SPIRAL: Learning to Search and Aggregate
Abstract: LLM reasoning can be substantially improved at test time via scaffolds that scale inference compute across different primitives -- sequential reasoning within a trace, independently sampled parallel traces, and aggregation of multiple reasoning traces into a final response. During post-training, however, LLMs are optimized only for sequential reasoning within a single trace. We introduce Sequential-Parallel-Aggregative Reinforcement Learning (SPIRAL), a framework in which a LLM is trained to use all three primitives, as part of a unified inference compute pipeline. Concretely, the LLM first samples a set of independent traces in parallel, each produced through sequential chain-of-thought reasoning, and then generates a final aggregation trace conditioned on those traces; all components are optimized end-to-end against the reward of the final aggregated response. To train this system, SPIRAL uses set reinforcement learning to teach models to produce a set of traces that are collectively useful for an aggregator and standard reinforcement learning to teach models to aggregate the set into improved final responses. Our experiments on reasoning tasks show that SPIRAL effectively scales with inference compute, outperforming GRPO by up to 11$\times$ scaling efficiency and 15% higher performance when all three compute primitives are scaled.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a LLM (an AI that writes and reasons) to think in smarter ways by using its “mental effort” more effectively. The authors introduce a training method called Spiral (Sequential-Parallel-Aggregative Reinforcement Learning) that helps the model:
- think step-by-step in one line of thought (sequential),
- try multiple ideas at the same time (parallel), and
- combine those ideas into a better final answer (aggregative).
Instead of only practicing one long chain of thought (which is what most models are trained to do), Spiral trains the model to use all three kinds of thinking together and rewards it only for the final combined answer. This makes the model better at searching for solutions and pulling together good parts from different attempts.
What questions does the paper ask?
In simple terms, the paper asks:
- How can we train an AI to use its thinking time better, not just by going deeper on one idea, but also by trying different ideas and combining them well?
- Can a model learn to create helpful sets of attempts that make the final combined answer stronger?
- Will this kind of training actually make the model solve more problems when we give it extra “thinking compute” at test time?
How does Spiral work?
The three kinds of thinking
Think of solving a hard math puzzle with friends:
- Sequential: One friend works through a single, careful solution path.
- Parallel: Many friends try different approaches at the same time.
- Aggregative: Another friend reads everyone’s attempts, checks them, and writes the best final solution by mixing the good parts.
Spiral trains the AI to do all three roles well.
The training setup (everyday analogy)
- Step 1: Brainstorm. The model writes several separate solution attempts to the same problem (parallel traces). Each attempt is a step-by-step chain of thought (sequential).
- Step 2: Synthesize. The model then reads a small group (a set) of those attempts and writes a final “best” solution (aggregation).
- Step 3: Reward. Only the final combined answer is graded (right or wrong). There’s no direct reward for the brainstorm attempts by themselves.
Here’s the clever part: How do you give fair credit to the brainstormers if only the final write-up is graded?
- Spiral uses a “set reinforcement learning” idea: it treats a group of attempts as a team. If the final combined answer is good, every attempt in that group gets some shared credit. If it’s bad, they share the blame.
- Over time, attempts that tend to be useful in winning teams get more credit. This teaches the model to produce diverse and helpful attempts (not just copies of the same idea), because even a partial, promising idea can help the final answer when combined with others.
In parallel, the model also learns to be a strong synthesizer: when it reads several attempts, it learns to verify, compare, fix mistakes, and write a better final response. This “aggregator” is trained with standard reinforcement learning: it gets more credit when its final answer is correct.
A bit more detail (without heavy math)
- The model first generates many candidate solutions (N1 attempts).
- It forms many small groups (sets) from those attempts.
- For each group, it writes several final combined answers (N2 aggregations) and gets rewards based on whether those final answers are correct.
- Credit assignment:
- Search attempts (the brainstorms) get credit based on how well the groups they’re part of tend to do (shared “team” credit).
- Aggregation answers (the final write-ups) get credit based on how well they did compared to the other final answers made from the same group (individual “within-group” credit).
This trains both the “search” behavior (make useful, varied attempts) and the “aggregation” behavior (turn a mixed set of ideas into a strong final answer).
What did they find, and why is it important?
The authors fine-tuned a 4-billion-parameter model on math problems and compared Spiral to a strong baseline method (GRPO) that only trains single chains of thought.
Key results:
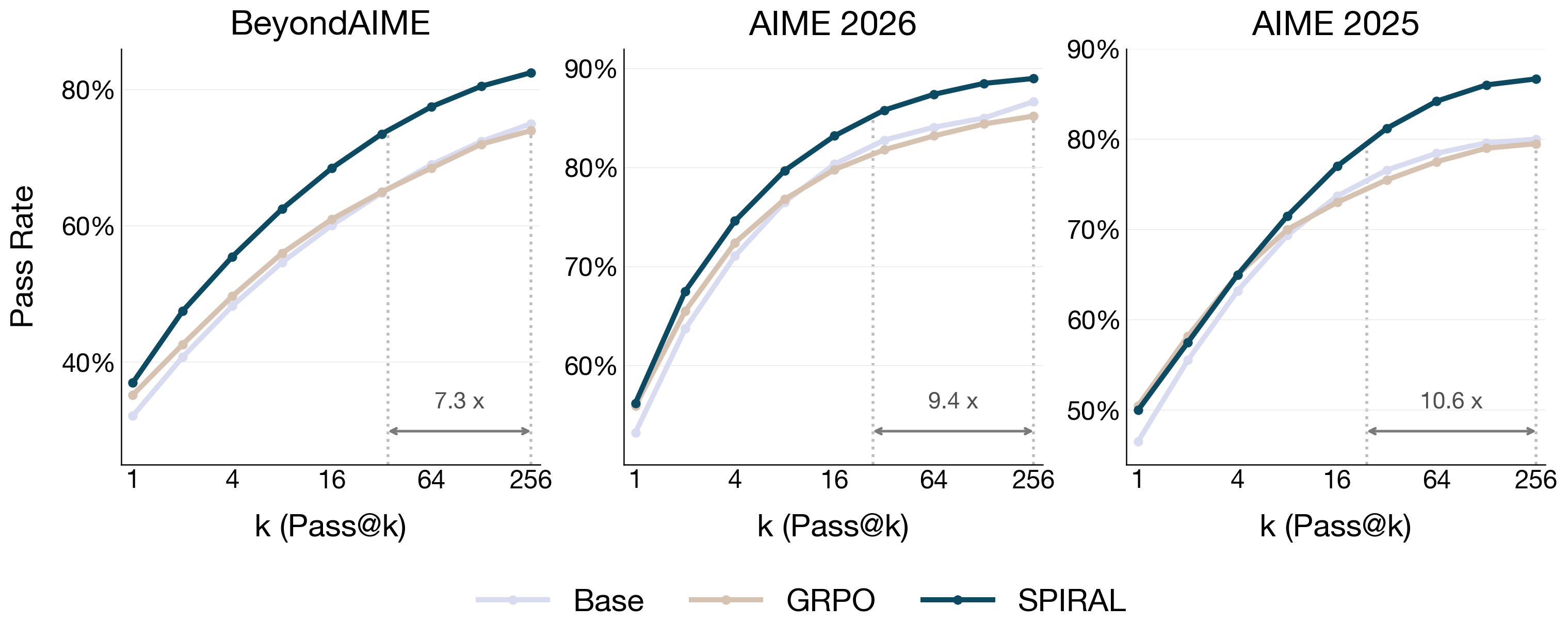
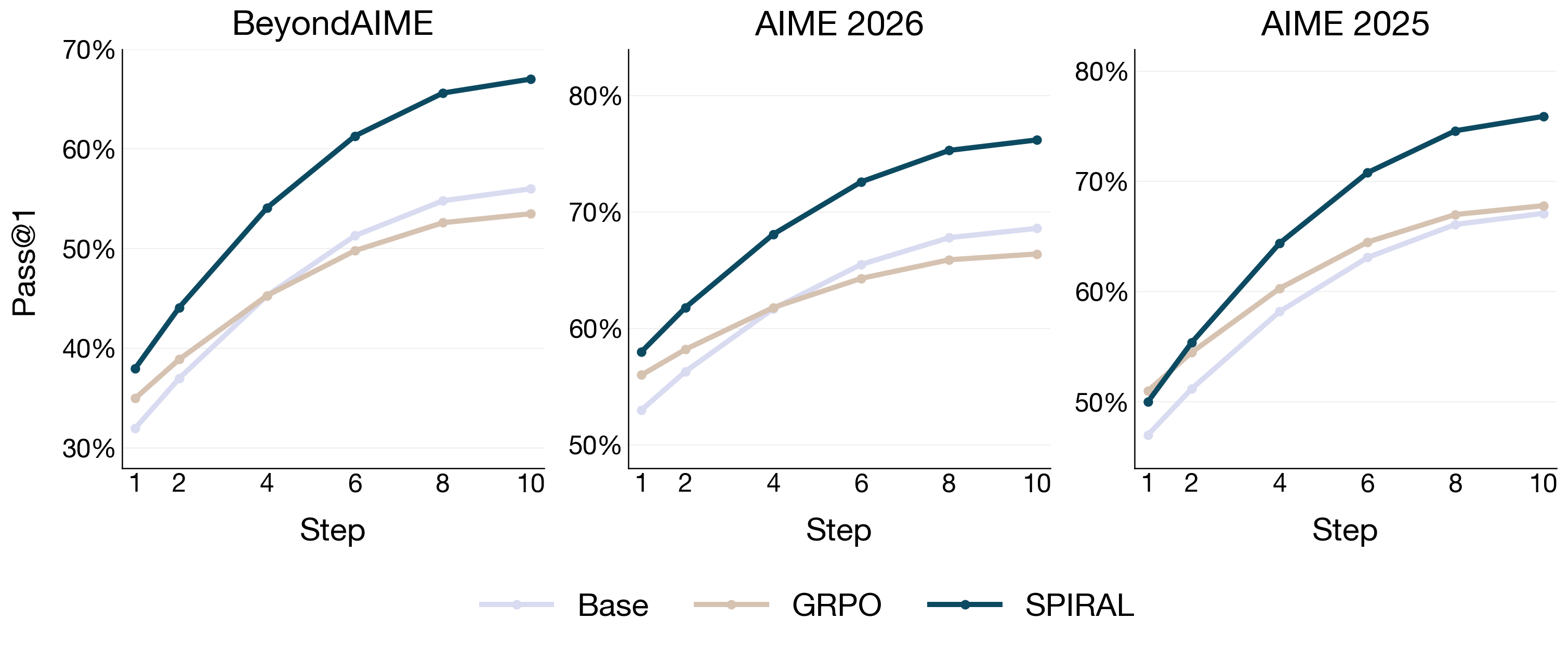
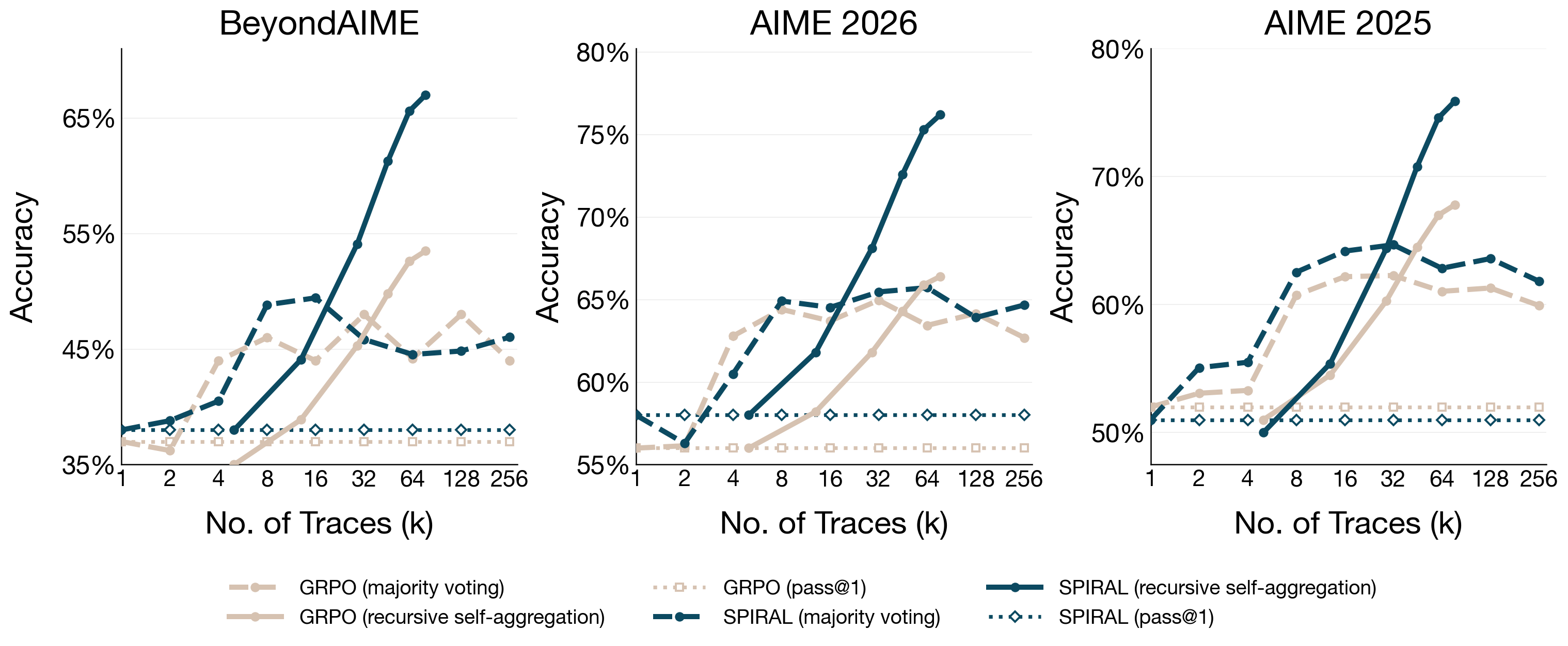
- Better use of parallel thinking: When they let the model try more independent attempts (pass@k), Spiral improved much more efficiently—up to 11× better scaling efficiency than the baseline. In practice, this means Spiral makes more use of extra attempts: more variety, more coverage of different solution paths, and better odds of finding a correct answer.
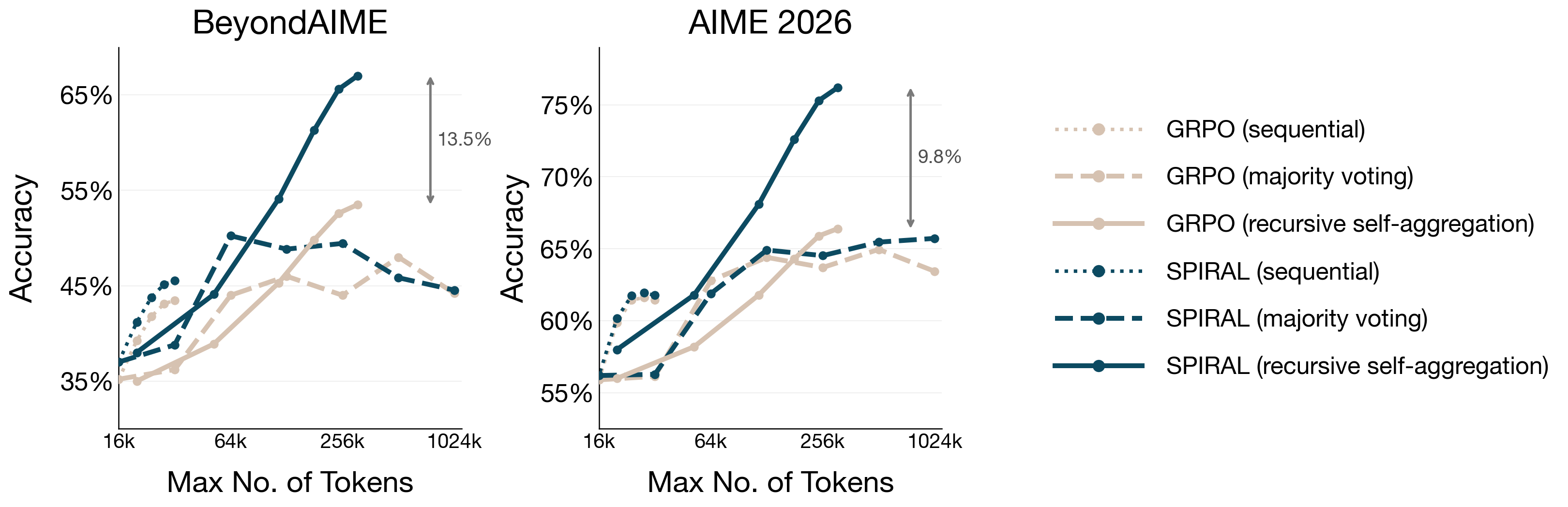
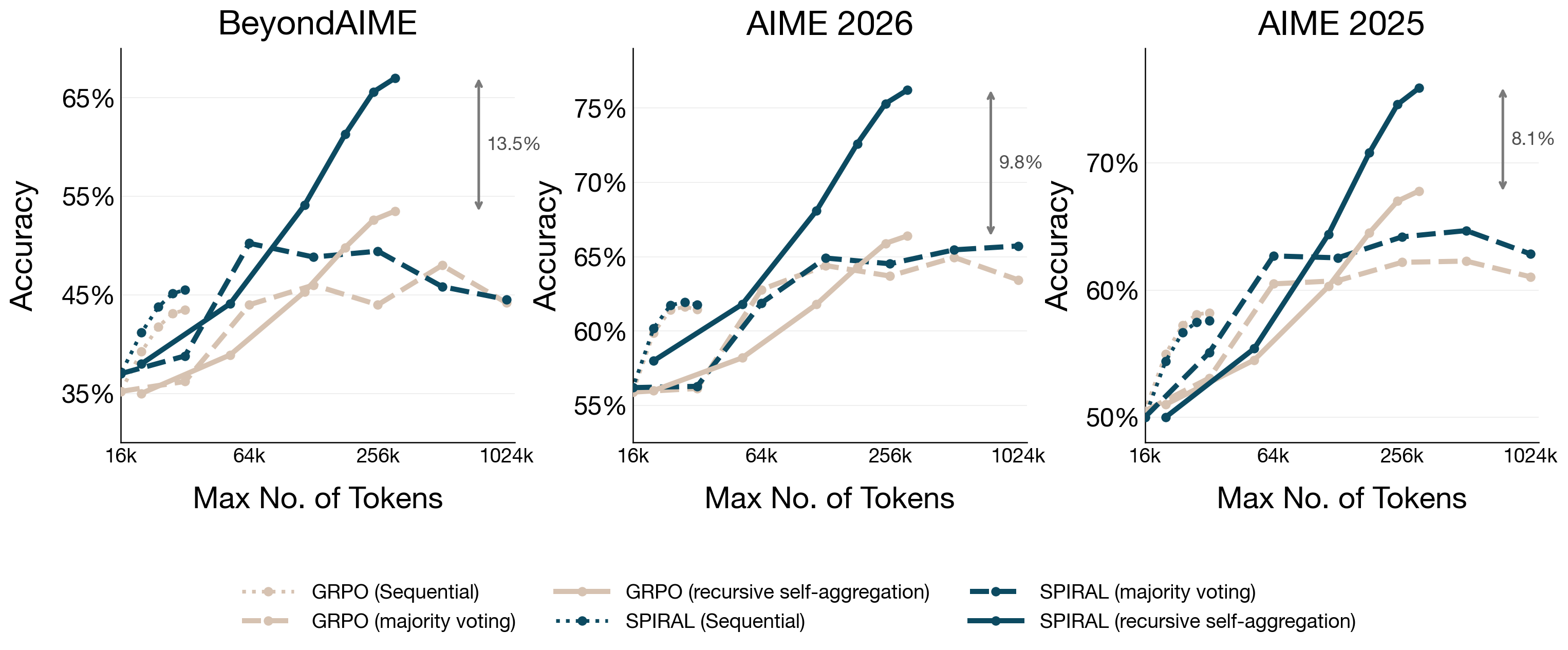
- Better combining of ideas: When they allowed the model to repeatedly combine ideas (recursive self-aggregation), Spiral beat the baseline by up to 13.5% and achieved up to 15% higher performance when parallel and aggregation were both scaled. This shows Spiral learns to judge, fix, and merge ideas effectively.
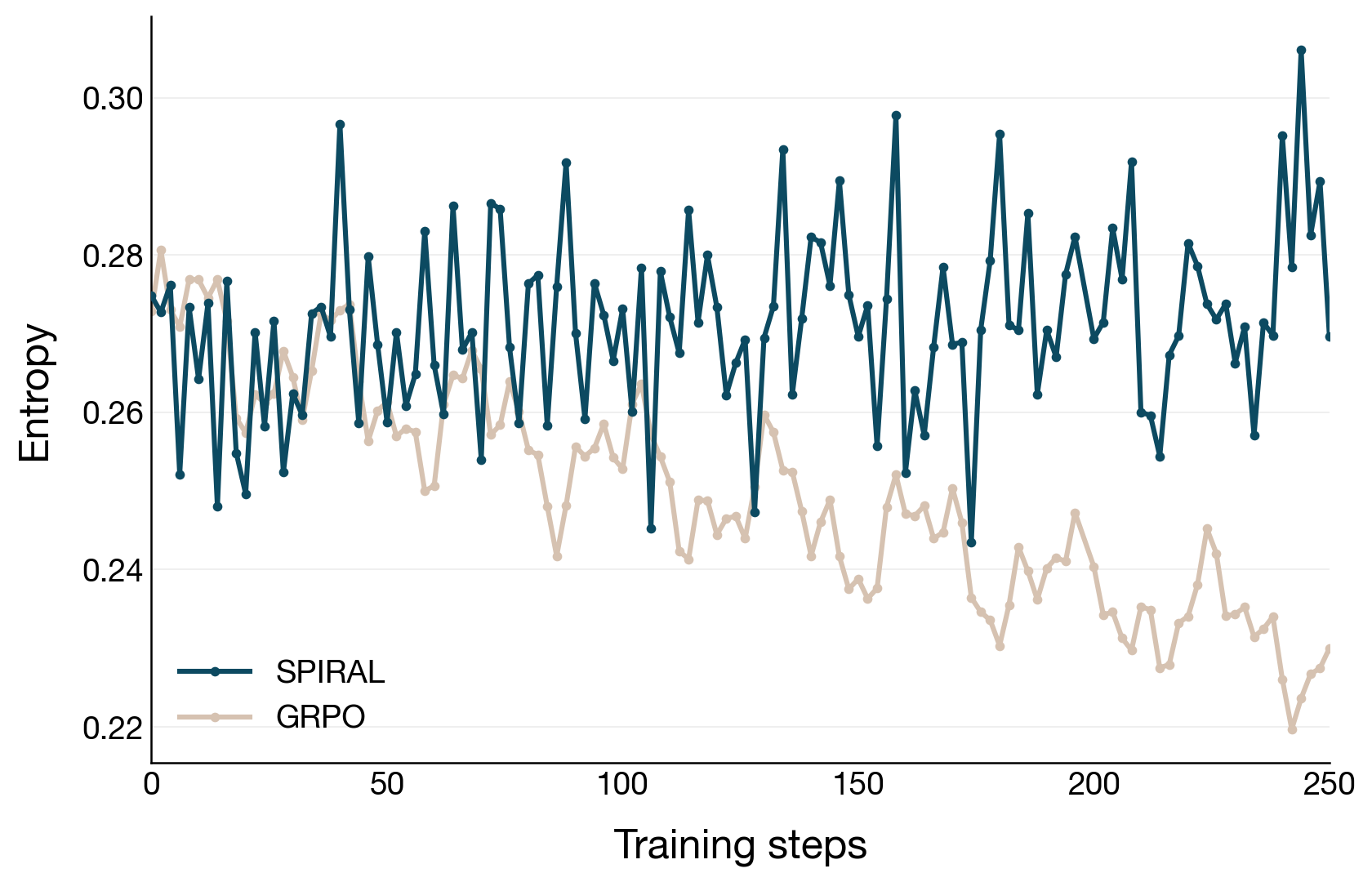
- Maintains healthy diversity: Spiral’s attempts stayed more diverse (higher entropy), instead of collapsing into similar answers. Diversity matters because it increases the chance that at least one attempt contains the key insight—or that different attempts contain pieces that can be stitched together.
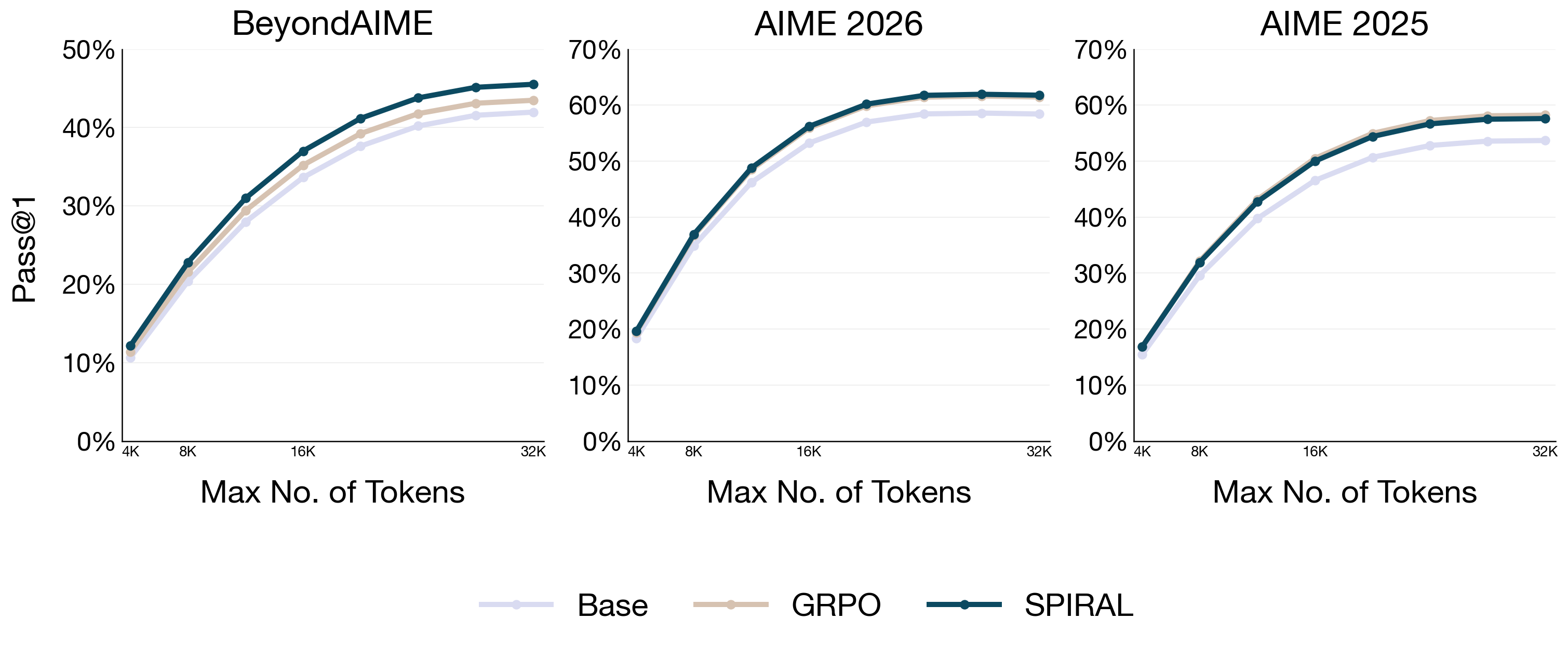
- Sequential-only gains were similar: When only the single chain-of-thought length was increased, all methods performed similarly. The real advantage of Spiral shows up when you scale parallel attempts and aggregation—the kinds of compute people already use in practice.
- Better use of token budgets: Given a fixed “thinking token” budget, strategies that use parallel attempts plus aggregation (especially when the model is trained for it, like Spiral) deliver more improvements than just writing longer single chains.
Why this matters:
- In real-world use, people often scale test-time compute by sampling many answers and then combining or selecting from them. Spiral explicitly trains the model to be good at that. That closes the gap between how we train and how we actually use models.
- It reduces the need for complicated, hand-crafted “scaffolds” to guide the model at test time. Instead, the model learns an internal search-and-aggregate strategy.
What could this change?
- Smarter problem-solving: Models could become better at math, science, and coding by exploring multiple angles and then carefully merging them into a final, reliable answer.
- More reliable reasoning: The aggregation skills (checking, comparing, verifying) can help reduce errors and make answers more trustworthy.
- Better scaling with compute: As we give models more “thinking time” (more attempts, more aggregation steps), Spiral-trained models get more out of it.
- Simpler systems: If the model learns to search and aggregate on its own, developers may not need as many hand-built tools and pipelines to get good results.
In short, Spiral teaches AI not just to think longer, but to think wider and then pull the best ideas together—much like a good team working toward a single, well-checked solution.
Knowledge Gaps
Below is a single list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper and could guide future research.
- Ordering bias in aggregation: Spiral’s set objective assumes permutation invariance of search traces, but LMs are sensitive to input order. Quantify the impact of ordering on outcomes, test randomization/architectural invariance, and evaluate training with ordered-tuples sampling (as in the unbiasedness proposition) versus unordered-set sampling used in practice.
- Unbiasedness vs practicality trade-off: The paper proves unbiasedness for ordered-tuple sampling but trains with unordered sets. Measure the empirical bias introduced, its effect on convergence/performance, and develop scalable estimators or control variates to recover unbiasedness without factorial blowup.
- Variance and baselines: The per-set baseline reduces variance for aggregation updates, but the variance properties and optimality of baselines for search-trace credit assignment are not analyzed. Compare learned critics, cross-set baselines, and control variates for both levels.
- Convergence and stability: No theoretical or empirical analysis of convergence properties when jointly optimizing set-RL (search) and standard RL (aggregation) with shared parameters. Study interference between the two gradient terms, stability under different learning rates, and conditions for monotone improvement.
- Sample complexity: The claim of “comparable” sample complexity to standard RL is not quantified. Provide compute-sensitive learning curves, ablate N1/N2/K/n, and report wall-clock/throughput to establish cost–benefit trade-offs.
- Compute scaling beyond two steps: Training is limited to a two-level pipeline, yet test-time recursive self-aggregation (RSA) is scaled to multiple steps. Train on deeper recursion, study generalization to longer depths, and define curricula/schedules for multi-level pipelines.
- Adaptive compute allocation: Spiral uses fixed counts for parallel and aggregation samples. Learn instance-adaptive policies that allocate sequential/parallel/aggregative compute subject to a token budget, and evaluate efficiency versus fixed allocations.
- Separate searcher vs aggregator models: The appendix mentions support for distinct models, but there are no experiments. Test asymmetric capacities, specialization benefits, and co-training protocols (e.g., alternating updates, frozen modules).
- Robustness to reward functions: Experiments rely on exact-answer rewards for math. Evaluate under noisy, partial, or learned reward models (RMs), including verifier-based rewards, preference/APE signals, or process-based rewards, and measure robustness to reward misspecification.
- Open-ended tasks and domains: Results are limited to math on POLARIS with a 4B model. Validate on code generation, scientific QA, theorem proving with verifiers, commonsense planning, tool-use, and multimodal reasoning; report cross-domain generalization.
- Baseline coverage: Only GRPO and simple majority voting are compared. Include stronger baselines: best-of-N with verifiers, DPO/RLAIF-style training, polychromic/diversity-aware set objectives, OpenDeepThink-style pairwise aggregation, tree search (ToT/MCTS), and evolutionary scaffolds.
- Ablations on set design: No ablations on set size n, pool size N1, number of sets K, or aggregation samples N2. Systematically map performance/variance vs these hyperparameters and provide guidelines for practical regimes.
- Entropy/diversity control: Spiral shows slower entropy collapse but lacks mechanisms to target “useful diversity.” Investigate explicit diversity terms, disagreement-aware sampling, or negative correlation priors, and measure how these affect aggregator success.
- Ordering and formatting of traces: The aggregator likely depends on how traces are presented (ordering, headings, summaries). Evaluate prompt formats, shuffling policies, learned selectors/summarizers, and their effect on performance and context budget.
- Long-context limitations: Aggregation requires many traces in context; performance degrades near context limits. Study summarization/compression of trace sets, memory modules, or retrieval-based aggregation to overcome long-context bottlenecks.
- Safety and reliability of aggregation: Aggregators may synthesize plausible but incorrect solutions or be swayed by adversarial/irrelevant traces. Evaluate calibration, confidence reporting, adversarial robustness, and verifier-in-the-loop defenses during training and inference.
- Tool-use and external verifiers: Although mentioned as part of sequential compute, experiments do not use tools. Integrate formal verifiers, calculators, and search engines into both search and aggregation phases, and measure joint learning and credit assignment with tool feedback.
- Off-policy corrections: The method references Tinker importance sampling but lacks analysis of off-policy bias/variance and replay design. Compare on-policy vs off-policy regimes, replay buffer strategies, and target networks/regularization for stability.
- Process supervision vs final-answer rewards: Spiral optimizes only final rewards. Test hybrids that incorporate process signals (step-wise checks, intermediate goals) to stabilize training, improve credit assignment, and reduce dependence on sparse signals.
- Error analysis: No qualitative breakdown of failure modes (e.g., redundant search, aggregator misverification, shallow synthesis). Provide detailed case studies linking failure patterns to credit assignment or formatting issues to guide fixes.
- Statistical significance and reproducibility: Results lack confidence intervals and multiple seeds. Report variance across seeds, statistical tests, and release full training/inference configs and code to validate claims.
- Compute–accuracy Pareto: Token-efficiency plots are presented but not as full Pareto frontiers across compute budgets and methods. Provide standardized compute budgets, throughput, latency, and cost to contextualize “11× scaling efficiency.”
- Non-stationarity from shared parameters: Using one model for both roles creates a moving target distribution for aggregation inputs. Study techniques to mitigate non-stationarity (e.g., lagged targets, partial freezing, dual-optimizer schedules).
- Interaction with temperature/decoding: The role of decoding parameters in maintaining diversity and aggregator-friendly traces is unexplored. Jointly learn or adapt decoding strategies (temperature, nucleus p) conditioned on instance difficulty.
- Curriculum over difficulty: Training does not control for instance difficulty. Evaluate curricula (easy-to-hard), adaptive sampling, or self-paced selection to improve stability and scaling on hard problems.
- Security and contamination: No discussion of data leakage or prompt injection in trace conditioning. Examine vulnerability to malicious traces and potential guardrails.
- Failure under sparse success: When all traces are poor, aggregation should “start fresh.” Measure and train explicit fallback behaviors, early-stopping of bad sets, and trace regeneration policies.
- Compression of training costs: Spiral incurs heavy sampling (N1, K, N2). Explore distillation of aggregator and searcher, shared-trajectory re-use, speculative decoding, and low-cost proxies to reduce training/inference cost.
- Theoretical links to multi-agent credit assignment: Formalize conditions under which set RL encourages complementary exploration versus redundant collapse, and analyze equilibria of the co-evolutionary dynamics between search and aggregation.
Practical Applications
Immediate Applications
These applications can be prototyped and deployed with current models and verifiers, especially where task rewards are automatically available (e.g., exact answers, unit tests, proof checkers).
- Math tutoring, grading, and contest solving
- Sector: Education; EdTech; Assessment
- Tools/Products/Workflows: Spiral-trained “solver” that samples diverse solution attempts and a built-in aggregator that explains and verifies a final solution; recursive self-aggregation (RSA) for hard problems; auto-grading pipelines for homework/competitions
- Dependencies/Assumptions: Automatic reward via exact-answer checkers; adequate context length to condition on multiple attempts; token/latency budget; guardrails for solution style and pedagogy
- Program synthesis, bug fixing, and test-driven code generation
- Sector: Software engineering; DevTools; CI/CD
- Tools/Products/Workflows: “SpiralFix” CI step that (1) generates multiple candidate patches, (2) aggregates them into a robust patch, (3) verifies via unit/prop tests; code-review assistants that aggregate multiple refactoring options into one suggestion
- Dependencies/Assumptions: Reliable test suites (coverage), sandboxed execution; stable RL fine-tuning pipeline; compute budget for parallel attempts and aggregation
- Formal theorem proving and proof search with verifiable checkers
- Sector: Academia (mathematics, CS theory); Automated reasoning
- Tools/Products/Workflows: Lean/Coq assistants that generate sets of proof sketches and aggregate into a final proof candidate; “best-of-N + aggregation” pipelines to boost proof success rates
- Dependencies/Assumptions: Proof checkers as ground-truth verifiers; long-context input for multiple proof attempts; domain-specific prompting/templates
- Benchmark QA and knowledge tasks with hard verifiers
- Sector: ML evaluation; Information retrieval; Search engines (closed-domain)
- Tools/Products/Workflows: Multi-attempt answer generation with aggregation to a single final response; best-of-N with a rule-based/verifier filter plus model-based aggregator; improved pass@1 under fixed token budgets
- Dependencies/Assumptions: Access to gold answers or strong reward models; calibrated aggregation to avoid “majority hallucination”; RAG stack to surface evidence for verification
- Enterprise knowledge assistants and SOP support
- Sector: Knowledge management; Customer support; Internal tools
- Tools/Products/Workflows: Parallel retrieval-and-reasoning chains aggregated into a consolidated, cited answer; RSA for multi-hop policy/SOP queries
- Dependencies/Assumptions: Reliable retrieval and citation; organizational preference constraints; internal evaluation datasets for rewards or human-in-the-loop grading
- LLM operations: compute-aware inference scheduling and pipeline simplification
- Sector: AI platforms; MLOps/LLMOps; Cloud inference
- Tools/Products/Workflows: Replace multi-agent “mixture-of-agents” ensembles with a single Spiral-trained model that natively searches and aggregates; controllers that dynamically allocate tokens across sequential/parallel/aggregative compute to maximize pass@1 per token
- Dependencies/Assumptions: Inference orchestration for parallel sampling; budget manager for token/latency; observability to monitor aggregation quality
- Content creation with consensus and synthesis
- Sector: Media; Knowledge work; Technical documentation
- Tools/Products/Workflows: Draft multiple outlines/snippets and aggregate into a coherent final artifact; editorial assistants that synthesize diverse angles into a single balanced draft
- Dependencies/Assumptions: Human oversight for taste, tone, and factuality; no hard automatic reward—use proxy rewards or human feedback
- Data labeling and quality control via self-aggregation
- Sector: Data operations; Annotation platforms
- Tools/Products/Workflows: Generate multiple label rationales and aggregate to a final label; use small gold subsets as rewards to calibrate aggregation behavior
- Dependencies/Assumptions: Availability of spot-check gold; aggregation prompts tuned to avoid bias reinforcement; careful use where labels are subjective
Long-Term Applications
These require further research, scaling, or additional infrastructure (e.g., robust verifiers or domain simulators), or they operate in safety-critical settings.
- Clinical decision support with multi-hypothesis synthesis
- Sector: Healthcare
- Tools/Products/Workflows: Generate differential diagnoses, tests, and management plans; aggregate into a recommendation with cited guidelines and uncertainties
- Dependencies/Assumptions: High-fidelity verifiers/reward models (simulators, outcome data); rigorous human oversight; regulatory approval; strong evidence retrieval
- Autonomous planning and tool-use in robotics and operations
- Sector: Robotics; Supply chain; Manufacturing
- Tools/Products/Workflows: Parallel generation of candidate plans/trajectories with aggregation into robust action plans; integrate with planners/simulators for reward
- Dependencies/Assumptions: Accurate simulators as reward signals; tool APIs and latency budgets; safe exploration constraints; extension of Spiral to tool calls and multi-step control
- Financial modeling and risk scenario synthesis
- Sector: Finance; Risk management
- Tools/Products/Workflows: Generate multiple market/risk scenarios and aggregate into stress-test outputs or policy recommendations; backtest-validated reward signals
- Dependencies/Assumptions: Reliable backtesting and reward models; governance to prevent reward hacking; explainability requirements; strict compliance controls
- Legal analysis and policy drafting with argument aggregation
- Sector: Legal; Public policy; Government
- Tools/Products/Workflows: Produce multiple legal arguments or policy options and aggregate into a unified brief/draft with sources and trade-off analysis
- Dependencies/Assumptions: Human legal review; fact-checking; domain reward models (e.g., quality assessors) to train aggregation; bias and fairness safeguards
- Science copilots for hypothesis generation and experiment design
- Sector: R&D; Pharma; Materials science
- Tools/Products/Workflows: Propose diverse hypotheses/experiments and aggregate into a prioritized plan; iterative cycles with lab/simulation feedback as reward signals
- Dependencies/Assumptions: Reliable simulators or lab-in-the-loop data for rewards; safety constraints; domain-specific tool integration and long contexts
- Dynamic compute allocation policies learned end-to-end
- Sector: AI infrastructure; Edge/on-device AI
- Tools/Products/Workflows: Extend Spiral to learn when to allocate more sequential tokens vs. more parallel attempts vs. deeper aggregation recursion under a token/latency budget
- Dependencies/Assumptions: Training on variable set sizes and recursion depths; scheduler integration; robust credit assignment for budgeted compute
- Secure code synthesis with formal verification aggregation
- Sector: Software security; Safety-critical systems
- Tools/Products/Workflows: Parallel code attempts aggregated and then formally verified (SMT solvers, model checkers) with provable guarantees as rewards
- Dependencies/Assumptions: Mature formal toolchains; performance tuning for solver latency; domain-specific reward shaping
- Knowledge base construction and fact-grounded synthesis
- Sector: Information systems; Enterprise search
- Tools/Products/Workflows: Generate and aggregate candidate assertions from diverse sources with provenance scoring and contradiction detection as part of rewards
- Dependencies/Assumptions: Source reliability models; misinformation detection; scalable retrieval and citation; governance for source selection
- Energy and logistics operations planning
- Sector: Energy; Transportation; Logistics
- Tools/Products/Workflows: Generate multiple dispatch/scheduling plans and aggregate into an optimized plan; use simulators or historical KPIs as reward signals
- Dependencies/Assumptions: High-fidelity, fast simulators; integration with existing optimization solvers; cost/risk constraints encoded in rewards
- Government program evaluation and policy synthesis
- Sector: Public sector; NGOs
- Tools/Products/Workflows: Generate multiple policy designs and synthesize a final proposal with trade-offs; simulate outcomes to provide reward feedback
- Dependencies/Assumptions: Credible socio-economic models; transparent assumptions; oversight and auditing for fairness/impact
Cross-cutting assumptions and dependencies
- Reward availability: Spiral relies on rewards for the final aggregated output. Works best where automatic verifiers exist (math checkers, unit tests, proof checkers, simulators). For open-ended domains, high-quality reward models or human feedback are needed.
- Context length and ordering bias: Aggregation conditions on sets of traces; large context windows and order-robust prompting are needed. The paper notes ordering biases and proposes sampling over unordered sets; real deployments should mitigate order effects.
- Compute budgets and latency: Parallel sampling and aggregation require token and time budgets. Scheduling and budget-aware policies are important for production.
- Generalization beyond math: Results are shown on mathematical reasoning with a 4B model; success in other domains presumes transfer and domain-specific reward engineering.
- Training stack complexity: Requires on-policy RL, set RL credit assignment, and infrastructure for multi-sample data collection (e.g., subset scoring, marginal advantages).
- Safety and governance: Aggregators may synthesize plausible but incorrect ideas. Use verifiers, citations, uncertainty reporting, and human-in-the-loop for high-stakes applications.
Glossary
- Aggregation trace: The final synthesis step that conditions on multiple candidate traces to produce a scored output. Example: "and then generates a final aggregation trace conditioned on those traces"
- Aggregative compute: Inference compute devoted to synthesizing multiple candidate traces into a single refined output. Example: "Aggregative compute. Aggregative inference refers to computation that conditions on multiple candidate traces along with the original problem to produce a final output."
- Bandit settings: A learning setup without state transitions where actions receive immediate rewards; used as an LM training abstraction. Example: "For LLM training (and bandit settings), a more practical formulation is obtained by applying a set-level objective over n i.i.d. generations from the same prompt."
- Best-of-: A test-time strategy that samples multiple solutions and selects the best using a verifier or reward model. Example: "Best-of- methods similarly sample several traces independently, but use a verifier or reward model to select the final output"
- Bradley--Terry comparisons: A probabilistic model for pairwise comparisons used to rank or choose among alternatives. Example: "aggregating traces through pairwise Bradley--Terry comparisons"
- Credit assignment: The process of determining which actions or traces contributed to the final reward. Example: "Credit assignment to each individual trace must recognize that useful and diverse ideas might not yield a correct solution in isolation, yet can be coupled with other attempts to do so during the aggregation phase."
- Group Relative Policy Optimization (GRPO): A policy-gradient variant that optimizes relative performance across grouped samples. Example: "outperforming GRPO by up to 11 scaling efficiency"
- Importance sampling: A technique to reweight samples from one distribution to estimate expectations under another, often used for off-policy correction. Example: "we substitute the standard advantage function in REINFORCE with importance sampling using Tinker"
- LEAN: An interactive theorem prover often used as an oracle verifier in formal reasoning. Example: "for example, LEAN"
- Majority@: Rule-based aggregation that picks the answer most frequently produced among k sampled traces. Example: "The majority@ performance is calculated by sampling independent search traces and then grading the answer selected by a majority of the generations."
- Marginal set advantage: The average advantage assigned to an individual sample based on the advantages of all evaluated sets that include it. Example: "define the marginal set advantage as "
- Monte Carlo estimate: An empirical average used to approximate an expectation or baseline from sampled data. Example: "We construct a Monte Carlo estimate of the baseline score across sets:"
- On-policy Data Collection: Gathering trajectories or generations using the current policy being optimized. Example: "On-policy Data Collection."
- Pass@1: The probability that a single sampled solution is correct. Example: "the y-axis is the pass@1 rate."
- Pass@: The probability that at least one of k independently sampled solutions is correct. Example: "We first evaluate the methods' pass@ performance"
- Policy gradient: A family of methods that optimize policy parameters directly via gradients of expected reward. Example: "The policy gradient of Spiral relies exclusively on the reward assigned to the aggregation traces."
- Polychromic objective: A set-level reward that combines per-sample reward with diversity to encourage exploration-exploitation balance. Example: "An example of such an objective is the polychromic objective defined as "
- Recursive self-aggregation: A multi-step procedure that repeatedly aggregates groups of traces into new candidates across levels. Example: "particularly under hybrid strategies that blend these primitives like recursive self-aggregation"
- REINFORCE: A classic Monte Carlo policy-gradient algorithm using sampled returns and log-probability gradients. Example: "we substitute the standard advantage function in REINFORCE with importance sampling using Tinker"
- Search traces: Independently sampled chains of thought used as candidates for later aggregation. Example: "we will refer to the parallel generations as the search traces"
- Self-aggregation: Model-based synthesis of multiple candidate traces into a new solution, as opposed to rule-based voting. Example: "Similarly, self-aggregation \cite{li2025llmsgeneratebetteranswer, venkatraman2025recursive} can be instantiated with ."
- Self-consistency: An aggregation heuristic that picks the most frequent answer among multiple sampled traces. Example: "self-consistency \cite{wang2022self} can be expressed as $\#1{y \mid x, y_{1:n} = \mathbf{1}\left\{ y = y_i \text{ for some } i \in \arg\max_j N(a(y_j)) \right\},$"
- Sequential compute: Inference compute allocated within a single chain of thought, including reasoning tokens, verification, and revision. Example: "Sequential compute. Sequential inference refers to computation allocated within an individual trace, including intermediate reasoning tokens, self-correction, verification, revision, and tool calls."
- Set advantage: The advantage of a specific set under a set-level objective relative to a baseline over sets. Example: "This allows us to compute the set advantage of each set as:"
- Set reinforcement learning (Set RL): An RL framework where a reward is assigned to a set of actions or generations, coupling their learning signals. Example: "Set reinforcement learning (set RL)~\citep{hamid2026polychromicobjectivesreinforcementlearning} is a framework that assigns a reward to a set of sampled actions, all of which are coupled under a shared learning signal."
- Set-level baseline: A baseline value computed over sets to reduce variance in the set-level policy gradient. Example: "where is a set-level baseline."
- Set-level objective: A reward function defined over a set of generations rather than individual ones. Example: "let be our set-level objective."
- Standard reinforcement learning: Conventional RL that optimizes single trajectories or generations with per-sample advantages. Example: "Spiral uses set reinforcement learning to teach models to produce a set of traces that are collectively useful for an aggregator and standard reinforcement learning to teach models to aggregate the set into improved final responses."
- Token-level entropy: The per-token uncertainty of the model’s output distribution, used to gauge exploration/collapse. Example: "the token-level entropy under Spiral does not collapse as readily as it does under GRPO."
- Tree-search methods: Algorithms that expand and evaluate partial solutions in a search tree guided by value or heuristics. Example: "tree-search methods can further allocate inference compute by filtering or expanding partial traces"
Collections
Sign up for free to add this paper to one or more collections.

