Tapered Language Models
Abstract: Modern LLMs, including transformer, recurrent, and memory-based variants, share a common chassis: a stack of identical layers in which parameters are allocated uniformly across depth. This is a default inherited from the original transformer and largely unchanged since, yet a growing body of evidence suggests that layers contribute non-uniformly to the final output, with later layers refining the residual stream rather than transforming it. We ask whether parameter capacity should reflect this asymmetry. Our controlled experiment shows that, under a fixed budget, allocating more capacity to earlier layers and less to later layers improves perplexity over a uniform-width baseline, while the reverse allocation hurts. Building on this result, we introduce Tapered LLMs (TLMs), an architectural principle in which a parameter-bearing component is monotonically tapered across depth under a fixed total budget. MLPs are the natural site for this instantiation: they dominate parameter count across all modern LM families and expose width as a single, clean axis of variation. Across three model scales and four architectures (Transformer, Gated Attention, Hope-attention, and Titans), tapering MLP width via a smooth cosine schedule consistently improves perplexity and downstream benchmark performance over uniform baselines, at no additional parameter or compute cost. These findings establish depth-aware capacity allocation as a simple, architecture-agnostic axis of LLM design, a free lever hidden in plain sight.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Tapered LLMs” in Simple Terms
Overview
This paper asks a surprisingly simple question about how we build LLMs (the AI that writes and understands text). Most models are made of many “layers,” and today we usually give each layer the same amount of “capacity” (think: the same number of knobs and levers to learn from data). The authors show that this one-size-fits-all approach isn’t ideal. They propose “Tapered LLMs” (TLMs): give earlier layers more capacity and later layers less—like a funnel that’s wide at the start and narrower at the end. This change improves the model’s accuracy without adding any extra cost.
What questions did the researchers ask?
They focused on three easy-to-understand questions:
- Do all layers in a LLM contribute equally, or are some layers more important than others?
- If early layers often do more “original” work and later layers mainly polish it, should we give early layers more capacity and later layers less?
- Can we do this in a smooth, fair way—keeping the total size and compute of the model the same—so it’s a free upgrade?
How did they study it? (Methods in everyday language)
Think of a LLM as an assembly line with L layers. Each layer has two main parts:
- A “token-mixing” part (like attention) that lets words see and influence each other.
- An MLP (a small feed-forward network) that transforms the information. The MLP’s “width” is how many channels it has to think with.
Today, every layer gets the same MLP width. The authors tried something different:
- Front-load capacity: make early layers wider and later layers narrower—but keep the total number of parameters and compute the same (like using the same number of LEGO bricks, just arranged differently).
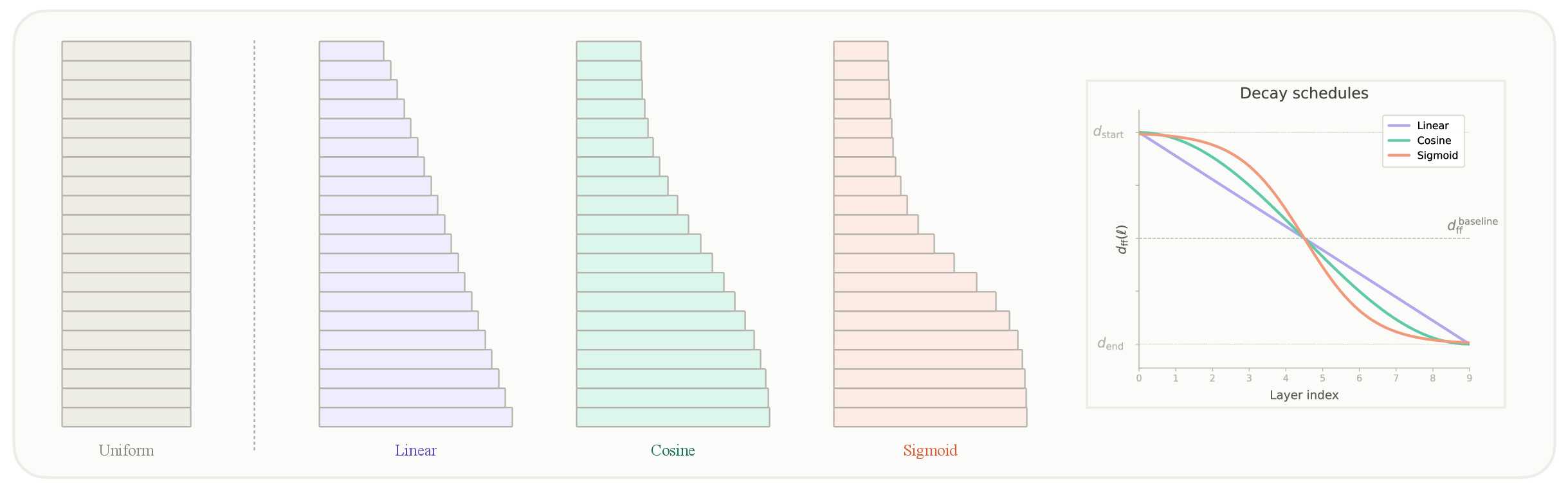
- They tested several “tapering” shapes for the MLP widths across depth:
- Linear: shrink at a steady pace.
- Sigmoid: stay wide for a while, then shrink fast midway.
- Cosine: shrink gently at the start and end, most in the middle (smooth “half-wave” shape).
They trained and evaluated:
- Different model sizes (about 440M, 760M, and 1.3B parameters).
- Different architectures (standard Transformers, Gated Attention, Hope-attention, and Titans—these differ mainly in how they mix token information).
- Same total parameters and FLOPs (compute) for fair comparisons.
They measured:
- Perplexity: a “how-confused-am-I?” score for word prediction. Lower is better—like fewer wrong guesses in a word-guessing game.
- Benchmark accuracy: scores on reasoning and language tests (e.g., LAMBADA, PIQA, HellaSwag, ARC, etc.).
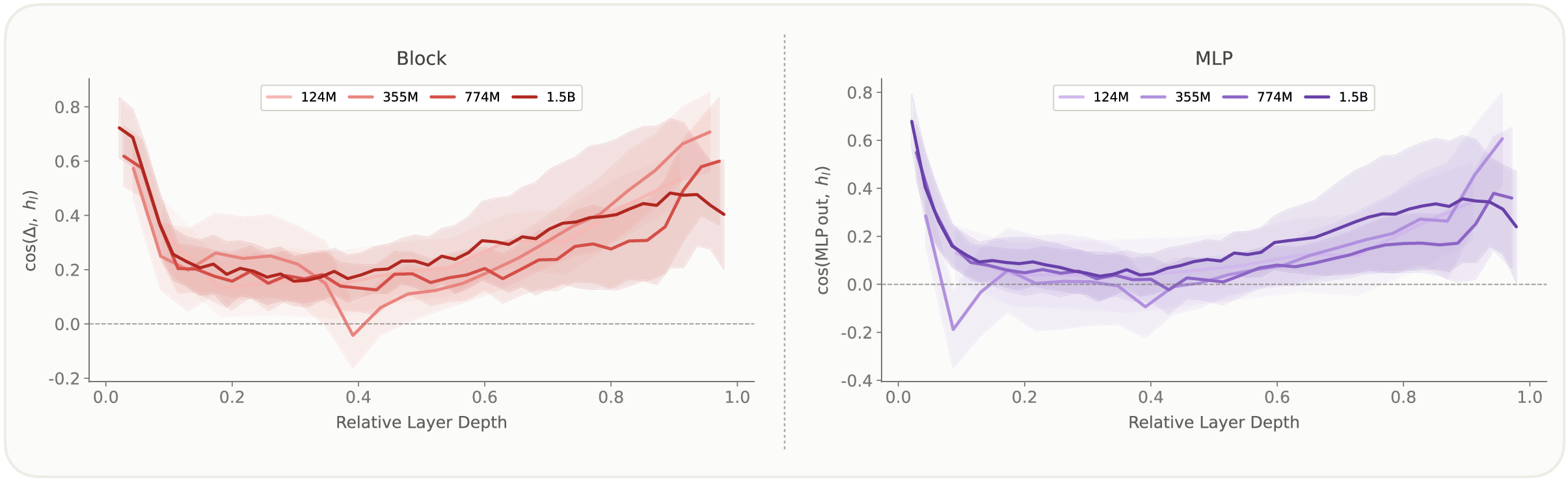
They also looked under the hood to ask “why does this work?” by measuring how “new” each layer’s contribution is. They checked how aligned a layer’s output is with what’s already there (the “residual stream,” which is like a running summary of the model’s current understanding). If a layer’s output lines up with what’s already present, it’s adding less new information.
What did they find?
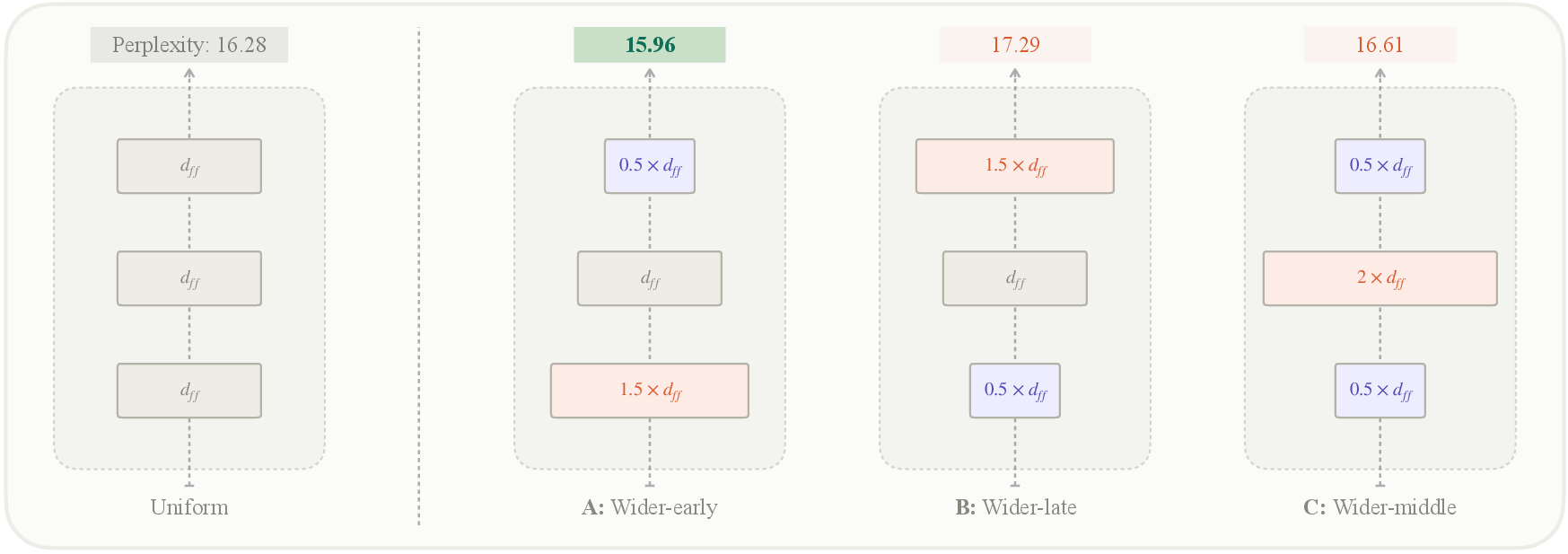
- Front-loading capacity helps. Putting more MLP capacity in early layers and less in later layers reduced perplexity (fewer wrong guesses).
- Doing the reverse (more in later layers, less in earlier ones) hurt performance.
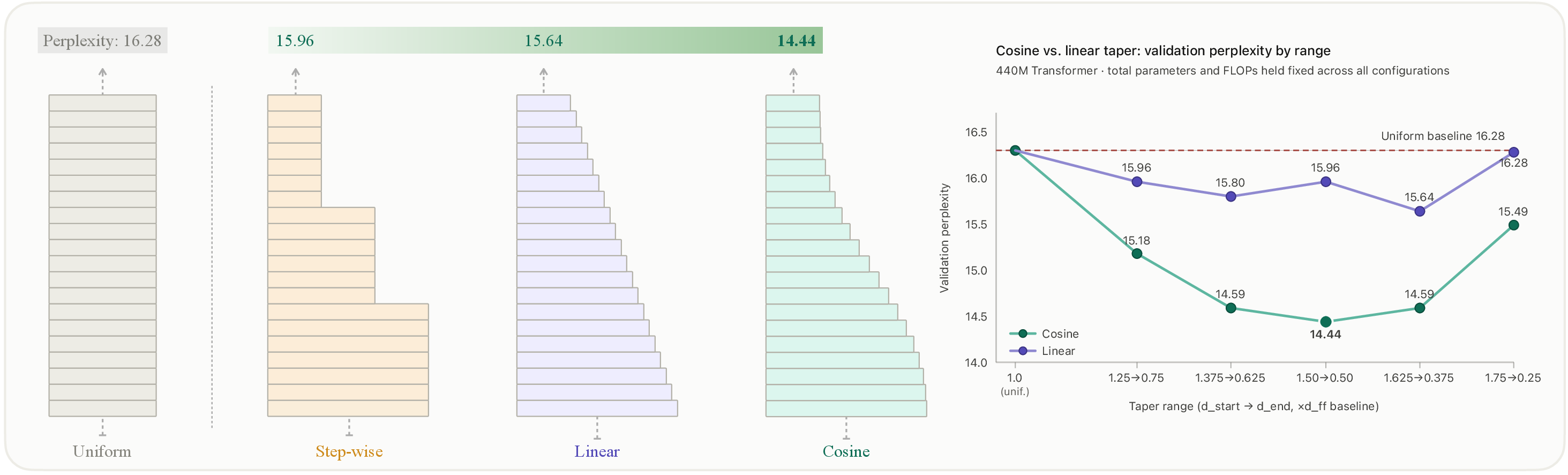
- A smooth cosine taper—wide early, gently shrinking to narrower late—worked best across the board.
- In one clear result (440M Transformer), cosine tapering improved validation perplexity from 16.28 to 14.44 without extra parameters or compute.
- This improvement held across:
- Four very different architectures (not just standard Transformers).
- Multiple model sizes (from hundreds of millions to over a billion parameters).
- Multiple tasks (both language modeling and commonsense reasoning).
- They observed a U-shaped curve when testing how aggressively to taper. Too little or too much tapering was worse; an intermediate setting (about 1.5× the usual width at the start down to 0.5× at the end) worked best.
Why it likely works:
- As layers go deeper, the MLPs tend to add less “new” information and more “refinement” to what’s already there. The paper measured this directly: later-layer outputs are more aligned with the residual stream (the model’s running memory), meaning less novelty.
- So it’s smart to give more capacity to the early layers (where the model is still discovering useful features) and less to the later ones (which mostly polish).
Why does this matter? (Implications)
- It’s a free improvement. You rearrange capacity across layers without increasing parameters or compute—and get better results.
- It’s general. The idea worked across different model families and sizes, suggesting it’s not just a Transformer trick.
- It’s simple and practical. You only adjust one design choice: the MLP width in each layer, following a smooth taper (cosine worked best here).
- It opens a door. The same “taper” idea could apply to other parts of a model that hold parameters, like the number of attention heads, the size of key-value vectors, recurrent state sizes, memory slots, or even experts in mixture-of-experts models.
- Beyond text. Many models in vision, speech, and multimodal AI also use layered designs with uniform capacity. Tapering could help there too.
A quick note on limitations
- The exact best taper shape and start/end widths might depend on the model’s size, depth, or architecture. The authors picked one good setting (cosine taper with about 1.5× start to 0.5× end) based on a 440M model and reused it elsewhere—it worked well, but they didn’t fully re-tune for every case. Future work could fine-tune tapering per model for even bigger wins.
Bottom line
Most LLMs give every layer the same capacity—but layers don’t contribute equally. Early layers do more of the heavy lifting. Tapered LLMs fix this by making early layers wider and later layers narrower in a smooth, budget-neutral way. This consistently improves performance on language and reasoning tasks without extra cost. It’s a simple, smart redesign that many kinds of models can adopt.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address.
- Optimality across scales and depths: The schedule/ratio sweep was only done on a 440M Transformer. Systematically map the best taper schedule and endpoints across depths, hidden sizes, and MLP parameter fractions at larger scales (e.g., 3B–70B), and quantify any shifts in the U-shaped optimum.
- Beyond MLPs: Only MLP width was tapered. Evaluate equal-cost tapering of other parameter-bearing axes (attention head count, key–value dimension, rotary frequency bands, recurrent/state sizes, memory slots, MoE expert counts) and combinations thereof to see where tapering yields the largest gains.
- Architecture- and scale-specific tuning: A single cosine 1.5→0.5 profile was transferred to all models. Determine whether per-architecture/per-scale profiles outperform a universal default, and characterize how the optimal profile relates to model depth and the MLP-to-total-parameter ratio.
- Learned or dynamic tapering: The taper profile is static. Explore learning the per-layer widths (e.g., continuous relaxation/NAS, meta-gradients, bilevel optimization) or curricula that taper over training time, and compare to static schedules at equal cost.
- Training dynamics and stability: Effects on convergence speed, optimization stability, gradient norms, layer-wise learning rates, and curvature were not measured. Track training curves and per-layer metrics to assess whether tapering accelerates or hinders learning.
- Systems and throughput impacts: While total FLOPs are matched, wall-clock training speed, memory footprint (activations, optimizer state), tensor/pipeline parallel balance, kernel efficiency with non-uniform shapes, and utilization on different accelerators were not reported. Benchmark throughput and memory for real training/inference pipelines.
- Quantization and deployment compatibility: Variable per-layer widths may interact with 8/4-bit quantization, weight packing, kernel fusion, and caching. Test quantization-aware training/post-training quantization and measure accuracy/latency on common inference stacks.
- Robustness and statistical significance: Results are single-run point estimates without confidence intervals. Report variance over multiple seeds and conduct significance testing to ensure effects are robust.
- Broader evaluation suite: Benchmarks are limited to WikiText/LAMBADA and eight commonsense tasks. Assess math (e.g., GSM8K, MATH), code (HumanEval, MBPP), multilingual (XNLI, FLORES), knowledge (MMLU), and long-context suites (LongBench, Needle-in-a-Haystack) to detect task-dependent trade-offs.
- Long-context behavior: Training used 4K context, and long-memory benefits were not assessed even for Titans. Measure perplexity and retrieval/recall accuracy at 8K–128K contexts and evaluate KV-cache/memory usage patterns under tapering.
- Fine-tuning regimes: Effects on instruction tuning, RLHF/DPO, and parameter-efficient fine-tuning (LoRA, adapters) are unknown. Compare uniform vs tapered backbones under identical post-training protocols.
- Safety, bias, and calibration: No analysis of output calibration, toxicity, bias, or jailbreak robustness. Evaluate on safety suites (e.g., RealToxicity, BBQ, AdvBench), expected calibration error, and refusal behavior.
- Interpretability mechanism beyond GPT-2: Residual-alignment “novelty” was measured on GPT-2 family but not on the newly trained tapered models or non-transformer backbones. Replicate alignment measurements across trained models (Transformer, Gated, Hope-attention, Titans) and verify that tapering alters layer-wise novelty as hypothesized.
- Causal tests of mechanism: Alignment is correlational. Perform causal interventions (e.g., ablating/zeroing late MLPs, targeted low-rank perturbations) to verify that reduced late capacity recovers early/overall performance in line with the mechanism.
- Interaction with pruning and compression: Does tapering reduce post-training pruning gains or change optimal pruning strategies? Compare structured/unstructured pruning, low-rank compression, and distillation on uniform vs tapered models at equal target budgets.
- Early-exit and dynamic depth: Investigate whether tapering enables more aggressive early-exit thresholds (LayerSkip/CA-LM) without accuracy loss and how gains trade off against dynamic-depth policies.
- Sensitivity to architectural variants: The study fixes pre-norm, activation (SwiGLU vs others), and residual design. Test whether tapering’s benefits persist across post-norm, ReLU/GELU/GEGLU, parallel vs sequential attn–MLP ordering, and normalization variants.
- Edge cases and failure modes: Some settings showed small regressions (e.g., WikiText in 1/8 cases). Characterize tasks or data regimes where tapering hurts, and develop diagnostics to adapt schedule/ratios to avoid regressions.
- Data and compute scaling laws: Benefits were shown at 30B/50B/100B tokens. Map how gains scale with more/less data and with different data mixtures (e.g., higher code/math fraction), establishing taper-aware scaling laws.
- Theory for optimal taper: Provide a theoretical framework linking residual alignment, effective rank of layer updates, and optimal width profiles across depth, predicting when and how much to taper.
- Interaction with memory/recurrent modules: For Titans and other memory-based models, quantify how tapering MLPs affects memory write/read utilization and whether tapering memory-state size instead yields larger gains.
- Curriculum or stagewise tapering: Explore starting uniform and progressively tapering late layers (or vice versa) during training, and measure whether stagewise schedules improve sample efficiency or final quality.
- Reproducibility and release: Exact per-layer widths, rounding effects, seeds, and code were not indicated. Provide artifacts to enable precise replication and to isolate sources of variance.
- Hardware-specific rounding effects: Widths are rounded to multiples of 16; confirm exact parameter/FLOP parity and examine whether different granularities (e.g., 64/128) or hardware (NVIDIA vs AMD vs TPU) change outcomes.
- Extreme taper limits: Assess stability and performance when d_end is very small or near zero, and characterize minimum safe late-layer capacities for given depths/tasks.
- Combination with MoE and routing: Evaluate tapering within MoE MLPs (e.g., per-layer expert count or hidden size taper) and interactions with token-level routing, keeping global compute/parameter budgets fixed.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating tapered MLP width (cosine schedule; start/end ≈ 1.5/0.5 of baseline FFN width) into training or fine-tuning pipelines, at fixed parameter and FLOP budgets.
- Better model performance at fixed cost in new training runs
- Sectors: software, cloud AI, foundation model vendors
- What: Train new Transformer-family LMs with TLMs to gain perplexity and downstream accuracy without increasing parameters or compute.
- Tools/products/workflows: Add a per-layer FFN width schedule to model configs; extend training stacks (PyTorch/Hugging Face/DeepSpeed/Megatron) to accept per-layer FFN hidden sizes; ship “Tapered” variants of existing model lines.
- Assumptions/dependencies: Training from scratch or full-parameter fine-tuning; kernels/frameworks must support non-uniform FFN sizes; use width multiples of 16 for accelerator efficiency.
- Edge and on-device LLMs with improved quality at the same footprint
- Sectors: mobile, embedded, robotics, automotive, consumer electronics
- What: Use tapering to boost quality of on-device assistants/keyboards/summarizers under tight memory and power limits.
- Tools/products/workflows: Release “Tapered-Edge” checkpoints at 0.5–2B parameters; integrate into mobile inference SDKs; memory-aware packing per layer.
- Assumptions/dependencies: Serving stacks must cache per-layer GEMM kernels; quantization calibration may need per-layer attention due to shape diversity.
- Fine-tuning workflows for domain-specific LLMs
- Sectors: healthcare, legal, finance, customer support, education
- What: Start from tapered base models (or re-train domain LMs) to deliver higher task accuracy under fixed budgets.
- Tools/products/workflows: Domain pretraining or instruction tuning with tapered FFN widths; LoRA/QLoRA with layer-wise ranks adjusted to FFN size; evaluation bundles showing cost-parity gains.
- Assumptions/dependencies: If starting from uniform models, re-initialization or distillation is needed (no drop-in weight reshaping); hyperparameters may need light retuning.
- Synergistic early-exit and partial decoding systems
- Sectors: cloud inference, real-time assistants, interactive applications
- What: Combine tapering (more capacity early) with early-exit/layer-skip to reach accurate exits earlier, reducing average inference latency.
- Tools/products/workflows: Calibrate exit thresholds on tapered models; deploy LayerSkip/Conformal Early Exit with TLMs; A/B test latency-quality tradeoffs.
- Assumptions/dependencies: Total FLOPs at max-depth remain unchanged; latency gains rely on exit ratios and calibration; monitoring for distribution shift.
- Architecture search and baseline improvements in academic research
- Sectors: academia, open-source AI
- What: Adopt tapered width as a new, strong baseline; reuse the cosine schedule and 1.5→0.5 ratio as a robust default across moderate scales.
- Tools/products/workflows: Public configs and scripts for per-layer FFN schedules; benchmark suites reporting equal-FLOP comparisons; release of layer-wise novelty probes.
- Assumptions/dependencies: Best ratio might shift by scale/architecture; report matched FLOPs/params to ensure fair comparisons.
- Cost- and energy-efficiency gains at fixed service tiers
- Sectors: cloud platforms, sustainability programs, enterprise IT
- What: Offer the same priced tier with better quality (or same quality with smaller models) by training tapered variants.
- Tools/products/workflows: Update model catalogs and SLAs; sustainability dashboards showing quality-per-watt improvements; procurement choices favoring tapered models.
- Assumptions/dependencies: Energy per request is unchanged if model size is fixed; efficiency gains materialize when better quality enables using a smaller tapered model for the same target.
- MLOps observability: layer-wise novelty diagnostics
- Sectors: AI platform engineering, reliability
- What: Compute the paper’s residual-alignment metrics to profile where a given model writes novel information and guide taper settings.
- Tools/products/workflows: “NoveltyMeter” profiling during pretraining/finetuning; dashboards of ρ_block and ρ_MLP by layer; alerts when later layers become overly redundant.
- Assumptions/dependencies: Requires activations during eval; interpretation sensitive to normalization conventions and datasets.
- Curriculum and practitioner education
- Sectors: education, professional training
- What: Teach depth-aware capacity allocation as a simple design lever; include TLM labs in ML courses.
- Tools/products/workflows: Lecture modules, practical assignments implementing cosine taper; comparisons against uniform baselines.
- Assumptions/dependencies: Course compute budgets must allow matched-FLOP training comparisons.
Long-Term Applications
These applications require additional research, scaling studies, systems support, or method development beyond the paper’s current scope.
- Generalized tapering beyond MLP width
- Sectors: software, AI research
- What: Taper other parameter-bearing axes (attention head count, key-value dims, recurrent state size, memory slots, MoE experts) under fixed budgets.
- Tools/products/workflows: Multi-axis taper schedulers; joint schedule search (e.g., cosine for FFN + linear for heads); evaluation tooling for equal-cost comparisons.
- Assumptions/dependencies: Interactions between axes can be nontrivial; stability and convergence must be revalidated; router dynamics (for MoE) may change with depth.
- Cross-domain adoption (ViTs, diffusion transformers, multimodal and speech models)
- Sectors: vision, generative media, multimodal assistants, speech
- What: Apply tapering to FFN/MLP components in encoders/decoders across modalities to improve quality at fixed cost.
- Tools/products/workflows: Vision/diffusion backbones with per-layer FFN schedules; schedule libraries shared across modalities.
- Assumptions/dependencies: Empirical confirmation needed; best schedule and ratios may differ by modality, depth, and training regime.
- Hardware–software co-design for non-uniform depth capacity
- Sectors: semiconductors, systems, cloud infrastructure
- What: Design accelerators and compilers optimized for layer-wise non-uniform widths (kernel autotuning, memory tiling, sharding/pipeline partitioning by per-layer load).
- Tools/products/workflows: Taper-aware graph compilers; pipeline-parallel planners that partition by true per-layer FLOPs/parameters; cache-aware kernel reuse across similar widths.
- Assumptions/dependencies: Vendor libraries must support many GEMM shapes efficiently; potential kernel cache pressure; requires collaboration with hardware vendors.
- Retrofitting uniform pretrained models into tapered ones
- Sectors: model providers, enterprise adopters
- What: Structural reparameterization or distillation to convert uniform FFN widths into tapered profiles with minimal retraining.
- Tools/products/workflows: Group-wise channel pruning/expansion with KD; low-rank adapters that effectively modulate width; progressive morphing schedules during SFT.
- Assumptions/dependencies: Not trivial due to shape changes; likely requires multi-stage distillation and careful initialization; risk of performance regressions.
- Input-adaptive or learned taper schedules
- Sectors: advanced inference, research
- What: Learn depth profiles conditioned on scale, domain, or even per-input signals (mixture-of-depths + per-layer capacity routing).
- Tools/products/workflows: Meta-controllers that adjust effective width/compute allocation; training objectives that regularize novelty vs redundancy.
- Assumptions/dependencies: Complexity in training and serving; risk of instability; hardware scheduling for dynamic shapes is challenging.
- Safety, alignment, and monitoring placement guided by novelty
- Sectors: safety engineering, compliance
- What: Use layer-wise novelty maps to place monitors, intervention hooks, or safety constraints where they are most effective (often mid/early layers).
- Tools/products/workflows: Policy engines that hook into high-novelty layers; targeted activation steering or rank reduction where it matters most.
- Assumptions/dependencies: Causality between novelty and behavioral leverage must be validated across tasks; monitor overhead must be controlled.
- Procurement and policy guidance for efficient model design
- Sectors: public sector, standards bodies, enterprise governance
- What: Encourage or require reporting of capacity-allocation strategies (e.g., tapering) as part of efficiency disclosures; include depth-aware allocation in green-AI best practices.
- Tools/products/workflows: Model cards that document per-layer parameter schedules; benchmarks reporting quality-at-fixed-compute with/without tapering.
- Assumptions/dependencies: Requires consensus on metrics and disclosures; avoid prescribing one schedule universally given architecture/scale dependencies.
- Automated schedule selection using profiling
- Sectors: AutoML, platform tooling
- What: Use short pretraining runs and novelty measurements to automatically select schedule type and start/end ratios per architecture/scale.
- Tools/products/workflows: Bayesian or bandit search over taper hyperparameters at small scale; transfer the selected schedule to full-scale training.
- Assumptions/dependencies: Transferability across scales and domains is empirical; search costs must be amortized by downstream gains.
- Quantization-, pruning-, and distillation-aware tapering
- Sectors: model optimization, deployment
- What: Jointly design taper schedules with quantization/pruning to maximize accuracy at stringent footprints.
- Tools/products/workflows: Per-layer quantization schemes reflecting width and sensitivity; structured pruning that aligns with tapered late layers; teacher–student distillation where teacher may be uniform and student tapered.
- Assumptions/dependencies: Sensitivity varies by layer and schedule; calibration pipelines must adapt; careful alignment of teacher and student capacities is required.
Key assumptions and dependencies across applications
- The reported gains are validated up to ~1.3B parameters and four backbone families; very large scales (e.g., 7B–70B+) need confirmation and possible re-tuning of ratios/schedules.
- Framework and kernel support for per-layer FFN hidden sizes is required; many codebases assume uniform FFN width and need minor refactors (checkpoint formats, config schemas, sharding).
- The cosine schedule with 1.5→0.5 is a robust default, not guaranteed optimal; data regime, depth, and architecture can shift the optimum.
- FLOPs and parameters are held constant overall; tapering redistributes compute across depth but does not by itself reduce worst-case latency unless combined with early-exit or reduced depth.
- Memory and serving implications (kernel caching, compilation time, per-layer quantization) must be considered in production.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates to improve training stability. "We use AdamW with a cosine annealing schedule"
- Activation-steering: A technique that intervenes on internal activations to change model behavior without retraining. "Activation-steering studies provide complementary intervention-based evidence"
- ARC-challenge: A challenging subset of the AI2 Reasoning Challenge dataset for scientific question answering. "ARC-easy and ARC-challenge"
- ARC-easy: An easier subset of the AI2 Reasoning Challenge dataset for scientific question answering. "ARC-easy and ARC-challenge"
- Attention head count: The number of parallel attention heads within a layer, controlling representational capacity and computation. "attention head count, key-value dimension, recurrent state size, memory slots, and expert count in mixture-of-experts models"
- BoolQ: A yes/no question answering benchmark focused on reading comprehension. "BoolQ"
- Cosine annealing schedule: A learning rate schedule that decreases the rate following a cosine curve over training. "a cosine annealing schedule"
- Cosine schedule: A tapering profile where a parameter decays following a half-cosine across depth. "tapering MLP width via a smooth cosine schedule"
- Cosine similarity: A measure of the angle between vectors indicating alignment; used to assess novelty of layer updates. "Cosine similarity between each layer's update and the residual stream entering its block"
- Decoder-only LLMs: Autoregressive models that generate text by predicting the next token using only decoder blocks. "We focus on the family of decoder-only LLMs"
- Depth-aware capacity allocation: Designing models so parameter capacity varies with layer depth rather than being uniform. "establishing depth-aware capacity allocation as a robust, architecture-agnostic design choice"
- Early-exit: Methods that allow stopping inference before the final layer when confidence or convergence criteria are met. "Early-exit methods show that the residual stream often converges to its final prediction well before the last layer"
- Expert count: The number of experts in a mixture-of-experts layer, controlling sparsity and capacity. "expert count in mixture-of-experts models"
- Feed-forward network (FFN): The per-token multilayer perceptron component within each transformer block. "feed-forward network (FFN)"
- FLOPs: Floating-point operations; a measure of computational cost in training and inference. "training FLOPs, and inference FLOPs"
- Gated Attention: An attention variant that introduces output gating to improve sparsity and remove attention sinks. "Gated Attention"
- HellaSwag: A commonsense reasoning benchmark focused on plausible continuation of text. "HellaSwag"
- Hope-attention: An attention mechanism with nested learning and self-modifying memory operating at multiple frequencies. "Hope-attention"
- Key-value dimension: The dimensionality of the key and value projections in attention, affecting memory and capacity. "key-value dimension"
- Key-value memories: The perspective that FFN layers act as associative memories storing key-value mappings. "FFNs as key-value memories"
- LAMBADA: A dataset requiring broad context to predict a final word, used to assess long-range language modeling. "out-of-distribution perplexity on WikiText and LAMBADA"
- LayerNorm: A normalization technique applied within layers to stabilize training by normalizing activations. "avoid the directional distortion that LayerNorm introduces"
- Layer-skipping: Techniques that bypass later layers during inference to reduce compute with minimal quality loss. "layer-skipping frameworks demonstrate that later layers can be bypassed at inference time"
- Llama 3 tokenizer: The subword tokenizer used for training and evaluation in Llama 3 models. "use the Llama~3 tokenizer"
- Memory-based architectures: Model families that augment attention or recurrence with learnable external memory modules. "memory-based architectures"
- Memory slot count: The number of discrete memory slots available to a memory module in architectures with external memory. "memory slot count"
- Mixture-of-Experts: A sparsity technique routing tokens to a subset of expert networks to increase capacity efficiently. "mixture-of-experts models"
- MLP intermediate dimension: The hidden width of the per-layer MLP, controlling per-layer parameter count and compute. "MLP intermediate dimension"
- Monotonically tapered: A design constraint where a parameter decreases (non-increasing) across depth while preserving total budget. "monotonically tapered across depth"
- Out-of-distribution perplexity: A perplexity measurement on data different from training distribution to assess generalization. "out-of-distribution perplexity on WikiText and LAMBADA"
- Parameter budget: The fixed total number of model parameters allocated across components or layers. "total parameter budget"
- Pearson correlation: A statistic measuring linear association, used here between similarity and layer index. "Pearson correlation with layer index is positive"
- Perplexity: A standard metric for language modeling evaluating how well a model predicts a sample; lower is better. "Validation perplexity"
- PIQA: A physical commonsense reasoning benchmark requiring practical everyday knowledge. "PIQA"
- Recurrent state size: The dimensionality of the hidden state in recurrent or state-space models across layers. "recurrent state size"
- Residual stream: The backbone representation carried through layers via residual connections that accumulate updates. "the residual stream"
- Sigmoid schedule: A tapering profile where a parameter transitions via a sigmoid concentrated around the midpoint. "Sigmoid."
- SIQA: A social commonsense reasoning benchmark focused on social interactions. "SIQA"
- SwiGLU: A gated MLP variant that improves transformers by introducing multiplicative gating between linear projections. "SwiGLU"
- Taper range: The chosen start and end widths defining how aggressively capacity is redistributed across depth. "validation perplexity as a function of the taper range"
- Tapered LLMs (TLMs): Models whose parameter-bearing components are tapered across depth under a fixed total budget. "Tapered LLMs (TLMs)"
- Titans: An architecture augmenting attention with a neural long-term memory that learns to memorize at test time. "Titans"
- Token-mixing module: The component in each block that mixes information across tokens (e.g., attention or recurrence). "token-mixing module"
- Transformer: A neural architecture based on self-attention and MLPs arranged in residual blocks. "Transformer"
- WikiText: A dataset derived from Wikipedia used for evaluating language modeling perplexity. "WikiText"
- WinoGrande: A large-scale coreference reasoning benchmark designed to be more challenging than Winograd. "WinoGrande"
Collections
Sign up for free to add this paper to one or more collections.

