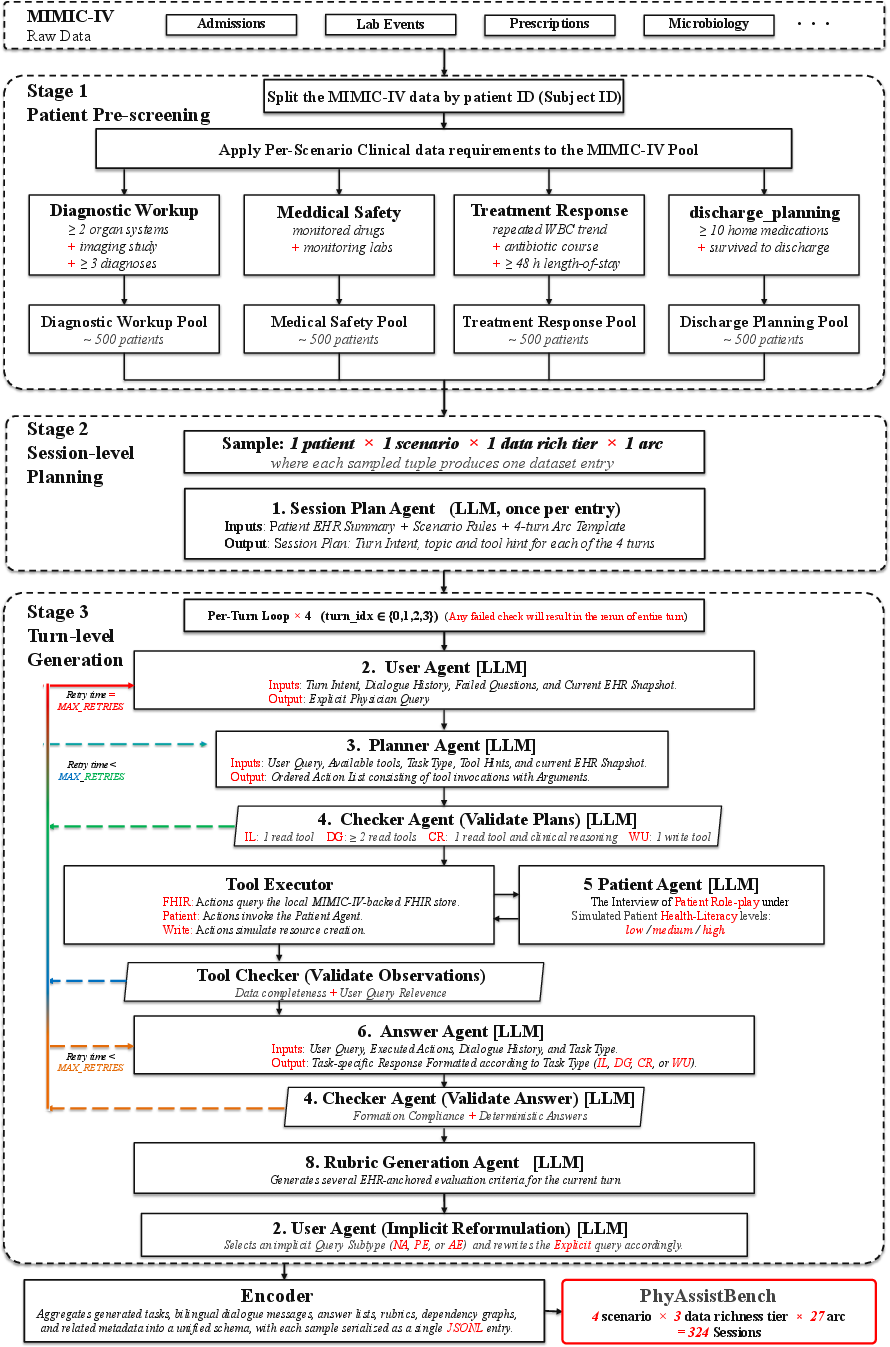
- The paper introduces PhysAssistBench, a benchmark simulating realistic clinical encounters with multi-turn doctor-patient-EHR interactions.
- It employs a multi-agent synthetic pipeline and rubric-based scoring to assess explicit and implicit query handling, tool orchestration, and patient communication.
- Results reveal strong turn-level performance but weak session-level reliability, underscoring challenges in clinical reasoning and sustained tool invocation.
PhysAssistBench: Evaluating LLMs as Physician Assistants in Interactive Doctor-Patient-EHR Settings
Current practices for benchmarking medical LLMs focus on isolated tasks—clinical knowledge QA, EHR retrieval, or patient communication—neglecting the realistic assistance context where LLMs are expected to operate as physician assistants coordinating knowledge, communication, and precise EHR actions under evolving, underspecified instructions. Real clinical encounters demand interpretive robustness: physicians issue implicit, context-dependent requests; patient information is incomplete and ambiguous; EHR interfaces require precise tool invocation and parameterization. Recent studies demonstrate a strong performance drop in interactive and under-specified settings, exposing interaction bottlenecks in clinical LLMs [laban2025lost, bean2026reliability]. The paper introduces PhysAssistBench, a benchmark rigorously designed to probe this integrated assistance setting.
Benchmark Design
PhysAssistBench is grounded in real-world EHR data (MIMIC-IV [johnson2023mimic]) and constructed via a scalable multi-agent synthetic pipeline that transforms static records into interactive, agentic patient environments, supporting realistic, multi-turn doctor-patient-EHR scenarios.
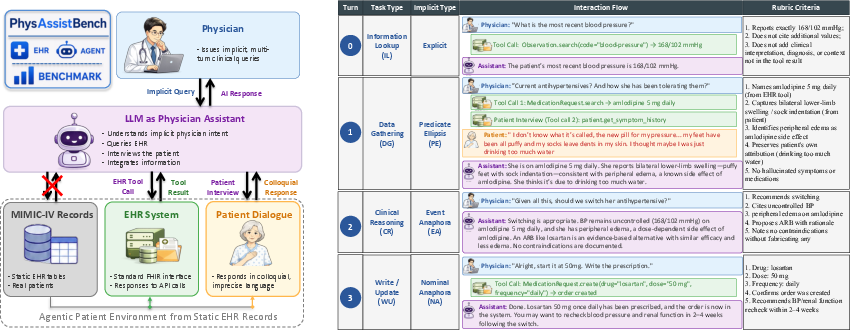
Figure 1: PhysAssistBench evaluates LLMs as physician assistants, requiring integrated interaction with standardized FHIR-based EHR tool interfaces and simulated patients.
The benchmark comprises:
- Sessions: Each session consists of four sequential turns reflecting a clinical workflow—anchored with explicit fact lookup, progressing through implicit queries, patient communication, clinical reasoning, and culminating in tool-driven write/update actions.
- Task Types: Information Lookup (IL), Data Gathering (DG), Clinical Reasoning (CR), Write/Update (WU).
- Implicitness Types: Nominal Anaphora (NA), Predicate Ellipsis (PE), Abstract Event Anaphora (AE)—each encoding graduated levels of implicit physician query formulation.
- Tool Abstraction: FHIR R4 compatible read/write tools for EHR, unified patient-interview tools generating subjective responses, all exposed to the evaluated agent.
The agentic patient environment synthesizes conversations that are strictly grounded in available EHR evidence, with unsupported cases filtered out to eliminate counterfactual risk. Each session is reviewed by trained annotators, validated by a physician, and assessed using rubric-based scoring at both turn and session levels.
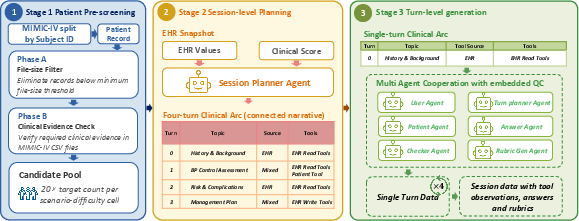
Figure 2: Multi-agent data synthesis pipeline transforms static MIMIC-IV records into agentic patients via session planning, turn generation, and quality gating.
Evaluation Protocol
Benchmark evaluation formalizes each session as a finite-horizon POMDP, with turn-level actions (EHR tool calls, patient interviews, natural-language responses) scored via objective rubrics capturing factual accuracy, clinical interpretation, context integration, and absence of hallucination. The key metrics are:
- Mean Rubric Score (mRS)
- Pass@Turn (τ): Fraction of turns scoring above threshold τ.
- Pass@Session (τ): Fraction of sessions where all turns exceed τ, reflecting robustness of sustained multi-turn interaction.
Numerical Results and Error Analysis
Fourteen LLMs (5 proprietary, 9 open-weight) were evaluated across both English and Chinese with identical settings. Strong numerical results emerged:
- Top models (GLM-5, Claude-Opus-4.7, Kimi-K2.6, Seed-1.8) achieve mRS in the 68–71% range across languages.
- Session-level reliability remains weak: Even leading models manage only 23.5–26.9% Pass@Session at τ=0.60, and 8–9% at τ=0.75, underscoring instability in sustaining performance across turns.
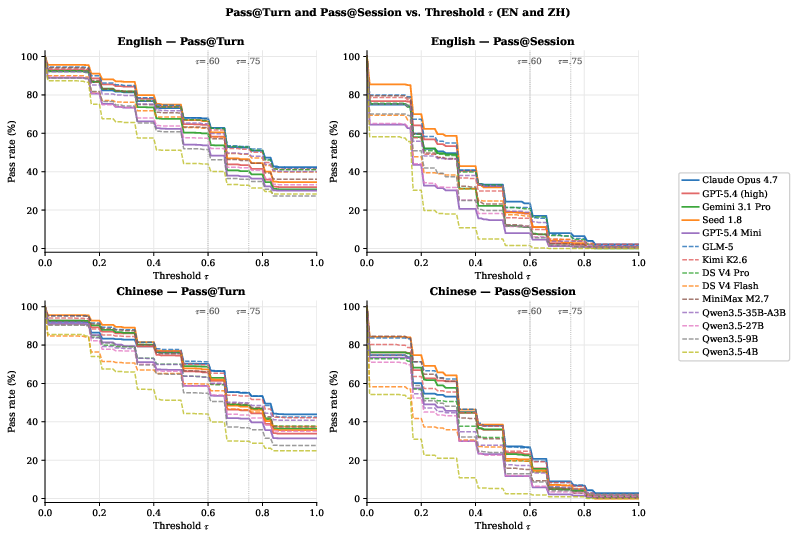
Figure 3: Pass@Turn and Pass@Session as functions of τ, evidencing sharp drop-offs for session-level reliability in both English and Chinese.
- Task difficulty hierarchy is consistent: IL and WU are relatively robust; DG and CR suffer marked performance deficits due to compositional reasoning and tool orchestration complexity.

Figure 4: Rubric scores by implicitness and task type reveal persistent weaknesses in Data Gathering and Clinical Reasoning.
- Implicit Physician Queries: Explicit phrasing consistently yields higher accuracy; implicitness types are reliably penalized, with AE yielding the worst degradation.
- Patient Communication: Patient-interview turns universally score lower (mean drop 26.4pp), indicating that subjective information integration remains a major obstacle.
- Language-conditioned safety priors: Certain models display higher performance in Chinese than English, driven partly by safety-oriented tool-invocation suppression in English.
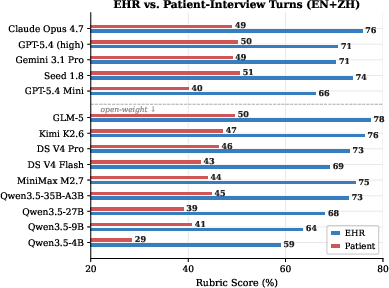
Figure 5: Rubric score comparison between EHR-only and patient-interview turns, showing significant drop on patient interview tasks.
Data Generation Pipeline and Methodological Advances
The data pipeline leverages coordinated LLM agents for patient selection, session planning, question generation (explicit/implicit variants), tool call planning, answer generation, and multi-stage quality validation. This ensures:
Practical and Theoretical Implications
PhysAssistBench provides definitive evidence that isolated gains in clinical knowledge, tool use, or patient dialogue do not translate to reliable multi-turn assistance. The bottleneck is interactive robustness across underdetermined queries, ambiguous patient information, and structured EHR operations. Key takeaways:
- Integrated evaluation is indispensable: Benchmarks must reflect true agentic workflows, not static QA.
- LLM coordination remains unsolved: Sustained tool orchestration and evidence integration are beyond frontier models’ capability, especially under implicit, context-rich instructions.
- Data enrichment is not a solution: Performance invariance across data richness tiers indicates reasoning, not information, is the constraint.
- **Generalization across languages and clinician behaviors requires explicit safety/policy modeling in agent architectures.
Theoretically, this work motivates a shift from parametric knowledge expansion to explicit modeling of context resolution, anaphora, ellipsis, and tool-centric planning within clinical dialogue. Practically, PhysAssistBench sets a new standard for multi-turn, cross-modal evaluation and provides a pathway for scalable, high-fidelity synthetic clinical benchmarks.
Limitations and Future Directions
PhysAssistBench is restricted to four core clinical scenarios and two languages, excludes critical care, and leverages general-purpose LLMs rather than domain-specialist models due to tool interface constraints. Future extensions should target:
- Broader clinical coverage (critical care, chronic management, multidisciplinary workflows).
- Expanded expert validation (turn-level review by diverse clinicians).
- Adaptive pipeline design (meta-agent for scenario expansion).
- Multi-language and regional generalization.
- Tool-use scaffolding for domain-specific LLMs.
Conclusion
PhysAssistBench establishes a rigorous, clinically grounded benchmark for physician-assistant LLMs, exposing persistent bottlenecks in interaction robustness, implicit query handling, and patient communication. The results underscore the need for new agent architectures capable of coordinated, context-aware, tool-mediated clinical assistance. The benchmark and code are available for community use, providing a foundation for research on interactive clinical AI (2606.18613).