Learning to Fold: prizewinning solution at LeHome Challenge 2026 (1st place online, 2nd offline)
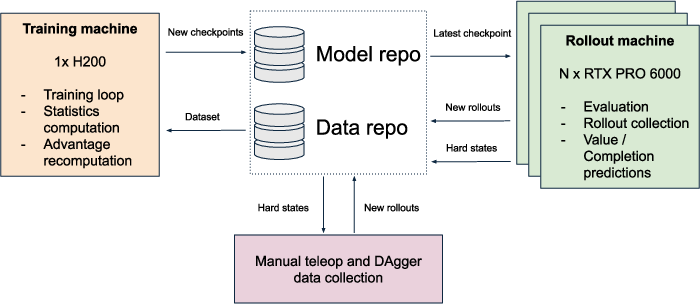
Abstract: I describe my solution to the LeHome Challenge 2026, an ICRA 2026 competition on bimanual garment folding. The system placed 1st of 62 teams in the online (simulation) round and 2nd in the real-world final. It improves a vision-language-action (VLA) policy with a reinforcement-learning loop. The policy is its own value function: the same network that predicts actions also predicts success, progress, and a few task-relevant future quantities, and those predictions drive advantage estimation, live failure detection, and candidate selection. The work mostly recombines existing RL ideas with engineering and optimization contributions that can be used together as one recipe or individually: AWR + RECAP combined for flow-matching VLA; an asynchronous distributed training / rollout pipeline through HuggingFace Hub; inference-time hyperparameters optimization via Thompson sampling; a sim-to-real recipe with camera-alignment tooling, heavy augmentation and DAgger-like HIL data collection.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper tells the story of how one researcher taught a two‑armed robot to fold different kinds of clothes (shirts and pants) very reliably. The system won 1st place out of 62 teams in the online (simulated) round of the LeHome Challenge 2026 and 2nd place in the real‑world final at a major robotics conference.
The key idea: use one smart model that sees camera images and decides what the robot should do next, and then make that model better with practice using reinforcement learning (RL). Clever engineering made the training fast, the decisions safer, and the move from simulation to a real robot practical.
What questions did the paper try to answer?
- How can a robot reliably fold soft, floppy clothes that change shape in tricky ways?
- How can it learn when the only official “score” is at the very end (folded perfectly or not)?
- How can it handle shirts and pants it has never seen before?
- How do you train for a real robot when you don’t have access to the competition’s robot?
How did they do it? (Simple explanation with analogies)
Think of the system as a team inside the robot:
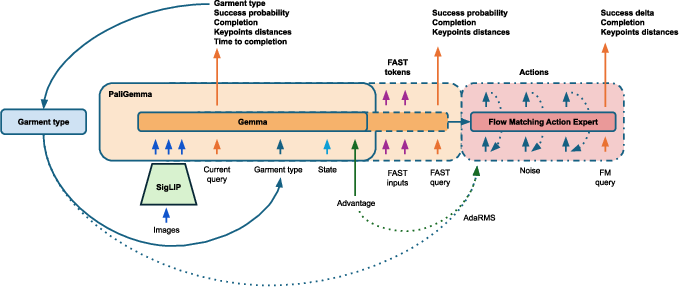
- The player: a model that watches three cameras (top and two wrist cams) and outputs a short “action clip” (about one second of joint movements) for both arms.
- The coach + scorekeeper: the very same model also predicts “How likely am I to succeed from here?” and “How far along am I?” and even “What will the cloth look like a moment later?” These extra predictions help it judge its own moves.
To train and improve, they built a fast practice loop:
- Many practice games in a realistic video game (simulation). Multiple computers run the robot folding over and over.
- A trainer machine picks up the newest practice data, updates the model, and publishes new versions for the practice machines to try right away. They shared everything through a public model hub so machines stay in sync without waiting.
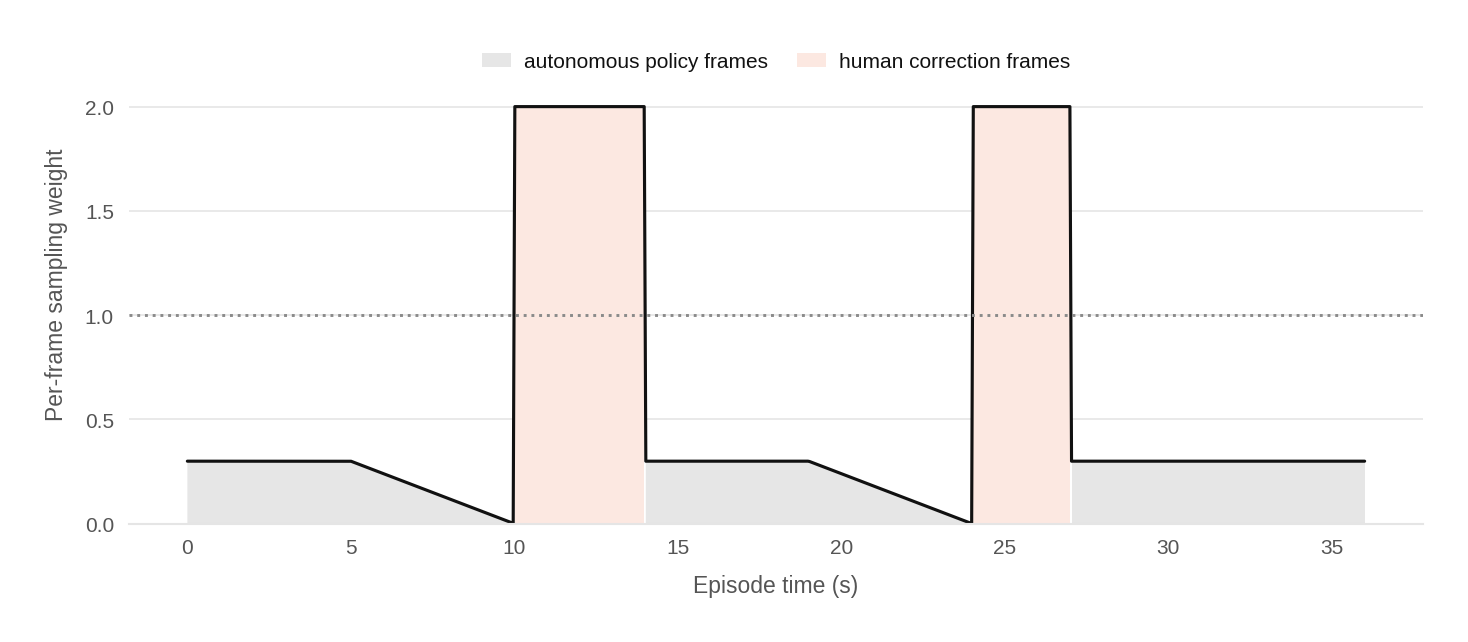
- A human helper can step in on hard cases (like when the robot messes up), quickly fix the cloth for a few seconds, and let the robot finish. Those “rescued” episodes teach the robot how to continue from messy situations.
Key learning tricks, in plain words:
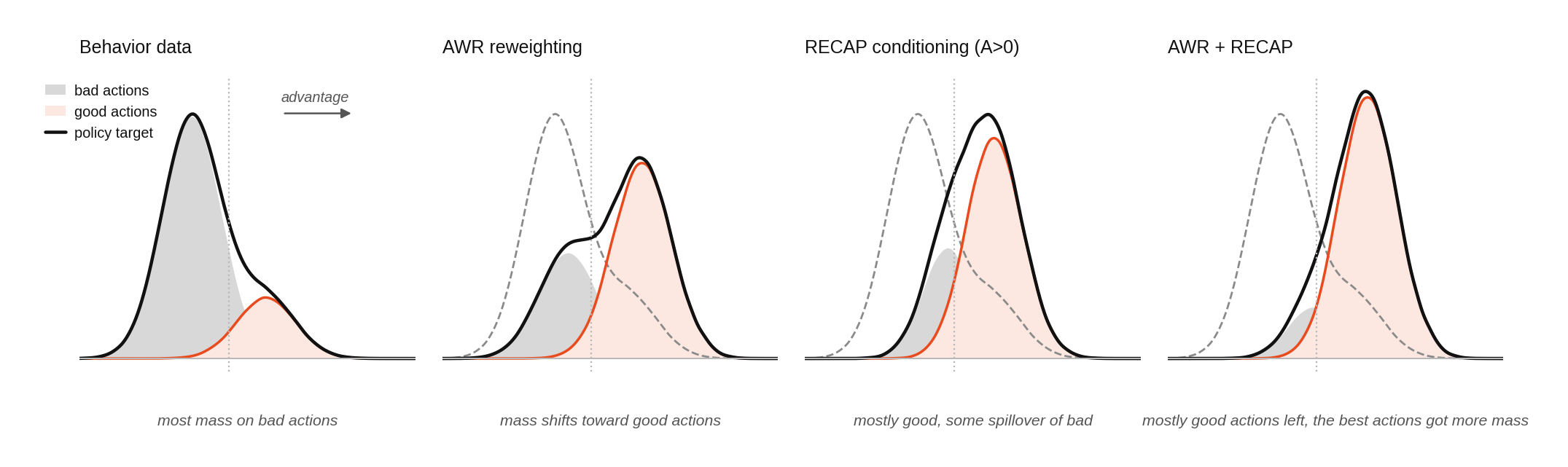
- Learn more from good moves: Advantage‑Weighted Regression (AWR) means “replay the good moments more often,” like a sports team watching the best clips repeatedly.
- Ask for only good moves: Advantage conditioning (RECAP‑style) means the model is told “focus on moves that usually lead to success.” At test time, it can run two versions of itself—one “neutral,” one “aiming for success”—and blend them, like turning a confidence knob.
- Action “de‑blurring”: The model first makes a rough, noisy guess for the next action clip and then refines it step by step, like sharpening a blurry photo into focus. This is called flow matching.
- Self‑checks from pixels: The model predicts from the images:
- Chance of final success (value).
- Progress (how far into the task we are).
- Key distances on the cloth (e.g., “Are the sleeves close enough?”). These are the same geometric checks the competition uses to judge success.
- A short‑term “future glimpse” (what those distances will look like in about one second if we do this action).
- These tiny “world model” predictions are cheap and practical, and they power better scoring and better choices.
Smart data collection:
- Success replays: When a fold goes well, save an early state and re‑run it with tougher visual changes (new textures, colors, lighting, camera jitter). This multiplies rare successes into many training examples.
- Hard mining: When the robot ruins a promising attempt, save that moment and try again later—great for learning to avoid mistakes.
- Curriculum and random sampling: Mix easy and hard garments so the model steadily improves.
- Heavy visual and camera “augments”: Randomly change garment colors, patterns, lights, camera positions, and more so the model doesn’t get fooled by small changes.
Making it work on a real robot:
- A “camera overlay” tool to line up simulated and real camera views.
- Even stronger visual randomness so the model is not surprised by the real world.
- Human‑in‑the‑loop demos on the real robot (brief teleop fixes).
- A simple garment‑type token (shirt or pants) that the model predicts from the first frames and then uses as a hint.
Choosing the best way to run the model:
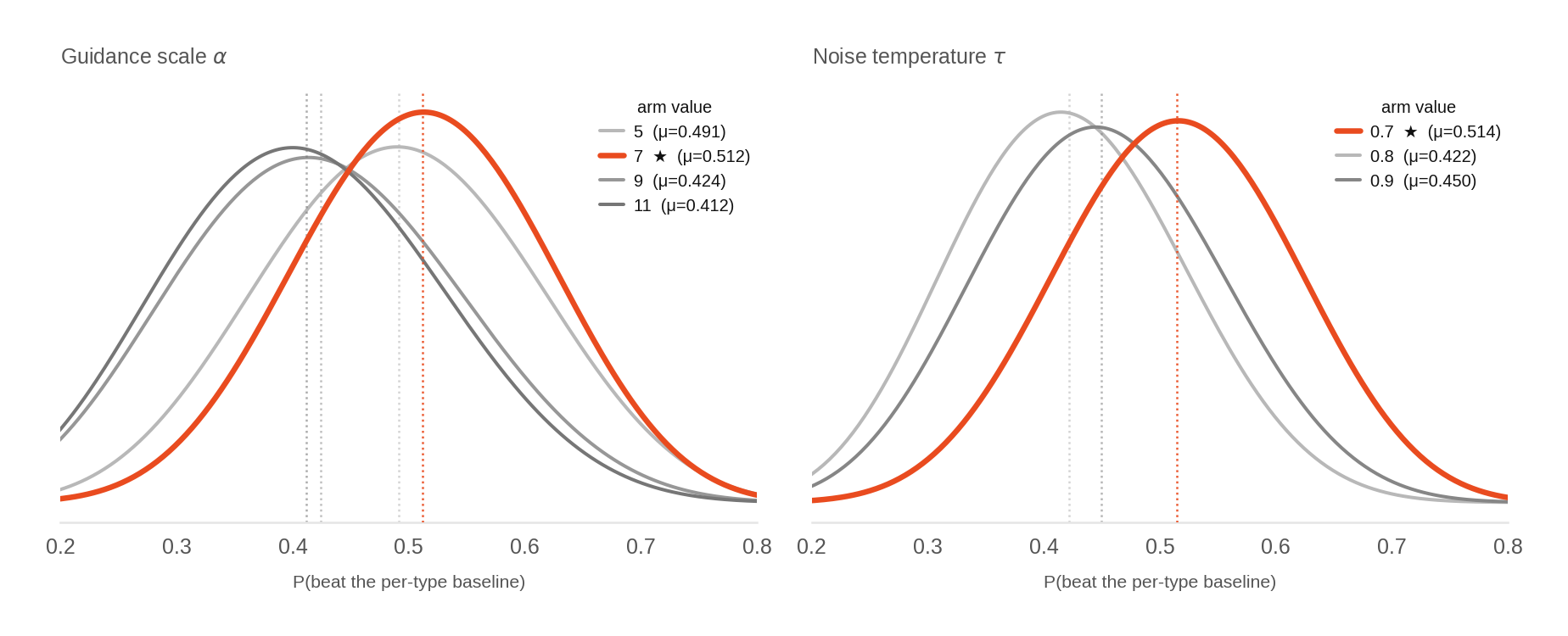
- There are several “knobs” at test time (how long to run, how fast to play back actions, how much to prefer “good moves,” how many action candidates to try in parallel, etc.). The system treats tuning these like a fair taste test (Thompson sampling): try different settings, keep what works best for each garment type.
What did they find?
- Top results: 1st place online (79.63% overall success), 2nd place on the real robot.
- One model did double duty well: Using the same network to both act and judge (predict success, progress, and near‑future cloth state) worked and made training and serving simpler.
- “Learn from the good” + “aim for good” is a strong combo: Replaying high‑quality moments (AWR) and conditioning the model to favor successful moves (RECAP‑style) improved reliability without breaking actions.
- Cheap future predictions helped choose actions: When the model generated several candidate action clips, it picked the one that most improved its predicted chance of success.
- Engineering mattered a lot: Asynchronous training/collection, success replays with heavy randomness, and occasional checkpoint rollbacks (jumping back to a slightly older model to escape ruts) noticeably boosted performance.
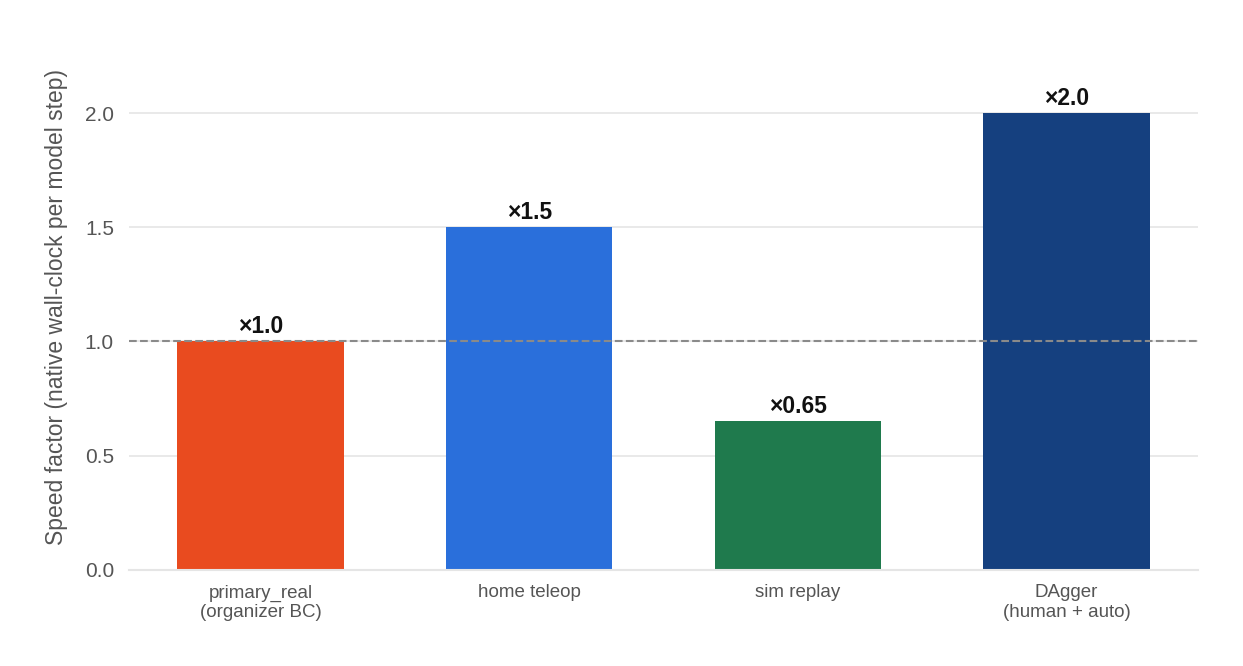
- Human help is more useful on real robots than in sim: Teleoperating inside the simulator was hard and less helpful; quick human corrections on a real robot were very effective.
Why is this important?
- A practical recipe for robot skills: The paper shows a clear, reusable way to upgrade a vision‑based robot policy using RL—especially when only the final outcome is scored.
- Less guesswork, more self‑assessment: Teaching the policy to predict its own success and near‑future state gives it “common sense” for choosing safer, smarter actions.
- Sim‑to‑real made doable: With the right camera alignment and strong visual randomization, skills learned in a simulator can transfer quickly to a real robot, even without the exact competition hardware.
- General lesson: For tasks with soft, changeable objects (like clothes), focusing on “learn more from good moves” and using simple, meaningful signals (key cloth distances) can beat more complicated, fragile methods.
Final takeaway
If you want a robot to do a delicate, long task—like folding clothes—don’t just copy demonstrations and hope. Let the robot:
- practice a lot in simulation,
- learn to judge how well it’s doing from the camera images,
- replay and focus on its best moments,
- try multiple action ideas and pick the one it believes will help most,
- and use realistic visual randomness and a bit of human rescue to bridge to the real world.
This approach produced a champion‑level folder and offers a solid blueprint for other complex household tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps, limitations, and open questions left unresolved by the paper that future work could address:
- Lack of ablations for key architecture choices. Quantify the marginal contribution and interactions of: garment-type input token, advantage conditioning (token + AdaRMS), AdaRMS multi-signal vector, Exclusive Self-Attention (XSA), cross-layer KV mixing, correlated flow-matching noise, soft inpainting, multi-sample flow, and smooth per-timestep action normalization.
- No controlled comparison of RL algorithms for flow-matching VLAs. Benchmark AWR+RECAP vs PPO/GRPO-style adaptations for flow-matching, vs offline AWAC/AWR, with matched data/compute to understand exploration, stability, and sample efficiency trade-offs.
- Advantage via sampling vs loss weighting. Validate that implementing AWR through the sampler (rather than weighted loss) does not introduce hidden biases or higher variance; measure impact on aux-head calibration despite IS weighting.
- Policy-as-value-function bias. Assess whether sharing representations for action and value/Q heads induces optimism or coupling that destabilizes training; compare to a separate value/Q network or delayed target networks.
- Calibration and robustness of the success and completion heads. Provide reliability diagrams, temperature scaling, and drift analysis under heavy augmentation and dataset staleness; quantify the effect of label smoothing and “success tail boost” on calibration and advantage variance.
- Progress head trained on successful episodes only. Investigate bias introduced by excluding failed episodes; evaluate alternative targets (e.g., monotone surrogate progress) that are policy-stable but defined across successes and failures.
- CUPED-style variance reduction is under-specified. Precisely define the estimator, the covariates used, and quantify variance reduction on advantage estimates; compare to baselines without CUPED.
- Privileged signals limit real-world transfer. The keypoint-distance heads and reward shaping depend on simulator-only keypoints. Develop vision-only surrogates or weakly supervised detectors usable on real robots and quantify their effect on both training and inference-time selection.
- Reward shaping alignment with real-world scoring. The offline final used partial-credit, jury-scored outcomes, but the reward is binary via success checker. Study alternative rewards that align with partial credit and human judgment, and their impact on real performance.
- Failure detection heuristics are ad hoc. The EMA drop threshold (e.g., 0.12) and stuck detector are heuristic. Learn a data-driven failure detector and compare thresholds for early termination vs recovery opportunities.
- Limited recovery learning. The method mainly improves “first-try” cleanliness; autonomous recovery after errors remains weak. Develop recovery curricula (e.g., targeted resets to hard states), explicit recovery rewards, or exploration bonuses that avoid leaving the valid-action manifold.
- DAgger efficacy unquantified. In sim, DAgger “didn’t help much,” while on the real robot it was critical. Quantify how much DAgger contributes by task and stage, determine optimal weighting vs RL/BC data, and analyze how teleop quality and latency affect learning.
- Staleness decay and rollback schedules are heuristic. Systematically ablate the rollout dataset decay factor (0.98), minimum floor, and checkpoint rollback cadence; analyze convergence, catastrophic forgetting, and stability vs these schedules.
- Multi-dataset sampling policy is ad hoc. Evaluate prioritized experience replay with principled correction across sources (BC, DAgger, RL), vs the current per-source shares and per-garment sampling heuristics; assess fairness and variance.
- Train–test mismatch in advantage conditioning. Training randomly masks the advantage token for A≥0, but inference always conditions. Quantify the induced distribution shift and test alternative masking schedules or inference-time dropout for robustness.
- Best-of-N candidate selection and Q residual risks. Measure how much Δsuccess-based selection improves success; assess overconfidence and miscalibration risks; compare to model-based rollouts using predicted future keypoint distances; study compute–performance trade-offs for real-time constraints.
- Inference-time HPO via Thompson sampling may overfit sim. Evaluate generalization of tuned hyperparameters across environments/garments/robots, and test adaptive, on-the-fly autotuning that uses only on-board signals (no simulator ground truth).
- Garment-type inference is single-shot and fixed. Study dynamic garment-type re-estimation, confidence thresholds, and recovery from misclassification; evaluate few/zero-shot extension to new garment categories without retraining the policy.
- Not using available depth. Quantify the impact of incorporating overhead depth (and possibly wrist depth) on generalization, recovery, and keypoint-distance estimation; compare to RGB-only under strong augmentations.
- Domain randomization lacks target matching. Provide a principled method (e.g., adversarial/BO-based randomization) to match the augmentation distribution to the real rig; measure the sensitivity of performance to each augmentation channel.
- Chunk length and replanning horizon are fixed (30 steps). Ablate chunk sizes and replanning frequencies; study the trade-off among stability, responsiveness, and compute, especially under real-time constraints and 20 Hz control.
- Action-space design unexamined. Compare joint-delta control to Cartesian delta, hybrid controllers, or learned impedance; measure effects on sample efficiency, sim–real transfer, and recovery behaviors.
- No tactile or force sensing. Investigate whether light force/torque or tactile signals improve grasp reliability, contact-rich manipulation, and recovery from wrinkles/entanglements.
- Generalization breadth is unclear. Provide stress tests across unseen fabrics (thickness, stiffness, friction), severe initial crumpling, occlusions, and lighting extremes; report failure taxonomies and robustness gaps.
- Auxiliary loss weights are hand-tuned. Explore automated multi-objective weighting (e.g., GradNorm, uncertainty weighting) and gradient surgery to resolve conflicts among aux heads and action loss.
- XSA inclusion not justified empirically. Conduct controlled studies of XSA’s effect on convergence, sample efficiency, and transfer, including layer-wise ablations and comparisons to alternative regularizers.
- Importance weighting only applied to aux heads. Examine bias introduced by not debiasing the action loss when sampling is advantage-skewed, and whether occasional uniform sampling improves robustness.
- Replay strategies’ distribution shift. Assess how success/near-success/failure state replays bias learning; quantify the net effect on fresh-episode performance and exploration, and evaluate PER-like scheduling vs current heuristics.
- Live failure trimming vs recovery potential. Early termination saves time but may remove valuable recovery data. Study conditional continuation with recovery incentives vs trimming, and the effect on overall success.
- Real-to-real transfer not characterized. The method transferred sim→own robot→evaluation robot once; characterize robustness across multiple real rigs (camera intrinsics/extrinsics, friction, gripper geometry) and define minimal calibration needed.
- Reproducibility and variance. Report seed variance, per-garment variance, and sensitivity to rollout ordering; release fixed evaluation scripts and configs to enable exact replication.
- Safety constraints are absent. Develop constraints (e.g., joint/velocity/force envelopes, cloth-damage proxies) and constrained-RL training to avoid entanglement or hardware stress during exploration/recovery.
- Scaling laws and compute. Provide scaling curves for data, model size (prefix/expert), and compute vs success; assess diminishing returns and optimal allocation between rollout collection and training.
- Extending the world-model proxy. Investigate training the keypoint-distance predictor purely from images with synthetic supervision and a small set of real annotations; measure oracle–proxy gap and impact on both reward shaping and inference-time candidate scoring.
- Bridge from selection to training. The Δsuccess head is used for candidate selection only; study training-time uses (e.g., Q-augmented AWR targets, conservative policy iteration on Δsuccess) to close the loop between selection quality and policy improvement.
Practical Applications
Immediate Applications
The following applications can be deployed or prototyped with current tools and resources, leveraging the paper’s methods and engineering recipes.
- Bimanual folding stations for simple textiles (towels, napkins, standard T-shirts)
- Sector: robotics, hospitality, laundry services, e-commerce logistics, retail backrooms
- What: Use the VLA+RL policy and sim-to-real recipe to automate folding of rectangular or simple garments (e.g., towels, basic tees) on bimanual arms in controlled stations.
- Tools/workflows: Isaac Sim for rapid success-replay data, the heavy environment augmentation engine, camera-overlay calibration tool, success/failure snapshot replay, and the DAgger HIL loop for fixing edge cases.
- Assumptions/dependencies: Requires a reliable dual-arm platform (e.g., SO-ARM101-class), a 3-camera setup, and access to a simulator for initial data. Privileged keypoint-based signals used for shaping in sim must be replaced by perception estimates in real settings.
- Runtime monitoring and failure handling in existing robot policies using self-predicted signals
- Sector: robotics operations, manufacturing, warehousing
- What: Integrate the “policy as its own value function” heads to enable live failure detection, early termination, and human handover triggers without adding a separate critic.
- Tools/workflows: Success probability and completion heads; stuck detector using value/variance signals; best-of-N candidate selection using the Δsuccess head.
- Assumptions/dependencies: Requires a VLA-like policy with auxiliary heads or adaptation of existing models to produce these signals; guardrails for safety when using best-of-N.
- Inference-time performance tuning via online bandits
- Sector: software/robotics deployment, MLOps
- What: Deploy Thompson-sampling bandit to optimize inference hyperparameters (chunk length, playback speed, inpainting onset, guidance scale, noise temperature, number of candidates) per task or item category.
- Tools/workflows: Lightweight bandit service attached to rollout workers; online telemetry to update priors.
- Assumptions/dependencies: Sufficient online traffic to learn; boundaries/safety constraints for parameter ranges.
- Asynchronous RL “flywheel” for continuous robot improvement
- Sector: academia, industrial R&D labs
- What: Adopt the HF Hub-based trainer–rollout–DAgger loop for any manipulation task (e.g., pick-and-place, cable routing, opening doors) to scale data collection with minimal orchestration.
- Tools/workflows: Stateless policy server, rollout workers behind a shared Hub, sampler-based AWR, RECAP-style advantage conditioning, checkpoint rollback for escaping local optima.
- Assumptions/dependencies: Access to GPUs for training/rollouts, ability to snapshot/replay simulation states; Hub infrastructure and permissions.
- Data efficiency in simulation using physics-state snapshots
- Sector: robotics research, simulator engineering
- What: Multiply rare successes and mine hard failures with success/near-success/failure state replays, combined with stronger domain randomization for robustness.
- Tools/workflows: Success replay with heavy augmentations; semi-success replays; hard-mining queues; per-episode augmentation seeds saved/restored with snapshots.
- Assumptions/dependencies: Simulator must expose/restore full physics states; careful management of physics-affecting augmentations when replaying.
- Sim-to-real transfer for vision-only policies
- Sector: robotics, systems integration
- What: Use the paper’s sim-to-real package (heavy image/lighting/pose augmentations, motion-velocity alignment, camera-overlay calibration, DAgger on real hardware) to port vision-only policies to similar rigs that lack depth sensors.
- Tools/workflows: Aggressive visual DR, camera overlay tool for calibration, real-robot DAgger station to fix residual errors and collect corrective data.
- Assumptions/dependencies: Matching camera geometry and kinematics across rigs or precise alignment; safety-rated teleop and data logging in real environments.
- Workflow-level improvements for VLA training
- Sector: ML systems, academia
- What: Adopt specific engineering patterns that showed practical benefit:
- AWR through the sampler (instead of per-sample loss weighting) for compute efficiency
- Runtime multi-dataset sampling (no merges; per-source shares and decay)
- Per-timestep action normalization for chunked flow matching
- Correlated flow-matching noise; soft inpainting at chunk boundaries; cross-layer KV-cache mixing
- AdaRMS multi-signal conditioning (time + garment type + advantage)
- Assumptions/dependencies: Availability of flow-matching VLA frameworks; modest code changes to existing stacks.
- Category-agnostic deployment with early episode self-classification
- Sector: robotics, software
- What: Use the garment-type head to bootstrap category tokens when labels are unavailable at inference; extendable to other tasks (tool type, object class).
- Tools/workflows: One-shot category inference at episode start; inject learned category token thereafter.
- Assumptions/dependencies: High initial classification accuracy; fallback if misclassification is detected (e.g., failure detection triggers re-classification).
- Teaching and benchmarking kits for deformable-object manipulation
- Sector: education, academic research
- What: Package the challenge assets, keypoint-based reward shaping, and rollout/debug overlays to create lab modules for courses on RL for robotics and deformable-object manipulation.
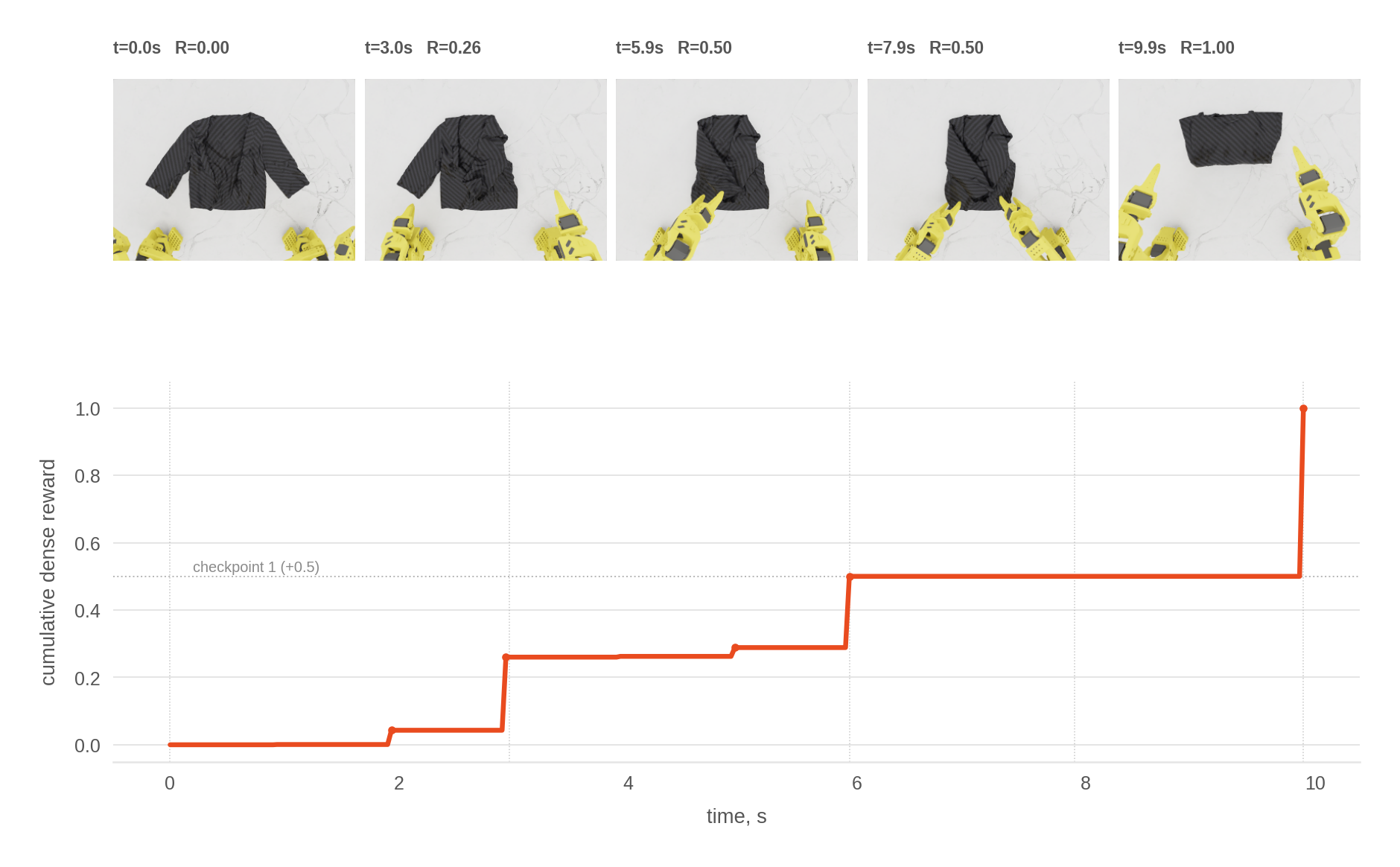
- Tools/workflows: Isaac Lab environments, dense reward from success checker, episode videos with overlaid reward/value/advantage traces.
- Assumptions/dependencies: University compute and simulator licenses; instructors comfortable with Hub-based pipelines.
- Safety and reliability telemetry for robot fleets
- Sector: industrial robotics operations
- What: Deploy the success/advantage heads as telemetry signals to monitor health of deployed policies and preemptively route tricky cases to human supervision.
- Tools/workflows: Live dashboards showing per-episode success probability and completion; automated routing thresholds.
- Assumptions/dependencies: Policy export must include auxiliary heads; on-robot compute/storage for logging.
Long-Term Applications
The following applications are promising but require further research, scaling, or ecosystem development before wide deployment.
- General-purpose home laundry folding robot
- Sector: consumer robotics, smart home
- What: A household robot that reliably folds diverse garments and linens under clutter, occlusions, and lighting changes; handles recovery after mistakes autonomously.
- Path from paper: Extend garment coverage, strengthen autonomous recovery (beyond DAgger), and integrate robust 3D perception to replace sim-only privileged signals.
- Assumptions/dependencies: Affordable dual-arm hardware, robust perception for deformable objects, safety certifications, acceptable cost-of-ownership.
- Comprehensive deformable-object manipulation in industry
- Sector: textiles manufacturing, packing, returns processing, retail
- What: Robots that handle flexible materials end-to-end (repositioning during sewing, defect localization, automated refolding, bagging).
- Path from paper: Generalize keypoint- or feature-based “world-model-lite” heads to real images; broaden sim assets; develop scalable recovery strategies.
- Assumptions/dependencies: Reliable perception substitutes for sim keypoints; custom grippers; integration with conveyors and QA systems.
- Assistive care and healthcare applications
- Sector: healthcare, eldercare, rehabilitation
- What: Robots that assist with dressing, bed-making, and sterile draping; tasks demand gentle, compliant bi-manual control with strong safety margins.
- Path from paper: Adapt VLA+RL framework with patient-in-the-loop constraints, failure prediction for safe handovers, and validated sim-to-real protocols for clinical environments.
- Assumptions/dependencies: Clinical approvals, human factors validation, high-reliability hardware and sensing; liability frameworks.
- Unified policy–value architectures as a standard control pattern
- Sector: robotics research, foundation models for control
- What: Broad adoption of policies that jointly predict actions and their outcomes (success, progress, predicted deltas) to enable self-evaluation, planning, and selection at inference.
- Path from paper: Validate across diverse tasks and robots; combine with tree search or short-horizon lookahead using Δsuccess; systematize best-of-N candidate selection with safety gates.
- Assumptions/dependencies: Wider benchmarks; tooling for real-time candidate evaluation; theoretical and empirical safety guarantees.
- World-model-lite planning via task-relevant future predictions
- Sector: robotics, autonomous systems
- What: Replace expensive pixel-level world models with sparse, task-relevant future state predictions (e.g., distances/contacts) for planning and reward shaping.
- Path from paper: Learn task-relevant keypoints or metrics directly from vision in real environments; extend to cables, cloth stacks, and nonrigid hoses.
- Assumptions/dependencies: Robust keypoint detection without privileged data; generalization to novel geometries.
- Autonomy with reduced human-in-the-loop correction
- Sector: robotics R&D
- What: Move from DAgger-heavy pipelines to autonomous exploration/recovery strategies that are sample-efficient for deformable objects.
- Path from paper: Blend AWR/RECAP with exploration methods compatible with flow-matching policies; develop safe, on-robot exploration.
- Assumptions/dependencies: New algorithms for exploration on thin action manifolds; safety interlocks; better recovery curricula.
- Standardized sim-to-real evaluation frameworks
- Sector: policy, consortiums/standards bodies, academia
- What: Establish benchmarks and tooling standards (camera overlay calibration, augmentation suites, snapshot replay protocols) for reproducible sim-to-real research in deformable-object manipulation.
- Path from paper: Open tooling around camera alignment, augmentation recipes, and replay machinery; shared HF Hub-style artifact registries.
- Assumptions/dependencies: Cross-institution agreement; governance for dataset sharing; privacy and IP concerns.
- Online bandit “autopilots” for deployed robots
- Sector: industrial robotics, MLOps
- What: Always-on bandit layer that optimizes inference hyperparameters per task/site while respecting safety/latency budgets.
- Path from paper: Integrate bandit optimization with risk constraints, A/B testing, and rollback policies across fleets.
- Assumptions/dependencies: Sufficient episode volume; robust monitoring and guardrails; regulatory acceptance for adaptive systems.
- Broad adoption and validation of Exclusive Self-Attention (XSA)
- Sector: ML research, model architecture
- What: Evaluate XSA across VLAs/VLMs for stability and generalization, potentially improving large-scale control models.
- Path from paper: Comprehensive ablations; library support; compatibility with fused attention kernels for deployment.
- Assumptions/dependencies: Maturity of XSA implementations; evidence of consistent gains across tasks.
- Cloud-based collaborative training exchanges
- Sector: academia/industry collaborations, policy
- What: Shared hubs (HF Hub-like) for models, rollouts, and checkpoints enabling asynchronous, multi-institution training while preserving data provenance.
- Path from paper: Formalize datasets’ decay/weighting policies, versioning, and privacy/security protocols.
- Assumptions/dependencies: Legal data-sharing frameworks, funding, standard APIs, and data governance.
- Household “assist-and-autonomy” workflows
- Sector: consumer robotics
- What: Robots that ask for brief human corrections when confidence drops (via teleop or simple guidance), then resume autonomous folding/tidying.
- Path from paper: Refine failure detection thresholds; UX for quick corrections; robust resume-from-state logic.
- Assumptions/dependencies: Intuitive teleop interfaces; reliable connectivity; user acceptance and safety.
Glossary
- AdaRMS: A conditioning scheme that modulates RMSNorm layers with learned vectors (e.g., flow time, garment type, advantage) to steer the action network. "multi-signal AdaRMS conditioning"
- Advantage conditioning: Feeding estimated advantage as an input to bias action generation toward better actions. "RECAP-style~\cite{recap2025} advantage conditioning"
- Advantage Weighted Regression (AWR): An RL method that regresses to actions weighted by their estimated advantage to improve a policy without policy gradients. "AWR + RECAP combined for flow-matching VLA;"
- AWAC: Advantage-Weighted Actor-Critic; a regression-style RL algorithm that weights supervised updates by advantage. "advantage-weighted regression methods such as AWAC~\cite{nair2020awac}"
- Behavior cloning (BC): Supervised imitation learning that replicates expert actions from demonstrations. "Plain behavior cloning on the provided scripted demonstrations is not very robust"
- Bimanual: Involving two robotic arms working together on a task. "an ICRA 2026 competition on bimanual garment folding."
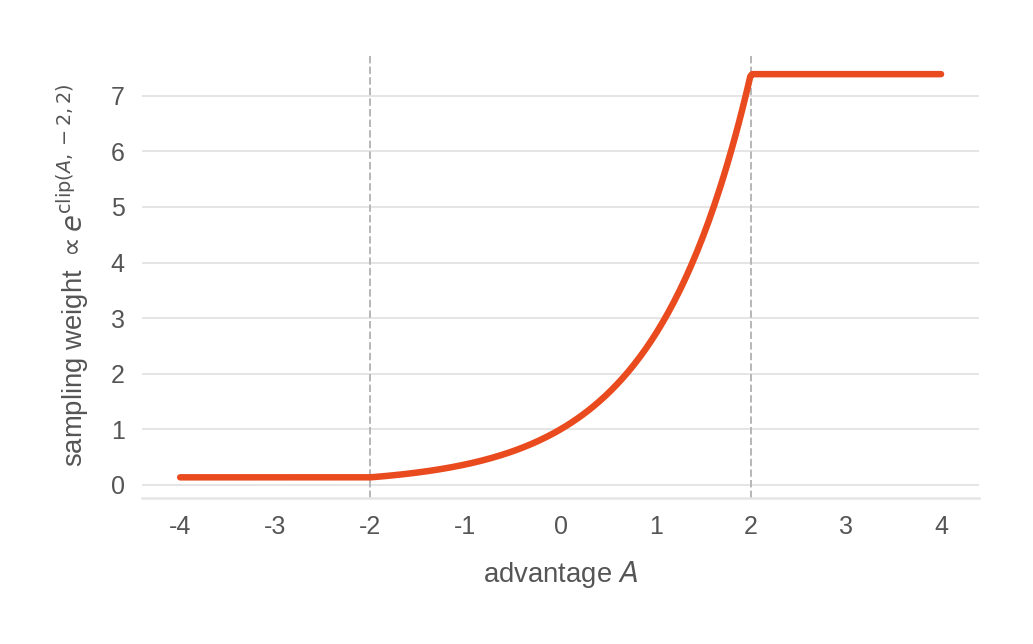
- Classifier-free guidance (CFG): An inference technique that mixes conditional and unconditional predictions to amplify desired behaviors. "which also unlocks classifier-free guidance (CFG) at inference"
- Correlated flow-matching noise: Noise with non-identity covariance used to seed the flow/denoising process, respecting action correlations. "Correlated flow-matching noise: the noise that seeds the denoising loop is drawn with the empirical action covariance (Cholesky factor from norm stats, shrinkage toward identity)."
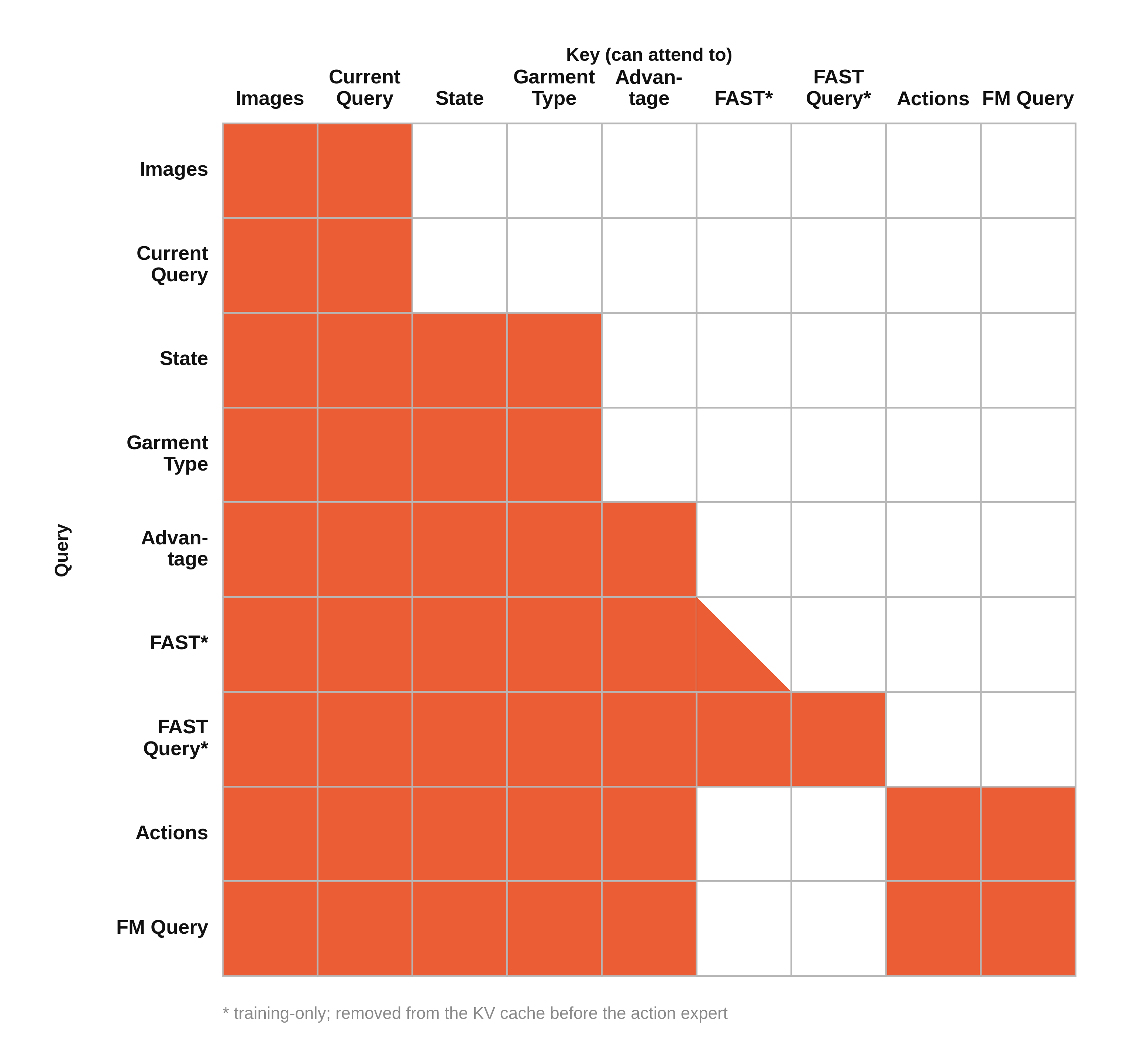
- Cross-layer KV-cache mixing: Replacing each layer’s keys/values with learned combinations across layers so the action model can choose which depths to attend to. "Cross-layer KV-cache mixing: before the action expert reads the prefix KV cache, each layer's K and V are replaced by a learned linear combination of all layers, letting the action expert choose which VLM depths to attend to."
- CUPED: A variance-reduction technique using a control variate to dampen estimates (here, value baselines). "a dampened (CUPED-style) value baseline,"
- DAgger: Dataset Aggregation; an interactive imitation learning approach that iteratively collects corrections and retrains. "I built a DAgger-style~\cite{ross2011dagger} loop:"
- Deformable-object manipulation: Robotics focusing on handling objects whose shape changes, like cloth. "simulation-driven robotics competition centered on deformable-object manipulation."
- Denoising loop: The iterative procedure in diffusion/flow models that transforms noise into structured outputs. "the noise that seeds the denoising loop is drawn with the empirical action covariance"
- Domain randomization: Randomizing visual and physical parameters during training to improve sim-to-real generalization. "Heavy domain randomization in both the sim (\S\ref{sec:env_aug}) and real (\S\ref{sec:heavy_aug}) rounds is the main lever I used against this."
- Exclusive Self-Attention (XSA): An attention variant that removes each token’s direct self-contribution to encourage cross-token interactions. "XSA~\cite{xsa2026} removes that path: after the attention step, the projection of the output onto the token's own value vector is subtracted"
- Exponential Moving Average (EMA): A smoothed running estimate giving more weight to recent values. "EMA-smoothed success prediction"
- FAST action tokens: Training-only tokens that guide representation learning for actions in vision-language(-action) models. "FAST action tokens~\cite{pertsch2025fast} in the prefix --- training-only auxiliary that shapes the VLM representation; absent at inference."
- Flow matching: A generative modeling approach that learns velocity fields to transform noise into data, here used for action generation. "via flow matching~\cite{lipman2023flow}"
- Generalized Advantage Estimation (GAE): A method to compute low-variance, biased advantage estimates using temporal smoothing. "and the two are combined with GAE into per-frame advantages"
- GRPO: Group-Relative Proximal Optimization; a PPO variant using group-relative baselines. "GRPO~\cite{shao2024grpo}"
- HuggingFace Hub: A model/data hosting service used here for distributed coordination of training and rollouts. "through HuggingFace Hub"
- Human-in-the-loop (HIL): Incorporating human corrections or feedback during training or data collection. "DAgger-like HIL data collection."
- Importance sampling (IS): A technique that reweights samples to correct for biased sampling distributions. "(inverse sampling (IS) probability, normalized per episode length)"
- Isaac Sim: NVIDIA’s robotics simulator used for evaluation and training. "evaluated in Isaac Sim~\cite{isaacsim2026}"
- Inpainting (soft inpainting): Blending or filling predicted action segments to ensure smooth transitions between chunks. "Correlation-aware soft inpainting at chunk boundaries"
- KL divergence (KL): A measure of difference between probability distributions, often used as a policy closeness constraint. "staying close (in KL) to the sampling policy."
- KV cache: Cached key-value tensors from transformer layers used to speed and structure attention at inference/training. "prefix KV cache"
- PPO: Proximal Policy Optimization; a popular on-policy RL algorithm for policy-gradient updates. "PPO~\cite{schulman2017ppo}"
- Policy-gradient updates: Optimization using gradients of expected returns w.r.t. policy parameters via log-probabilities. "log-probability policy-gradient updates"
- Proprioceptive: Relating to internal robot state sensing (e.g., joint positions/velocities). "the value heads cannot overfit to proprioceptive state"
- Q-function: An action-value estimator predicting expected return conditioned on state and action. "an action-conditional success residual that acts as a Q-function."
- RECAP: A conditioning framework that injects advantage signals into the model to bias action generation. "RECAP-style~\cite{recap2025}"
- RMSNorm: Root Mean Square Layer Normalization, a normalization technique for transformer layers. "modulates every layer's RMSNorm"
- SigLIP: A vision encoder pretrained with a sigmoid loss variant for image-text alignment. "a frozen SigLIP encoder"
- Sim-to-real: Transferring policies trained in simulation to real-world robots. "a sim-to-real recipe with camera-alignment tooling, heavy augmentation and DAgger-like HIL data collection."
- Teleoperation (teleop): Direct human control of a robot to demonstrate or correct behaviors. "via teleop"
- Thompson sampling: A Bayesian bandit strategy for balancing exploration and exploitation in parameter selection. "via Thompson sampling;"
- Time-to-completion (TTC): An estimate or prediction of remaining time until task completion. "Time-to-completion head."
- Vision-Language-Action (VLA): Models that integrate visual inputs, language/context, and actions, typically with transformer backbones. "vision-language-action (VLA) policy"
- World model: A predictive model of future states or task-relevant quantities used to plan or evaluate actions. "It is not a real world model, but it works as a very cheap analogue:"
Collections
Sign up for free to add this paper to one or more collections.