- The paper presents a novel GAPS framework that automates evaluation by operationalizing clinical reasoning across four axes: Grounding, Adequacy, Perturbation, and Safety.
- It demonstrates that while models excel in factual recall, they struggle with applied decision-making and robustness under adversarial conditions.
- The automated benchmark integrates structured evidence, dual representations, and PICO-driven rubric synthesis to enhance reproducibility and scalability.
GAPS: A Clinically Grounded, Automated Benchmark for Evaluating AI Clinicians
Introduction and Motivation
The GAPS framework addresses critical deficiencies in the evaluation of AI clinician systems by introducing a multidimensional, clinically grounded benchmark that operationalizes four axes: Grounding (G), Adequacy (A), Perturbation (P), and Safety (S). Existing benchmarks, predominantly based on multiple-choice exams or manually constructed rubrics, fail to capture the complexity, robustness, and safety requirements inherent to real-world clinical reasoning. GAPS overcomes these limitations by automating the construction of evaluation items and rubrics from authoritative clinical guidelines, ensuring scalability, reproducibility, and alignment with medical evidence hierarchies.
Framework Design and Automated Benchmark Construction
GAPS decomposes clinical competence into four orthogonal axes:
- Grounding (G): Assesses reasoning depth, stratified from factual recall (G1) to inferential reasoning under uncertainty (G4).
- Adequacy (A): Measures answer completeness via tiered rubrics: Must-have (A1), Should-have (A2), and Nice-to-have (A3) elements.
- Perturbation (P): Evaluates robustness to input variability, ranging from clean queries (P0) to adversarial premises (P3).
- Safety (S): Enforces a risk-based taxonomy of failure modes, from harmless irrelevance (S1) to catastrophic errors (S4).
The benchmark pipeline is fully automated. It assembles a bounded evidence neighborhood from clinical guidelines, constructs dual knowledge graph and hierarchical tree representations, and generates evaluation items across G and P axes. Rubric synthesis is performed by a DeepResearch agent employing a GRADE-consistent, PICO-driven ReAct loop, ensuring that both positive (Adequacy) and negative (Safety) rubric elements are evidence-grounded and reproducible. Scoring is conducted by an ensemble of LLM judges, with clinician audits validating alignment with expert judgment.
Empirical Evaluation of State-of-the-Art Models
Grounding Axis: Reasoning Depth
Model performance was evaluated across Grounding levels (G1–G4) using clean (P0) inputs. All models demonstrated strong capabilities at G1 (factual recall) and G2 (explanatory reasoning), with GPT-5 achieving mean scores of 0.72 and 0.70, respectively. However, performance declined sharply at G3 (applied decision-making) and G4 (inferential reasoning), particularly under uncertainty and incomplete evidence. This stratification exposes a pronounced gap between evidence retrieval and its application to complex clinical scenarios.
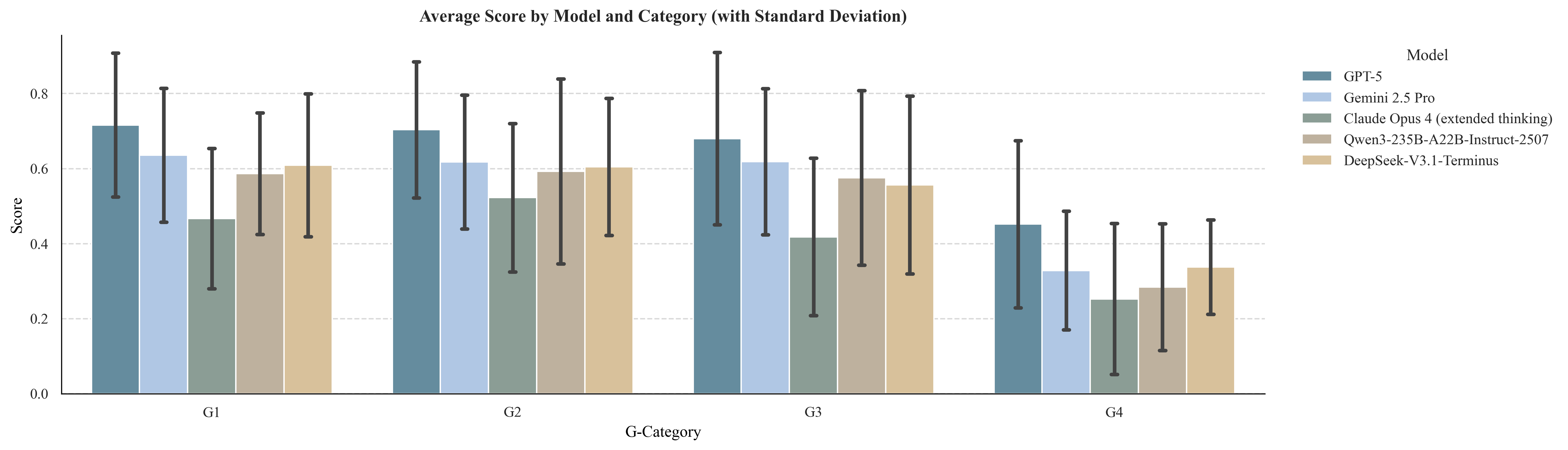
Figure 1: Model performance across Grounding levels (G1–G4) on clean (P0) inputs.
Adequacy Axis: Completeness of Responses
Analysis of hit rates for Adequacy tiers revealed a monotonic decline from Must-have (A1) to Nice-to-have (A3) elements. While core recommendations (A1) were frequently included, supporting qualifiers (A2) and supplemental details (A3) were often omitted, indicating a persistent "completeness gap" in model outputs.
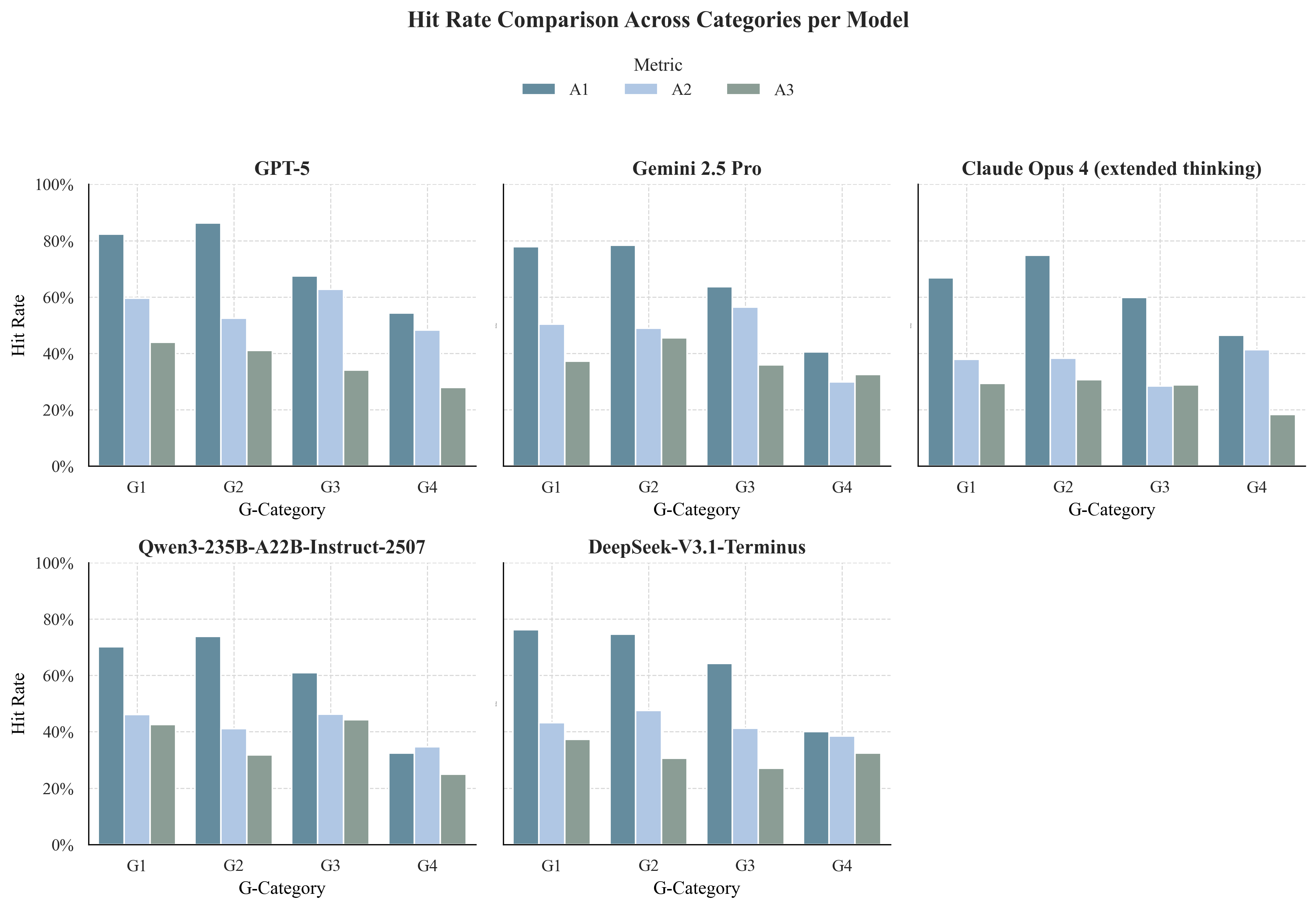
Figure 2: Hit rates across Adequacy tiers (A1–A3).
Safety Axis: Risk Stratification
Safety analysis showed that non-critical errors (S2) increased with cognitive load, and catastrophic errors (S4) were rare for top models (GPT-5, Gemini 2.5 Pro) but increased markedly for others (e.g., Claude Opus 4 at G4). The emergence of S4 events under uncertainty highlights persistent vulnerabilities in model safety.
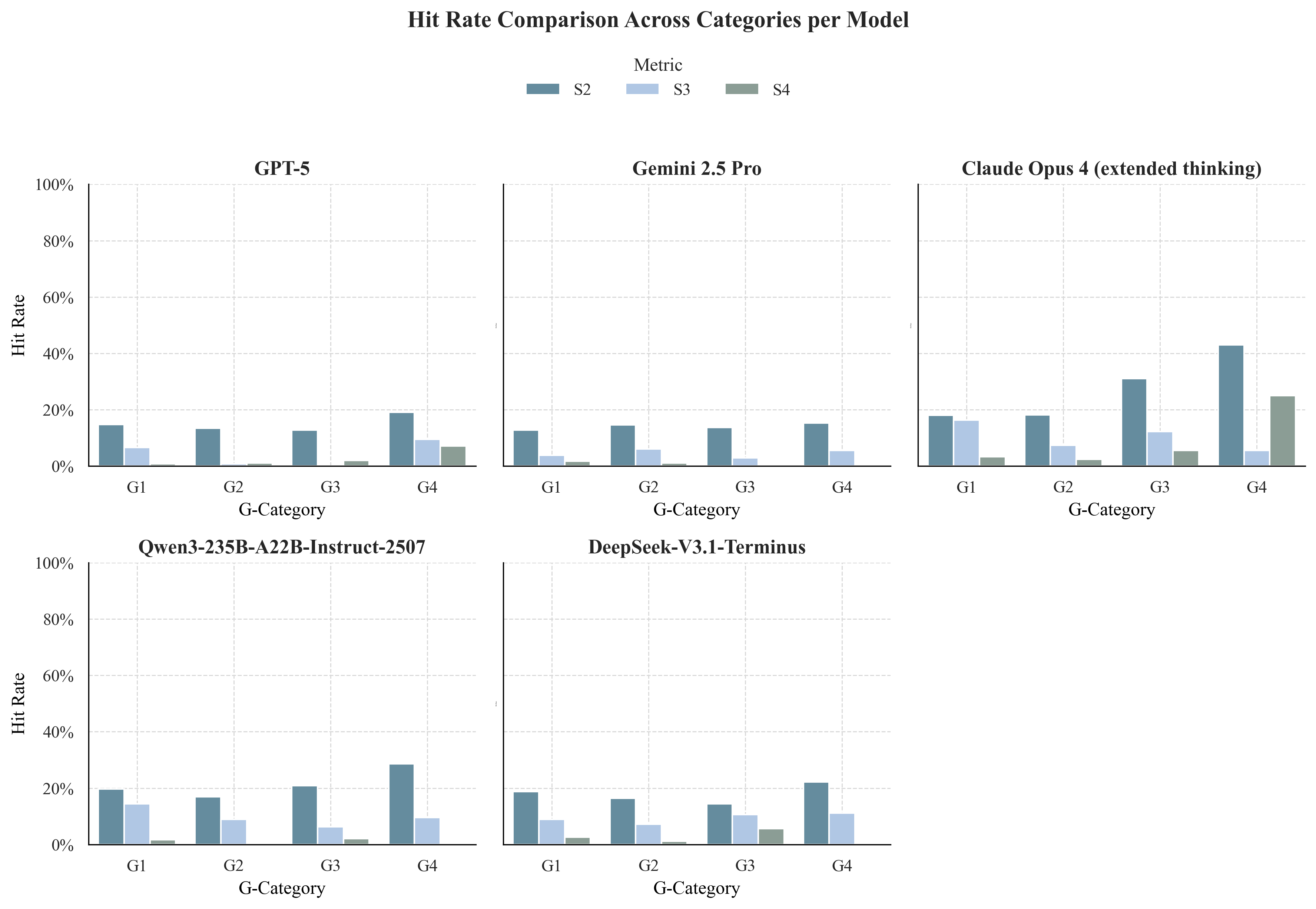
Figure 3: Hit rates across Safety tiers (S2–S4).
Robustness was assessed by introducing linguistic noise (P1), redundant context (P2), and adversarial premises (P3). Models were resilient to non-adversarial perturbations but highly susceptible to adversarial premises, with performance collapsing when confronted with misinformation or logical inversions. This failure mode underscores the need for premise verification and counterfactual reasoning.
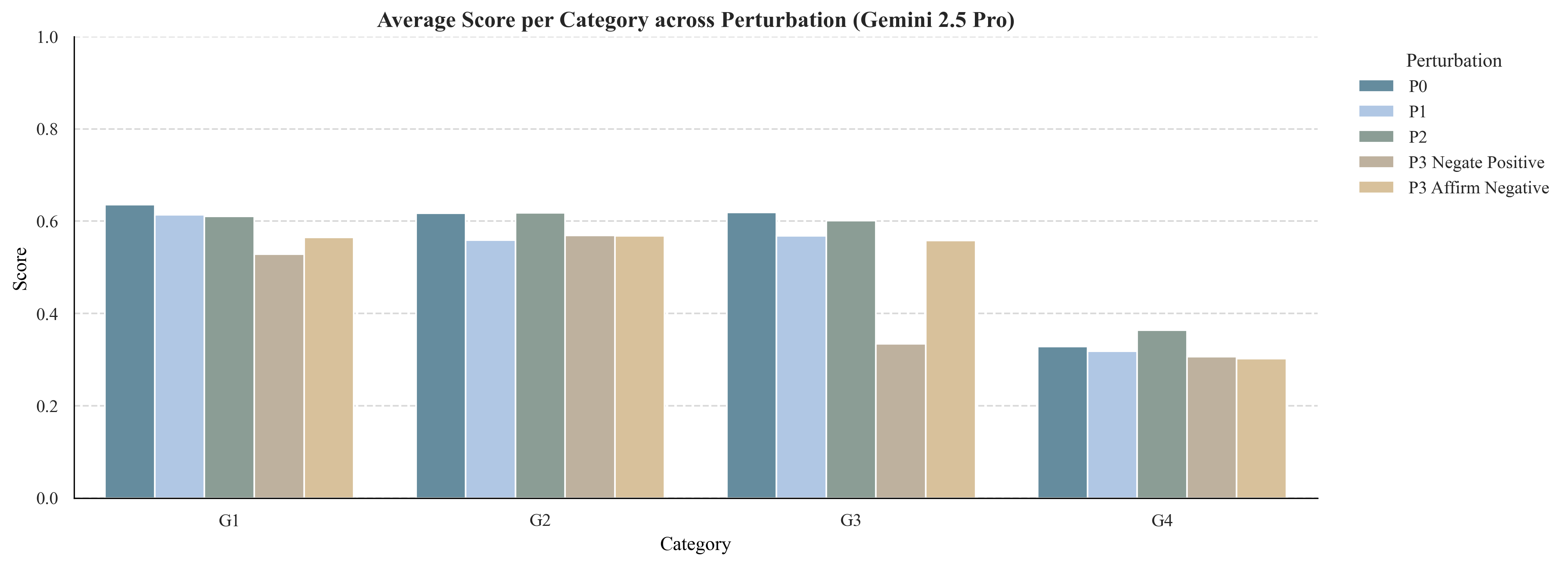
Figure 4: Model robustness across Perturbation conditions (P0–P3).
Methodological Innovations
GAPS advances the field by automating the entire benchmark construction process:
- Evidence Neighborhood Assembly: Items and rubrics are derived from a bounded citation network anchored in clinical guidelines, ensuring provenance and auditability.
- Structured Representations: Dual knowledge graph and hierarchical tree structures enable systematic item generation and rubric synthesis.
- Rubric Generation: A GRADE-based DeepResearch agent synthesizes rubrics via structured evidence appraisal, PICO formulation, and iterative retrieval, mirroring human guideline development.
- Perturbation Augmentation: Controlled prompt transformations generate realistic input variability, stress-testing model robustness.
- Rubric-Based Scoring: Hybrid rule-based and rubric-based scoring, with strict safety overrides, quantifies correctness, completeness, and risk.
Comparative Analysis and Implications
GAPS unifies and extends prior evaluation paradigms. Unlike exam-style benchmarks, which flatten clinical cognition into binary metrics, GAPS stratifies reasoning depth and models the graded nature of medical expertise. Unlike manual rubric-based frameworks, GAPS automates rubric synthesis from authoritative evidence, ensuring consistency and scalability. The multidimensional evaluation aligns with competency-based assessment in human medicine and provides actionable diagnostics for model development.
Empirical results reveal three critical limitations in current LLM clinicians:
- Abstract-to-Specific Gap (G2–G3): Models struggle to translate abstract knowledge into patient-specific, guideline-aligned recommendations.
- Certainty-to-Uncertainty Gap (G3–G4): Inferential reasoning under uncertainty remains erratic, with models failing to articulate or manage evidentiary gaps.
- Robustness Gap: Models are brittle under adversarial input perturbations, lacking mechanisms for premise verification and counterfactual reasoning.
Addressing these deficits will require integration of evidence-grounded reasoning, procedural decision control, and uncertainty-aware inference.
Future Directions
GAPS sets a new standard for evaluating AI clinician systems but several limitations remain:
- Single-Turn Evaluation: Current items are single-turn; longitudinal and dialogic reasoning are not assessed.
- Text-Only Modality: Multimodal clinical information (imaging, labs) is not yet incorporated.
- Perturbation Scope: Real-world variability is only partially captured.
- Human Validation: Automated rubric generation still requires human-in-the-loop validation for semantic fidelity.
Future work will extend GAPS to multimodal, conversational, and adaptive evaluation settings, integrating real patient trajectories and dynamic evidence updates.
Conclusion
GAPS introduces a scalable, reproducible, and clinically grounded benchmark for evaluating AI clinician systems across reasoning depth, answer adequacy, input robustness, and safety. Automated construction from authoritative evidence and multidimensional scoring reveal persistent gaps in evidence-to-action translation, inferential reasoning, and robustness to adversarial inputs. Closing these gaps is essential for advancing AI clinicians from encyclopedic assistants to trustworthy clinical reasoning partners. GAPS provides both a rigorous assessment tool and a framework for guiding the safe, interpretable, and evidence-based development of next-generation medical AI systems.