with AI; continuing certification modules.
- Assumptions/dependencies: Accreditation body alignment; faculty development; access to safe sandboxes.
- Economic and policy models for reimbursement and ROI
- Sectors: Payers, Health economics, Policy
- What: Evaluate cost-effectiveness of specialized CDS tools versus general LLMs; design reimbursement or incentive models tied to quality and safety gains.
- Potential outputs: HTA reports; payer policies; value-based care measures incorporating AI.
- Assumptions/dependencies: Access to outcomes/cost data; robust study designs; payer engagement.
- Privacy-preserving pipelines to capture real queries at scale
- Sectors: Software (privacy tech), Healthcare IT, Academia
- What: Advance automated deidentification and rewriting workflows that preserve clinical content for benchmarking while protecting PHI, generalizing the paper’s rewriting approach.
- Potential outputs: Open-source deidentification toolkits; audit frameworks for content fidelity; compliance attestations.
- Assumptions/dependencies: High-accuracy PHI detection; legal/IRB approvals; validation studies of clinical fidelity.
- Interoperability for multi-model routing and evaluation feedback
- Sectors: EHR vendors, Middleware, Software
- What: Define APIs to route queries to multiple AI tools based on task/specialty, collect evaluations, and feed performance back into routing logic.
- Potential outputs: Smart orchestration layers; dynamic model selection; governance dashboards.
- Assumptions/dependencies: Vendor API stability; latency/cost budgets; governance for automated routing.
Cross-cutting assumptions/dependencies that affect feasibility
- The Real-POCQi dataset reflects U.S.-based, English-language queries from a single week and a single platform; question mix and performance may shift over time and across settings.
- Specialized tools’ advantage is partly due to targeted engineering and evidence integration; replicating this in other domains requires high-quality sources and retrieval infrastructure.
- Specialty-matched expert evaluation is resource-intensive; scaling needs funding, incentives, and efficient tooling.
- General-purpose models’ performance is sensitive to prompt engineering and updates; evaluations must be versioned and repeated.
- Institutional adoption depends on governance maturity, legal risk tolerance, and integration capacity.
Glossary
- Bertopic: A topic modeling method that clusters documents using transformer-based embeddings. "the keyphrases were clustered using Bertopic \citep{Grootendorst2022-it}"
- Bootstrap confidence intervals: Confidence intervals estimated by resampling the data with replacement to assess variability. "All error bars are 95% bootstrap confidence intervals."
- Cluster bootstrap: A bootstrap method that resamples at the cluster level to account for within-cluster correlation. "we recomputed -values and confidence intervals using the cluster bootstrap but with clusters defined by the grader rather than the question."
- Davidson model: A probabilistic ranking model for pairwise comparisons that can accommodate ties. "Rankings between the four LLMs were estimated using a Davidson model that allowed for ties in pairwise comparisons"
- Deidentified: Having all personal identifiers removed to protect privacy. "The question bank (Real-POCQi) was derived from deidentified and rewritten OE real user queries"
- Exempt determination (IRB): An Institutional Review Board decision that a study is exempt from full review under specific regulatory categories. "This study received an exempt determination from Rapid IRB (IRB number IRB00014585; Federalwide Assurance FWA00035509)"
- Frontier models: The most advanced, state-of-the-art LLMs available at a given time. "three frontier general-purpose models (Claude Opus 4.8, Gemini 3.1 Pro, and GPT-5.5)"
- HACHI: An LLM-assisted workflow for organizing and interpreting clustered text data. "Following a workflow based on HACHI~\citep{Feng2026-ka},"
- HealthBench: A benchmark dataset for evaluating medical AI systems on physician-relevant questions. "questions from HealthBench \citep{Arora2025-fp}"
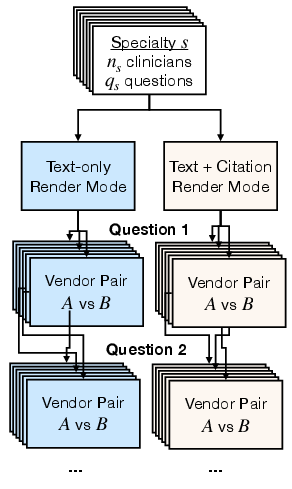
- Inter-rater agreement: The level of consistency between different evaluators rating the same items. "The inter-rater agreement rate---evaluated between physicians rating the same question and AI model pair within the same rendering mode---ranged from 74.1\% to 76.9\% across the five evaluation dimensions."
- IQVIA OneKey provider database: A commercial registry of healthcare providers used for sampling licensed physicians. "OE generated and emailed surveys to physicians sampled from the IQVIA OneKey provider database."
- Kendall's tau: A nonparametric statistic measuring rank correlation between two orderings. "its average correlation with the human expert ratings was low and, in fact, negative (Kendall's tau=-0.200)."
- Length bias: A systematic preference for longer responses regardless of substance, which can skew evaluations. "The length of a modelâs response to a clinical query may alone influence clinician ratings of that response (length bias)."
- Likert scale: An ordinal rating scale commonly using 5 or 7 points to measure preferences or agreement. "Answers were compared on a 5-point Likert scale, allowing for ties."
- LLM arenas: Evaluation platforms that use pairwise comparisons to rank LLMs by preference. "Through the pairwise comparison approach popularized by LLM arenas \citep{Chiang2024-tw},"
- LLM-as-a-judge: The practice of using a LLM to evaluate and score other model outputs. "AI system rankings from LLM-as-a-judge systems versus human experts."
- LLM-as-a-jury: Using an ensemble of LLM judges to aggregate evaluations, analogous to a jury. "also known as an LLM-as-a-jury \citep{Verga2024-vf, Chan2024-dj, Kalra_undated-rn}"
- LLM-based clustering: Grouping items using features or labels generated by LLMs. "LLM-based clustering \citep{Grootendorst2022-it, Feng2026-ka} of the questions uncovered eleven key themes,"
- National Plan and Provider Enumeration System: The U.S. registry that manages the provider identifier system. "Each physician's specialty was identified from the National Plan and Provider Enumeration System, the national NPI registry,"
- National Provider Identifier (NPI): A unique identification number for health care providers in the United States. "licensed U.S. physicians holding a valid National Provider Identifier (NPI)."
- One-vs-Rest (OvR) win difference: A metric equal to wins minus losses against all comparators, averaged across opponents. "The primary outcome, the One-vs-Rest (OvR) win difference, is the average difference between the win and loss rates when system A is compared to a comparator system."
- Permutation test: A nonparametric method that computes a p-value by repeatedly shuffling labels to simulate the null distribution. "The p-value was obtained using a permutation test, where the winner of each LLM pair was randomly flipped with 50\% (ties remain unchanged)."
- Point-of-care: The setting where clinical care is delivered and immediate decisions are made. "for questions that arise at the point-of-care,"
- Protected health information (PHI): Individually identifiable health information regulated under privacy law (e.g., HIPAA). "questions potentially containing protected health information (PHI);"
- Randomized mixed factorial design: An experimental design combining multiple factors with randomization to assess effects efficiently. "We conducted a randomized mixed factorial design with blinded pairwise model evaluations"
- Sensitivity analyses: Additional analyses that vary assumptions or conditions to test the robustness of results. "A comprehensive set of sensitivity analyses were conducted to assess the robustness of these findings."
- Stratified sampling: Sampling that divides a population into subgroups (strata) and samples within each to ensure representation. "Sampling was stratified 50/50 between questions without patient context and questions containing patient information."
- Strict win-rate matrices: Win-rate calculations that only count strong preferences as wins, making the criterion more stringent. "As a sensitivity analysis, strict win-rate matrices were computed in which a system was credited with a win only when it was strongly preferred"
- Weighted Cohen's kappa (quadratic weights): An agreement statistic that adjusts for chance and penalizes larger disagreements more heavily. "Weighted Cohen's kappa with quadratic weights was moderate to high, ranging from 23\% to 38\% for all but the verifiability axis which had a kappa of 9\%."
- Win-rate matrices: Tables giving the proportion of head-to-head comparisons won by each system against others. "The secondary endpoint was pairwise win-rate matrices, defined as the proportion of head-to-head comparisons in which system was preferred over system ."
Collections
Sign up for free to add this paper to one or more collections.

