The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
Abstract: The Hitchhiker's Guide to Agentic AI is a comprehensive practitioner's reference for building autonomous AI systems. The book covers the full stack from first principles to production deployment, organized around a central thesis: building great agentic systems requires understanding every layer of the pipeline, not just one. The book opens with the LLM substrate -- transformer architecture, GPU systems, training and fine-tuning (SFT,LoRA, MoE), model compression, and inference optimization -- treated as essential foundations rather than the primary focus. It then develops the alignment and reasoning layer: reinforcement learning from human feedback (RLHF), PPO, DPO and its variants, GRPO, reward modeling, and RL for large reasoning models including chain-of-thought and test-time scaling. The second half is devoted to agentic AI proper. Topics include agentic training and trajectory-based RL, retrieval-augmented generation (RAG and Agentic RAG), memory systems (in-context, external, episodic, and semantic), agent harness design and context management, and a taxonomy of agent design patterns. Inter-agent coordination is covered in depth: the Model Context Protocol (MCP), agent skills and tool use, the Agent-to-Agent (A2A) communication protocol, and multi-agent architectures spanning centralized, decentralized, and hierarchical topologies. The book concludes with agent development frameworks, agentic UI design, evaluation methodology for agentic tasks, and production deployment. Each chapter pairs rigorous theoretical foundations with implementation guidance, code examples, and references to the primary literature.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this “paper” is about
This work is a friendly, all‑in‑one guide to “agentic AI” — AI systems that don’t just chat, but can plan, use tools, work with other AIs, and get things done. Think of it as a complete handbook that shows how today’s LLMs work on the inside, how we train and align them to be helpful, how we teach them to reason, and how we assemble them into reliable, useful agents in the real world.
Instead of presenting one new experiment, it gathers and explains lots of important ideas, tools, and best practices from many places, then organizes them into a single, practical roadmap “from foundations to systems.”
The key questions it answers
The guide focuses on clear, practical questions people building AI care about, such as:
- How do transformers (the brains behind LLMs) actually work?
- How do we train big models efficiently and cheaply?
- How do we align models so they follow human preferences (e.g., RLHF, DPO)?
- How can models learn to reason through multi‑step problems?
- How do we give models hands and eyes in the world — tools, memory, and ways to talk to other agents?
- How do we test, compare, and trust these systems?
- What designs and frameworks work best in real products?
How the guide approaches the topic
This is a survey and teaching guide, not a single lab study. Its approach is:
- Intuition first: It explains tricky ideas in plain language (with math and code only when helpful).
- Implementation‑aware: It covers not only “what” and “why,” but also “how to build it,” with tips on hardware, libraries, and debugging.
- Honest about trade‑offs: It tells you what’s proven in production and what’s still experimental.
- Organized like a course: It’s split into parts that build on each other — foundations, training and alignment, reasoning, evaluation, and full agentic systems.
To make complex ideas accessible, it uses everyday analogies:
- Tokenization is like breaking text into LEGO bricks the model can snap together.
- Attention is like highlighting the most important words so the model knows where to look.
- An agent is like a digital intern who can plan, use tools, and ask others for help.
What it covers (methods and topics, in everyday terms)
Here’s the “toolbox” the guide walks through:
- Transformers and LLM basics: How text becomes tokens, tokens become vectors, and attention lets each word look at other words to understand context.
- Efficient training: Tricks that make big models faster and cheaper to train and adapt (for example, LoRA to fine‑tune without changing all the weights, and FlashAttention to speed up attention).
- Alignment methods: Ways to teach models what people want, like:
- RLHF: Humans compare outputs; a reward model and reinforcement learning push the model toward preferred answers.
- DPO and friends: Simpler training that uses preference pairs directly without a separate reward model.
- Reasoning models: New training that teaches models to think step‑by‑step, check their own work, and backtrack when needed — helpful for math and coding.
- Systems and deployment: How GPUs, memory, distributed training, and inference engines fit together so models run at scale.
- Evaluation: How to measure quality fairly, avoid data leaks, and judge agent skills.
- Agentic AI stack: How to build full agents that:
- Remember things over time (memory),
- Use tools through standard protocols (like MCP),
- Communicate with other agents (A2A),
- Coordinate in teams (multi‑agent systems),
- And run inside practical frameworks (LangGraph, CrewAI, AutoGen, and others).
It also sets a clear scope: it focuses on text‑based systems and leaves vision/audio/video for other specialized resources.
Main takeaways and why they matter
Here are the big messages, explained simply:
- Decoder‑only transformers won: For text generation, the simpler GPT‑style model scales best and powers today’s strongest LLMs.
- Size matters — and so does efficiency: Bigger models trained on more data get better, but smart engineering (like LoRA, quantization, and FlashAttention) makes them practical.
- Alignment turned raw models into helpful assistants: RLHF and preference‑based training transformed powerful but unpredictable models into useful chatbots.
- RL can teach reasoning: With the right rewards, models learn to think in steps, check themselves, and solve harder problems — not just sound fluent.
- Tools make agents useful: Standard ways to call tools (MCP) and talk to other agents (A2A) give models “hands” and “voices,” turning them from talkers into doers.
- Orchestration is the new operating system: Good patterns for planning, memory, and control logic turn a smart model into a reliable system.
- Evaluation is essential: Clear tests, careful metrics, and human checks help prevent mistakes and overconfidence — critical for safety and quality.
These takeaways matter because they show not only what works, but also how to put all the pieces together so AI can help with real tasks, from writing code to searching the web to coordinating complex workflows.
What this means for the future
The guide’s impact is practical: it shortens the path from idea to working agent. With it, students and engineers can:
- Understand the full pipeline from model to product.
- Choose the right training and alignment method for their needs.
- Build agents that plan, use tools, and cooperate with other agents.
- Evaluate responsibly, catching failures before they reach users.
Big picture: agentic AI could change how we build software and run workflows. Instead of telling a computer exactly what to do, we’ll increasingly describe goals, and agents will plan and act to achieve them — safely, transparently, and with humans in control. This guide aims to make that future reachable, reliable, and understandable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper (as provided) leaves missing, uncertain, or unexplored, framed to be directly actionable for future research.
- Empirical guidance on tokenizer choice is absent: no controlled comparisons across BPE, WordPiece, Unigram LM, and byte-level BPE for code, multilingual text, and arithmetic, measuring fertility, accuracy, latency, and downstream RL stability.
- No procedure for selecting vocabulary size (e.g., 32K vs 128K) under compute/latency constraints; lacks ablations quantifying trade-offs between seq length, embedding table size, and multilingual/code performance.
- Special token and chat-template design lacks evidence: no ablations on how template boundaries, role tokens, and tool-call delimiters affect PPO/DPO KL behavior, mode collapse, or tool-use reliability.
- EOS handling in RL is flagged as a failure point but no algorithmic guarantees are offered; open problem: termination-aware objectives or decoding constraints that provably prevent runaway generations.
- Weight tying is presented as common practice without analysis of when to untie input/output embeddings (e.g., very large vocab, MoE decoders) to improve stability or calibration.
- Decoder-only dominance is asserted without decision criteria; missing guidance on when encoder–decoder remains preferable (structured seq2seq, retrieval-heavy tasks) and how to migrate between architectures.
- Lack of formal understanding of why RL induces chain-of-thought and self-verification (o1/R1-style) without CoT supervision; open theory: conditions on reward signals, exploration, and model scale that guarantee emergent reasoning.
- Reproducibility of reasoning RL is unaddressed: no seed-variance studies, hyperparameter sensitivity, or compute scaling laws for PPO/GRPO/DPO on math/code reasoning benchmarks.
- Reward model design remains under-specified: no prescriptions for regularization, calibration, and out-of-distribution robustness; open question of reward hacking mitigation that generalizes across domains.
- Process reward models: no cost–benefit analysis of sparse vs dense process feedback, label granularity, or annotator instruction protocols; unclear labeling strategies that maximize reasoning gains per dollar.
- Online preference optimization (e.g., Online DPO) lacks safety analyses: how to prevent reward drift, catastrophic forgetting, or preference oscillations during continual updates.
- Test-time compute allocation is not operationalized: no optimal stopping or adaptive “think budget” policies that trade off latency vs accuracy under service-level objectives.
- vLLM, speculative decoding, and KV-cache policies are not evaluated for RL-tuned reasoning models; unknown impacts on correctness, calibration, and verification rates.
- Mixture-of-Experts routing for agent skill specialization is not addressed: open issues include interference between skills, stability of routers under tool-use distributions, and compute-aware routing policies.
- Memory architectures for agents (working/episodic/semantic) are promised but not validated: missing quantitative retention curves, retrieval precision/latency trade-offs, and interference/forgetting measurements over long horizons.
- Tool-use security for MCP is not formalized: no threat model, sandboxing guarantees, or policy languages with verifiable enforcement for filesystem, network, and code-execution tools.
- A2A protocol interoperability and reliability are open: no benchmarks for agent-to-agent negotiation, deadlock/livelock detection, or message-level consistency under partial failure.
- Evaluation with LLM-as-Judge lacks calibration audits: no bias assessments, adversarial robustness tests, or protocols for cross-model triangulation and human arbitration fallback.
- Benchmark contamination and drift are acknowledged but unresolved: no standardized contamination detection pipeline, dataset versioning scheme, or attack-resistant agentic environments with hidden test states.
- Absence of domain-specific pipelines (intentional omission) leaves open how to satisfy regulatory, privacy, and data-governance requirements in RLHF/DPO pipelines for healthcare, finance, and legal settings.
- Personalization is omitted, leaving unanswered how to safely do user-level adaptation (on-device RLHF/bandits) without privacy leakage, fairness harms, or preference overfitting.
- Multimodal agents are out of scope, but critical open questions remain about how vision/audio inputs alter orchestration, reward design, and tool-use reliability in real-world settings.
- Data curation for SFT/RM is not specified: no auditing tools for label noise, formatting artifacts, or prompt leakage; no curricula that balance instruction coverage with reasoning difficulty.
- Hallucination under tool calls remains unaddressed: no verified execution pathways, schema validators, or post-conditions that guarantee factuality/consistency in tool-augmented outputs.
- Lack of formal verification for autonomous agents: no runtime monitors, contracts, or provable safety envelopes for long-horizon plans interacting with external systems.
- Economic and environmental costs are not analyzed: missing carbon/energy accounting for training and agentic inference; no cost–quality frontiers to inform deployment choices.
- Licensing and provenance practices are unspecified: no mechanisms to ensure attribution, provenance tracking, or derivative-content compliance within CC BY-SA constraints.
- Orchestration complexity vs reliability is a hypothesis (“simplicity principle”) without evidence: no experiments that quantify failure rates as a function of graph depth, branching, or parallelism.
- Cross-lingual performance with high-fertility languages (e.g., agglutinative morphology) is not evaluated; open: tokenizer adaptations or char/subchar hybrids that preserve reasoning while controlling context length.
- Robustness of positional encodings (e.g., RoPE) at 128k+ contexts is not examined: open methods for position extrapolation, chunk-merge strategies, and degradation detection in long-horizon tasks.
Practical Applications
Below is an overview of practical applications grounded in the guide’s methods and system patterns (LLM foundations, efficient training, RLHF/DPO/GRPO alignment, reasoning RL, RAG/memory/orchestration, MCP tool-use, A2A inter-agent communication, vLLM/FSDP/LoRA/quantization), organized by deployment horizon.
Immediate Applications
- Sector: Software/IT — Autonomous code maintenance on constrained scopes (e.g., bug triage and small PRs)
- What: Agents fix well-scoped issues, write tests, and submit PRs against predefined repositories.
- Methods/stack: ReAct or Plan-and-Execute; pass@k and unit tests as verifiable rewards; SFT + DPO/ORPO for style and safety; RAG over codebase; memory for issue context.
- Tools/workflows: LangGraph/CrewAI/OpenAI Agents SDK; MCP tools for Git, CI, package managers; vLLM for high-throughput inference.
- Assumptions/dependencies: Robust test harnesses; sandboxed execution; repo/API permissions; human-in-the-loop code review.
- Sector: Customer Support/SaaS/Retail — Agentic Tier‑1 support with knowledge-base grounding
- What: Resolve FAQs, billing queries, and account changes; escalate with summaries.
- Methods/stack: RAG (hybrid search + reranking); instruction tuning + DPO; memory for session state; LLM-as-Judge spot checks.
- Tools/workflows: MCP connectors to CRM, ticketing, billing; guardrails for PII; structured prompts with role tokens.
- Assumptions/dependencies: Up-to-date KB indexing; privacy controls; explicit EOS handling to prevent runaway responses.
- Sector: Finance/Legal — Policy- and compliance-aware document analysis and drafting
- What: Draft memos and summaries, extract obligations/risks, generate checklists from policy libraries.
- Methods/stack: RAG with domain schemas; SFT on format; preference optimization (DPO/KTO) for tone/safety; evaluation with ELO-style model comparisons.
- Tools/workflows: MCP to document stores and DMS; prompt templates for structured outputs; contamination detection for benchmark hygiene.
- Assumptions/dependencies: Human review for regulated outputs; auditable prompts; redaction pipelines.
- Sector: IT Operations/DevOps — Incident triage and runbook automation
- What: Triage alerts, propose mitigations, execute safe runbook steps (e.g., restart service, rollback).
- Methods/stack: ReAct with tool-use; trajectory logging for later RL; reward signals via success/failure of checks.
- Tools/workflows: MCP tools for observability (logs, metrics), ticketing (Jira/ServiceNow), deployment (CI/CD).
- Assumptions/dependencies: Role-based access; sandboxed commands; rollback strategies; latency budgets.
- Sector: Business Intelligence/Data — Natural language to SQL with execution safety
- What: Generate/validate SQL, run queries, and produce annotated dashboards.
- Methods/stack: Tool-augmented decoding; self-verification passes; DPO fine-tuning on preferred query styles.
- Tools/workflows: MCP connectors for DBs; dry-run and EXPLAIN checks; result caching; vLLM for concurrency.
- Assumptions/dependencies: Schema documentation; row-level security; cost controls.
- Sector: Enterprise Knowledge/HR — Organization-wide semantic search and synthesis
- What: Cross-repository Q&A over docs, tickets, wikis, emails; produce action summaries.
- Methods/stack: Production RAG (chunking, hybrid retrieval, reranking); memory for user preferences; structured templates.
- Tools/workflows: Indexing pipelines; access control-aware retrieval; dashboards with streaming responses.
- Assumptions/dependencies: ACL alignment between index and tools; frequent reindex; data retention policies.
- Sector: Education — Personalized tutoring and practice generation
- What: Explain concepts, generate practice problems and hints, track progress via episodic memory.
- Methods/stack: SFT + preference tuning for pedagogy; memory systems (working/episodic); evaluation with rubric-based LLM-as-Judge.
- Tools/workflows: Agentic UI for hints/steps; content filters; per-student progress prompts.
- Assumptions/dependencies: Curriculum alignment; misuse safeguards; parental/teacher oversight.
- Sector: Research/Academia — Literature review and synthesis assistants
- What: Retrieve/cite papers, summarize methods/results, maintain research notebooks.
- Methods/stack: RAG over bibliographic indices; process rewards via citation checks; contamination detection.
- Tools/workflows: MCP tools for scholarly APIs (Crossref/ArXiv); memory for topic threads; export to LaTeX/Markdown.
- Assumptions/dependencies: Reliable citation extraction; source-linked outputs; deduplication.
- Sector: Security — Alert enrichment and triage copilot
- What: Enrich IOCs, classify alerts, propose investigative steps, open tickets.
- Methods/stack: ReAct with tool-calls (threat intel, sandbox lookups); preference tuning for false-positive reduction.
- Tools/workflows: MCP to SIEM/SOAR; structured outputs; human approval for actions.
- Assumptions/dependencies: Data sensitivity controls; vendor API quotas; audit logs.
- Sector: Platform/ML Ops — Cost/performance optimization of LLM services
- What: Reduce training/inference costs without quality loss.
- Methods/stack: LoRA/QLoRA, quantization, distillation; vLLM for throughput; FSDP/ZeRO for scale.
- Tools/workflows: Canary and A/B eval with ELO scoring; regression dashboards.
- Assumptions/dependencies: Quality acceptance thresholds; hardware compatibility; rollback plans.
- Sector: Cross-industry Policy/Procurement — Vendor-agnostic tool-use via MCP
- What: Standardize tool invocation to reduce lock-in and improve security reviews.
- Methods/stack: Adopt MCP’s tool/resource/prompt primitives; consistent special token handling.
- Tools/workflows: Shared tool catalogs; policy templates for tool permissions; red-team evaluations.
- Assumptions/dependencies: Vendor support for MCP; internal security sign-off; change management.
- Sector: Personal Productivity/Daily Life — Email/calendar/task automation
- What: Draft replies, schedule meetings, create task plans based on inbox content.
- Methods/stack: Orchestration with memory; structured prompts; preference tuning for tone.
- Tools/workflows: MCP connectors for email/calendar/todo; human-in-the-loop approvals; agentic UI with streaming.
- Assumptions/dependencies: OAuth scopes; privacy controls; rate limits.
Long-Term Applications
- Sector: Enterprise — Autonomous, multi-agent workflows with A2A marketplaces
- What: Teams of agents (procurement, legal, finance) negotiate and coordinate end-to-end processes.
- Methods/stack: A2A protocol (Agent Cards, task lifecycle, streaming); debate/marketplace coordination; long-horizon trajectory RL.
- Dependencies: Robust safety/eval frameworks; standardized interop; governance policies for autonomy and spend caps.
- Sector: Software Engineering — Self-managing delivery pipelines
- What: Agents plan features, implement, test, and deploy with minimal supervision.
- Methods/stack: Reasoning RL (process reward models, MCTS), test-time compute scaling; trajectory-level rewards from CI/CD outcomes.
- Dependencies: Verifiable reward signals, secure tool execution, extensive unit/integration test coverage.
- Sector: Science/Drug Discovery — Agentic research pipelines
- What: Hypothesis generation, protocol drafting, result synthesis across heterogeneous tools.
- Methods/stack: Tool-use via MCP; process rewards for methodological correctness; multi-agent critique/debate.
- Dependencies: Lab/LIMS integration; ground-truth feedback loops; domain benchmarks and safety oversight.
- Sector: Public Policy/Governance — Regulation and audit of agentic systems
- What: Frameworks for audit trails, memory governance, tool permissioning, and accountability.
- Methods/stack: Standardized Agent Cards; evaluation protocols (LLM-as-Judge + human panels); red-teaming harnesses.
- Dependencies: Regulatory consensus; standardized logging formats; third-party certification ecosystem.
- Sector: Healthcare/Finance (Safety-critical) — Verified reasoning assistants
- What: Assist in decision support with traceable, verifiable reasoning and tool-grounded evidence.
- Methods/stack: Process reward models; chain-of-thought with self-verification; strict tool scoping via MCP.
- Dependencies: Domain-specific data access, rigorous validation studies, regulatory approval, privacy-by-design memory policies.
- Sector: Platform/Tooling — Mature MCP ecosystems and third-party skill libraries
- What: Industry-wide catalogs of secure, composable tools and prompts.
- Methods/stack: MCP standardization; capability abstraction and signatures; formal tool schemas for zero-shot generalization.
- Dependencies: Broad vendor adoption; security certifications; versioning and deprecation policies.
- Sector: HCI/Productivity — Agentic UI as a first-class interaction paradigm
- What: Canvas-driven, streaming UIs with human-in-the-loop controls embedded across apps/OS.
- Methods/stack: Tool visualization, reversible actions, evaluation-driven orchestration.
- Dependencies: UX standards, user trust models, recovery patterns for failures.
- Sector: Education — Longitudinal AI mentors and curricula planners
- What: Multi-year personalization using episodic/semantic memory and mastery models.
- Methods/stack: Memory architectures; preference optimization for motivational strategies; agentic evaluation methods.
- Dependencies: Data guardianship; equitable outcomes research; integration with LMS/SIS.
- Sector: Energy/Industrial Ops — API-driven supervisory agents for digital control surfaces
- What: Multi-agent optimization of schedules, maintenance, and markets via software interfaces (no direct sensor control).
- Methods/stack: Planning/orchestration with verifiable objectives; A2A coordination; rule-based guardrails.
- Dependencies: Safe API abstractions; human override; domain simulators for pre-deployment RL.
- Sector: Cross-domain AI Training — Trajectory-level RL for generalist agents
- What: Train agents on end-to-end tasks using dense/structured process rewards beyond simple preferences.
- Methods/stack: GRPO/Online DPO; process reward models; best-of-N and test-time compute.
- Dependencies: High-quality interaction logs, scalable training infrastructure, reward hacking mitigation.
- Sector: Standards/Interoperability — Inter-organizational agent-to-agent protocols
- What: Agents securely transact across firms (e.g., supply chains) using shared A2A and identity standards.
- Methods/stack: Agent identity, capability attestations, signed tool calls, rate-limited contracts.
- Dependencies: Security standards, legal frameworks for automated contracting, dispute resolution mechanisms.
Notes on feasibility across all applications:
- Data quality and retrieval are bottlenecks; production RAG (chunking, hybrid retrieval, reranking) is a prerequisite for reliability.
- Alignment and evaluation (RLHF/DPO variants, LLM-as-Judge with bias checks, contamination detection) are required to control behavior and measure gains.
- Systems constraints (GPU budgets, quantization accuracy, vLLM throughput, KV-cache policies) determine cost-effectiveness.
- Safety relies on strict tool permissioning, sandboxing, audit trails, and EOS/token handling to prevent unbounded generations.
- Many domain-specific deployments (healthcare/legal/finance) additionally depend on regulatory compliance, human oversight, and rigorous validation.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient-based updates to improve training stability in deep networks. "Chapter 1 --- LLM Architecture and Optimization: Transformer internals (self-attention, multi-head attention, RoPE, GQA), Flash Attention, optimization methods (AdamW, learning rate schedules, gradient clipping), mixed precision, LoRA/QLoRA, quantization, knowledge distillation, and Mixture of Experts."
- Agent Cards: Structured descriptors of agents’ capabilities and interfaces used for standardized inter-agent communication. "A2A Communication: Google's Agent-to-Agent protocol --- Agent Cards, task lifecycle, streaming, enterprise patterns."
- Agent-to-Agent (A2A): A protocol enabling direct communication and coordination between autonomous agents. "Agent-to-Agent (A2A) enabled inter-agent communication"
- Agentic AI: AI systems that can autonomously plan, reason, and act using tools and memory within orchestrated environments. "Agentic AI (2025--present) --- The convergence point: LLMs with reasoning capabilities, equipped with standardized tool access (MCP), inter-agent communication (A2A), persistent memory, and sophisticated orchestration frameworks."
- autoregressive: A generation paradigm where the model produces tokens sequentially, conditioning on previously generated tokens. "the autoregressive loop (append token to input)"
- Bellman equations: Recursive relationships defining the value of states or actions in Markov decision processes, central to dynamic programming in RL. "MDPs, Bellman equations, TD learning, Q-learning, policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- Best-of-N: A selection strategy where multiple candidate outputs are generated and the best is chosen, often used in preference optimization. "preference optimization variants (Online DPO, KTO, IPO, ORPO, SimPO, Best-of-N)."
- Bradley--Terry: A probabilistic model for pairwise comparisons used to train reward or preference models from human judgements. "Reward model training (Bradley--Terry, scaling laws, reward hacking) and SFT best practices"
- Byte-level BPE: A tokenization variant that operates on raw bytes, preventing unknown tokens and improving robustness across languages and scripts. "Byte-level BPE & GPT-2~\cite{radford2019gpt2}+ & BPE on raw bytes (no unknown tokens possible); 256 base vocab"
- Byte-Pair Encoding (BPE): A subword tokenization algorithm that iteratively merges frequent symbol pairs to build a compact, open-vocabulary lexicon. "BPE~\cite{sennrich2016bpe} is the dominant tokenization algorithm used by GPT, Llama, Mistral, and most modern LLMs."
- causal mask: A masking scheme in decoder self-attention that prevents positions from attending to future tokens to preserve autoregressive causality. "To prevent the model from ``seeing the future,'' the self-attention in the decoder uses a causal mask:"
- chain-of-thought: A multi-step reasoning style in which models explicitly generate intermediate steps before answers. "how RL discovers chain-of-thought, MCTS, process reward models, and test-time compute scaling."
- contamination detection: Methods to identify whether evaluation data has leaked into training sets, safeguarding benchmark validity. "Chapter 14 --- LLM Evaluation: Metrics (perplexity, pass@k, ELO), LLM-as-Judge patterns, contamination detection, benchmark suites, and agentic evaluation methodology."
- cross-attention: An attention mechanism where the decoder attends to encoder outputs (or another modality), enabling sequence-to-sequence conditioning. "After masked self-attention, each decoder layer applies cross-attention where the decoder attends to the encoder’s output representations."
- decoupled training: A systems approach that separates major training components (e.g., data, optimization, RL loops) to improve scalability and fault isolation. "System architecture at scale (decoupled training, fault tolerance, GPU allocation)"
- DeepSpeed ZeRO: A memory-optimization technique for distributed training that shards optimizer states, gradients, and parameters across devices. "distributed training (FSDP, DeepSpeed ZeRO, tensor/pipeline parallelism)"
- Direct Preference Optimization (DPO): A preference-based alignment method that eliminates an explicit reward model by directly optimizing a supervised objective from pairwise preferences. "DPO~\cite{rafailov2023direct} collapsed the reward model and RL loop into a single supervised loss, democratizing alignment."
- distributional hypothesis: The linguistic principle that words occurring in similar contexts have similar meanings, underpinning learned embeddings. "This is the distributional hypothesis: ``you shall know a word by the company it keeps''"
- ELO: A rating system adapted to compare model performance via pairwise matches or judgements. "Metrics (perplexity, pass@k, ELO), LLM-as-Judge patterns, contamination detection, benchmark suites, and agentic evaluation methodology."
- embedding table: A learnable matrix mapping discrete token IDs to dense vector representations used as model inputs. "The embedding table is learned end-to-end with the rest of the model."
- encoder-decoder: A sequence-to-sequence transformer architecture with a bidirectional encoder and an autoregressive decoder connected via cross-attention. "The Transformer was originally introduced as an encoder-decoder architecture for sequence-to-sequence tasks (machine translation, summarization)."
- episodic memory: An agent memory type storing experience-level events or interactions over time for future retrieval and reasoning. "Working, episodic, semantic, and procedural memory for persistent agent knowledge."
- Feed-Forward Network (FFN): The position-wise multi-layer perceptron sublayer in transformer blocks that transforms token representations between attention layers. "Feed-Forward Network + Residual + LayerNorm"
- fertility (tokenization): The average number of tokens per word, often used to assess tokenizer efficiency across languages. "Fertility: Measure tokens-per-word across languages."
- few-shot learning: The capability of LLMs to perform tasks from a few in-context examples without explicit gradient updates. "GPT-2 and GPT-3 demonstrated that decoder-only transformers, scaled sufficiently, become capable few-shot learners."
- Flash Attention: A memory-efficient attention algorithm that reorders computations to reduce memory traffic and improve training speed. "Flash Attention~\cite{dao2022flashattention} made training 2--4 faster by eliminating memory bottlenecks."
- FSDP (Fully Sharded Data Parallel): A distributed training strategy that shards parameters, gradients, and optimizer states across devices to fit larger models. "distributed training (FSDP, tensor/pipeline parallelism)"
- GAE (Generalized Advantage Estimation): A variance-reducing estimator for policy gradients that balances bias and variance in advantage computation. "policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- GAIA: An evaluation environment/benchmark for agentic capability in complex tasks. "WebArena, SWE-bench, OSWorld, GAIA --- evaluation environments for agentic capability."
- GQA (Grouped Query Attention): An attention variant that shares key-value projections across groups of queries to reduce memory and compute. "Transformer internals (self-attention, multi-head attention, RoPE, GQA)"
- GRPO: A family of preference/RL optimization methods for aligning LLMs using graded or ranked preferences. "Variants proliferated: KTO, IPO, ORPO, GRPO"
- IPO: A preference optimization method (Implicit Preference Optimization) used for aligning LLMs without explicit reward models. "Variants proliferated: KTO, IPO, ORPO, GRPO"
- KL (Kullback–Leibler) divergence: A measure of distributional difference often used as a regularizer to keep a policy close to a reference model. "mismatches corrupt KL computation."
- KTO: A preference optimization approach (e.g., Keep The Optimal/Kernelized Teacher Optimization variants) for aligning models via comparisons. "Variants proliferated: KTO, IPO, ORPO, GRPO"
- KV cache: Cached key-value tensors from prior tokens used to accelerate autoregressive inference by avoiding recomputation. "When not thinking about gradient flows and KV caches"
- LayerNorm: A normalization technique applied per token to stabilize training by normalizing hidden activations. "Each sub-layer (attention, FFN) is preceded by LayerNorm and followed by a residual addition"
- LLM-as-Judge: An evaluation pattern in which models are used to assess outputs of other models, often with calibration strategies. "Chapter 14 --- LLM Evaluation: Metrics (perplexity, pass@k, ELO), LLM-as-Judge patterns, contamination detection, benchmark suites, and agentic evaluation methodology."
- LLM Compiler: An orchestration pattern where the model performs planning and compilation of steps before execution to improve reliability. "Orchestration: ReAct, Plan-and-Execute, LLM Compiler, reflexion patterns, context management, and harness design."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into weight matrices to adapt large models cheaply. "LoRA~\cite{hu2022lora} enabled fine-tuning 70B+ models on a single node."
- MCTS (Monte Carlo Tree Search): A search algorithm combining stochastic rollouts and tree expansion, used to enhance reasoning and planning. "how RL discovers chain-of-thought, MCTS, process reward models, and test-time compute scaling."
- MCP (Model Context Protocol): A standardized protocol for tool access enabling models to interact with external resources and services. "the Model Context Protocol (MCP) standardized tool access"
- Mixture-of-Experts (MoE): An architecture that routes tokens through a subset of specialized experts to increase capacity without proportionally increasing compute. "Mixture-of-Experts (MoE) decoupled model capacity from compute cost."
- MDPs (Markov Decision Processes): Formal frameworks for sequential decision-making under uncertainty, defining states, actions, transitions, and rewards. "MDPs, Bellman equations, TD learning, Q-learning, policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- mixed precision: Training with lower-precision number formats (e.g., FP16/BF16) to reduce memory and improve throughput while maintaining accuracy. "optimization methods (AdamW, learning rate schedules, gradient clipping), mixed precision, LoRA/QLoRA, quantization, knowledge distillation"
- mode collapse: A failure mode in generative training where the model produces low-diversity outputs that overly exploit rewards or training signals. "debug reward hacking and mode collapse"
- Multi-Head Self-Attention: An attention mechanism with multiple parallel heads that allows the model to focus on different representation subspaces. "The encoder processes the entire input sequence bidirectionally --- each token attends to all other tokens (no causal mask). This produces a rich contextual representation ... Multi-Head Self-Attention → Add & Norm → FFN → Add & Norm"
- NVLink: A high-bandwidth interconnect linking GPUs within a node to accelerate distributed training and inference. "GPU architecture (A100/H100/B200), memory hierarchies, NVLink/NVSwitch, distributed training (FSDP, DeepSpeed ZeRO, tensor/pipeline parallelism), and vLLM for high-throughput inference."
- NVSwitch: A switching fabric enabling all-to-all high-bandwidth GPU connectivity within a server. "GPU architecture (A100/H100/B200), memory hierarchies, NVLink/NVSwitch, distributed training (FSDP, DeepSpeed ZeRO, tensor/pipeline parallelism), and vLLM for high-throughput inference."
- Online DPO: A variant of Direct Preference Optimization that updates from preferences collected during training rather than a fixed dataset. "preference optimization variants (Online DPO, KTO, IPO, ORPO, SimPO, Best-of-N)."
- ORPO: A preference optimization method (e.g., Odds Ratio Preference Optimization) for aligning models with pairwise judgements. "Variants proliferated: KTO, IPO, ORPO, GRPO"
- pass@k: A coding evaluation metric measuring the probability that at least one of k generated samples passes unit tests. "Metrics (perplexity, pass@k, ELO), LLM-as-Judge patterns, contamination detection, benchmark suites, and agentic evaluation methodology."
- pipeline parallelism: A distributed training technique that splits model layers across devices and pipelines microbatches to maximize utilization. "distributed training (FSDP, DeepSpeed ZeRO, tensor/pipeline parallelism)"
- Plan-and-Execute: An agentic orchestration pattern where planning is separated from execution to improve task reliability and modularity. "Orchestration: ReAct, Plan-and-Execute, LLM Compiler, reflexion patterns, context management, and harness design."
- policy gradients (REINFORCE): An RL framework that estimates gradients of expected returns with respect to policy parameters; REINFORCE is a classic Monte Carlo method. "MDPs, Bellman equations, TD learning, Q-learning, policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- PPO (Proximal Policy Optimization): A stable policy-gradient algorithm that constrains updates via clipped objectives or KL penalties. "Here you learn how to align, improve, and fine-tune LLMs --- from full mathematical derivations to working code. Chapters 4--8: Every major RL/preference algorithm with math, intuition, and TRL code --- PPO, DPO, GRPO, and preference optimization variants"
- Post-Norm: A transformer variant where LayerNorm is applied after residual addition, as in the original Transformer, often requiring warmup. "Note: the original work uses Post-Norm (LayerNorm applied after the residual addition: LN(x + SubLayer(x))), unlike modern LLMs which use Pre-Norm."
- Pre-Norm: A transformer variant where LayerNorm is applied before each sublayer, improving training stability in deep models. "Decoder-only Transformer block (GPT-style, Pre-Norm variant). Each sub-layer (attention, FFN) is preceded by LayerNorm and followed by a residual addition"
- process reward models: Reward models that evaluate intermediate reasoning steps or processes rather than only final outputs. "how RL discovers chain-of-thought, MCTS, process reward models, and test-time compute scaling."
- Q-learning: An off-policy RL algorithm that learns action-value functions via temporal-difference updates. "MDPs, Bellman equations, TD learning, Q-learning, policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- QLoRA: A memory-efficient fine-tuning approach that combines quantization with LoRA adapters to fit large models on limited hardware. "Train and fine-tune efficiently --- LoRA/QLoRA, quantization, knowledge distillation, optimizer selection, and learning rate scheduling."
- quantization: The compression of model parameters and activations to lower-precision formats to reduce memory and accelerate inference. "Train and fine-tune efficiently --- LoRA/QLoRA, quantization, knowledge distillation, optimizer selection, and learning rate scheduling."
- RAG (Retrieval-Augmented Generation): A technique that augments generation with retrieved external knowledge to improve factuality and grounding. "Chapter 16 --- RAG: Retrieval methods, chunking, embedding models, hybrid search, reranking, and production architectures."
- ReAct: An agentic pattern that interleaves reasoning and actions (tool calls) during task execution. "Orchestration: ReAct, Plan-and-Execute, LLM Compiler, reflexion patterns, context management, and harness design."
- reflexion patterns: Orchestration strategies where agents reflect on their outputs to self-correct and improve performance iteratively. "Orchestration: ReAct, Plan-and-Execute, LLM Compiler, reflexion patterns, context management, and harness design."
- REINFORCE: A Monte Carlo policy gradient algorithm that updates parameters to increase the likelihood of sampled high-reward trajectories. "policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- residual connections: Skip connections that add a sublayer’s input to its output, aiding gradient flow and training of deep networks. "gray lines show residual connections bypassing each sub-layer."
- reward hacking: Exploiting weaknesses in reward definitions or models to achieve high scores with undesirable behaviors. "Reward model training (Bradley--Terry, scaling laws, reward hacking)"
- reward model: A learned model that scores model outputs according to human preferences or task-specific criteria, used in RLHF and related methods. "Reward model training (Bradley--Terry, scaling laws, reward hacking)"
- RoPE (Rotary Positional Embeddings): A positional encoding method that imparts relative position information by rotating token representations in embedding space. "Transformer internals (self-attention, multi-head attention, RoPE, GQA)"
- self-attention: A mechanism allowing each token to attend to other tokens in the sequence to build contextualized representations. "The transformer stack processes all embeddings in parallel, using self-attention to let each position ``read'' from all other positions."
- SimPO: A preference optimization technique involving similarity or simple preference objectives for aligning LLMs. "preference optimization variants (Online DPO, KTO, IPO, ORPO, SimPO, Best-of-N)."
- sinusoidal positional encodings: Fixed, non-learned encodings added to embeddings to inject position information in the original Transformer. "Input: Token embeddings + sinusoidal positional encodings"
- SFT (Supervised Fine-Tuning): Fine-tuning a base model on human-written instruction-response pairs to align behavior before RL-based alignment. "Reward model training (Bradley--Terry, scaling laws, reward hacking) and SFT best practices"
- TD learning (Temporal Difference learning): A class of RL methods that learn value functions by bootstrapping from estimates at subsequent time steps. "MDPs, Bellman equations, TD learning, Q-learning, policy gradients (REINFORCE), actor-critic methods, GAE --- the algorithmic toolkit that underpins Part II."
- tensor/pipeline parallelism: Distributed training approaches that split model computations across devices by tensors (intra-layer) and by layers (inter-layer). "distributed training (FSDP, DeepSpeed ZeRO, tensor/pipeline parallelism)"
- teacher forcing: A training technique for autoregressive models where the ground-truth previous tokens are fed during training to enable parallelization. "During training, the decoder processes the entire target sequence in parallel (teacher forcing), but each position must only attend to previous positions"
- test-time compute scaling: Increasing computation during inference (e.g., more samples, deeper reasoning) to improve output quality without retraining. "how RL discovers chain-of-thought, MCTS, process reward models, and test-time compute scaling."
- trajectory-level RL: Reinforcement learning that evaluates and optimizes entire sequences of actions/outputs rather than token-level rewards. "LLM agentic training --- how to train agents end-to-end with trajectory-level RL."
- Unigram LM: A tokenization method that starts with a large vocabulary and prunes tokens by their contribution to corpus likelihood. "Unigram LM & SentencePiece (T5~\cite{raffel2020t5}, XLNet~\cite{yang2019xlnet}) & Top-down: start with large vocab, prune by likelihood impact"
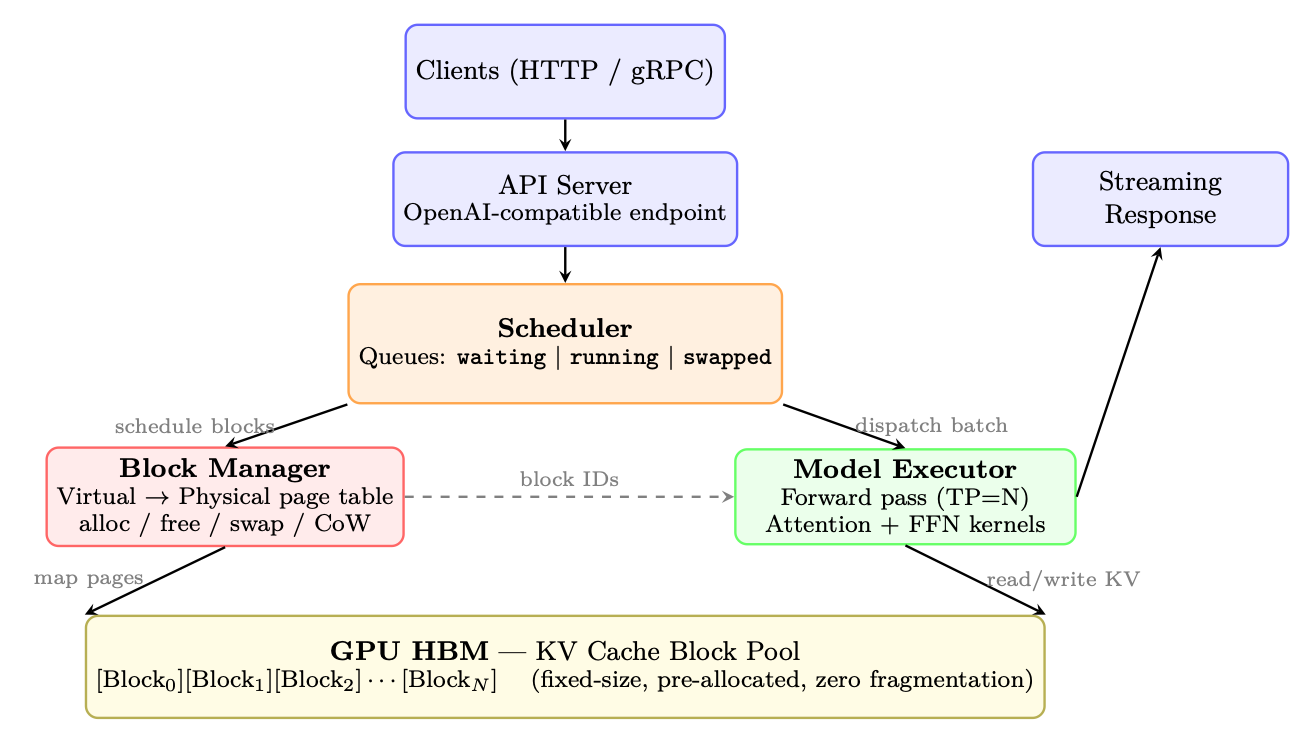
- vLLM: A high-throughput LLM inference engine optimized for efficient memory management and parallelism. "Inference engines like vLLM brought throughput within reach of real-time applications."
- weight tying: Sharing parameters between the input embedding matrix and the output projection to reduce parameters and improve symmetry. "Many models share the embedding matrix with the output projection head: $W_{\text{head} = \mathbf{E}^T$. This saves parameters and creates a symmetric encode-decode structure."
- WordPiece: A subword tokenization algorithm that builds a vocabulary by maximizing the likelihood of training data, used in BERT-family models. "WordPiece & BERT~\cite{devlin2019bert}, DistilBERT~\cite{sanh2019distilbert} & Similar to BPE but maximizes likelihood of training data"
Collections
Sign up for free to add this paper to one or more collections.

