Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
Abstract: Normalization layers in modern LLMs consist of a deterministic normalization operation and a learnable scale vector. While the normalization operation has been extensively studied, the scale vector remains poorly understood despite its ubiquitous use. In this work, we present a systematic study of scale vectors in LLMs from the perspectives of expressivity, optimization, and architectural structure. First, we show empirically that although scale vectors constitute only a negligible fraction of model parameters, removing them substantially degrades LLM pre-training. Our theory further shows that, in Pre-Norm architectures, scale vectors do not increase expressivity; instead, they improve optimization through a self-amplifying preconditioning effect on subsequent linear mappings. Second, we investigate the role of weight decay for scale vectors. By distinguishing Input-Norm and Output-Norm layers, we theoretically show that weight decay is beneficial for the former but harmful for the latter, due to their distinct roles in optimization and expressivity. Third, motivated by this understanding, we propose three lightweight and complementary improvements to scale vectors: branch-specific heterogeneity, improved placement around linear mappings, and magnitude-direction reparameterization. Both theory and experiments show that each improvement yields consistent gains. Finally, we combine these improvements into a unified scale-vector strategy and evaluate it through extensive LLM pre-training experiments on dense and mixture-of-experts models ranging from 0.12B to 2B parameters, across multiple optimizers and learning rate schedules, under industrial-scale token budgets. The unified strategy consistently achieves lower terminal loss than well-tuned baselines and exhibits more favorable scaling behavior, while adding negligible parameter and computational overhead.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a tiny part of LLMs called “scale vectors.” These live inside normalization layers (like RMSNorm) and act like small, per-channel volume knobs that rescale signals. Even though they take up almost no space in the model, the authors show they have a big impact on how well and how fast LLMs learn. They explain why that is, when to regularize (shrink) them, and how to redesign them to make training better and more stable.
The main questions the paper asks
- Do scale vectors actually matter during training, even though they’re tiny and don’t add new “expressive power” to the model’s math?
- Should we apply “weight decay” (a common technique that slowly shrinks parameters to keep training stable) to these scale vectors?
- Can we rearrange or reparameterize (re-express) scale vectors to make learning faster and more reliable?
How the authors studied the problem (in everyday terms)
The authors used two approaches:
- Careful experiments: They trained many LLMs (from about 120 million to 2 billion parameters), both “dense” models and Mixture-of-Experts (MoE) models, using different optimizers (like AdamW and Muon) and learning rate schedules. They tried removing scale vectors, changing where they are placed, and adjusting how they are learned.
- Simple theory with clear analogies:
- “Expressivity” means what functions the model can represent (like the range of songs a piano can play).
- “Optimization” means how easily and quickly the model learns (like how smooth the keys feel when you play).
- They show that in common “Pre-Norm” designs (where you normalize just before a linear layer), scale vectors don’t let the model represent new functions—you could absorb their effect into the next linear weights. But they still matter a lot for optimization: they act like smart, automatic gear-shifters that make the learning steps more effective, a process the authors call “self-amplifying preconditioning.”
To make technical ideas accessible:
- Normalization is like resetting volume so signals don’t get too loud or too quiet.
- Scale vectors are per-channel volume knobs.
- Preconditioning is like smoothing a bumpy road so each step moves you forward more efficiently.
- Weight decay is a gentle pull toward smaller values to avoid instability.
What they found (and why it matters)
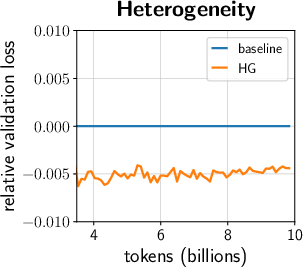
- Scale vectors are tiny but important
- Removing them made training worse: higher final loss and slower progress. Even when they tuned learning rates, models without scale vectors still performed worse.
- Why? In Pre-Norm models, scale vectors don’t add expressivity but they speed learning by “preconditioning” the next layer in a way that reinforces itself. Think of them as adaptive gear settings that make gradients (learning signals) more effective.
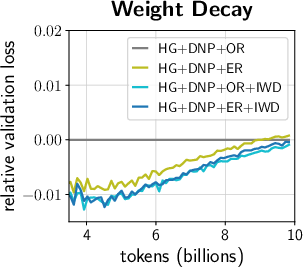
- Weight decay rules depend on where the scale vector sits
The paper distinguishes two places where norm+scale can appear:
- Input-Norm: scale vectors are right before a linear map (the common Pre-Norm setup).
- Output-Norm: scale vectors are applied to a module’s output (like Q/K-Norm or output norms in attention/FFN).
Findings: - For Input-Norm scale vectors, weight decay helps. It keeps the parameter balance healthy, prevents “over-sharpness” (wildly sensitive directions), and makes training faster and more stable. - For Output-Norm scale vectors, weight decay hurts. These scales directly control what the module can express at the output. Shrinking them weakens the module in a way that can limit the model’s abilities.
Simple rule of thumb: - Apply weight decay to Input-Norm scale vectors. - Do not apply weight decay to Output-Norm scale vectors.
- Three simple upgrades that make scale vectors work even better
The authors propose lightweight changes that add almost no extra cost but improve training:
- Branch-specific knobs (heterogeneity): Instead of sharing one scale vector for several branches (like Query, Key, Value in attention, or gate/up in FFN), give each branch its own. Different branches learn differently, so dedicated knobs help each learn faster.
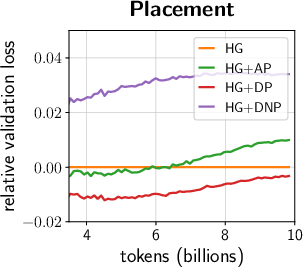
- Better placement around linear layers:
- After-placement (AP): put a scale vector after a linear map, not just before.
- Dual-placement (DP): put them both before and after to control input and output sides.
- Dual normalized placement (DNP): like DP, but insert a normalization in between for extra stability. These layouts give the model more ways to “shape” signals where it matters, speeding learning.
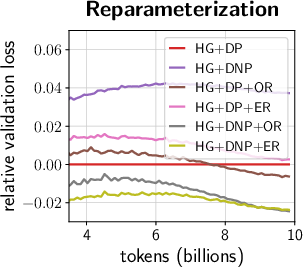
- Magnitude-direction reparameterization:
- Split a scale vector into two parts: one number for overall magnitude (how loud) and a unit vector for direction (how the loudness is distributed across channels).
- This separation makes optimization “anisotropic” in a good way: the model can quickly adjust overall scale (the magnitude) without messing up the fine detail (the direction). The paper tries two versions: one in normal space (OR) and one in log/exponential space (ER). Both help, with OR often slightly ahead.
- A unified view: scale vectors as smart preconditioners
All these ideas can be seen as ways to reparameterize the effective linear layers so that the learning steps are better shaped. This is different and complementary to adaptive optimizers like Adam:
- Optimizers adapt using past gradient statistics.
- These scale-vector designs adapt the coordinate system of the parameters themselves, based on the current model state. Using both together gives extra gains.
- Big-picture experimental results
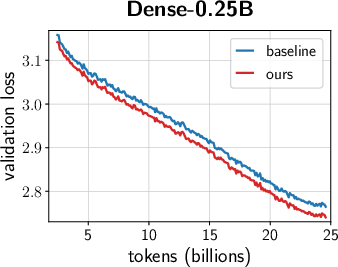
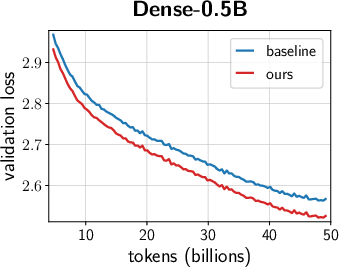
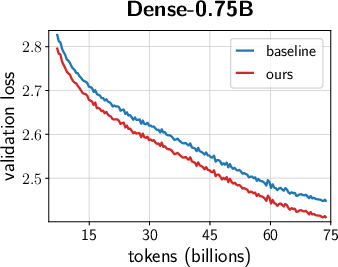
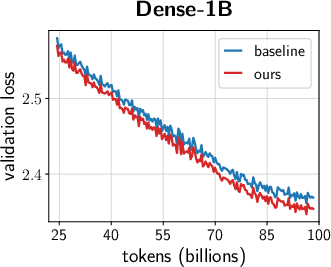
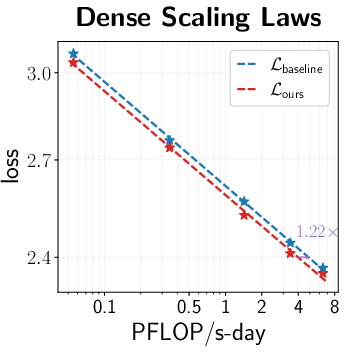
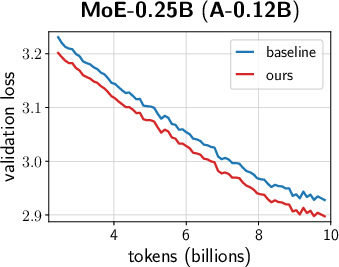
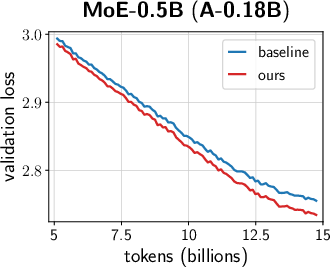
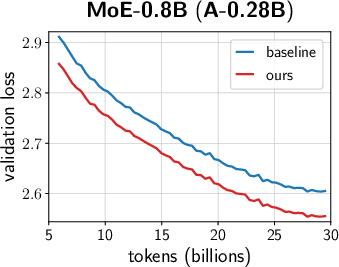
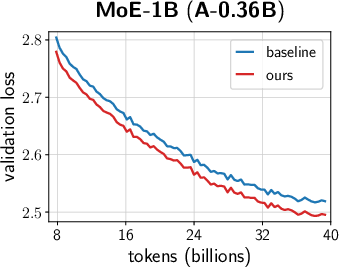
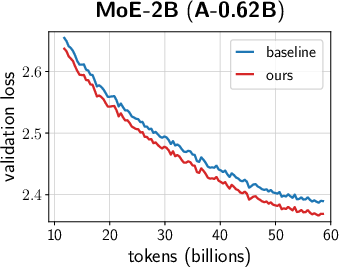
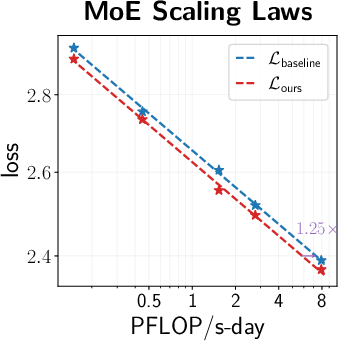
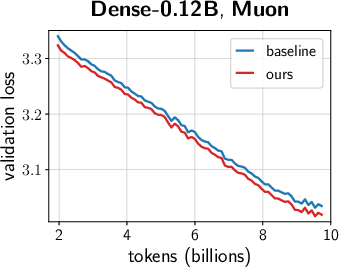
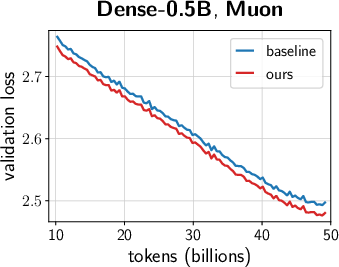
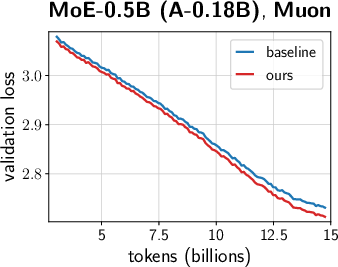
- Across many settings (0.12B–2B parameters, dense and MoE models, AdamW and Muon, different schedules), the combined “unified scale-vector strategy” consistently reduced training loss and showed better scaling behavior than well-tuned baselines.
- The improvements showed up early and kept growing over time, with negligible extra parameters or compute.
Why this is important
- Practical guidance for building better LLMs:
- Keep scale vectors—don’t dismiss them just because they’re small.
- Apply weight decay to Input-Norm scale vectors but not to Output-Norm ones.
- Use branch-specific scale vectors where branches behave differently (like Q/K/V).
- Consider two-sided placement with normalization (DNP) for stronger, stable control.
- Reparameterize scale vectors into magnitude and direction for faster, steadier learning.
- Faster, more stable training at almost no extra cost:
- These tweaks help models learn more efficiently and can make large-scale training smoother.
- General insight:
- Sometimes tiny components (like scale vectors) can have outsized effects by improving the “geometry” of learning, even if they don’t expand what the model can represent.
In short, this paper shows that the “little knobs” in normalization layers are not just decoration—they are powerful tools for speeding up and stabilizing LLM training, and clever designs around them can make a real difference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions left unresolved by the paper that can guide future research:
- Limits of theory-to-practice transfer:
- Theoretical analyses rely on simplified linear teachers, Gaussian inputs, and continuous-time gradient flow/SDEs; it remains unclear how the self-amplifying preconditioning effect, DP/OR acceleration, and the weight-decay arguments behave under realistic Transformer dynamics with nonlinearity (softmax attention, gating, activations), discrete-time updates, momentum, and adaptive optimizers (e.g., AdamW’s decoupled weight decay).
- Scope of architectural generality:
- Expressivity “redundancy” of Pre-Norm scale vectors is argued in linear settings; whether this claim holds when scaling interacts with softmax attention (e.g., implicit temperature changes) or other nonlinearities is not formally established.
- The study is restricted to Pre-Norm Transformers with RMSNorm; it remains open how results extend to Post-Norm, NormFormer/DeepNorm/µParam-style variants, or other sequence models (RetNet, RWKV, Mamba) and modalities (ViT, diffusion models, speech).
- Scale and regime limitations:
- Experiments cover 0.12B–2B models; whether gains persist, grow, or saturate in larger LLMs (e.g., 7B–70B+) and ultra-long-context settings is unknown.
- Token budgets and batch sizes are described as “industrial-scale” but only up to 2B parameters; the scaling law extrapolation to very large models is not validated.
- Downstream impacts beyond loss:
- The work optimizes pre-training loss; effects on downstream tasks (zero-/few-shot, instruction tuning, RLHF), calibration, long-context behavior, and safety/robustness are not evaluated.
- Whether lower pre-training loss translates into consistent gains on real-world benchmarks (e.g., MMLU, GSM8K, code) remains untested.
- Interaction with attention mechanics:
- DNP on Q/K is said to recover Q/K-Norm, but the broader effect of AP/DP/DNP on attention logit scales, softmax temperature, head competition, and training stability is not theoretically analyzed.
- Potential impacts on attention sparsity patterns, head specialization, or attention entropy are unmeasured.
- Weight decay policy (IWD) generality and boundaries:
- The Input-/Output-Norm distinction is clear for Gemma-like designs but may be ambiguous in other architectures with interleaved norms or nonstandard placements; guidelines for edge cases are missing.
- Theoretical support for IWD is given for SGD; whether the same conclusions hold with AdamW’s decoupled weight decay, Lion, Adafactor, Sophia, Shampoo/K-FAC, or Muon is not established theoretically (only partial empirical tests).
- Sensitivity to weight-decay strengths for scale vectors (and to schedules) is not mapped; principled defaults or tuning heuristics are not provided.
- Reparameterization stability and best practices:
- OR/ER separate magnitude and direction but can alter optimization geometry significantly; numerical stability (e.g., with bf16/fp8), initialization sensitivity (β, direction), and failure modes (e.g., runaway magnitude) are not systematically studied.
- ER enforces positive entries via exponentials; while signs may be “absorbed by W,” the practical interplay with weight-tying, quantization, and certain regularizers is unexamined.
- Heterogeneity granularity:
- The paper introduces branch-specific scale vectors (Q/K/V and gate/up) but does not explore finer granularity (e.g., per-head, per-expert, per-layer) or the trade-off between gains and parameter/overfitting risks.
- In MoE, interactions with expert routing and load balancing (e.g., whether scale-vector changes bias gating or expert utilization) remain uninvestigated.
- Placement design space and conditions:
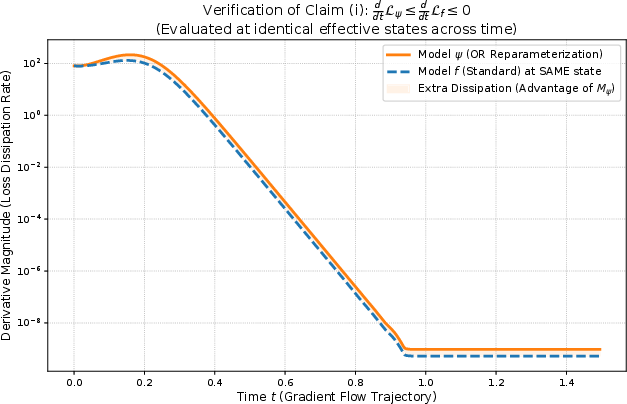
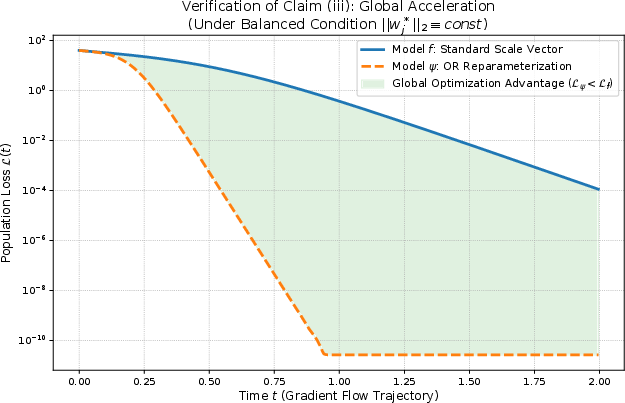
- DP shows “instantaneous” acceleration at matched effective states under GF, but practical conditions under which AP, DP, or DNP is preferable are not characterized; DNP sometimes underperforms DP in experiments without a principled criterion for when to use which.
- The incremental compute/memory and throughput impacts of AP/DP/DNP (extra norms and elementwise ops) are not quantified, despite claims of negligible overhead.
- Preconditioning–optimizer interactions:
- The reparameterization-induced preconditioner (state-dependent) and optimizer-induced preconditioner (history-dependent) may interact constructively or destructively; a formal analysis of the combined geometry and potential conflicts (e.g., over-preconditioning along certain directions) is absent.
- No theoretical or systematic empirical study of how these methods interact with different adaptive optimizers, momentum settings, or gradient clipping norms.
- Sharpness claims not empirically validated:
- The benefit of weight decay on Input-Norm scale vectors is argued via bounded sharpness metrics, but no empirical measurements of Hessian spectral norm/trace or noise–sharpness couplings are reported.
- Generalization across data distributions:
- Experiments are conducted on a single high-quality corpus; robustness across diverse domains (code, math, low-resource languages, noisy web), tokenizers, and curriculum schedules remains unknown.
- Effects on representational geometry:
- OR/ER and DP/DNP change channel-wise scaling and could alter anisotropy/isotropy of representations; impacts on representation collapse, feature diversity, and internal covariance shift are not studied.
- Interaction with other training tricks:
- Compatibility with techniques like scaled init (µParam), DeepNorm, T-Fixup, normformer-style post-attention norms, sandwich norms, residual rescaling, or logit scaling is not tested.
- Interplay with regularizers beyond weight decay (e.g., norm penalties on scales, orthogonality constraints, spectral norm control) is unexplored.
- Precision, quantization, and deployment:
- Impact of new placements and parameterizations on low-precision training/inference (bf16/fp8), post-training quantization, and calibration is unmeasured.
- Whether altered scaling dynamics affect KV-cache behavior, latency, or memory pressure in long-context inference is not discussed.
- Robustness and reproducibility:
- Variance across random seeds and sensitivity to hyperparameters (learning rate, warmup, clipping threshold) are not reported; statistical significance of improvements is unclear.
- Public code, exact configs, and reproducibility artifacts are not provided within the paper text.
- Fine-tuning stage behavior:
- Whether the IWD policy and the proposed scale-vector designs remain beneficial (or need to be adapted) during SFT, PEFT/LoRA, RLHF, or domain adaptation is unknown.
- Failure cases and trade-offs:
- Conditions where the proposed strategies hurt (e.g., small models, extremely large batch sizes, very high learning rates, or aggressive gradient noise) are not identified.
- Potential over-regularization when misclassifying a layer as Input- vs Output-Norm under IWD is not analyzed.
- Theoretical extensions:
- The invariance γ2 − ||w||2 = 1 under GF is used in arguments; whether analogous invariants or approximate conservation laws exist under AdamW/Muon with finite step sizes is not explored.
- Formal results that incorporate nonlinearities (activation/softmax), residual connections, and multi-branch coupling (Q/K/V interactions) are missing.
- Broader applicability:
- Whether similar conclusions hold for LN/BN scale vectors (beyond RMSNorm) and in computer vision or speech tasks is suggested but not demonstrated.
These gaps suggest concrete next steps: expand theory to nonlinear and adaptive-optimizer settings, quantify compute/latency trade-offs, probe larger scales and diverse tasks/data, measure sharpness and representation geometry empirically, develop principled guidance for placement and IWD in new architectures, and assess stability/robustness across training regimes and precisions.
Practical Applications
Immediate Applications
The paper’s results can be operationalized today with minimal code changes and negligible parameter/FLOP overhead. Below are concrete uses, organized by sector and including dependencies and assumptions.
- LLM pretraining efficiency upgrades (Industry: software/AI; Academia)
- What to do:
- Adopt Individual Weight Decay (IWD): apply weight decay to Input-Norm scale vectors (e.g., Pre-Norm RMSNorm before linear layers), and avoid weight decay on Output-Norm scale vectors (e.g., Q/K-Norm and final Output-Norm).
- Introduce branch-specific scale vectors (heterogeneity) for Q, K, V and FFN gate/up to tailor self-amplifying preconditioning per branch.
- Adjust placement: use Dual Normalized Placement (DNP) around linear maps (input- and output-side scale vectors with a normalization in between; for Q/K this is equivalent to adding Q/K-Norm).
- Reparameterize scale vectors via magnitude-direction (OR variant): parameterize a scale vector as β·norm(γ), optimizing β (magnitude) and normalized direction separately.
- Expected impact:
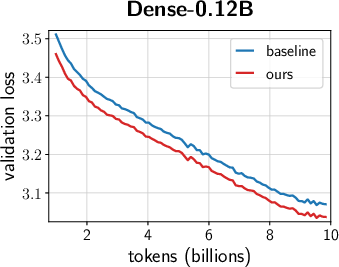
- Faster convergence and lower terminal loss (reported ~0.02–0.03 loss reduction at up to 2B parameters; ~1.4× token-efficiency gains in ablations with negligible parameter overhead).
- More favorable scaling curves and stability across optimizers (AdamW, Muon) and LR schedules.
- Tools/workflows:
- Integrate into existing training stacks (PyTorch + DeepSpeed/Megatron-LM/Accelerate). Provide a “scale-vector strategy” module to:
- Clone γ per branch for Q/K/V and FFN up/gate.
- Add per-branch after-norm (DNP), ensuring head-wise normalization for attention.
- Implement OR reparameterization (β as a scalar or small group vector; enforce unit direction via per-step normalization).
- Configure optimizer parameter groups to enforce IWD (distinct weight decay for Input-Norm vs Output-Norm scale vectors).
- Assumptions/dependencies:
- Pre-Norm Transformer with RMSNorm (common in LLMs). Mechanisms likely extend to LN/BN-based models but may need tuning.
- Verified up to 2B parameters; likely but not yet empirically confirmed at larger scales (e.g., ≥7B).
- DNP adds normalization ops; ensure numerical stability and minimal kernel overhead; use fused kernels if available.
- Parameter-efficient finetuning knob via scale vectors (Industry: software/AI; Academia; Daily life via downstream model availability)
- What to do:
- Finetune only scale vectors (γ) and possibly β (for OR) while freezing main weights to adapt to new domains or tasks.
- Expected impact:
- Extremely low-parameter adaptation path (~O(d) per norm) with measurable functional effect (though scale vectors do not add architectural expressivity, adjusting them with frozen W changes the function).
- Useful for quick personalization or domain calibration with small memory footprint.
- Tools/workflows:
- Add γ-only finetuning recipes alongside LoRA/IA3/Adapters in Hugging Face Transformers and similar frameworks.
- Assumptions/dependencies:
- Effects are task-dependent; may need small learning rates and IWD for stability.
- For Output-Norm γ, avoid weight decay to preserve capacity.
- Training stability and hyperparameter tuning guidance (Industry/Academia)
- What to do:
- Monitor scale vector norms during training. If Input-Norm γ norms grow unchecked, enable or increase weight decay on those γ’s to control Hessian sharpness.
- Expected impact:
- Reduced instability and sensitivity to learning rate; potential to safely use larger LR or batch sizes.
- Tools/workflows:
- Add logging hooks for γ magnitude and sharpness proxies; integrate with dashboarding (e.g., Weights & Biases).
- Assumptions/dependencies:
- Benefits demonstrated under standard optimizer settings (AdamW β1=0.9, β2=0.95, wd=0.1, clip=1.0). Retune if strongly deviating from these baselines.
- MoE model improvements (Industry: software/AI)
- What to do:
- Apply the unified scale-vector strategy to MoE projections (expert FFNs and shared projections).
- Expected impact:
- Consistent terminal loss reduction (>0.02) across multiple MoE sizes; better scaling.
- Tools/workflows:
- Integrate with Llama-MoE codebases; ensure DNP is aware of per-expert normalizations.
- Assumptions/dependencies:
- Token budgets at “industrial-scale” used in paper; validate under constrained compute settings as well.
- Compiler- and config-level best practices (Industry: MLOps; Academia)
- What to do:
- Update default templates in training repos to:
- Include IWD parameter groups.
- Expose switches for γ heterogeneity, DNP, and OR reparameterization.
- Expected impact:
- Out-of-the-box stronger convergence for new projects and smaller labs.
- Tools/workflows:
- Hugging Face/Lightning recipes; DeepSpeed config schemas with γ-specific parameter groups.
- Assumptions/dependencies:
- Minor code changes; ensure compatibility with gradient checkpointing and mixed precision.
- Cross-modal Transformer training (Industry: vision/audio; Academia)
- What to do:
- Apply IWD + DNP + OR to ViTs, speech transformers, and diffusion U-Nets that use LayerNorm/BatchNorm scale vectors.
- Expected impact:
- Likely training acceleration and stability benefits due to generic preconditioning effects.
- Tools/workflows:
- Adapt norm layers’ γ handling similarly; ensure per-head/per-channel normalization semantics are respected.
- Assumptions/dependencies:
- While the mechanisms are plausible beyond RMSNorm, verify per-domain hyperparameters and numerical behavior, especially with BN’s batch-dependent stats.
- Energy and cost savings in training (Policy; Industry)
- What to do:
- Adopt the unified strategy in corporate/model-zoo baselines to reduce tokens-to-target-loss.
- Expected impact:
- Fewer tokens for same loss => lower compute cost and carbon footprint at scale.
- Tools/workflows:
- Report standardized metrics (tokens-to-loss, energy-per-loss) in model cards and internal dashboards.
- Assumptions/dependencies:
- Realized savings depend on pipeline throughput and token budget; validate in production settings.
Long-Term Applications
These require further research, engineering, or scaling beyond what the paper demonstrates.
- Auto-preconditioning graph rewrites (Industry: compilers; Academia)
- Idea:
- Training compilers automatically insert/position γ and normalization (DNP/DP/AP) around linear maps and select IWD policies based on layer role and gradient statistics.
- Potential products:
- XLA/ONNX/DeepSpeed passes that rewrite computational graphs to optimized scale-vector placements and reparameterizations.
- Dependencies/assumptions:
- Need robust heuristics or learned controllers; ensure inference-time equivalence and minimal kernel overhead.
- Dedicated kernels and hardware support (Industry: hardware/software co-design)
- Idea:
- Fused kernels for dual-placement with normalization; efficient magnitude-direction γ updates; low-overhead head-wise normalization.
- Potential products:
- CUDA/Triton kernels and vendor libraries that treat γ as a first-class primitive; accelerator microarchitectures that cache per-branch γ effectively.
- Dependencies/assumptions:
- Requires collaboration with accelerator vendors; ensure benefits persist for very large models and mixed precision.
- Automated γ-policy tuning (AutoML) (Industry/Academia)
- Idea:
- Learn when to use heterogeneity, which placement (DP/DNP/AP), and which reparameterization (OR/ER) per layer, with schedules that adapt during training.
- Potential products:
- AutoML plugins that propose γ strategies per architecture/optimizer/task to minimize tokens-to-loss.
- Dependencies/assumptions:
- Needs reliable on-the-fly metrics (e.g., sharpness, γ drift) and low-cost exploration strategies.
- Extension to very large LLMs and multimodal foundation models (Industry/Academia)
- Idea:
- Validate and refine the unified γ strategy at scales ≥7B and across multimodal architectures (e.g., LLM+vision encoders, diffusion backbones).
- Potential products:
- Next-gen pretraining recipes that standardize γ policies for large-scale models.
- Dependencies/assumptions:
- Need careful scheduling, memory planning, and numerical stability checks at massive scales.
- Personalized inference via γ-tuning on-device (Industry: mobile/edge; Daily life)
- Idea:
- Post-hoc adjust γ’s (and β for OR) to personalize model behavior with tiny memory/compute, while keeping the main weights frozen.
- Potential products:
- On-device personalization kits (e.g., “Gamma-Tuning”) for text assistants or speech keyboards, updating only scale vectors from user interactions.
- Dependencies/assumptions:
- Must ensure safety alignment is preserved; develop regularizers/constraints to prevent drift.
- Robustness and safety shaping via norm placement (Policy/Industry/Academia)
- Idea:
- Explore whether γ placement and IWD can modulate sharpness and gradient noise to reduce instability, catastrophic forgetting, or unsafe behaviors in RLHF/post-training.
- Potential products:
- Safety-aware training recipes that couple γ policies with preference optimization.
- Dependencies/assumptions:
- Requires empirical validation on alignment datasets; careful trade-offs between expressivity (avoid wd on Output-Norm γ) and conservativeness.
- Theoretical generalization and curricula (Academia)
- Idea:
- Extend the preconditioning analysis to nonlinear blocks, attention with softmax, and adaptive optimizers; develop textbooks/tutorials on reparameterization-induced preconditioning.
- Potential outputs:
- Analytic tools for sharpness control via γ; course modules on optimization geometry in deep networks.
- Dependencies/assumptions:
- Nonlinear dynamics are harder to analyze; require additional assumptions or approximations.
- Standards and reporting for efficiency (Policy/Industry)
- Idea:
- Incorporate γ-policy disclosures (IWD, placements, reparameterizations) and energy-per-loss metrics into model cards and benchmark submissions.
- Potential outputs:
- Best-practice guidelines that encourage energy-efficient training via γ strategies.
- Dependencies/assumptions:
- Community adoption; alignment with emerging compute governance frameworks.
Notes on Assumptions and Dependencies (Cross-cutting)
- Architecture: Most evidence targets Pre-Norm Transformers with RMSNorm; extension to LN/BN and other modalities is plausible but may require tuning.
- Scale: Verified up to 2B parameters; extrapolation to larger models needs validation.
- Optimizers/schedules: Compatible with AdamW and Muon; benefits may interact with optimizer preconditioning; keep IWD and LR tuned after enabling γ strategies.
- Overheads: Parameter overhead is negligible; DNP introduces additional normalization ops—use fused kernels to limit runtime cost.
- Duplication with existing norms: If a model already includes Q/K-Norm and Output-Norm, integrate heterogeneity, OR reparameterization, and IWD carefully to avoid redundant normalizations.
Glossary
- AdamW: A variant of Adam with decoupled weight decay commonly used for training deep networks. "we adopt AdamW as the default optimizer"
- Adaptive optimizers: Optimizers that precondition gradients using statistics of past gradients to improve convergence. "Modern adaptive optimizers, such as RMSProp~\citep{Tieleman2012_rmsprop}, Adam~\citep{kingma2014adam}, KFAC~\citep{pmlr-v37-martens15}, Shampoo~\citep{pmlr-v80-gupta18a}, and Soap~\citep{vyas2025soap}"
- After-placement (AP): A design that places the scale vector after a linear map to modulate outputs directly. "AP: after-placement."
- BatchNorm (BN): A normalization method that normalizes activations using batch statistics. "Compared with BatchNorm (BN) in computer vision~\citep{ioffe2015batch}"
- Branch-specific heterogeneity: Using different scale vectors per branch (e.g., Q/K/V) to match distinct optimization dynamics. "branch-specific heterogeneity"
- Chinchilla-optimal regime: A scaling regime that balances model size and data to minimize loss for a given compute budget. "This budget substantially exceeds the Chinchilla-optimal regime~\citep{hoffmann2022training}"
- Continuous-time SDE approximation: Modeling SGD dynamics via a stochastic differential equation in continuous time. "stochastic gradient descent (SGD) through its continuous-time SDE approximation"
- Cosine learning rate schedule (cos schedule): A schedule that warms up then decays the learning rate following a cosine curve. "We use the cos schedule"
- Dual normalized placement (DNP): Using input- and output-side scale vectors with an intermediate normalization for stability. "DNP: dual normalized placement."
- Dual-placement (DP): Placing scale vectors on both the input and output sides of a linear map to enable two-sided preconditioning. "DP: dual-placement."
- ER (exponential-space reparameterization): Parameterizing scale vectors multiplicatively via log-space magnitude and centered exponentials for direction. "ER: reparameterization in exponential space."
- Expressivity: The representational capacity of a model or component to fit functions. "do not increase expressivity in Pre-Norm architectures"
- Feedforward network (FFN): The MLP submodule in Transformers consisting of linear projections and nonlinearities. "feedforward network (FFN)"
- Gradient flow (GF): The continuous-time limit of gradient descent used to analyze optimization dynamics. "gradient flow (GF):"
- Hadamard product: Element-wise multiplication between vectors or matrices. "We denote the Hadamard product by ."
- Hessian sharpness: Measures (e.g., spectral norm, trace) of curvature that influence optimization stability and speed. "key Hessian sharpness metrics"
- Heterogeneity (HG): A strategy that introduces separate scale vectors per branch to tailor preconditioning. "Heterogeneous scale vectors (HG)."
- Individual weight decay (IWD): Applying weight decay selectively to certain parameters (e.g., Input-Norm but not Output-Norm scale vectors). "Individual weight decay (IWD). Apply wd to Input-Norm scale vectors, but not to Output-Norm ones."
- Input-Norm layers: Normalization layers immediately followed by a linear map; their scale vectors mainly affect optimization. "Input-Norm layers: the RMSNorm layer immediately followed by a linear transformation."
- KFAC: A second-order optimizer that uses Kronecker-factored approximations to the Fisher information matrix. "KFAC~\citep{pmlr-v37-martens15}"
- LayerNorm (LN): A normalization method that normalizes across feature dimensions per example. "LayerNorm (LN) in sequence modeling~\citep{ba2016layer}"
- Magnitude-direction reparameterization: Separating a scale vector into global magnitude and directional components to improve conditioning. "magnitude-direction reparameterizations of scale vectors."
- Mixture-of-experts (MoE): An architecture that routes tokens through a subset of expert networks to increase capacity efficiently. "mixture-of-experts (MoE) models"
- Muon optimizer: A recent optimizer designed for efficient, stable LLM pre-training. "using Muon optimizer~\citep{jordan2024muon}"
- OR (original-space reparameterization): Splitting a scale vector into Euclidean magnitude and unit direction components. "OR: reparameterization in original space."
- Output-Norm layers: Normalization layers not immediately followed by a linear map; their scale vectors directly affect expressivity. "Output-Norm layers: the RMSNorm layer not immediately followed by a linear transformation."
- Pre-Norm architectures: Transformer designs where normalization is applied before submodules like attention and FFN. "In Pre-Norm architectures such as Llama~\citep{touvron2023llama}"
- Q/K-Norm: Normalization applied specifically to query and key projections in attention. "Q/K-Norm~\citep{dehghani2023scaling}"
- RMSNorm: A normalization method that scales activations by their root-mean-square without mean-centering. "RMSNorm~\citep{zhang2019root}"
- RMSProp: An adaptive optimizer that scales gradients by a running average of recent gradient magnitudes. "RMSProp~\citep{Tieleman2012_rmsprop}"
- Scale vector: A learnable per-channel scaling parameter typically following normalization layers. "a learnable scale vector"
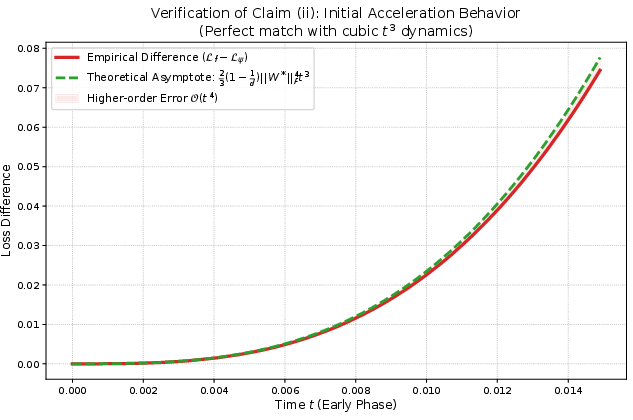
- Self-amplifying preconditioning: A state-dependent preconditioning effect where scale vectors strengthen their own optimization advantages. "self-amplifying preconditioning effect on subsequent linear mappings."
- Stochastic gradient descent (SGD): An optimization method that updates parameters using noisy gradient estimates from minibatches. "stochastic gradient descent (SGD) through its continuous-time SDE approximation."
- Warmup-stable-decay (wsd) scheduler: A learning-rate schedule with warmup, a stable phase, and a decay phase. "warmup-stable-decay (wsd) scheduler~\citep{hu2024minicpm}"
- Weight decay (wd): L2 regularization applied via parameter decay to improve generalization and stability. "weight decay (wd)"
Collections
Sign up for free to add this paper to one or more collections.

