Autodata: An agentic data scientist to create high quality synthetic data
Abstract: We introduce Autodata, a general method that enables AI agents to act as data scientists who build high quality training and evaluation data. We show how to train (meta-optimize) such a data scientist agent, so that it learns to create even stronger data. We describe the overall formulation, and a specific practical implementation, Agentic Self-Instruct. We conduct experiments on computer science research tasks, legal reasoning tasks and reasoning with mathematical objects, where we obtain improved results compared to classical synthetic dataset creation methods. Further, meta-optimizing the data scientist agent itself delivers an even larger performance uplift. Agentic data creation provides a way to convert increased inference compute into higher quality model training. Overall, we believe this direction has the potential to change the way we build AI data.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “Autodata: An agentic data scientist to create high quality synthetic data”
1) What is this paper about?
This paper introduces Autodata, a way to let AI act like a data scientist. Instead of people writing all the practice problems and test questions that train AI, Autodata uses AI agents to design, check, and improve those questions on their own. The goal is to make better “synthetic data” (AI-made training examples) that helps models learn faster and perform better, especially on tough reasoning tasks.
2) What questions are the researchers trying to answer?
They ask:
- Can an AI “data scientist” design training and test questions that are the right level of difficulty for improving another AI model?
- Does iteratively checking and improving those questions lead to better results than older one-shot methods (like simple prompting)?
- Can we also train the data-creating agent itself to get even better over time?
3) How does it work? (Methods explained simply)
Think of training an AI like training a sports team:
- The team needs good practice drills (training data) that are neither too easy nor too hard.
- A coach watches how players perform, then adjusts drills to focus on what needs improvement.
Autodata does this with AI:
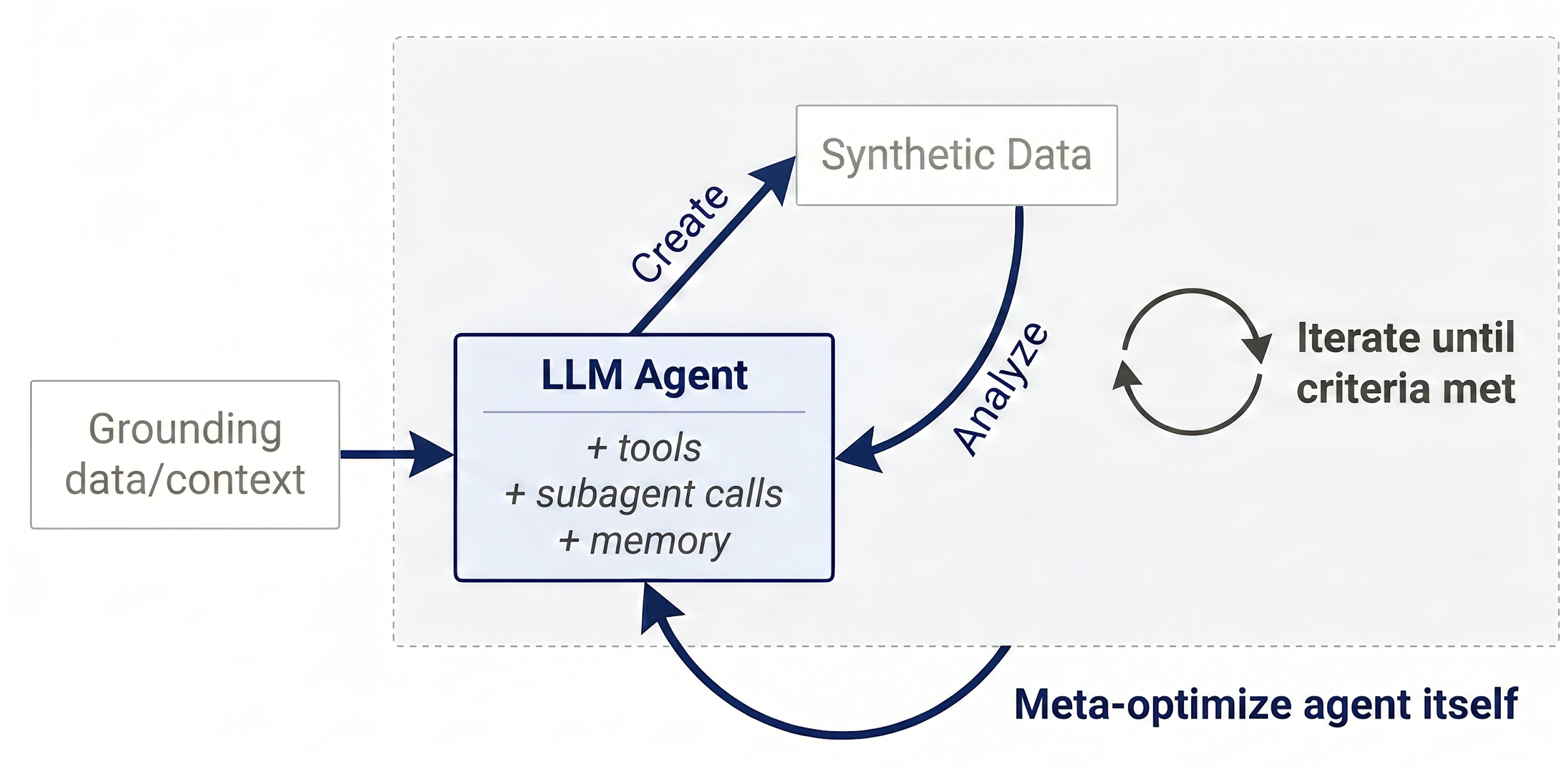
- An AI agent creates practice questions, looks at how models do on them, learns from mistakes, and updates the question-making strategy. This loop repeats to steadily improve data quality.
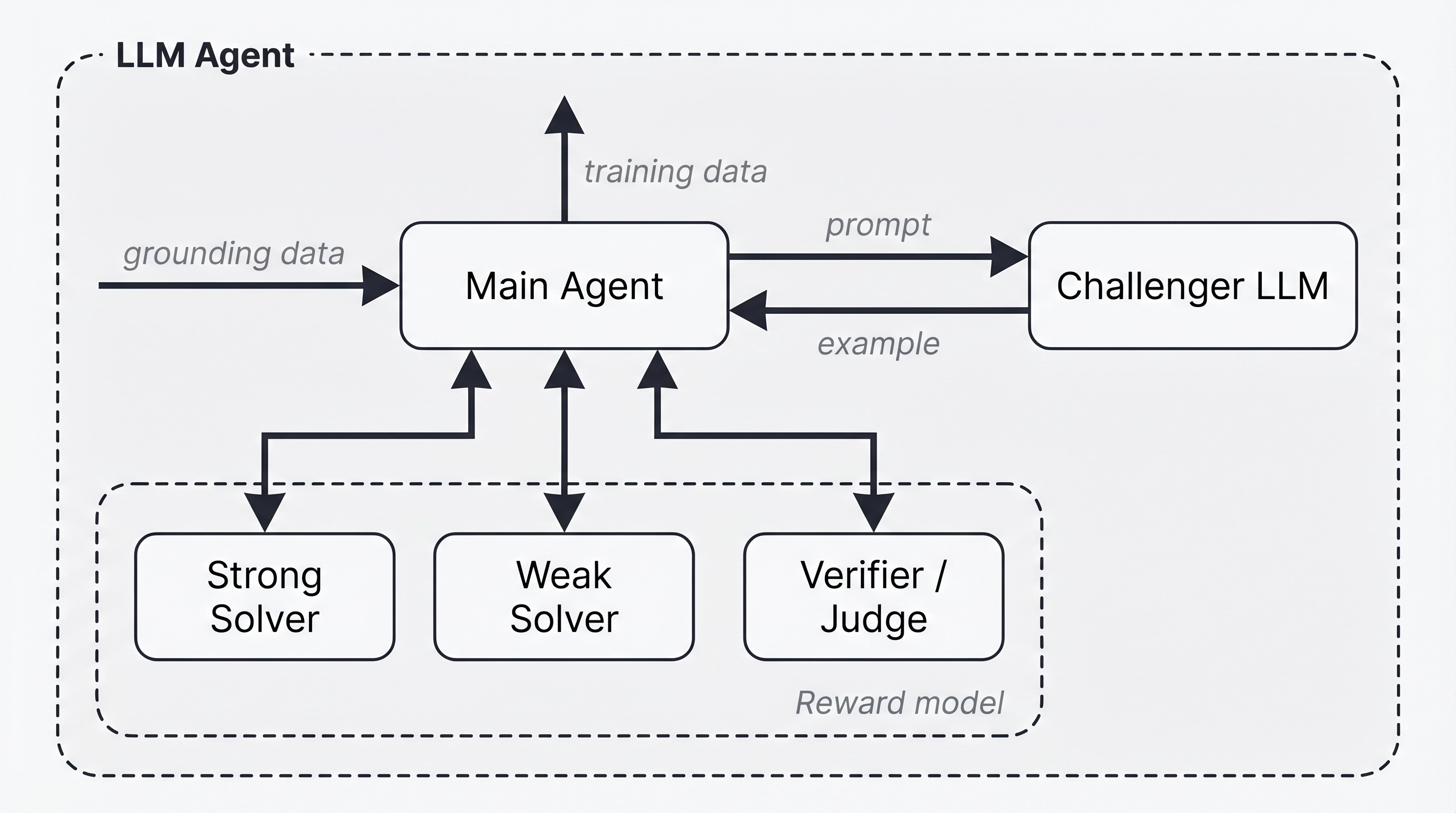
A specific version they test is called Agentic Self-Instruct. It uses four AI “subagents” with different roles:
- The system first creates a candidate question (like a problem from a math paper, a legal case, or a computer science paper).
- It then tests two solvers:
- A “weak solver” (a smaller or restricted model),
- A “strong solver” (a bigger or more capable model).
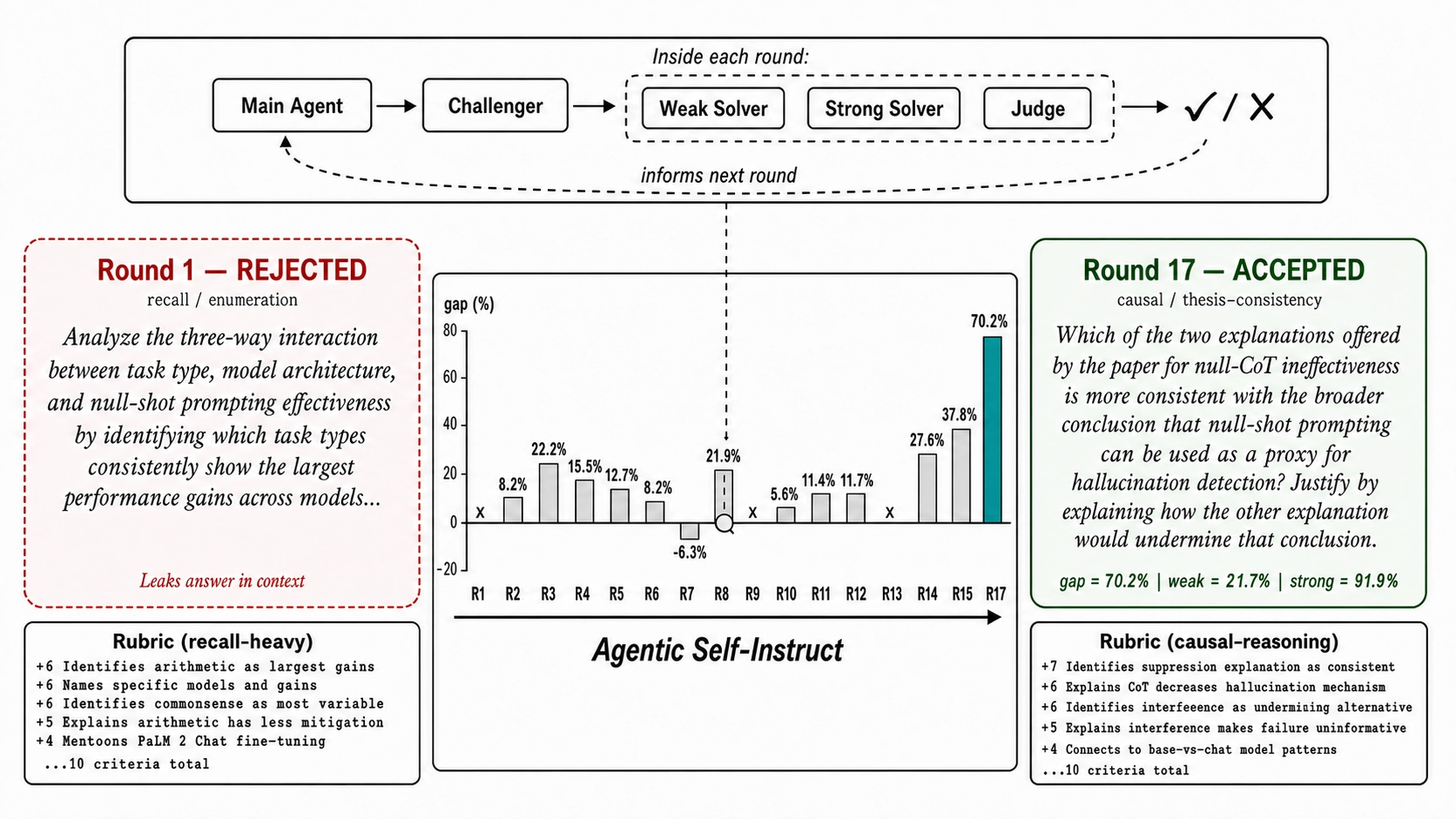
- A “judge” evaluates their answers using a rubric (a checklist with scoring rules), and the main agent decides whether the question is accepted or needs improvement.
Here is the lineup used in the loop:
- Challenger: proposes the question, the context, and a scoring rubric.
- Weak solver: tries to answer; ideally struggles somewhat.
- Strong solver: tries to answer; ideally does well.
- Judge: scores the answers, checks question quality, and gives feedback.
If the question is too easy (both solvers do well) or too hard (both fail), the agent revises the question to hit the “just right” zone where the strong solver succeeds but the weak solver struggles—this creates useful training data to help the weak solver improve.
They also “ground” questions on real documents (like actual legal cases or research papers). Grounding means the AI uses real sources, which reduces made-up facts and keeps questions specific and diverse.
Finally, they explore meta-optimization: training the data-creating agent itself. You can picture this as “teaching the coach to be a better coach.” The system analyzes where its data creation goes wrong (like giving away answers in the context or writing confusing rubrics), then updates the agent’s prompts and rules to fix those issues.
Technical terms in everyday language:
- Synthetic data: practice questions and examples made by AI rather than by humans.
- LLM: a powerful text-based AI that reads and writes.
- Chain-of-Thought (CoT): the model writes its step-by-step reasoning, like showing work in math.
- Reinforcement Learning (RL): a way to train models using “rewards” based on how well they perform; here, the judge scores are the rewards.
- GRPO: a specific RL training setup where the model generates multiple answers per question and learns from judged scores.
4) What did they find, and why does it matter?
They test Autodata on three areas—computer science research questions, legal reasoning, and scientific/mathematical problems—and consistently see better results than older synthetic data methods.
Key takeaways:
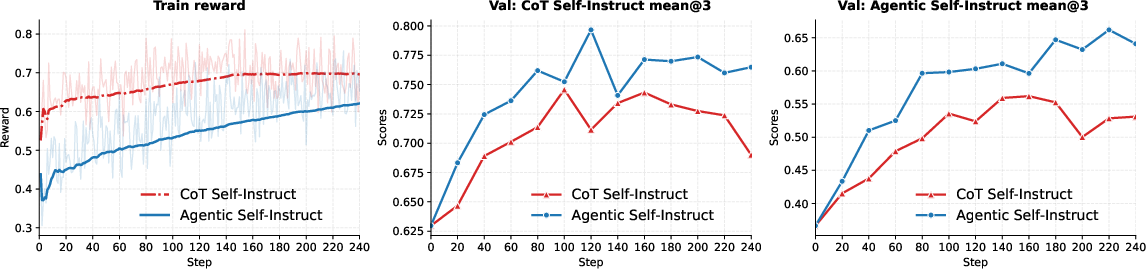
- Computer Science tasks: The agentic loop shifts questions from generic summaries to detailed, paper-specific reasoning (like algorithm steps or ablation details). Training on these improved questions makes the weak solver significantly better, and it beats the baseline training method throughout training.
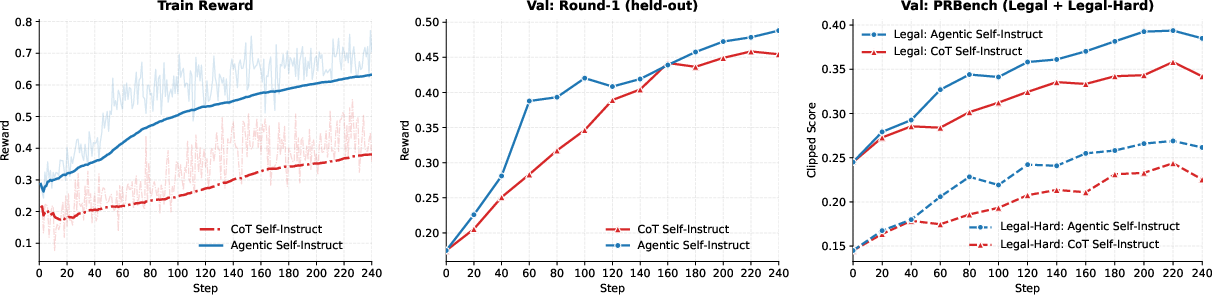
- Legal reasoning: The usual CoT approach made questions too hard (weak solver often scored near zero, which is bad for learning). The agentic loop adjusted difficulty to “just right”—it increased the weak solver’s score variability and made questions more learnable. After training on agentic data, a small model (4B) even outperformed a much larger model (397B) on PRBench Legal benchmarks.
- Scientific/mathematical reasoning: Training on agentic-generated, harder problems improved performance both in-distribution (on similar data) and out-of-distribution (on independent benchmarks like Principia). It showed better generalization, not just memorization. Training also reduced cases where the model’s reasoning got cut off by token limits (it became more “token-efficient” in its thinking).
Meta-optimization results:
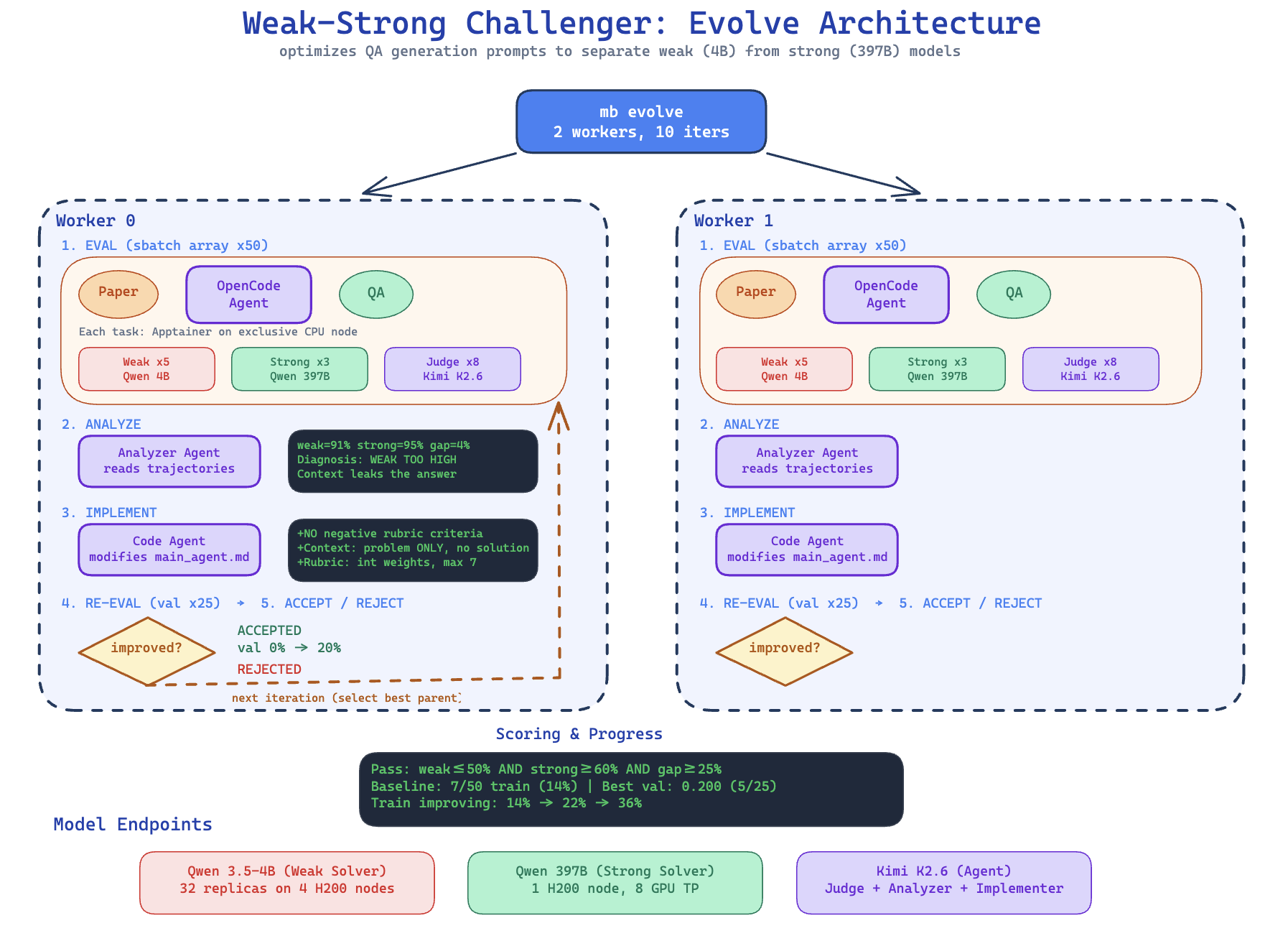
- When they “trained the coach,” the agent’s prompt and rules improved. For example, they enforced paper-specific questions, banned context leaks (not revealing the answer in the provided text), and fixed rubric format issues. This raised the agent’s success rate in producing useful questions (from roughly 62% to nearly 80% on validation), without manual tuning.
Why this matters:
- Stronger training data leads to stronger models.
- The agent can adapt question difficulty to the model’s current skill level—like a good coach.
- It shows that spending compute on smarter data creation can be more impactful than just collecting more data or only tuning model architecture.
5) What’s the big picture?
Autodata points to a future where AI systems help build the very training data that makes other AI systems better. Instead of relying heavily on human-written examples (which can be slow and expensive) or simple one-shot AI prompts (which may be too easy or too hard), agentic data creation:
- Iteratively improves question quality,
- Targets the “just right” difficulty for learning,
- Converts extra compute at inference time into better training signals,
- Scales to different domains (CS, law, math) and evaluation styles (rubrics, verifiable answers).
In short, Autodata shows a promising way to keep AI progress going: teach the models using smarter, tailored practice that they themselves help design—then teach the teacher to improve that process, too.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Judge dependence and circularity: The pipeline relies heavily on LLM-based judges (primarily Kimi-K2.6) for acceptance decisions, RL rewards, and evaluation. Quantify cross-judge robustness (e.g., Kimi vs multiple independent graders, including humans), assess susceptibility to reward hacking, and measure agreement rates and sensitivity to judge identity.
- Generalization across domains: Experiments cover CS research QA, legal reasoning, and math/science problems only. Test Autodata on additional domains (code with execution, multimodal tasks, safety- and policy-sensitive tasks, multilingual settings) to assess transferability.
- Verifiability gaps: For non-verifiable tasks, correctness rests on LLM-generated rubrics. Establish independent verifiability (e.g., tool-based checks, rule-executable rubrics, or human audits) and quantify rubric accuracy, coverage, and consistency across graders.
- Compute cost and scalability: The agentic loop requires multiple subagents, rollouts, and several rounds per accepted item (e.g., ~6.6 rounds in CS, ~5 in Legal). Provide a rigorous cost-benefit analysis (tokens per accepted item, energy/latency) and study scaling laws and optimal budget allocation across components (rounds, rollouts, judge invocations).
- Sensitivity to solver choices: Results use a specific weak/strong solver pair (Qwen3.5-4B vs Qwen3.5-397B-A17B). Systematically vary teacher models, modes (scaffolding, self-consistency), and sizes to evaluate stability, data quality, and transfer when teacher-student capabilities are closer or the same model is used in different modes.
- Acceptance criteria design: The CS setting uses hard thresholds on weak/strong scores and gap, while Legal uses a flexible judge. Study how different acceptance rules affect data usefulness (ablation of thresholds, dynamic vs fixed criteria) and identify principled difficulty-calibration methods that generalize across tasks.
- Robustness to grading noise: Solvers run with temperature and stochastic rollouts; acceptance decisions may be noisy. Quantify how rollout count, temperature, and majority-vote schemes affect acceptance reliability and downstream RL, and develop uncertainty-aware acceptance (e.g., confidence intervals, repeated grading).
- Guardrails and anti-gaming: The paper mentions guardrails but does not specify them. Design and evaluate anti-exploitation measures (e.g., adversarial audits, independence between judge and generator, leakage detection, perturbation tests) to prevent agents from optimizing toward judge-specific artifacts.
- Grounding and leakage measurement: Although context leakage checks are used, there is no systematic estimate of leakage/hallucination rates across datasets. Build automated leakage detectors, conduct human spot-checks, and report leakage prevalence and its impact on downstream performance.
- Data diversity and mode collapse: The iterative loop may bias toward question types that best separate weak/strong models, potentially narrowing topical diversity. Measure and enforce diversity (topic/skill coverage, novelty vs redundancy) and study its relation to generalization.
- Downstream evaluation breadth: CS experiments rely on in-house rubric-graded tests derived from the same process; there is no external, human-authored CS benchmark used. Add independent, human-curated evaluations to validate real-world utility.
- Human evaluation: Aside from PRBench’s judge-based scoring, no human rating of question quality, rubric adequacy, or solver responses is reported. Include human studies to validate correctness, difficulty, clarity, and fairness.
- Training objective comparisons: Only GRPO is used. Compare RL approaches (PPO, RLAIF/RLHF, DPO, KTO) and SFT (with or without preference/RM augmentation) on the same agentic data to understand which objectives exploit autodata most effectively.
- Tool-augmented verification: Math/science tasks could leverage symbolic solvers; code tasks could use execution; legal tasks could use retrieval/citation validators. Evaluate whether tool-based verifiers improve correctness and reduce judge bias compared to pure LLM judging.
- Difficulty calibration theory: The paper shows “too easy” vs “too hard” failure modes and heuristic fixes. Develop formal, task-agnostic metrics and controllers for “just-right” difficulty (e.g., target success bands, adaptive bandits) and test their stability across domains.
- Meta-optimization external validity: Meta-optimization of the agent’s prompts is only demonstrated on a small CS set (50 train/25 val papers) and evaluated on pass rate, not downstream RL. Validate across larger, heterogeneous tasks, measure downstream RL gains, and test for overfitting to validation tasks or judges.
- Outer-loop safety and stability: The code-editing agent can introduce brittle or unintended prompt changes. Study convergence, reproducibility, rollback strategies, and safety constraints (e.g., schema enforcement, diff linting, regression tests) to ensure stable evolution.
- Teacher bias imprinting: Data is optimized to separate a particular strong solver from a weak solver, risking teacher-specific biases. Evaluate cross-teacher generalization (train on data created with Teacher A, test with Teacher B) and develop teacher-agnostic acceptance criteria.
- Extractor quality in Legal: The legal pipeline depends on a document extractor agent; its accuracy and failure modes are not quantified. Evaluate extractor precision/recall and its impact on downstream data quality and RL outcomes.
- Capacity limits and model scaling: Scientific reasoning gains on OOD Principia are modest, with hints of 4B model capacity limits. Test with larger student models and report how student capacity interacts with autodata difficulty and dataset size.
- Alternative baselines under matched budgets: The paper compares against CoT Self-Instruct but not against other strong synthetic data strategies (e.g., instruction evolution, refinement, self-challenging) under the same compute budget. Provide head-to-head comparisons with compute accounting.
- Contamination checks: Ensure no overlap between autodata and evaluation sets (e.g., PRBench), and assess whether grounding sources leak into test distributions. Report contamination auditing procedures and results.
- Multi-turn and tool-use tasks: The current focus is single-turn QA/rubric grading. Extend to interactive tasks (planning, tool-use, debugging, multi-step research) and study how the agentic loop adapts acceptance and verification in these settings.
- Rollout and sampling policies: Only a few rollout counts (e.g., 3–5) are used; their impact on acceptance and RL is not ablated. Explore adaptive rollout budgeting and self-consistency strategies to trade off compute for reliability.
- Data and scaffold release: The paper does not state whether datasets, prompts, or agent scaffolds will be released. Public release is needed for reproducibility and third-party auditing of judge-dependence and leakage.
- Fairness and bias: No analysis of demographic, topical, or jurisdictional biases in generated data (especially in legal) is provided. Conduct bias audits and develop constraints/regularizers to mitigate biased or harmful generations.
- Formal quality metrics: “Data quality” is proxied by downstream scores and weak–strong gaps. Define and validate more general, task-agnostic quality metrics (e.g., correctness, novelty, verifiability, diversity) and analyze their predictive power for downstream gains.
- Stopping criteria and diminishing returns: Average rounds per accepted sample are reported, but not the marginal utility of additional rounds. Develop stopping rules that maximize performance-per-token and study round-level return curves.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that draw directly from the paper’s Autodata framework, Agentic Self-Instruct method, and meta-optimization results. Each item notes target sector(s), a concrete tool/workflow that could be stood up now, and key dependencies/assumptions that affect feasibility.
Software/AI and MLOps
- Synthetic curriculum builder for small/medium models
- What: Use a strong solver + judge to generate difficulty-calibrated training data (with rubrics) that systematically separates a “weak” target model from a stronger reference (weak-vs-strong loop).
- Sectors: Software/AI, ML platform providers
- Tools/workflows: “Autodata Trainer” service (Agentic Self-Instruct loop + GRPO or PPO reward), “Gap Controller” (acceptance criteria), “Weak-rollout variance monitor”
- Dependencies: Access to a strong LLM (teacher/judge), inference budget for multi-round loops, domain-grounded source documents, RL pipeline (e.g., GRPO), safeguards against reward hacking
- Continuous benchmark and regression-suite generation (“Autobench”)
- What: Automatically produce new, document-grounded evaluation items that remain challenging as models improve, with rubric-based, reproducible grading
- Sectors: Software/AI, Model evaluation vendors, Enterprise AI QA
- Tools/workflows: “Autobench Generator” (judge-calibrated difficulty), rubric standardization and JSON schema validator (to avoid parsing errors found in meta-optimization)
- Dependencies: Reliable judge model, curated grounding corpora, stable storage of evaluation provenance and rubrics, guardrails for context leakage
- Data quality copilot for RLHF/RLAIF pipelines
- What: Insert the agentic data scientist loop as a pre-RL data curator, improving reward signal quality (e.g., raising weak-rollout variance when too low; narrowing/ widening gaps as needed)
- Sectors: AI labs, LLM ops teams
- Tools/workflows: “Loop Judge” for GRPO-suitability tagging (high/medium/low), targeted challenger feedback templates, acceptance dashboards
- Dependencies: Reward-model availability (or rubric judging), telemetry to monitor weak/strong gaps and rollout variance, budget for multiple loop rounds
- Prompt-harness meta-optimizer for autonomous data generation
- What: Apply the paper’s outer-loop optimization to evolve data-scientist prompts and guardrails, raising validated pass-rates without manual prompt engineering
- Sectors: MLOps, AI tooling vendors
- Tools/workflows: “Harness Evolver” (code-diff prompt evolution, validation-gated acceptance), failure-mode analyzers (e.g., context-leak detector), population-based search
- Dependencies: Validation sets and pass/fail criteria, reproducibility tracking, concurrency-safe prompt versioning
Legal Tech and Compliance
- Document-grounded legal QA generation with rubrics (training + eval)
- What: Produce realistic, rubric-graded legal questions from public opinions/regulations that are “learnable” for target models (reshape weak-rollout distributions as shown in PRBench experiments)
- Sectors: Legal tech, In-house counsel tools, Compliance
- Tools/workflows: Extractor agents (facts/holdings synthesis), “Loop Judge” tuned for GRPO-suitability, PRBench-compatible graders
- Dependencies: Licensed/approved corpora (jurisdictional coverage), stringent context-leak checks, expert review for safety/policy alignment, record-keeping for auditability
- Continuous regulatory-change test suites
- What: Generate evolving test sets from updated statutes/guidance to validate enterprise legal assistants’ adherence to latest rules
- Sectors: Finance, Healthcare, Insurance, RegTech
- Tools/workflows: Nightly retrieval + agentic generation, risk-weighted rubrics, drift monitors
- Dependencies: Access to up-to-date legal sources, human legal review for high-stakes use, risk triage workflows
Education and EdTech
- Adaptive practice generator with rubric-based grading
- What: Personalized exercises calibrated to a student’s current ability (weak solver) with a strong solver guaranteeing correctness and a judge grading via rubrics
- Sectors: Education, Corporate L&D, Test prep
- Tools/workflows: “Difficulty Calibrator” (gap and variance targets), per-learner capability profiling, rubric-aligned feedback
- Dependencies: Pedagogical review of rubrics, safeguards against hallucinated facts, content licensing when grounded on textbooks/papers
- Automated exam/test-bank authoring from source texts
- What: Generate balanced, diverse question sets with verified rubrics from course materials/papers; enforce paper-specific insight tests and context leak prevention
- Sectors: Higher ed, MOOCs, Certification providers
- Tools/workflows: “Context Leak Guard,” structured JSON rubric schema, per-topic coverage analyzers
- Dependencies: Instructor approval workflows, alignment with syllabus/standards, bias/content quality checks
Scientific R&D and Knowledge Work
- Paper-comprehension QA and review aids
- What: Create paper-specific Q&A with rubrics to train/evaluate assistants that summarize, critique, or cross-check claims (shown effective for CS research tasks)
- Sectors: Academia, Industrial R&D, Publishing
- Tools/workflows: Agentic Self-Instruct over literature repositories, citation-verification checks, numeric/ablation detail targeting
- Dependencies: Access to full texts/metadata, IP/licensing, judge reliability for open-ended rubrics
- Advanced math/science problem generation for model training
- What: Generate harder, verifiable problems to improve reasoning beyond CoT-generated datasets (as with Principia-style tasks)
- Sectors: Scientific computing, EdTech (STEM), AI research
- Tools/workflows: Verifier modules (symbolic/math tools), pass@k analytics, truncation-rate monitors
- Dependencies: Strong solver competence in target domains, verifiability or robust rubric grading, enough inference budget for multi-round exploration
Enterprise Knowledge Management
- Internal, document-grounded QA dataset creation
- What: Build private, rubric-scored training/eval sets from enterprise docs to improve internal assistants’ accuracy and provenance
- Sectors: Any enterprise with large document stores
- Tools/workflows: Retrieval-grounded challenger prompts, redaction/PII filters, acceptance criteria tuned for business KPIs
- Dependencies: Data governance approvals, privacy/security constraints, storage of provenance and rubrics for audit
Safety, Red Teaming, and Policy
- Self-challenging adversarial evaluation suites
- What: Use the challenger + strong solver + judge to surface failure cases and calibrate their difficulty so they’re neither trivial nor impossible
- Sectors: Safety evaluation, Security, Policy compliance
- Tools/workflows: “Self-Challenge” harness, tool-augmented strong solvers, per-category coverage dashboards
- Dependencies: Governance for risky content, guardrails preventing prompt injection and reward hacking, periodic human review
Finance and Healthcare (low-risk scopes first)
- Policy/Guideline-grounded QA training and checks
- What: Generate rubrics and questions from financial regulations or clinical guidelines to train assistants on compliant summaries and procedures (non-diagnostic for healthcare)
- Sectors: Finance Ops, Healthcare Ops, Quality Assurance
- Tools/workflows: Domain-specific extractors, rubric standards aligned to SOPs, “accept/improve” loop judge for GRPO-suitability
- Dependencies: Regulatory and privacy constraints (HIPAA/GDPR), human-in-the-loop for high-stakes outputs, provenance tracking of sources
Daily Life
- Personalized study, interview prep, and skill practice
- What: Difficulty-calibrated practice questions with rubric-based feedback (coding katas, bar exam prep, case interviews)
- Sectors: Consumer apps, Career services
- Tools/workflows: “Practice Loop” app (weak/strong/ judge roles abstracted), session-level difficulty targets
- Dependencies: Access to a capable base model (cloud or local), content licensing for grounded materials, accuracy safeguards
Long-Term Applications
These opportunities extend the paper’s approach to new modalities, larger scales, regulated contexts, or self-improving ecosystems; they will likely need further research, scaling, or standardization.
Cross-Modal and Embodied AI
- Agentic synthetic data for robotics and multimodal models
- What: Generate curricula and evaluation tasks for perception/manipulation with verifiable success metrics (sim-to-real)
- Sectors: Robotics, Autonomous systems
- Tools/workflows: Simulator-integrated judge/verifier, tool-augmented strong solvers, sensor-grounded rubrics
- Dependencies: High-fidelity simulators, reliable verifiers beyond text-only LLMs, safety and real-world validation
Continuous, Self-Evolving Benchmarks and AutodataOps
- Organization-wide “AutodataOps” platforms
- What: Always-on pipelines that auto-generate, evaluate, and version high-quality training/eval data; meta-optimized data-scientist agents maintain targets as models evolve
- Sectors: AI-first enterprises, Model providers
- Tools/workflows: Population-based harness evolution, lineage/provenance registries, drift detection and automatic difficulty rebalancing
- Dependencies: Significant inference budgets, governance for synthetic data provenance, integration with CI/CD for ML
Regulatory-Grade Evaluation and Audit
- Standardized, regulator-accepted synthetic evaluation suites
- What: Benchmarks whose rubrics and provenance meet audit standards for compliance certification
- Sectors: Finance, Healthcare, Government
- Tools/workflows: Audit trails, data cards and rubrics with versioning, cross-grader validation (multiple judges)
- Dependencies: Policy buy-in, third-party certification processes, handling of bias/fairness/equity metrics
Scalable Safety and Oversight
- Dynamic safety curricula and scalable oversight
- What: Agentic generation of nuanced safety and misuse cases, with meta-optimized guardrails and reward models
- Sectors: AI safety, Trust & Safety
- Tools/workflows: Safety-specific loop judges, red-team marketplaces, continuous “oversight-as-data” services
- Dependencies: Stronger judges than today’s LLMs for safety domains, human governance, robust tool-use and sandboxing
Low-Resource and Multilingual Expansion
- High-quality synthetic corpora for underserved languages/domains
- What: Grounded, agentic data generation with bilingual judges/solvers to bootstrap alignment and reasoning
- Sectors: Global education, Public-interest AI
- Tools/workflows: Cross-lingual evaluators, cultural-context rubrics, domain-specific grounding
- Dependencies: High-quality bilingual source corpora, multilingual strong solvers, community review
Scientific Discovery Assistants
- From paper QA to hypothesis generation and experiment planning
- What: Extend the loop to propose, evaluate, and refine testable hypotheses and experimental protocols
- Sectors: Pharma, Materials, Basic science
- Tools/workflows: Integration with lab simulators/ELNs, verifiers tied to known constraints, uncertainty-aware judges
- Dependencies: Reliable domain tools beyond LLMs, safety/ethics oversight, reproducibility standards
Personalization at the Edge
- On-device tutors and copilots with continual, difficulty-calibrated data generation
- What: Local “weak” models that are continuously improved via small, on-device agentic loops
- Sectors: Consumer devices, Education
- Tools/workflows: Distilled strong solvers as teacher snapshots, efficient judges, compute-aware loop policies
- Dependencies: On-device acceleration, privacy-preserving evaluation, energy constraints
Market and Ecosystem Evolution
- Data-as-Compute services and judge/solver marketplaces
- What: Providers selling difficulty-calibrated data, judge APIs, and meta-optimized harnesses as commodities
- Sectors: Cloud AI, Data vendors
- Tools/workflows: SLAs around grading reliability, standardized rubric schemas, cost/performance dashboards
- Dependencies: Interoperability standards, transparent metrics, competition regulation
Notes on Common Assumptions/Dependencies Across Applications
- Access to a strong solver (teacher) and a reliable judge is pivotal; results depend on their capability and calibration.
- Inference budgets must cover multi-round agentic loops; cost control and variance reduction techniques are important.
- Grounding sources must be licensed and appropriate; privacy/PII and context-leak prevention are essential in regulated domains.
- Acceptance criteria (gap/variance thresholds, GRPO-suitability) should be tuned per domain; poor criteria can produce unhelpful data.
- Guardrails against reward hacking, prompt injection, and rubric mis-specification are necessary; structured rubric formats help.
- Human-in-the-loop review is advised in high-stakes domains (legal, medical, safety) until judges are demonstrably robust.
Glossary
- Acceptance criterion: The explicit rule used to decide whether a generated example is accepted by the agentic loop. Example: "We therefore define the acceptance criterion of the agentic loop directly in terms of this gap:"
- Agentic data creation: Using autonomous AI agents to iteratively generate, evaluate, and refine datasets. Example: "Autodata, via agentic data creation, provides a way to convert increased inference compute into higher quality model training"
- Agentic Self-Instruct: A specific Autodata implementation that orchestrates challenger, solver, and judge agents to synthesize targeted training data. Example: "which we call Agentic Self-Instruct, depicted in \autoref{fig:fig2}"
- Aggregation: Combining multiple model outputs (e.g., via voting or ensembling) to improve reliability. Example: "scaffolding or aggregation \citep{zhao2025majority}"
- Autodata: The proposed framework where an agent acts as a data scientist to create and improve training/evaluation data. Example: "We introduce Autodata, a general method that enables AI agents to act as data scientists who build high quality training and evaluation data."
- Autoresearch: A methodology for automatically exploring and optimizing research pipelines (here, for agent optimization). Example: "using autoresearch \citep{karpathy_autoresearch_2026}"
- Boltzmann sampling: A probabilistic selection method where choices are sampled with probability proportional to exponentiated scores. Example: "Select a parent from the population via Boltzmann sampling, where candidate is chosen with probability proportional to "
- Chain-of-Thought reasoning: Structured, step-by-step reasoning traces used during generation or solving. Example: "use Chain-of-Thought reasoning during the generation process"
- Challenger: A subagent that generates candidate tasks or examples given instructions from the main agent. Example: "Challenger, which creates training examples given a detailed prompt from the main agent,"
- Context leakage: When provided context inadvertently reveals answers or evaluation cues. Example: "A quality verifier then checks for context leakage, rubric coverage, and question quality"
- CoT Self-Instruct: A Self-Instruct variant that leverages Chain-of-Thought to synthesize more complex data. Example: "CoT Self-Instruct \citep{yu2025cot} extended that to use Chain-of-Thought reasoning"
- Gap (strong − weak): The performance difference between strong and weak solvers on the same tasks. Example: "Gap (strong weak)"
- GRPO: Group Relative Policy Optimization, a reinforcement learning algorithm used for fine-tuning LLMs. Example: "We train Qwen3.5-4B with GRPO"
- Grounded Self-Instruct: A method that grounds generation on external sources (e.g., documents) to reduce hallucinations. Example: "Grounded Self-Instruct \citep{lupidi2024source2synth,yuan2025naturalreasoning} extended that to ground on documents"
- Grounding: Anchoring generation to specific external data sources (papers, legal documents, etc.). Example: "The autodata agent grounds on some provided data"
- In-context learning: Teaching a model via examples and instructions included directly in the prompt. Example: "the ability to use in-context learning and instruction following"
- Inner loop: The iterative data creation and analysis cycle whose outcomes define the quality criteria. Example: "using the same inner loop criteria (creating better data) to guide the optimization of the outer loop"
- Loop judge: A decision-making component that accepts or rejects a round’s generation based on multi-factor analysis (e.g., variance, gap, quality). Example: "we instead adopt a more flexible {\em loop judge} to decide if a round's generation is accepted."
- Majority vote: An aggregation scheme where the final answer is determined by the most common output among multiple runs/agents. Example: "require that majority vote over the strong solver is correct, while majority vote over the weak solver is wrong."
- Meta-harness: A framework for meta-level optimization of agent scaffolds or prompts. Example: "meta-harness \citep{lee2026meta} style optimization"
- Meta-optimization: Optimizing the agent itself (its prompts/strategy) using metrics from the inner data-generation loop. Example: "we thus apply meta-optimization to the data scientist agent itself,"
- Outer loop: The meta-level process that tunes the agent’s strategy based on inner-loop performance. Example: "to guide the optimization of the outer loop (the agent optimization itself)."
- Out-of-distribution: Evaluation on data that differ from the training distribution to measure generalization. Example: "as well as the out-of-distribution Principia benchmark."
- Pass@8: The probability of obtaining at least one correct solution in 8 attempts (rollouts). Example: "pass@8"
- Pile of Law: A large corpus of public legal texts used as grounding data. Example: "Pile of Law~\citep{henderson2022pile}"
- PRBench-Legal: A benchmark split for evaluating legal reasoning performance. Example: "evaluate on PRBench-Legal and the PRBench-Legal-Hard subset"
- Reward model: A grader model that assigns rewards to outputs for reinforcement learning. Example: "using Kimi-K2.6 as the reward model to score responses against the generated rubrics."
- Rollout: Multiple sampled attempts by a model on the same prompt to assess performance/variance. Example: "Each candidate is rolled out by the weak solver 5 times and the strong solver 3 times."
- Rubric: Structured, often weighted, evaluation criteria used by a judge to score responses. Example: "the judge scores their answers against the rubric on a per-criterion basis."
- S2ORC: The Semantic Scholar Open Research Corpus, a large dataset of academic papers. Example: "We process over 10k CS papers from the S2ORC corpus (2022+)"
- Scaffolding: Procedures that structure or extend inference (e.g., tools, multi-step plans) to improve model performance. Example: "scaffolding or aggregation \citep{zhao2025majority}"
- Self-challenging: A paradigm where an agent proposes increasingly difficult tasks, often with tool use, to stress-test models. Example: "so called ``self-challenging'' methods \citep{zhou2025self}"
- Self-Instruct: A method where models bootstrap synthetic instruction data from seed prompts. Example: "Self-Instruct \citep{wang2023self} emerged as a method to create synthetic data"
- Strong solver: A higher-capability model (or mode) used to validate correctness and set difficulty. Example: "``Strong'' solver that is expected to generally succeed at the created training data,"
- Token budget: The maximum token limit available for reasoning/generation within a run. Example: "with a 65,536 token budget"
- Truncation rates: The proportion of outputs cut off due to exceeding the token limit. Example: "reduces reasoning truncation rates (from 23.75\% to 4.09\%)"
- Verifiable tasks: Tasks whose answers can be automatically checked for correctness. Example: "For verifiable tasks (using an LLM-based verifier)"
- Verifier: An agent that checks correctness/quality and provides feedback to guide data generation. Example: "Verifier/judge that given the example and a model solution, checks its quality,"
- Weak rollout standard deviation: The variability (standard deviation) of scores across multiple weak-solver attempts on a prompt. Example: "Weak rollout std"
- Weak solver: The target model to improve; tasks are tailored so it initially struggles. Example: "``Weak'' solver that is expected to generally struggle to solve the created training data;"
- Weighted grading rubric: A rubric whose criteria have weights to reflect their relative importance in scoring. Example: "a weighted grading rubric"
Collections
Sign up for free to add this paper to one or more collections.