EmuGEMM: Fused Tensor Core Kernels for Precision Emulation in Matrix Multiplication
Abstract: Modern GPUs devote an increasing silicon budget to low-precision matrix-multiplication units, widening the precision-throughput gap for scientific computing workloads. Ozaki Schemes I and II offer an alternative by reconstructing high-precision general matrix multiplication (GEMM) from low-precision operations, yet existing implementations leave substantial performance untapped. In particular, intermediate results are repeatedly materialized in global memory, making data movement the dominant bottleneck. We present EmuGEMM, fused integer Tensor Core kernels for NVIDIA Hopper and Blackwell GPUs that eliminate redundant memory round-trips in both Ozaki schemes. Using Scheme I, EmuGEMM sustains up to 1,639 Top/s on Hopper (83% of INT8 peak) and 3,654 Top/s on Blackwell (81%). For large matrices, EmuGEMM surpasses cuBLAS TF32 throughput by up to 1.4x on Hopper and 1.7x on Blackwell, at comparable accuracy. Using Scheme II, EmuGEMM extends to complex arithmetic and outperforms cuBLAS ZGEMM by up to 2.3x on Hopper and 5.5x on Blackwell.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about making scientific math run fast on modern GPUs that are mostly built for AI. Today’s GPUs are super quick at “low-precision” math (like tiny 8‑bit integers) but much slower at “high-precision” math (like 64‑bit floating point) that scientists often need. The authors introduce EmuGEMM, a set of clever GPU programs (kernels) that use the fast low-precision hardware to “emulate” high-precision matrix multiplication and still get accurate answers—much faster than usual.
Think of it like this: you only have a very fast calculator that handles small numbers. EmuGEMM shows how to break big-number problems into many small-number problems, solve them super fast, and then reassemble the pieces to get a big, accurate result.
Key goals in simple terms
The paper focuses on three questions:
- How can we get high-precision answers using the GPU’s fastest low-precision units?
- How can we avoid wasting time moving temporary data back and forth to slow memory?
- How can we do this for both real and complex numbers while staying accurate?
How they did it (explained with everyday ideas)
First, a few quick definitions to keep things clear:
- Matrix multiplication (GEMM) is a core math operation for science and AI: combining rows and columns to produce a new matrix.
- Precision means how many exact digits a number has; high-precision (like FP64) is very accurate but slow on today’s GPUs. Low-precision (like INT8) is super fast but too coarse if used directly.
- Tensor Cores are special GPU units that multiply small tiles of numbers very quickly, especially low-precision ones.
- Global memory is like the pantry (far away and slow), while on‑chip memory (registers, shared memory) is like the kitchen counter (near and fast).
- A kernel is a small program that runs on the GPU.
The authors build on two known “emulation” tricks (called Ozaki Schemes I and II) and then supercharge them by fusing steps together so results stay on the chip (kitchen counter) instead of being written out and read back from global memory (the pantry). Memory trips are slow—avoiding them is key.
Scheme I: Slice and recombine (like place values)
- Idea: Split each high-precision number into several 8‑bit “slices” (like writing a big number in base 256 and separating the digits).
- Multiply all the needed slice pairs using the fast 8‑bit hardware. Each such product is exact in 32‑bit integers.
- Recombine the slice results like place values (shift and add) to get the final high-precision answer.
- Challenge: There are many slice pairs—if each pair runs as a separate kernel, the GPU keeps reloading the same slices and writing big intermediate matrices to memory. That’s a ton of unnecessary back-and-forth.
What EmuGEMM-I changes:
- Interleaved layout: The authors pack the slices next to each other in memory so a single load brings in all slices needed for a tile.
- Fused kernel: Instead of launching many small kernels, they run one “persistent” kernel that:
- Loads each slice once.
- Computes all slice-pair products while keeping partial sums on the chip.
- Recombines (shift-reduce) the results on the chip and writes only the final answer out.
- Analogy: Bring all the ingredients from the pantry to the counter once, cook everything without running back and forth, and plate the final dish at the end.
Result: This cuts memory traffic dramatically—from something that grows with the square of the slice count to something that grows linearly—and lets the GPU spend more time computing and less time waiting.
Scheme II: Remainders and clocks (CRT)
- Idea: Instead of splitting bits, use remainders (modulo math). For example, you can compute the answer “mod 256”, then “mod 255”, “mod 253”, etc. Each of those is a small-number problem the GPU solves very fast with INT8.
- After getting several different remainders, the Chinese Remainder Theorem (CRT) combines them into the full (exact) integer answer, which is then scaled back to floating point.
- Analogy: If you know the time on several different clocks that tick at different speeds, you can figure out the exact time. More clocks mean more precision.
What EmuGEMM-II changes:
- In-register modular reduction: The usual way writes large 32‑bit intermediate results to memory and reads them back just to reduce them modulo m (turn them into 8‑bit residues). EmuGEMM-II does this modulo step directly in the kernel, in registers, and writes only the final small 8‑bit residues. That removes a big 8× write/read overhead.
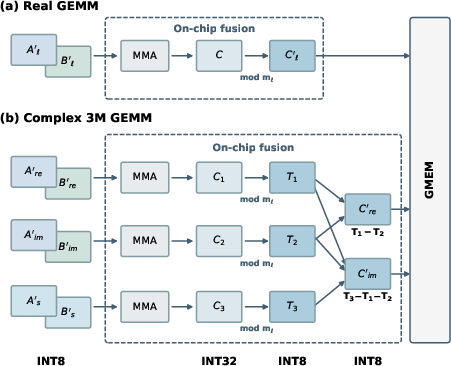
- Complex numbers with 3M: For complex multiplication, they use a math identity called “3M” that reduces four real multiplications to three. Normally, this can hurt accuracy in floating point, but in exact integer arithmetic (before the modulo), it’s safe. EmuGEMM-II fuses all three products and the reductions in one kernel and only writes the final two small outputs (real and imaginary parts).
Result: Far less memory traffic and better use of fast on-chip compute for both real and complex matrix multiplications.
Main findings and why they matter
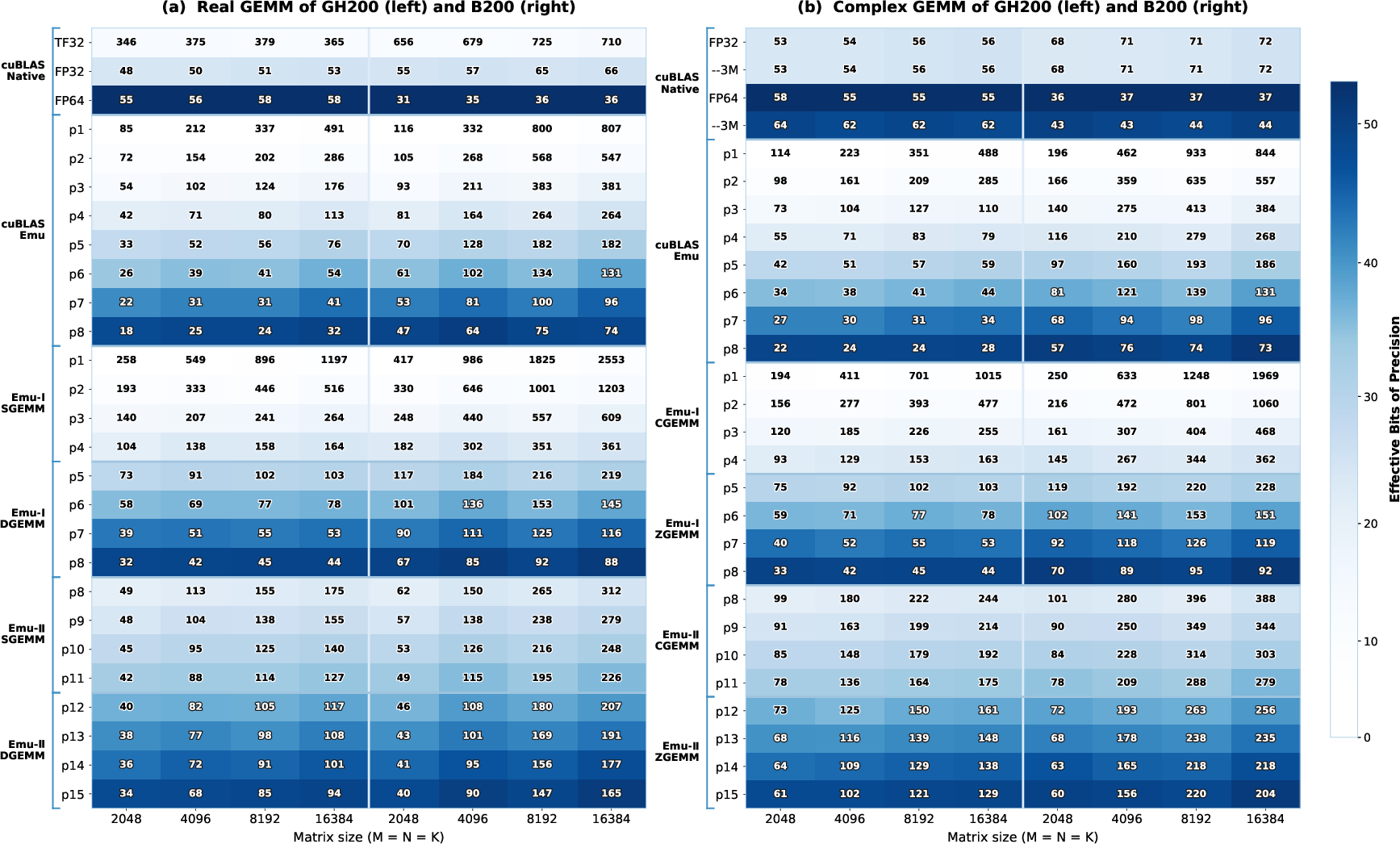
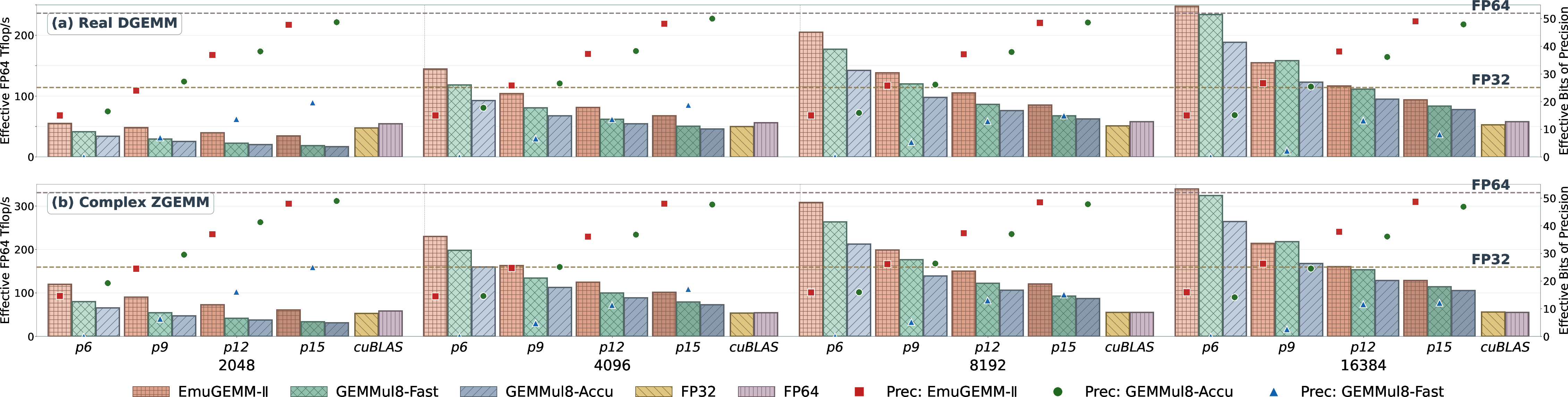
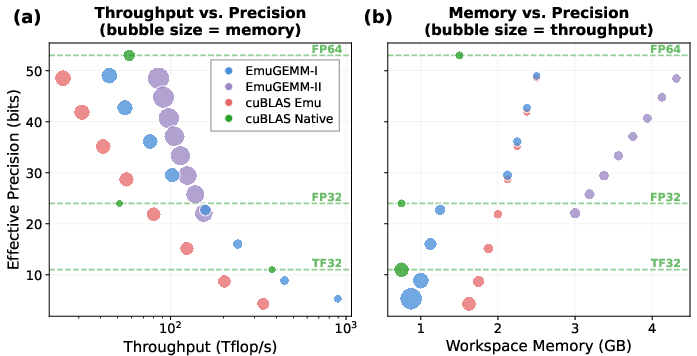
- Very high speed on new GPUs:
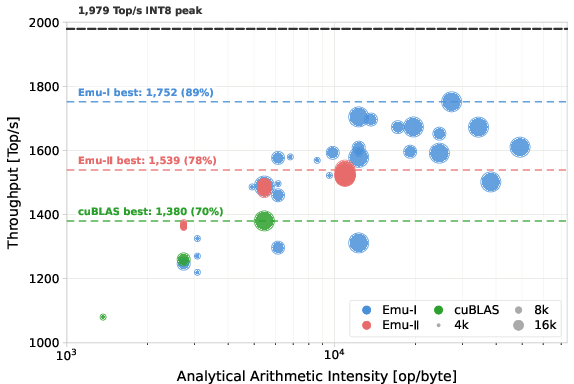
- EmuGEMM-I (Scheme I) sustains up to about 1,639 trillion 8‑bit operations per second (Top/s) on NVIDIA Hopper (about 83% of the theoretical max) and 3,654 Top/s on Blackwell (about 81%).
- Faster than widely used libraries in key cases:
- For large matrices, EmuGEMM-I beats NVIDIA’s cuBLAS TF32 throughput by up to 1.4× on Hopper and 1.7× on Blackwell, while keeping similar accuracy.
- EmuGEMM-I also outpaces cuBLAS’s own Scheme I emulation by up to about 1.4× and even exceeds cuBLAS’s native INT8 GEMM in some settings.
- Better at high precision with Scheme II:
- When aiming for double‑precision‑level accuracy (like FP64), EmuGEMM-II (CRT‑based) performs best. It delivers up to 1.6× (Hopper) and 4.6× (Blackwell) the speed of cuBLAS native FP64 for real matrices.
- For complex matrices, EmuGEMM-II (using 3M) is up to 2.3× faster on Hopper and 5.5× faster on Blackwell than cuBLAS’s complex FP64 (ZGEMM).
- The “secret sauce”: Fusion and smart data layout dramatically reduce slow memory traffic. For Scheme I, loading each slice once and keeping all partial sums on-chip turns a memory-bound problem into a compute-friendly one. For Scheme II, doing the modulo step on-chip removes huge intermediate write/reads.
Why it’s important:
- Scientists in fields like climate modeling, chemistry, and engineering often need high-precision math; these results show they can get that accuracy much faster on GPUs designed mainly for AI’s low-precision workloads.
- It stretches the usefulness of existing hardware—no new chips required—by smarter software.
What this could change
- Faster science on AI-tuned GPUs: As GPUs keep favoring low precision for AI, techniques like EmuGEMM help scientists keep up by “bending” fast low-precision units to deliver high-precision answers.
- Energy and cost savings: Doing more with the same hardware can cut time and power for large simulations and data analysis.
- Flexibility: Users can pick how many slices or moduli to use—trading a bit more time for more precision or vice versa—rather than being stuck with only a few fixed precision modes.
- Broader impact: The same ideas—fusing steps and keeping data on-chip—can benefit other algorithms that juggle lots of intermediate results.
In short, this paper shows a practical, high-performance path to accurate matrix math on modern GPUs by cleverly reorganizing work: break big numbers into small pieces, compute them fast, and keep everything on the “kitchen counter” until the final result is ready.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes strong contributions on fused emulation kernels, but it leaves several important aspects unresolved. The following concrete gaps can guide future research:
- End-to-end overheads outside the fused kernels
- Quantify and optimize the cost of preprocessing (slice extraction, scaling, and interleaving) for Scheme I and modular operand generation for Scheme II, including their memory traffic, latency, and device memory footprint.
- Clarify what portion of reported “effective performance” includes or excludes preprocessing and CRT reconstruction, and provide end-to-end breakdowns across p and problem sizes.
- Operand materialization in Scheme II
- Avoid storing p separate INT8 residue copies of A and B by computing per-modulus residues on-the-fly within the GEMM pipeline (e.g., per-tile modular reduction of A′, B′ before MMA), and quantify the trade-off between extra ALU work and reduced HBM footprint.
- CRT reconstruction remains unfused
- The CRT stage is implemented as a separate kernel due to register pressure. Investigate streaming/Garner-like reconstruction fused with residue production (e.g., reconstructing partial words incrementally as moduli complete) to reduce global memory round-trips and total passes over C.
- Analyze when CRT arithmetic (multiword ops) becomes the dominant bottleneck for large p and propose GPU-friendly implementations (e.g., warp-cooperative bignum, TMEM staging, overlap with residue generation).
- Moduli selection and robustness in Scheme II
- Provide a principled, hardware-aware strategy to choose pairwise coprime moduli ≤ 256 that maximizes log2 P subject to efficient modulo operations and register pressure; compare primes-only, mixed composite sets, and hardware-friendly bases (e.g., 2k±1).
- Develop a reliable, low-cost estimator to select the minimum p needed per problem (or per tile) to satisfy 2 Σ_h |a′_ih| |b′_hj| < P with high confidence; quantify failure probabilities and detection/mitigation strategies.
- Scaling (μ, ν) and precision control
- Formalize and evaluate strategies to compute per-row and per-column power-of-two scalings that minimize p while guaranteeing no overflow in INT32 accumulators; compare static, adaptive-per-tile, and global scaling.
- Explore dynamic precision (ADP)-style selection for fused EmuGEMM (per-tile p choices) while preserving fusion benefits and hardware utilization.
- INT32 accumulator safety bounds
- Provide explicit bounds and safeguards preventing INT32 overflow in both schemes, especially for large K and worst-case residues/slices. For Scheme I, analyze worst-case slice magnitudes after unsigned slicing; for Scheme II, analyze residue accumulation at chosen moduli.
- Evaluate chunked-K accumulation with periodic modular reductions (Scheme II) or partial shift-reduce (Scheme I) to extend safe K without sacrificing throughput.
- Numerical analysis and error bounds
- Give formal end-to-end error bounds for both schemes under the fused implementations, including effects of INT32→FP32/FP64 conversion in shift-reduce, rounding in the final scaling, and conditioning of inputs beyond the tested φ=4.
- Assess robustness on real HPC matrices (ill-conditioned, wide exponent spans) and provide guidance for selecting p and β under domain-specific constraints.
- Memory footprint and data layout constraints
- Interleaving increases the effective K dimension to pK and requires extra GMEM for interleaved copies; assess peak memory needs for very large problems and tight-memory systems, and explore in-place or streamed interleaving to reduce memory overhead.
- Evaluate boundary handling (non-multiples of tK, odd K) and the performance impact of padding/masking, which the paper does not detail.
- Small/skinny/batched GEMM regimes
- The benchmarks focus on large, square matrices. Characterize performance and crossover points for:
- small/medium M, N, K where fusion overheads and reduced ω may dominate,
- tall/skinny or wide/short matrices,
- strided-batched and batched GEMM workloads with different transpose/conjugate options.
- Parallelization beyond a single GPU
- Extend fused emulation to multi-GPU/distributed settings (e.g., 2D/3D SUMMA), including how interleaving and p accumulators interact with partitioning, communication, and overlap across NVLink/NVSwitch; quantify communication overheads per p.
- Architectural portability and future formats
- Port EmuGEMM to architectures without TMA/TMEM (e.g., NVIDIA Ampere, AMD CDNA) and quantify the impact of lacking those features; identify required kernel redesigns and data layouts for different MMA tile shapes.
- Explore emulation on FP8/INT4 tensor cores (or mixed-precision combinations), generalizing the interleaved layout and fusion to different tile widths and accumulators, along with the implications for accuracy and p.
- Complex 3M scheduling
- The 3M fused kernel executes three K-loop passes sequentially. Investigate interleaving these passes at finer granularity (e.g., micro-k steps) to improve temporal locality and overlap, and analyze the effect on TMEM/RF pressure.
- Energy and cost-efficiency
- Measure energy per operation and performance-per-watt across p and schemes; assess whether the memory-traffic reductions translate into meaningful energy savings in realistic HPC workloads.
- Integration into numerical algorithms and libraries
- Evaluate the impact of emulated GEMM on solvers (LU/Cholesky/QR), eigensolvers, iterative refinement, and Krylov methods; determine when the emulation residual is acceptable vs. when additional refinement is needed.
- Provide an API and heuristics for automatic p selection given a target tolerance and conditioning estimate; consider integration into existing BLAS/LAPACK/solver stacks.
- Autotuning coverage and stability
- Document the autotuner’s search space (α, tN, β, γ), convergence reliability across architectures and sizes, and provide portable heuristics that achieve near-optimal performance without exhaustive tuning.
- Software availability and reproducibility
- Clarify code availability, reproducibility artifacts (seeds, datasets), and integration paths with cuBLAS/CUTLASS/DeepGEMM to facilitate adoption and further experimentation.
Practical Applications
Immediate Applications
The following use cases can be deployed now on NVIDIA Hopper (GH200) and Blackwell (B200) GPUs by integrating the paper’s fused kernels (EmuGEMM-I and EmuGEMM-II) into existing BLAS-backed workflows. They exploit the library’s ability to emulate FP32/FP64 (real and complex) using INT8 Tensor Cores, cutting memory traffic and boosting throughput.
- Sector: Scientific computing (HPC) — drop-in high-precision GEMM acceleration
- Use case: Speed up FP32/FP64 real and complex GEMMs in physics, chemistry/materials, CFD, climate, and numerical linear algebra codes that already call BLAS/LAPACK/MAGMA/cuBLAS
- Why this paper: EmuGEMM-I achieves up to 1.4–1.7× cuBLAS TF32-equivalent throughput at similar accuracy; EmuGEMM-II outperforms native FP64/ZGEMM by up to 1.6–5.5× for large matrices
- Tools/products/workflows: Replace or wrap cuBLAS GEMM calls with EmuGEMM kernels via a BLAS-compatible shim; tune p (slices/moduli) per target precision; integrate into MAGMA/BLIS-backed solvers
- Assumptions/dependencies: NVIDIA Hopper/Blackwell GPUs; CUDA 13.1; large matrices (best benefits >4k); extra preprocessing (interleaving) and CRT reconstruction; careful choice of slice count and scaling
- Sector: Quantum chemistry/materials (e.g., CP2K, Quantum ESPRESSO, VASP, Gaussian)
- Use case: Accelerate dense complex GEMMs in Fock matrix builds, coupled-cluster tensor contractions, diagonalization updates
- Why this paper: EmuGEMM-II fused 3M complex kernels provide exact modular arithmetic in the multiply stage and deliver up to 2.3× (GH200) and 5.5× (B200) over cuBLAS ZGEMM
- Tools/products/workflows: Link BLAS calls in quantum chemistry packages to EmuGEMM; enable Scheme II + 3M for complex paths; add validation tests for chemical accuracy thresholds
- Assumptions/dependencies: Ensure CRT bound P is large enough via moduli selection; regression testing for sensitive post-processing (e.g., SCF convergence)
- Sector: Signal processing and telecommunications (5G/6G vRAN/O-RAN, radar, beamforming)
- Use case: Complex MIMO/beamforming kernels and channel estimation pipelines that rely on complex GEMM
- Why this paper: Fused 3M complex kernels reduce GEMM count by 25% and avoid INT32 round-trips, improving throughput and energy efficiency
- Tools/products/workflows: Integrate custom CUDA ops using EmuGEMM-II into baseband chains; expose “complex matmul” with emulated precision levels tied to SNR targets
- Assumptions/dependencies: Latency constraints may require micro-batched or tile-optimized variants; verification of deterministic timing for real-time requirements
- Sector: Medical imaging (MRI/CT reconstruction, compressed sensing)
- Use case: Faster iterative reconstruction and large-scale complex linear algebra in reconstruction toolchains
- Why this paper: Complex GEMM-heavy steps benefit from EmuGEMM-II’s fused 3M and in-register modular reductions
- Tools/products/workflows: Replace reconstruction library’s GEMM backends; offer “precision knobs” to meet image quality targets while accelerating throughput
- Assumptions/dependencies: Clinical/regulatory validation; ensure numerical behavior matches acceptable error bounds for diagnostic use
- Sector: Climate/weather and CFD (WRF, ICON, E3SM, OpenFOAM-based solvers)
- Use case: High-precision GEMMs in time-stepping, spectral transforms, and solver updates where FP64 accuracy is required
- Why this paper: Bridges the growing INT8–FP64 performance gap on modern GPUs while preserving solution accuracy
- Tools/products/workflows: Swap GEMM kernels in solver backends to EmuGEMM; autotune p per model configuration
- Assumptions/dependencies: Best gains at large problem sizes; validate stability of long runs; adjust p for ill-conditioned scenarios
- Sector: Finance (risk analytics, portfolio optimization, Monte Carlo)
- Use case: Covariance updates, factor model matmuls, and linear solvers that prefer FP64
- Why this paper: EmuGEMM-II can exceed native FP64 throughput on Blackwell by 4.6× for large matrices while delivering requisite precision
- Tools/products/workflows: Integrate EmuGEMM in quant libraries; expose per-computation precision profiles to meet risk tolerances
- Assumptions/dependencies: Model validation for regulatory/audit requirements; large-batch workloads favored for best efficiency
- Sector: EDA/CAE (circuit simulation, structural analysis)
- Use case: Dense GEMMs in device modeling, frequency-domain simulation, and finite-element assembly
- Why this paper: Fused kernels keep intermediates on-chip and boost throughput even at FP64-equivalent targets
- Tools/products/workflows: Link EmuGEMM into solver modules; autotune per device and mesh sizes
- Assumptions/dependencies: Benefits increase with matrix size and batching; verify numerical conditioning and stability
- Sector: Cloud/HPC service providers
- Use case: Offer “FP64-equivalent” acceleration tiers on Blackwell nodes using INT8 TCs with emulation
- Why this paper: Demonstrated end-to-end Top/s near INT8 peak and speedups over cuBLAS FP64/complex enable attractive price/performance
- Tools/products/workflows: Kubernetes device plugins and SLAs that report “emulated FP64 throughput”; billing tied to precision level p and matrix size
- Assumptions/dependencies: Transparent integration into customer containers via BLAS shims; acceptance tests to certify accuracy
- Sector: Education/academia and scientific Python
- Use case: Run FP64-heavy labs and research on low-precision-optimized GPUs without sacrificing accuracy
- Why this paper: Emulation enables practical FP64-equivalent performance on modern GPUs optimized for INT8
- Tools/products/workflows: Python bindings (NumPy/CuPy/PyTorch) exposing matmul with target precision flags; tutorials demonstrating Scheme I/II trade-offs
- Assumptions/dependencies: Packaging for common distros; user education around p selection and data scaling
Long-Term Applications
These use cases depend on further development (e.g., broader hardware support, compiler/runtime integration, small-matrix/low-latency tuning, numerical analysis extensions) before widespread deployment.
- Sector: Full numerical linear algebra suites (factorizations and eigensolvers)
- Use case: Rework LU/QR/Cholesky, SVD, and eigensolvers to exploit emulated GEMM in blocked updates and use iterative refinement for robust FP64 accuracy
- Potential tools/products/workflows: MAGMA/BLIS/SLATE integrations that choose Scheme I/II dynamically; autotuners that balance precision and throughput
- Assumptions/dependencies: Rigorous error analyses and pivoting strategies; end-to-end stability testing on ill-conditioned problems
- Sector: Compiler and runtime systems
- Use case: Automatic graph-level transformation that detects GEMM hot spots, inserts interleaving/CRT, and fuses epilogues at compile time
- Potential tools/products/workflows: MLIR/TVM/CUTLASS backends with schedule templates for fused Ozaki kernels; autotuning of p by error/throughput budgets
- Assumptions/dependencies: Vendor-agnostic abstractions for integer MMAs, on-chip buffers (RF/TMEM), and async copy (TMA-like) across architectures
- Sector: Cross-vendor portability (AMD, Intel, specialized accelerators)
- Use case: Port fused emulation kernels to AMD Matrix Cores or other accelerators with integer MMAs and on-chip accumulation
- Potential tools/products/workflows: A standardized “Emulated BLAS” API; backend implementations per vendor ISA
- Assumptions/dependencies: Availability of equivalent integer MMA instructions and on-chip storage semantics; performance parity requires similar memory hierarchy features
- Sector: Real-time telecom and radar
- Use case: Latency-critical small/mid-size complex matmuls for baseband and sensing, with deterministic timing
- Potential tools/products/workflows: Micro-batched and warp-specialized EmuGEMM kernels; integration into RAN stacks and SDR frameworks
- Assumptions/dependencies: Kernel variants optimized for small matrices; hard real-time scheduling and profiling on production hardware
- Sector: Energy-aware scheduling and procurement policy
- Use case: Supercomputing centers adopt emulation-aware schedulers that minimize energy per solution by leveraging INT8 TCs for high-precision workloads
- Potential tools/products/workflows: Job schedulers exposing precision-throughput-energy trade-offs; procurement favoring GPUs with strong low-precision MMUs plus emulation capability
- Assumptions/dependencies: Validation frameworks that certify numerical equivalence; updates to benchmarking (e.g., FP64 metrics) to recognize emulated precision
- Sector: Regulatory-grade scientific/medical/aerospace computing
- Use case: Certify emulation-based pipelines for regulated workflows that require FP64 accuracy and reproducibility
- Potential tools/products/workflows: Conformance tests, numerical reproducibility modes, and documentation of error bounds under Ozaki schemes
- Assumptions/dependencies: Standardized verification/validation; reproducibility controls (deterministic seeds, fixed p and moduli)
- Sector: Edge/robotics and embedded GPUs
- Use case: High-precision linear algebra in control/estimation on devices where FP64 hardware is constrained but INT8 TCs are present
- Potential tools/products/workflows: Jetson-class kernels tailored for small matrices and low latency; integration into SLAM/estimation libraries
- Assumptions/dependencies: Hardware support for integer MMAs and sufficient on-chip buffers; specialized scheduling for real-time constraints
- Sector: Data analytics and GPU-accelerated databases
- Use case: Accelerate FP64-heavy analytics (e.g., PCA/SVD-heavy pipelines) by funneling matmul to emulated kernels
- Potential tools/products/workflows: Columnar GPU databases and analytics engines integrating EmuGEMM as a high-precision matmul primitive
- Assumptions/dependencies: Broader adoption of GPU backends in DBs; operator fusion passes that preserve data layout benefits
- Sector: Quantum simulation and quantum AI
- Use case: Large-scale complex linear algebra in state vector and tensor network simulators
- Potential tools/products/workflows: EmuGEMM-backed complex GEMM primitives in qsim libraries; precision knobs aligned to fidelity targets
- Assumptions/dependencies: Memory scaling and CRT parameterization for extremely large dimensions; validation against physics-specific error metrics
Common assumptions and dependencies across applications
- Hardware/software: Current results depend on NVIDIA Hopper/Blackwell features (INT8 Tensor Cores, wgmma/tcgen05 MMAs, TMA, RF/TMEM footprints) and CUDA 13.1; portability to other vendors requires new kernels
- Problem sizes: Best gains occur for large matrices where kernel fusion and arithmetic intensity dominate; small matrices/low-latency use cases need specialized variants
- Data layout and overheads: Scheme I requires interleaved K-layout; Scheme II requires CRT reconstruction; preprocessing and CRT costs should be amortized over large workloads
- Numerical guarantees: Choice of slice count p, bit-width β (Scheme I), and moduli set (Scheme II) must meet application-specific accuracy/stability targets; ill-conditioned problems may need higher p
- Memory footprint: Interleaving effectively scales K by p during compute; ensure on-device memory and bandwidth budgets are sufficient for staging and buffering
Glossary
- 3M (three-multiplication) method: An algorithm to compute complex matrix products using three real multiplications instead of four, reducing GEMM count without accuracy loss in modular arithmetic. "extended Scheme~II to complex arithmetic via the 3M method"
- 4M formulation: The standard complex GEMM approach that uses four real-valued multiplications to form the real and imaginary parts. "The standard 4M formulation computes C'{\ell,re} and C'{\ell,im} from four real products"
- accumulator (INT32 accumulator): On-chip storage holding the running sum of MMA tile results (typically 32-bit integers) before conversion or reduction. "which multiplies the residue operands into an INT32 accumulator:"
- arithmetic intensity: The ratio of computations to data movement (ops per byte), indicating how compute- or memory-bound a kernel is. "The resulting arithmetic intensity increases by a factor of ."
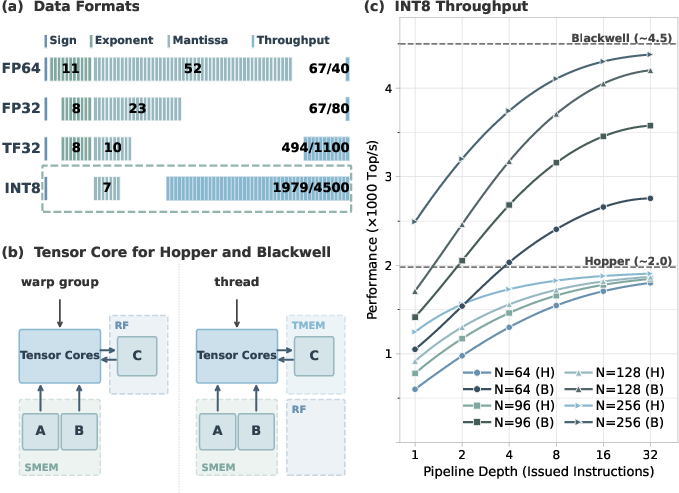
- Blackwell (SM100) microarchitecture: NVIDIA’s GPU architecture succeeding Hopper, featuring updated Tensor Cores and TMEM. "We target NVIDIA Hopper (SM90) and Blackwell (SM100) microarchitectures."
- Chinese Remainder Theorem (CRT): A number-theoretic method to reconstruct an integer from its residues modulo co-prime moduli, enabling precision emulation via modular products. "leverages the Chinese Remainder Theorem (CRT) to perform emulation via integer modular arithmetic"
- cooperative thread array (CTA): A CUDA thread block that executes cooperatively on an SM, sharing on-chip resources. "An SM executes one or more cooperative thread arrays (CTAs, or thread blocks)"
- cuBLAS: NVIDIA’s CUDA-optimized BLAS library providing high-performance GEMM routines and emulation support. "The recent integration of Ozaki Scheme~I into cuBLAS"
- DeepGEMM: A lightweight GEMM library used as the implementation base for the fused kernels. "We develop our optimized implementations of the fused Ozaki Schemes~I and II on top of DeepGEMM"
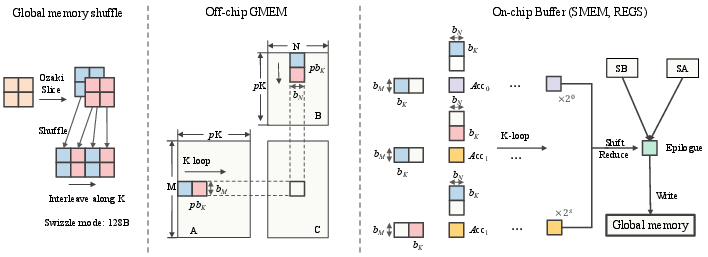
- epilogue (GEMM epilogue): The final kernel stage that converts/reduces accumulators and writes results to memory. "the epilogue applies the shift-reduce reconstruction"
- fused kernel (kernel fusion): Combining multiple computational stages into one kernel to keep intermediates on-chip and avoid memory round-trips. "kernel fusion is not merely an optimization"
- GEMM (General Matrix Multiplication): The core operation computing C = AB for matrices, central to HPC and ML workloads. "General matrix multiplication (GEMM) is the computational backbone of modern high-performance computing (HPC) and ML workloads"
- HBM3: High Bandwidth Memory (gen 3) used on GPUs to provide very high memory bandwidth. "with 96\,GiB HBM3 at up to 4\,TB/s bandwidth"
- Hopper (SM90) microarchitecture: NVIDIA’s GPU architecture prior to Blackwell, with wgmma MMA and RF-based accumulators. "We target NVIDIA Hopper (SM90) and Blackwell (SM100) microarchitectures."
- interleaved data layout: A global-memory arrangement that interleaves per-slice tiles along K to fetch all slices with one TMA and align with MMA tiles. "Interleaved data layout."
- matrix-multiply-accumulate (MMA) instruction: A Tensor Core instruction that multiplies two tiles and accumulates into an output tile. "INT8 TCs are accessed via architecture-specific matrix-multiply-accumulate (MMA) instructions"
- modular reduction: Reducing an integer result modulo m to its residue, used to keep outputs in INT8 for CRT-based emulation. "must then undergo a modular reduction to extract its INT8 residue"
- Ozaki Scheme I: A precision-emulation method that splits mantissas into INT8 slices and recombines exact partial products. "the Ozaki Scheme~I"
- Ozaki Scheme II: A precision-emulation method that computes modulo products under several co-prime moduli and reconstructs via CRT. "This method is referred to as the Ozaki Scheme~II."
- persistent kernel: A kernel that stays resident and iterates over tiles internally, overlapping compute with data movement. "we implement a persistent kernel for NVIDIA Hopper and Blackwell GPUs"
- pipeline depth (MMA pipeline depth): The number of MMA instructions issued per K-step, governing sustained TC throughput. "Sustained INT8 throughput as a function of MMA pipeline depth~"
- register file (RF): Per-SM on-chip registers storing thread-local state and (on Hopper) accumulators. "a register file (RF) for holding thread-local state and intermediate values"
- shared memory (SMEM): On-chip scratchpad memory used to stage tiles of A/B and sometimes epilogue data. "on-chip shared memory (SMEM) for staging input and output data"
- shift-reduce: A reconstruction technique that combines INT32 accumulators with power-of-two weights to recover higher precision. "followed by an in-register shift-reduce epilogue"
- tcgen05.mma: The Blackwell-generation MMA instruction used to access integer Tensor Cores. "On Blackwell, we use tcgen05.mma, with , , and configurable "
- Tensor Core (TC): Specialized GPU units for high-throughput matrix-multiply-accumulate operations across data formats. "Each SM contains Tensor Core (TC) units"
- tensor memory (TMEM): Blackwell’s dedicated on-chip storage for accumulators, separate from RF and SMEM. "tensor memory (TMEM), a dedicated on-chip storage for accumulator data"
- Tensor Memory Accelerator (TMA): Hardware engine for asynchronous bulk copies between global memory and shared memory. "tensor memory accelerator (TMA) instructions, which perform asynchronous bulk copies between GMEM and SMEM"
- TF32 (TensorFloat-32): NVIDIA’s reduced-precision floating-point format used for faster GEMM with acceptable accuracy for many workloads. "cuBLAS TF32 throughput"
- Top/s (tera-operations per second): A throughput unit measuring trillions of operations per second, commonly used for INT8 performance. "1{,}639~Top/s on Hopper"
- triangular MMA schedule: A scheduling pattern that accumulates slice-pair products into diagonals (s = i + j) across p accumulators. "via a triangular MMA schedule over on-chip accumulators"
- warpgroups (WG): Groups of warps that execute certain TC instructions collectively on an SM. "threads can be partitioned into warpgroups (WG)"
- wgmma.mma_async: Hopper’s warpgroup-level asynchronous MMA instruction for Tensor Cores. "On Hopper, we use wgmma.mma_async, a WG-level instruction"
Collections
Sign up for free to add this paper to one or more collections.

