Improving Neural Network Training by Decoupling the Magnitude and Direction of Weight Vectors
Abstract: Modern neural network training relies on optimizers such as Adam and Muon which act on each weight matrix as a single object. Yet every weight matrix carries two distinct quantities -- a \emph{magnitude} and a \emph{direction} -- and all optimizers stepping in the matrix as a whole couple their dynamics: the directional change from an update depends on the current magnitude, while the magnitude drifts as a byproduct of learning the direction, so neither is governed directly by the learning rate. Typical training therefore leans on surrounding recipes such as weight decay and warmup to keep learning stable at scale, though these regulate the coupling only indirectly; other recent methods instead constrain the weight to a fixed-norm sphere, but add no learnable magnitude, leaving scale control to normalization layers alone. We propose \emph{Magnitude--Direction (MD) Decoupling}, an optimizer modification that factorizes each weight into a fixed-norm direction on a hypersphere and learnable per-row and per-column magnitude gains, updated at separate learning rates, all while the model still sees a single fused weight tensor. The method is agnostic to the base optimizer and removes the need for weight decay and warmup. Across both Adam and Muon, MD Decoupling improves on well-tuned baselines, transfers the optimal LR across model width without retuning, and continues to help at scale on large Mixture-of-Experts (MoE) models. Treating magnitude and direction as separately controlled quantities thus yields more predictable training dynamics and a simple, broadly applicable improvement to modern optimizers.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a simple idea to train neural networks more smoothly and predictably. It says: instead of adjusting a whole weight matrix (a big table of numbers in a neural network) all at once, treat two parts separately:
- the direction the weights point, and
- how big those weights are (their magnitude).
By controlling these two parts independently, training becomes more stable and often better, without needing extra tricks like weight decay or warmup.
Key Questions
The authors ask:
- Why do current training methods mix up “how far” and “which way” weights move, and how does that cause problems?
- Can we separate magnitude and direction during training so the learning rate directly controls the rotation (direction change) while magnitude is learned cleanly?
- Does this help across different optimizers (like Adam and Muon) and for both small and large models, including Mixture-of-Experts (MoE) models?
Methods and Approach (Explained Simply)
Think of each weight matrix like lots of arrows:
- Each arrow has a direction (where it points) and a length (how long it is). In math, that’s “direction” and “magnitude.”
What goes wrong today:
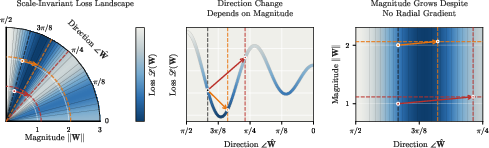
- Most optimizers update the whole arrow at once. The same step rotates small arrows a lot but big arrows only a little. That means the learning rate doesn’t consistently control “how much we turn.”
- Even when only direction matters (common if there’s a normalization layer after the weight), updates tend to accidentally make arrows longer over time. This can cause runaway growth unless you add fixes like weight decay and warmup.
The proposed fix: Magnitude–Direction (MD) Decoupling
- Keep directions on a “hypersphere.” That’s just a fancy term for “all arrows are kept at a fixed length” so only their direction changes.
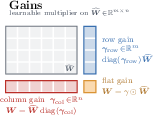
- Add learnable magnitude “gains” for rows and columns of the matrix. Imagine per-row and per-column volume knobs that make certain parts louder or quieter. These control the scale of outputs in a fine-grained way.
- Update direction and magnitude separately, each with its own learning rate:
- Direction updates are normalized and then projected back onto the sphere, so the relative change is set exactly by the learning rate.
- Magnitude gains are learned like regular parameters (often with Adam), giving the network the scale control it needs.
- The model still sees a single fused weight tensor, so there’s no architectural change—this logic lives inside the optimizer.
Small glossary to make terms clearer:
- Optimizer: the method that decides how to adjust weights to make the model better (e.g., Adam, Muon).
- Learning rate (LR): how big a step the optimizer takes each update.
- Weight decay: a rule that slowly shrinks weights to prevent them from growing too large.
- Warmup: starting with small learning rates to avoid unstable big steps early in training.
- Mixture-of-Experts (MoE): a model with many “experts” and a router that chooses a few experts for each input.
Main Findings and Why They Matter
Here are the key results, described in everyday terms:
- More stable, predictable updates:
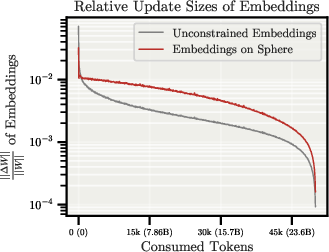
- On the sphere, the learning rate directly controls how much weights rotate. This removes the hidden coupling between direction and magnitude.
- Magnitude gains let the model naturally amplify or dampen specific rows/columns, which improves learning compared to only fixing norms.
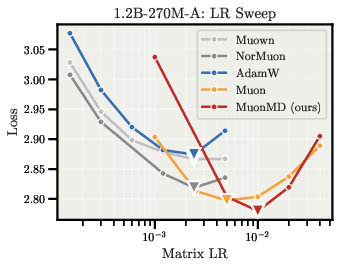
- Better performance across optimizers:
- MD Decoupling improves well-tuned baselines with both Adam and Muon.
- It reduces or removes the need for weight decay and warmup, simplifying training.
- Learning rate “transfer” without retuning:
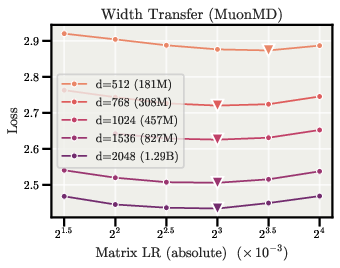
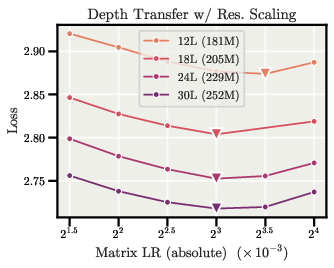
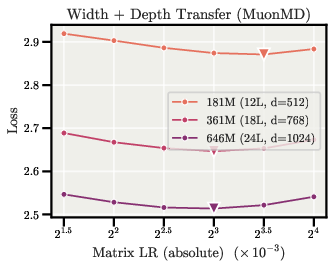
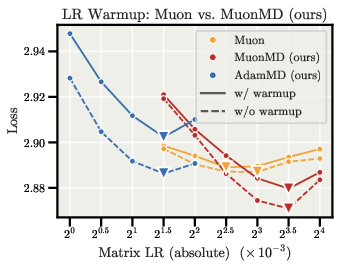
- With the sphere constraint, the optimal learning rate for direction stays almost the same when you make the model wider (more channels) or deeper (more layers). You can tune LR on a small model and reuse it on bigger ones.
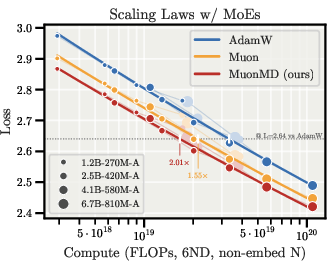
- Works at scale with MoE models:
- On large MoE models, the MD approach beats well-tuned AdamW and Muon.
- It reaches the AdamW loss with about 2× less compute, meaning it’s more efficient.
- Practical training improvements:
- Warmup-free training is stable and often better, since early steps aren’t wasted at reduced LR.
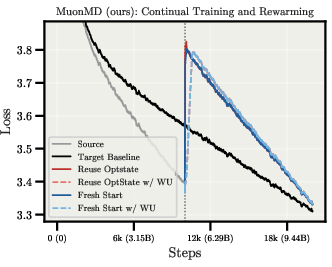
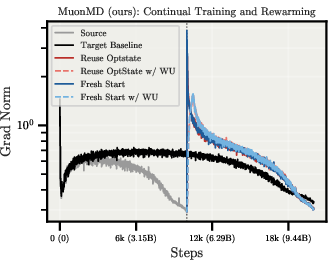
- Resuming training from checkpoints behaves well (loss and gradients stay stable).
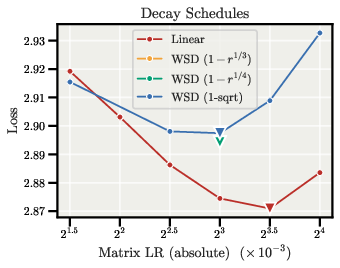
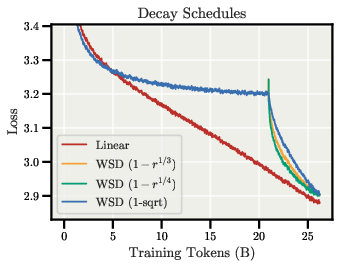
- The shape of the learning-rate schedule matters more on the sphere because the relative update follows the LR directly; smoother, gradual decay can be beneficial.
Implications and Impact
- Simpler recipes: You can drop weight decay and warmup in many cases, making training setups cleaner.
- Fewer retuning headaches: The same learning rate often works when scaling model width and depth, saving time and compute.
- Better efficiency at scale: For big models, especially MoEs, you can hit the same loss with less compute—useful for training LLMs cost-effectively.
- Broad applicability: The method is optimizer-agnostic, fits cleanly into existing pipelines, and keeps the model architecture unchanged, so it’s easy to try.
In short, treating “which way” and “how big” as separate, controllable parts during training makes neural networks learn more reliably. It’s a small change inside the optimizer that can yield big improvements across sizes and optimizers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what the paper leaves missing, uncertain, or unexplored, phrased to enable follow‑up work.
- Optimizer-agnosticism: Validate MD Decoupling beyond Adam/Muon (e.g., Shampoo, AdEMAMix, SOAP, LAMB, SGD without normalized updates), and characterize when non-normalized updates break LR transfer on the sphere.
- Learning-rate schedules on the sphere: Determine optimal on-sphere decay shapes (cosine, 1−sqrt, exponential, cyclical) and whether gains and directions should use different schedules or phases.
- LR transfer theory: Provide conditions under which width/depth LR transfer holds across base optimizers and architectures, and quantify deviations when update normalization differs (e.g., Muon scaling choices, Adam variance estimates).
- Training-length scaling: Derive and validate the exponent p in LR ∝ T−p for MD across datasets and sizes (the paper uses p≈0.25 heuristically; Complete(d)P uses 0.5), and clarify how this interacts with the spherical constraint.
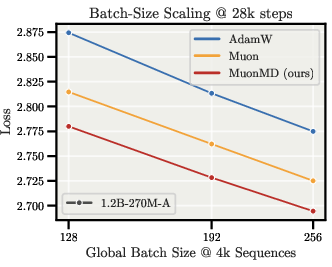
- Batch-size scaling: Establish principled LR–batch scaling under MD (e.g., sqrt(k) or alternative) using gradient-noise-scale analysis in the spherical setting.
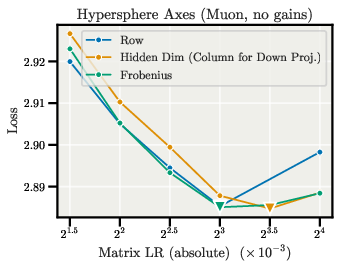
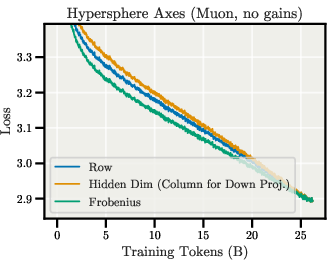
- Normalization axis selection: Identify regimes (architectures, layers, tasks) where row-, column-, or Frobenius-sphere constraints outperform others; extend beyond transformer MLP/attention to convs and structured matrices.
- Sphere radius choice: Move beyond “match initialization norm”—develop principled per-layer sphere radii (learned or scheduled), including adaptation over training and compatibility with different initializations (e.g., scaled output projections).
- Direction-update geometry: Assess benefits/limits of projecting gradients onto the tangent space (Riemannian step) vs. simple projection for larger models and diverse losses, especially where radial components might matter.
- Muon scaling factor: Provide a principled calibration of Muon’s update scaling (and its dependence on initialization and layer shapes) rather than fixed heuristics; automate robust per-layer calibration.
- Embedding/LM-head constraints: Quantify how per-token unit-norm constraints affect rare-token representations, tied embeddings, and downstream tasks; compare forward RMSNorm vs. optimizer-sphere enforcement.
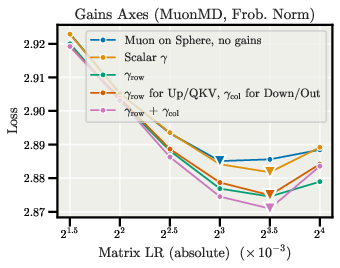
- Gains design (expressivity): Determine when higher-rank gain factorizations (rank>1) yield benefits (if any) at scale or in specific layers (e.g., attention Q/K vs. FFN), and characterize compute/overfitting trade-offs.
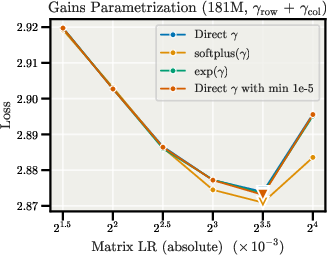
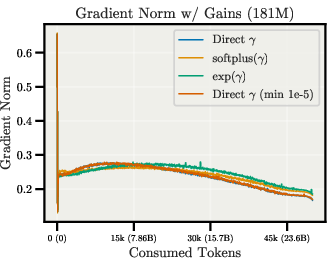
- Gains parameterization and LR: Systematically study gains’ parameterization (softplus/exp/unconstrained), positivity constraints near zero, and separate LR/schedule for gains vs. directions; assess effects on stability and generalization.
- Redundancy with normalization layers: Clarify when per-row/column gains are redundant with normalization-layer gains (e.g., RMSNorm scale) and whether MD should disable or regularize one set to avoid over-parameterization.
- Norm-free architectures: Test MD in settings without pervasive normalization (e.g., post-norm vs. pre-norm variants, or architectures explicitly lacking RMSNorm after blocks) and diagnose where scale invariance assumptions break.
- Router-specific choices in MoE: Explore the best normalization axis, scaling factors, and schedules for routers; analyze impact on load balance, routing entropy, and expert collapse across different routing schemes.
- Warmup boundaries: Identify conditions where warmup might still be needed (very large models, cold momentum, small batches) and provide diagnostics for safe warmup-free starts under MD.
- Extremely long training stability: Monitor gain dynamics over very long runs (norm drift, extreme gain values) and determine whether additional constraints (clipping, regularizers on gains) are required without weight decay.
- Generalization and loss landscape: Measure how MD affects sharpness/flatness, spectral properties (e.g., singular/spectral norms), calibration, and OOD robustness; link to generalization performance beyond pretraining loss.
- Downstream performance: Verify that loss improvements translate to benchmark gains (reasoning, multilingual, code, retrieval) and analyze which components (sphere, gains, schedules) contribute most downstream.
- Interaction with regularizers: Revisit weight decay’s role under MD (e.g., decay on gains only), and study interactions with dropout, label smoothing, Stochastic Depth, and other regularization techniques.
- Finetuning/PEFT compatibility: Determine how MD interacts with LoRA/QLoRA/adapters and whether to constrain base weights, adapters, or both; provide recipes for instruction tuning and SFT with MD.
- Modalities and architectures: Evaluate MD in CNNs, ViTs, diffusion/speech models, and RL; assess whether constraints/gains need modality-specific choices (e.g., conv kernel axes, multi-head attention sharing).
- Mixed precision and systems: Quantify throughput/latency and memory overheads from MD (splitting/reassembly, optimizer state) across hardware and distributed setups; test numerical stability in fp16/bfloat16.
- Hyperparameter interactions: Explore joint tuning of direction LR, gain LR, and schedule shapes; assess sensitivity and automated selection strategies (e.g., adaptive schedules tied to relative update statistics).
- Theoretical convergence: Develop formal analysis of MD dynamics for scale-invariant vs. non-invariant losses, including stationary points, convergence rates, and coupling between magnitude and direction under stochastic gradients.
- Pathological optimizer interactions: Identify cases where certain preconditioners or grafting techniques interact poorly with sphere projection or gain learning, and propose safeguards or diagnostics.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of Magnitude–Direction (MD) Decoupling that follow directly from the paper’s results. Each item lists sectors, what to build/do, and key assumptions or dependencies.
- Training cost and energy reduction for LLMs and MoEs — Sectors: software/AI infrastructure, energy, finance
- What to do: Wrap existing optimizers (Adam, Muon) with MD Decoupling to fix weight norms (Frobenius sphere) and add learnable per-row/per-column gains; remove weight decay and warmup. Apply the paper’s default recipe: Frobenius constraint for matrices, unit L2 rows for embeddings and LM head, softplus-parametrized gains, and separate LRs for direction vs. gains.
- Tools/products: md-optimizer wrappers for PyTorch/JAX; Hugging Face Trainer plugin; config templates to disable weight decay and warmup.
- Assumptions/dependencies: Base optimizer provides normalized updates (Adam/Muon as used in paper). Use residual downscaling (e.g., α = 1/L) for depth. Adopt paper’s Muon scaling factor and router row-normalization for MoE.
- Compute-efficient MoE training (up to ~2× less compute to match AdamW loss) — Sectors: software/AI infrastructure, energy, finance
- What to do: For DeepSeekMoE-style models, adopt MuonMD (Muon + MD Decoupling) with the paper’s router normalization (rows) and LR transfer rule; scale LR with training length by ≈ T−0.25 as in the paper.
- Tools/products: MoE training recipe cards; gating/router configs with on-sphere updates.
- Assumptions/dependencies: Results shown on 270M–810M active parameters; downstream task parity assumed via loss–performance correlation.
- Hyperparameter tuning compression via width-wise LR transfer — Sectors: software/AI infrastructure, academia
- What to do: Tune the matrix LR once on a small model; reuse it unchanged across widths (and with a simple rule across depth). Cut LR sweeps for scaled models.
- Tools/products: AutoML/HParam services that lock a matrix LR for families of widths; registries that store “width-stable” LRs.
- Assumptions/dependencies: Use the sphere constraint so that the relative update equals the LR; keep embedding/output LRs separate if still on Adam.
- Warmup-free training and safe resume/continual training — Sectors: software/AI infrastructure, healthcare, finance, government
- What to do: Remove warmup from pretraining, SFT, and staged training; resume from checkpoints without re-warmup. Monitor gradient norms and relative updates.
- Tools/products: Training pipelines without warmup blocks; “re-warming” tests; dashboards for angular/relative updates.
- Assumptions/dependencies: For extremely large models with Adam, a very short warmup might still help early momentum states.
- More stable magnitude control without weight decay — Sectors: software/AI infrastructure
- What to do: Replace weight decay with on-sphere direction updates and learned gains; reduce reliance on ad-hoc fixes (e.g., QK-clipping).
- Tools/products: Config simplifications; training checklists that remove decay and clipping unless needed.
- Assumptions/dependencies: Presence of normalization layers makes many losses scale-invariant; gains restore fine-grained scaling the sphere removes.
- Embedding stabilization via per-row unit-norm — Sectors: software/AI infrastructure
- What to do: Enforce unit L2 norm per token embedding vector (and per LM-head row). Optionally remove or simplify post-embedding RMSNorm.
- Tools/products: Embedding-normalization hooks in the optimizer; lightweight validators for embedding RMS and angular updates.
- Assumptions/dependencies: Follow the paper’s fused-weight implementation to avoid extra memory traffic.
- Training schedule modernization for on-sphere optimization — Sectors: software/AI infrastructure, academia
- What to do: Prefer gradual annealing (e.g., linear decay) over Warmup–Stable–Decay, since on-sphere relative updates mirror the nominal LR exactly. Start simple; monitor relative updates per layer.
- Tools/products: LR schedule components “for-sphere”; per-layer relative-update telemetry.
- Assumptions/dependencies: No weight decay; relative updates should match schedule by design.
- Reproducible baselines and pedagogy — Sectors: academia, education
- What to do: Use MD Decoupling to demonstrate magnitude–direction interference and angular updates in teaching labs; publish width-transferable LRs to aid replication.
- Tools/products: Notebooks showing toy scale-invariant losses, angular-change tracking, and LR transfer; baseline configs for 100–1B parameter models.
- Assumptions/dependencies: Same architecture choices as in the paper (RMSNorm, residual scaling) ease replication.
- ESG and procurement quick wins — Sectors: policy, enterprise IT
- What to do: Update internal training standards to include on-sphere optimizers and warmup removal to reduce energy per experiment; require reporting of relative-update telemetry in RFPs.
- Tools/products: Policy addenda for AI training; internal green-AI scorecards that credit on-sphere training and reduced tuning.
- Assumptions/dependencies: Organizations can adopt optimizer-level changes without vendor lock-in.
- Domain model fine-tuning on limited budgets — Sectors: healthcare, legal, education, SMBs
- What to do: Fine-tune or continually train domain-specific LLMs using MD Decoupling to reduce divergence risk and compute. Resume runs safely after pauses.
- Tools/products: Turnkey fine-tuning scripts with MD optimizers; cost calculators that estimate savings vs. AdamW+decay+warmup.
- Assumptions/dependencies: Pretraining loss improvements translate to target tasks; check with lightweight evals.
Long-Term Applications
These opportunities are plausible but need further validation, scaling, or productization beyond the paper’s experiments.
- RL and control policy training on spheres — Sectors: robotics, autonomy, gaming
- What to explore: Apply MD Decoupling to policy/value networks where update predictability matters; study interactions with nonstationary gradients and entropy regularization.
- Dependencies: Empirical validation in on-policy/off-policy RL; stability under high variance updates.
- Multi-modal and diffusion models — Sectors: media, healthcare imaging, industrial inspection
- What to explore: Extend MD Decoupling to vision backbones, VLMs, and diffusion U-Nets; check if angular-control improves scaling and reduces warmup-specific heuristics.
- Dependencies: Benchmarks on image/text/video tasks; adaptation of sphere/scale rules to convolutional and attention–conv blocks.
- Hardware and compiler fusion — Sectors: semiconductors, cloud
- What to explore: Fuse “update + project-to-sphere + reassemble” into accelerator kernels; Triton/XLA passes for in-optimizer factorization; memory-aware fused ops.
- Dependencies: Kernel engineering; verification that fused steps retain numerical stability and speed.
- Automated scaling rules across training length, batch size, and MoE granularity — Sectors: software/AI infrastructure
- What to explore: Move from the paper’s T−0.25 heuristic toward principled, theory-backed schedules for tokens, depth, width, and expert counts.
- Dependencies: Theory of rotational equilibrium on spheres; broad-scale ablations; integration with Complete(d)P-like recipes.
- Higher-rank and structured magnitude gains — Sectors: software/AI infrastructure, research
- What to explore: Learn rank-k gain matrices or structured gains (e.g., Kronecker factorizations) when rank-1 (row×column) isn’t enough.
- Dependencies: Evidence beyond initial null results; regularization to prevent overfitting/instability; memory–compute trade studies.
- Standardization and governance of optimizer telemetry — Sectors: policy, enterprise IT
- What to explore: Define metrics (relative update, angular change, gain dispersion) as required reporting for large training runs to reduce silent failures and improve comparability.
- Dependencies: Community consensus; integration in logging standards and training cards.
- On-device/private personalization — Sectors: mobile, healthcare, finance
- What to explore: Use warmup-free, predictable updates for brief on-device adaptation (privacy-preserving personalization) without instability spikes.
- Dependencies: Efficient mobile kernels; validation under intermittent power/thermal constraints.
- Safety and reliability tooling — Sectors: safety, compliance
- What to explore: Use sphere-constrained dynamics to detect out-of-family training behavior (e.g., runaway magnitudes) and to bound angular changes per step for risk controls.
- Dependencies: Thresholds correlated with undesirable behaviors; interfaces for halting/rolling back.
- Curriculum and education content — Sectors: education
- What to explore: Develop modules that teach geometry-aware optimization (spherical updates, angular LRs) and the difference between magnitude and direction learning.
- Dependencies: Stable open-source implementations and visualizations.
- Interoperability with advanced optimizers — Sectors: software/AI infrastructure
- What to explore: Combine MD Decoupling with Shampoo/SOAP or Riemannian optimizers; compare shape-aware preconditioners on-sphere vs. off-sphere.
- Dependencies: Benchmarks across scales; kernel support for mixed-precision preconditioning.
Cross-cutting assumptions and dependencies to watch
- Architectural context: Results are strongest for transformer-style models with normalization layers; embeddings and LM-head rows held at unit norm.
- Optimizer behavior: Base optimizer should produce normalized-like updates (Adam/Muon); Muon uses a scale factor that should match the target weight norm.
- Schedules: On-sphere relative updates mirror LR exactly; decay must be chosen deliberately; training-length scaling exponent (≈0.25 suggested) is not yet settled.
- Integration details: Use fused-weight implementation to avoid memory overhead; project back to the sphere each step; use softplus (or similar) for positive gains.
- External validation: The paper reports pretraining loss and scaling benefits; downstream-task confirmation is advisable before high-stakes deployment.
Glossary
- AdEMAMix: An optimizer family mixing Adam-like adaptive updates with EMA-style components to stabilize training. "the weight update can be treated as a black box, so it naturally fits different optimizers (AdEMAMix, Muon, Shampoo, \dots)."
- Adam: A widely used adaptive gradient optimizer that normalizes updates by running estimates of first and second moments. "Beyond Adam~\citep{kingma2014adam}, matrix-aware optimizers such as Shampoo~\citep{gupta2018shampoo}, SOAP~\citep{vyas2024soap}, and Muon~\citep{jordan2024muon} improve the update by accounting for the geometry of the weight space"
- AdamW: A variant of Adam with decoupled weight decay for better regularization and scale control. "reaching AdamW's loss with less compute"
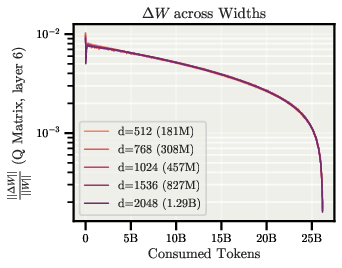
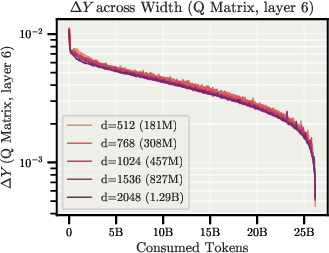
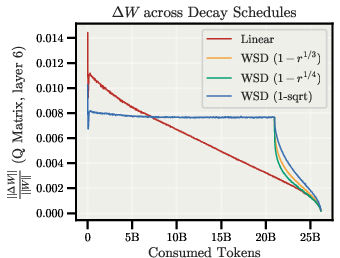
- Angular update: The change in direction (angle) of a weight tensor after an optimizer step, often approximated by the relative update size. "We can measure the directional change caused by an optimizer update through the angular update "
- Complete(d)P: A hyperparameter parameterization scheme for scaling learning rate and weight decay across model and data scales. "we follow the Complete(d)P~\citep{dey2025completep,mlodozeniec2025completed} parametrization to set the LR and weight decay for all parameter groups"
- DeepSeekMoE: A Mixture-of-Experts transformer architecture used to evaluate scaling behavior. "We use a DeepSeekMoE-style architecture~\citep{dai2024deepseekmoe}"
- Effective LR: A combined quantity (e.g., ) that governs dynamics under certain regimes like rotational equilibrium. "motivated by intuitions from rotational equilibrium~\citep{kosson2023rotational}, where the effective LR governs the dynamics."
- Frobenius norm: The square root of the sum of squared entries of a matrix, used to define matrix magnitude. "Throughout, unless otherwise noted, is the Frobenius norm"
- Frobenius sphere: The set of matrices constrained to a fixed Frobenius norm, used to control relative updates. "AdamH/MuonH~\citep{muonh2026} constrain the hidden weights of LLMs to a fixed Frobenius sphere"
- GQA: Grouped-Query Attention; a variant of attention that groups queries to reduce compute. "each with head-dimension 128, GQA~\citep{ainslie2023gqa}, QK-norm~\citep{dehghani2023scaling,wortsman2023small}, and Sandwich Norm~\citep{ding2021cogview,kim2025peri} with RMSNorm~\citep{zhang2019rmsnorm}."
- HyperP: A method extending fixed-norm training to transfer learning rates across multiple axes (width, depth, tokens, MoE granularity). "HyperP~\citep{ren2026rethinking} builds on top of this and investigates how to achieve LR transfer across width, depth, training tokens, and MoE granularity."
- Hypersphere: The manifold of vectors (or matrices) with fixed norm; used to constrain directions during training. "a fixed-norm direction on a hypersphere and learnable per-row and per-column magnitude gains"
- LionAR: A method emphasizing relative-update control that demonstrated LR transfer from a spherical/relative perspective. "the same effect was shown with LionAR in earlier work~\citep{kosson2025weight}"
- Mixture-of-Experts (MoE): A sparse model architecture that routes tokens to a subset of expert networks per layer. "large Mixture-of-Experts (MoE) models."
- Muon: A matrix-aware optimizer that preconditions updates using approximate second-order information and normalization. "Beyond Adam~\citep{kingma2014adam}, matrix-aware optimizers such as Shampoo~\citep{gupta2018shampoo}, SOAP~\citep{vyas2024soap}, and Muon~\citep{jordan2024muon}"
- MuonMD: The combination of Muon with Magnitude–Direction Decoupling, including normalization choices tailored to MoE routers. "For MuonMD we additionally normalize the routers along the expert axis (rows)"
- Newton--Schulz: An iterative method used to compute matrix inverse square roots, here referenced for orthogonalization quality. "assuming proper orthogonalization through Newton--Schulz"
- nGPT: A training approach that fixes weight norms on a sphere without weight decay and bundles architectural changes. "Our fixed-norm motivation is closely related to nGPT~\citep{loshchilov2024ngpt}"
- QK-clip: A stabilization trick that clips query–key interactions to prevent runaway growth. "warmup~\citep{goyal2017accurate,xiong2020layer} and fixes like QK-clip~\citep{kimiteam2025kimi} patch similar symptoms of runaway growth."
- QK-norm: A normalization technique applied to queries and keys in attention to stabilize training. "GQA~\citep{ainslie2023gqa}, QK-norm~\citep{dehghani2023scaling,wortsman2023small}, and Sandwich Norm"
- Relative weight update: The size of the parameter change relative to its magnitude, which directly controls angular update on the sphere. "The relative weight update is then determined by the LR at every step"
- Riemannian gradient: The gradient defined with respect to a manifold’s geometry, used when optimizing on spheres. "and supports it with Riemannian gradient theory."
- RMS grafting: A technique that matches the root-mean-square scale of an update to another update or target; used in Muon variants. "which we found to be noticeably better than the RMS grafting when sweeping"
- RMSNorm: Root-Mean-Square Layer Normalization that scales activations by their RMS without mean-centering. "with RMSNorm~\citep{zhang2019rmsnorm}"
- Rotational Equilibrium: A framework describing how weight norms and updates balance under decay and noise, explaining norm growth. "Prior work on Rotational Equilibrium~\citep{kosson2023rotational} showed how weight decay partially fixes this"
- Sandwich Norm: A normalization placement strategy that inserts normalization around sublayers to stabilize training. "Sandwich Norm~\citep{ding2021cogview,kim2025peri}"
- Scale-invariant: A property where scaling weights does not change the loss, making only direction matter. "the loss is scale-invariant: This means that only the direction of the weights affects the output, not the magnitude."
- Scaling laws: Empirical relations (often power laws) between performance and compute/model/data scale. "Scaling laws for sparse MoEs, where the improvement holds across a wide range of compute."
- Shampoo: A second-order preconditioning optimizer that uses matrix factorizations to adapt learning rates across dimensions. "Shampoo~\citep{gupta2018shampoo}"
- SOAP: A matrix-aware optimization method that accounts for weight-space geometry to improve updates. "SOAP~\citep{vyas2024soap}"
- Spectral norm: The largest singular value of a matrix, used to control or analyze stability and drift. "motivated by Muon's tendency to let the spectral norm drift upward"
- Top-2 routing: An MoE mechanism where each token is routed to the two most relevant experts. "with 64 experts (1 shared) and top-2 routing."
- Warmup: An initial phase of gradually increasing the learning rate to avoid instability at the start of training. "Like Muon, we no longer need warmup, since the large early updates it exists to prevent never appear."
- Warmup-Stable-Decay (WSD): A learning-rate schedule with phases of warmup, constant LR, and decay. "We compare the established recipe of a Warmup-Stable-Decay (WSD) schedule"
- Weight decay: A regularization technique that penalizes large weights, often implemented as decoupled L2 shrinkage. "standard optimizers struggle to learn the magnitude of weight matrices and lean on weight decay to keep learning the direction"
- Weight Normalization: A reparameterization that separates weight magnitude and direction to improve conditioning. "The factorization echoes classic Weight Normalization~\citep{salimans2016weight}"
Collections
Sign up for free to add this paper to one or more collections.

