- The paper introduces the concept of rotational equilibrium, where angular updates of weights stabilize effective learning rates.
- It employs theoretical analysis and random walk models to derive equilibrium dynamics across optimizers like AdamW and SGDM.
- Experimental validation on architectures such as ResNet-50 and GPT2-124M confirms that balanced rotation enhances training efficiency.
Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks
Introduction
The study titled "Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks" (2305.17212) investigates the influence weight decay has on the learning dynamics of deep neural networks. The concept of rotational equilibrium, where the angular updates of a neuron's weight vector converges to a stable state, is introduced. This equilibrium balances the average rotation, serving as a proxy for the effective learning rate across different layers and neurons. The paper extends the analysis to popular optimizers such as Adam, Lion, and SGD with momentum, offering a fresh perspective on training methodologies that elucidates the efficacy of commonly used but poorly understood practices.
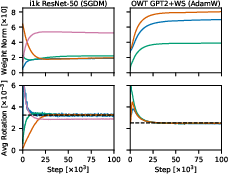
Figure 1: Measured weight norms and average rotation for different layers in ResNet-50 and GPT2-124M, showcasing predicted equilibrium rotation.
The paper demonstrates how balanced rotation enhances the effectiveness of normalization techniques like Weight Standardization and the performance of AdamW over Adam with ℓ2-regularization. Controlling the rotation offers the benefits of weight decay with reduced dependency on learning rate warmup.
Theoretical Analysis
Scale-Invariance and Effective Learning Rate
Scale-invariance is a critical concept affecting how weight decay operates in neural networks with normalization layers. The study leverages prior work showing that normalization layers can make weight vectors scale-invariant, meaning the output remains unaffected by the magnitude of the weight. This insight leads to the notion of an "effective learning rate," which refers to the rotational updates of scale-invariant weights, a key factor in optimizing deep networks.
Equilibrium Dynamics
At the heart of the paper is the analysis of rotational equilibrium. By investigating a simplified setting where updates are dominated by noise, a random walk model is used to derive expressions for equilibrium magnitude and expected angular update size. The authors find that the equilibrium states are characterized by homogeneous rotations across layers and neurons. This convergence reflects a balance between gradient updates (which tend to increase weight norms) and weight decay (which reduces them).
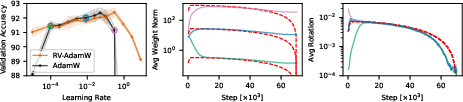
Figure 2: Validation accuracy for ResNet-20 on CIFAR-10 when varying learning rate and weight decay, illustrating the transient behavior.
The paper further analyzes optimizers like AdamW, Adam+ℓ2, SGDM, and Lion, each revealing distinct equilibrium dynamics that contribute to their unique learning characteristics. For scale-sensitive weights, a radial gradient component modifies the effective weight decay, influencing the equilibrium behavior.
Experimental Validation
The authors validate their theoretical claims through extensive experimentation across various neural architectures and tasks. Using standard datasets like CIFAR-10 and ImageNet, they demonstrate that practical neural network optimization aligns closely with their predictions. For scale-invariant layers, the equilibrium angular updates converge as expected, whereas for scale-sensitive layers, these predictions deviate due to the radial gradient components.
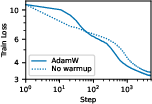
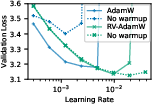
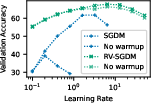
Figure 3: Comparison of loss curves with and without learning rate warmup for GPT2-124M and ResNet-50 configurations.
Further experiments show that rotational optimizer variants (RVs), which explicitly control angular updates, can replicate the benefits of weight decay, simplifying the update dynamics by removing the transient phase. In tasks where neurons rotate imbalancedly, performance degradation is evident, reinforcing the importance of balanced rotation.
Conclusion
The study offers significant insights into the interactions between weight decay and neural update dynamics. It provides a theoretical underpinning for widely adopted deep learning techniques, enhancing our understanding of how these methods achieve their effectiveness. The findings not only demystify current practices but present potential avenues for improvement and innovation in neural network optimization.
In summary, this paper contributes to the foundational understanding of weight decay, proposing balanced rotational dynamics as a crucial aspect of efficient neural network training. Future work may focus on further refining these concepts to develop more robust and adaptive training algorithms.