Understanding Performance Gap Between Parallel and Sequential Sampling in Large Reasoning Models
Abstract: Large Reasoning Models (LRMs) have shown remarkable performance on challenging questions, such as math and coding. However, to obtain a high quality solution, one may need to sample more than once. In principal, there are two sampling strategies that can be composed to form more complex processes: sequential sampling and parallel sampling. In this paper, we first compare these two approaches with rigor, and observe, aligned with previous works, that parallel sampling seems to outperform sequential sampling even though the latter should have more representation power. To understand the underline reasons, we make three hypothesis on the reason behind this behavior: (i) parallel sampling outperforms due to the aggregator operator; (ii) sequential sampling is harmed by needing to use longer contexts; (iii) sequential sampling leads to less exploration due to conditioning on previous answers. The empirical evidence on various model families and sizes (Qwen3, DeepSeek-R1 distilled models, Gemini 2.5) and question domains (math and coding) suggests that the aggregation and context length do not seem to be the main culprit behind the performance gap. In contrast, the lack of exploration seems to play a considerably larger role, and we argue that this is one main cause for the performance gap.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies two simple ways to get better answers from big “thinking” AIs (called Large Reasoning Models, or LRMs) when one try isn’t enough. The two ways are:
- Parallel sampling: ask the AI to try many answers independently, then pick the best one (for example, by voting).
- Sequential sampling: ask the AI to try again and again, each time looking at its previous answer and trying to improve it.
Even though, in theory, the second way (sequential) should be more powerful—because the AI can learn from its own attempts—the paper finds that, in practice, the first way (parallel) usually works better on tough math and coding problems. The paper investigates why.
The big questions the authors asked
In simple terms, the authors tested three possible reasons for why parallel tends to beat sequential:
- Does parallel win because it can “combine” answers with a good chooser (the aggregator), like majority vote or picking the best solution?
- Does sequential lose because it has to read longer inputs (its past attempts), which might make it harder to focus?
- Does sequential explore fewer new ideas because it keeps looking at its older answers and gets “stuck” repeating similar solutions?
How did they test it?
Two ways to try multiple solutions
- Parallel sampling (like a class of students): give the same question to many students at once, collect their independent answers, and then choose the final answer by voting or by checking which one works best.
- Sequential sampling (like self-revision): have one student answer, then read their own answer and try to fix or improve it, repeating several rounds.
An “aggregator” is the chooser at the end. Examples:
- Majority voting (used for math): pick the answer most students agree on.
- Best-of-N (used for coding): run tests and pick the program that passes the most tests.
What they measured and where
They ran lots of experiments across:
- Tasks
- Math contest questions (AIME 2025): answers are integers 0–999.
- Coding tasks (LiveCodeBench v5): write code that must pass hidden tests.
- Models
- Multiple popular LRM families and sizes (e.g., Qwen3, DeepSeek-R1 distilled models, Gemini 2.5).
They varied:
- How many solutions they sampled.
- The type of feedback in sequential runs (e.g., “Please re-answer,” or “Review and fix errors”).
- The aggregation method for selecting final answers.
How they tested the three possible reasons
- Aggregation: They gave sequential sampling the same aggregation boosts that parallel gets (e.g., majority vote, best-of-N) to see if that closes the gap.
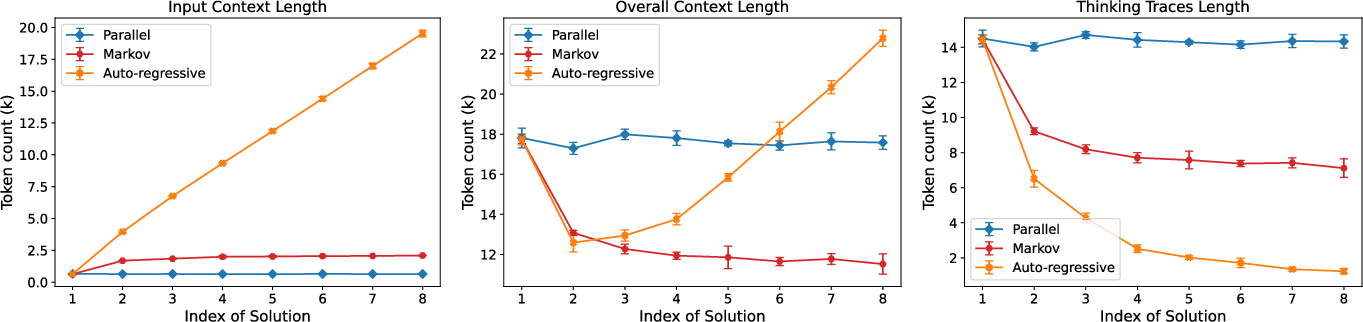
- Context length: They measured how long the inputs were for each method. They also added large amounts of irrelevant text (up to tens of thousands of tokens) in the input for parallel runs to see if long context alone hurts performance.
- Exploration: They checked how similar the multiple solutions were (using text similarity tools) and visualized model attention patterns (“induction heads,” which tend to copy patterns from earlier text) to see if sequential runs keep echoing earlier answers.
They also tried giving very strong, detailed error feedback in coding (including hidden tests), to see if that forced sequential sampling to explore more and improve.
What did they find?
Here are the core findings, and why they matter:
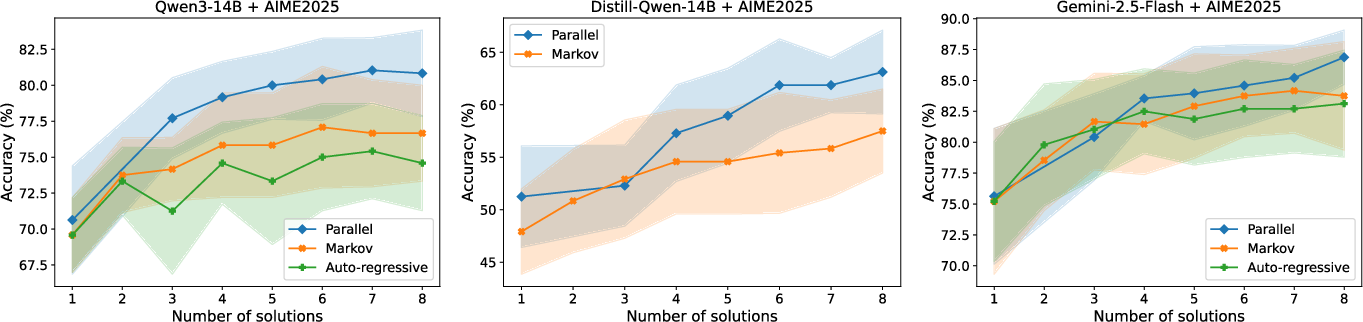
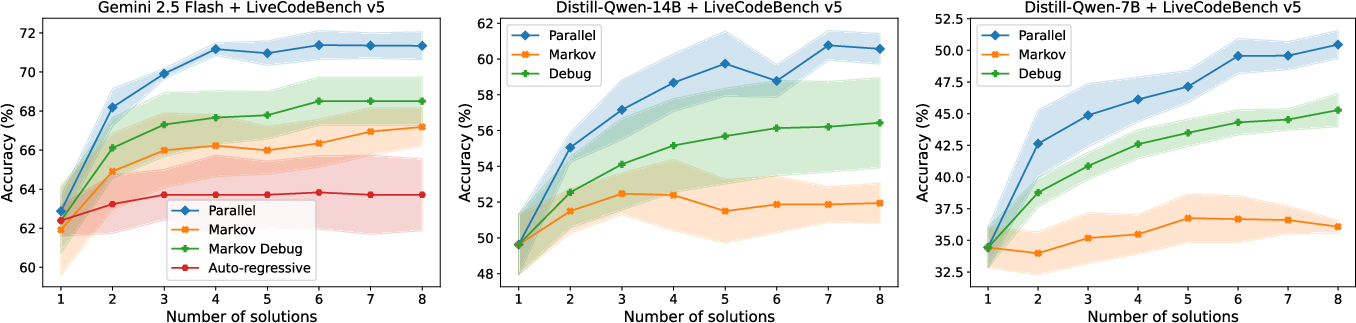
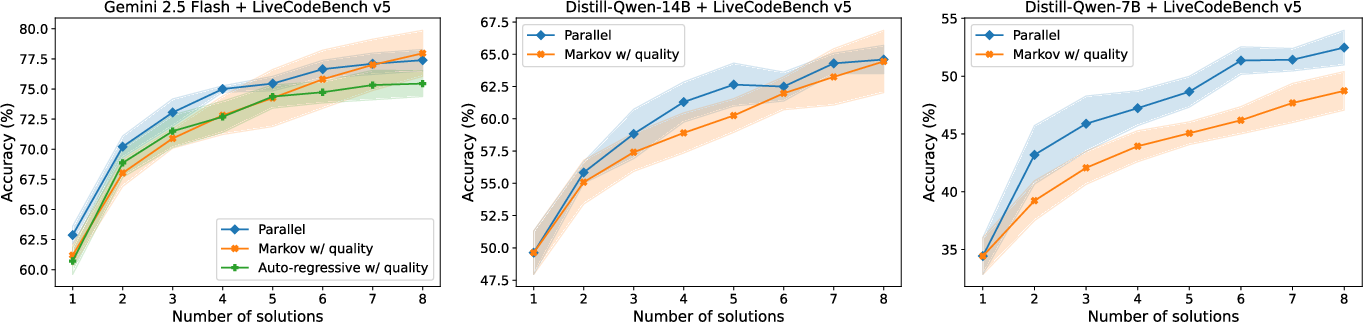
- Parallel generally beats sequential on both math and coding.
- As you sample more solutions, parallel improves strongly.
- Sequential improves less, and sometimes gets stuck repeating similar ideas.
- Aggregation isn’t the main reason parallel wins.
- Giving sequential the same aggregation tricks (like voting or best-of-N) helps a bit but does not close the gap.
- Even with a near-perfect chooser (e.g., using all tests), parallel keeps an edge.
- Longer input context isn’t the main problem for sequential.
- Markov-style sequential (which only feeds the last answer back) has context lengths similar to parallel, yet still underperforms.
- Adding lots of irrelevant text to parallel didn’t significantly harm its performance, suggesting “long input” is not the real culprit.
- The biggest reason: sequential explores less.
- In sequential runs, new attempts often look a lot like previous attempts—even sometimes nearly word-for-word. The model becomes “lazy” and sticks to what it already wrote.
- Solution similarity measurements show sequential attempts are more alike than parallel attempts.
- Attention visualizations show strong “induction heads,” meaning the model is literally attending to (and copying patterns from) earlier solutions while writing the new one. That reduces the variety of ideas.
- With very high-quality feedback, sequential can catch up in some coding cases.
- When the model is told exactly why its code fails (using both public and hidden tests), it gets pushed to truly revise and explore.
- Under this strong guidance, sequential sometimes matches parallel (especially on stronger models), though not always on harder problems or smaller models.
Why this matters: If you want better answers from a reasoning model, simply trying many independent solutions and picking the best is reliably strong. If you do sequential self-improvement, you need to fight the “copying” effect and push for diversity—especially with high-quality, specific feedback.
What does this mean going forward?
- For users and builders of AI systems:
- If you have compute to try multiple solutions, parallel sampling with a good chooser (vote, tests) is a safe, strong choice.
- If you prefer sequential refinement, design it to force exploration:
- Provide concrete, targeted feedback (e.g., exact error messages).
- Limit how much the model sees of its old answers, or prompt it to propose alternative approaches.
- Consider diversity-promoting strategies (change temperature, sampling, or explicitly ask for different reasoning paths).
- For researchers:
- The main performance gap comes from reduced exploration in sequential runs, not from aggregation or context length.
- Mechanistic findings (induction heads that copy previous answers) explain why sequential generations converge to similar solutions.
- Training or prompting methods that reduce over-copying, encourage branching, or introduce disciplined “debate” among ideas could improve sequential methods.
In short: Parallel sampling wins because it explores more. Sequential sampling tends to copy itself and needs strong, specific guidance to break out of loops. Designing better feedback and diversity mechanisms is key to making sequential self-improvement live up to its potential.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research:
- Causal mechanism behind reduced exploration
- The paper correlates induction heads and higher solution similarity with poorer sequential performance but does not establish causality. Conduct targeted interventions (e.g., attention-head masking/patching, attention-dropout on prior-answer tokens, anti-copy losses at decode-time) to test whether suppressing pattern-copying increases exploration and improves accuracy.
- Formal theory of expressivity vs performance
- The claim that sequential sampling is theoretically more expressive than parallel sampling is not formalized. Develop a formal framework (e.g., an MDP or stochastic process model of iterative refinement with dependent samples) that predicts when sequential should dominate, and characterize regimes where dependence harms aggregator efficacy.
- Compute- and token-budget parity
- Comparisons do not equalize total tokens, wall-clock time, or total compute across strategies. Re-run experiments under matched budgets (e.g., equal total tokens generated or equal latency constraints) to isolate where each approach is more compute-efficient.
- Decoding hyperparameters and exploration control
- Sequential sampling was evaluated with “best recommended” settings; the sensitivity to temperature, top-p, repetition penalties, and per-round temperature schedules is untested. Systematically optimize decode hyperparameters per strategy and per round to determine whether exploration deficits are hyperparameter-driven.
- Diversity metrics beyond embedding cosine similarity
- The diversity proxy (off-the-shelf embedding cosine similarity) may be insensitive for code/math. Introduce task-appropriate diversity measures (e.g., AST edit distance and test behavior diversity for code; step-level proof-structure or equation-tree diversity for math) and relate them quantitatively to aggregator gains.
- Broader task coverage and data scale
- Evidence is limited to AIME2025 (30 items) and LiveCodeBench v5. Validate on larger and more diverse reasoning tasks (e.g., GSM8K/DeepMath variants, theorem-proving, planning, multi-hop QA, scientific reasoning) to test generality and statistical robustness.
- Sequential-feedback design space
- Only two feedback prompts and simple “run error” prompts are explored. Evaluate richer, structured feedback (checklists, rubrics, chain-of-critique), calibrated uncertainty feedback, targeted counterexample generation, and tool-assisted diagnostics (static analyzers, linters, fuzzers, property-based tests).
- Verifier/aggregator quality and dependence-awareness
- Aggregation is limited to majority voting (math) and best-of-N (code) with simple rewards. Study stronger and dependence-aware aggregators (learned verifiers, debate-based adjudication, confidence-weighted voting, DPP-based or coverage-aware selection) that explicitly account for correlated candidates in sequential chains.
- Sequential variants not evaluated
- The study omits tree-based or search-based methods (Tree-of-Thought, MCTS/UCB-guided sampling, best-first search), sequential-with-branching, and beam-search hybrids. Compare these to pure parallel and pure sequential to identify regimes where structured search offsets dependence costs.
- “Laziness” diagnosis vs prompt anchoring
- It is unclear whether reduced exploration stems from model inductive bias, prompt anchoring (“Please re-answer”), or instruction-following alignment. Test prompts that explicitly require diverse alternatives, forbid reuse of prior steps, or penalize overlap; measure the trade-off with solution quality.
- Context-length findings’ external validity
- The irrelevance-context ablation uses unrelated code files and focuses on coding with a single model variant. Test long relevant contexts, math-specific contexts, more model families, and thought-summarization strategies (e.g., different compressions) to confirm that input length is not a hidden confounder.
- Why Markov > autoregressive sequential?
- Markov sequential often outperforms autoregressive sequential, but the mechanism is unexamined. Analyze whether reduced copying, altered attention patterns, or shorter contexts explain the gap; ablate the last-answer inclusion vs full history inclusion explicitly.
- Induction head characterization and quantification
- Attention visualizations are anecdotal. Quantify induction head prevalence across layers/heads, measure attention mass to prior answers, and correlate with similarity and accuracy per instance. Perform causal ablations (pruning/suppressing specific heads) and measure downstream effects.
- Enforcing or rewarding exploration in sequential chains
- No mechanisms are tried to actively promote diversity in sequential rounds. Explore negative similarity rewards, coverage-driven sampling, mutual-repulsion decoding, nucleus/temperature annealing across rounds, or stochastic prompting to counteract mode collapse.
- Realistic high-quality feedback for math
- The only high-quality sequential feedback evaluated uses private tests for code, which is unrealistic and not transferrable to math. Develop math verifiers/critics (symbolic checkers, numeric consistency tests, proof checkers, self-consistency with derived constraints) and test whether they close the gap.
- Tool-augmented sequential debugging for code
- Beyond public/private tests and LLM-generated tests, investigate integrating fuzzing, mutation testing, static analysis, semantic diffs, and program repair tools into sequential feedback loops to see if exploration and correction improve without relying on hidden tests.
- Interaction between dependence and aggregator efficacy
- The detrimental effect of sample dependence on aggregator performance is hypothesized but not quantified. Model and measure how varying degrees of dependence (e.g., by mixing independent-with-dependent candidates) affect aggregator gains in practice.
- Per-problem difficulty and failure-mode analysis
- While harder code questions show larger gaps in some cases, there is no fine-grained failure taxonomy. Characterize where sequential fails (anchoring on wrong approach vs minor bug loops vs premature “passed public tests” stopping) and design targeted interventions per failure type.
- Scaling with much larger models and deliberate-training
- The study uses mid-sized models (e.g., 7B–14B and an API family). Evaluate larger “deliberate” or chain-of-thought-optimized models and long-context-specialized architectures to see if the sequential deficit diminishes with scale or training tailored for iterative refinement.
- Compute/latency and systems considerations
- Wall-clock, memory, and parallelism trade-offs are not analyzed. Provide end-to-end cost curves (tokens, latency, GPU utilization) to inform when parallel vs sequential is preferable in deployment.
- Exploration vs single-sample quality trade-offs
- The paper does not characterize how increased diversity affects single-run correctness or aggregator efficacy. Map the Pareto frontier between diversity and per-sample quality for each strategy to inform optimal operating points.
- Stability across seeds and statistical significance
- With small benchmarks and few repeats, significance is unclear. Report confidence intervals and statistical tests across more seeds/problems to ensure observed gaps are robust.
- Generalization to multimodal reasoning
- All experiments are text-only. Test whether the same parallel-over-sequential advantage and “copying” dynamics hold for multimodal reasoning with long visual/audio contexts where sequential context might be more beneficial.
Practical Applications
Immediate Applications
Below are actionable ways to operationalize the paper’s findings now, with sector links, suggested tools/workflows, and feasibility notes.
- Software engineering (code generation): adopt best-of-N parallel sampling with test-based selection
- How: generate N candidate programs in parallel; score with public unit tests plus LLM-generated tests; select the highest-scoring solution.
- Tools/workflows: integrate into IDEs/CI (e.g., GitHub Actions, Jenkins) with sandboxed execution; add “generate tests” step; deduplicate tests; run best-of-N selection.
- Assumptions/dependencies: unit tests or synthetic tests must be available and relevant; sandbox and resources for code execution; extra compute/latency budget; guardrails for non-determinism and flakiness.
- AI agent frameworks (reasoning-heavy tasks): default to parallel-then-aggregate instead of iterative self-refinement
- How: replace multi-round self-critique loops with independent parallel attempts; apply majority voting (discrete answers) or verifier scoring (structured outputs).
- Tools/workflows: LangChain/LlamaIndex orchestration nodes for parallel sampling; plug-in aggregators (majority vote, best-of-N, learned verifiers).
- Assumptions/dependencies: clear aggregation criterion; sufficient budget for N>1; for coding or planners, an executable/verifier is required.
- Prompting and UX: prefer minimal “Please re-answer.” over elaborate self-refinement; if sequential is necessary, use first-order (Markov) context only
- How: avoid feeding full prior chains; either no prior solution in context or only the last answer/code block.
- Tools/workflows: prompt templates with “reset chat” for each attempt; context-pruning middleware.
- Assumptions/dependencies: slight loss of continuity in multi-turn UX; measurable gains from reduced pattern copying (“induction”) and increased exploration.
- Diversity monitoring and early-stop for stagnant sequential chains
- How: compute embedding-based cosine similarity across sequential solutions; if similarity remains high, abort the chain and switch to fresh parallel samples.
- Tools/workflows: off-the-shelf embedding models (e.g., text-embedding-3-small) and simple thresholds; logging dashboards for “diversity over time.”
- Assumptions/dependencies: embedding API/compute; threshold tuning per task; additional latency per monitoring step.
- Robotics and planning: parallel plan proposal with simulator-scored best-of-N
- How: propose multiple independent plans; score via fast simulation or cost functions; select best.
- Tools/workflows: simulation stacks (Gazebo, Isaac) or learned cost models; batch evaluation.
- Assumptions/dependencies: access to a fast and faithful simulator; clear scalar objective; computational resources.
- Customer support/troubleshooting: parallel diagnostic paths with rule- or test-based selection
- How: produce multiple root-cause analyses or action sequences; score with rule engines or quick probes/tests; pick best.
- Tools/workflows: device probes, runbooks, rule-based verifiers.
- Assumptions/dependencies: existence of automated checks; mapping between proposed actions and measurable outcomes.
- Finance/data analysis: parallel hypothesis/code generation with backtest-based selection
- How: generate N scripts or strategies; backtest each; select by risk-adjusted performance with holdouts.
- Tools/workflows: backtesting frameworks; data versioning; result caching.
- Assumptions/dependencies: strong risk controls to avoid overfitting; access to compute and historical data; compliance review.
- Education (math tutoring): parallel solution proposals with majority vote and curated explanation
- How: sample multiple independent solutions; aggregate the final answer; present the top solution and one alternative with reasoning.
- Tools/workflows: answer box extraction; simple majority voting.
- Assumptions/dependencies: tasks with unambiguous answers; educator oversight for pedagogy.
- Red-teaming and safety evaluation: use parallel sampling to broaden failure-mode discovery
- How: run many independent generations to expose diverse behaviors; prioritize inspection via learned or rule-based scorers.
- Tools/workflows: evaluation harnesses, toxicity/hallucination detectors; batch inference.
- Assumptions/dependencies: safety scorers/verifiers; compute budget; dataset coverage.
- Inference operations (throughput/latency): batch-parallel sampling for better ROI than longer chains
- How: allocate test-time compute to concurrent parallel samples rather than long sequential loops; tune N for target latency.
- Tools/workflows: server-side batching, KV-cache management; concurrency scheduling.
- Assumptions/dependencies: adequate GPU/TPU capacity; latency SLAs; cost controls.
- Academic evaluation practices: standardize reporting with parallel vs sequential sampling and aggregators
- How: benchmark with both strategies; report N, aggregation method, and verifier(s).
- Tools/workflows: reproducible evaluation scripts; public test generation recipes.
- Assumptions/dependencies: community adoption; clear task-specific aggregators.
- Practical rule-of-thumb on context length: do not fear moderate input-context increases; focus on exploration instead
- How: prioritize sampling strategy over aggressive context trimming; avoid over-reliance on long autoregressive chains.
- Tools/workflows: context management policy; token accounting.
- Assumptions/dependencies: models tested (Qwen3, DeepSeek-R1-Distill, Gemini 2.5); applicability may vary for other LLMs.
Long-Term Applications
These require further research, new tooling, domain verifiers, or model/infrastructure changes.
- Exploration-enhanced sequential methods (training and inference)
- Idea: counter “induction head” pattern-copying by rewarding diversity or penalizing low-edit updates in sequential chains; train with diversity regularizers or RL from exploration signals.
- Potential products: “Diverse-Refine” decoding; exploration-aware agents that guarantee novelty across rounds.
- Dependencies/risks: retraining or adapter methods; trade-offs with stability and correctness.
- Verifier ecosystems and “VerifierHub” for cross-domain best-of-N
- Idea: unify programmatic verifiers (compilers/tests/fuzzers), symbolic math solvers, theorem provers, constraint solvers, retrieval-based fact-checkers, and domain-specific scorers (e.g., legal/clinical).
- Sectors: software, math, legal, healthcare, engineering.
- Dependencies/risks: coverage and correctness of verifiers; integration complexity; privacy and regulatory hurdles.
- Automatic high-quality feedback generation for sequential refinement
- Idea: synthesize private/hidden tests, fuzz cases, or counterexamples to keep refinement going when public tests pass (closing the parallel–sequential gap shown for coding).
- Tools: test generation via LLMs + fuzzing (e.g., AFL-like), program analysis, concolic testing.
- Dependencies/risks: false positives/negatives; computational cost; security sandboxing.
- Induction-aware decoding controls
- Idea: attention masking/penalties to reduce copying from prior answers; memory gating to limit cross-round pattern transfer when exploration is desired.
- Tools: decoding-time attention modifiers; plug-in attention controllers.
- Dependencies/risks: access to low-level model internals; potential degradation on tasks that benefit from copying.
- Dynamic agent schedulers that switch between parallel and sequential modes
- Idea: use diversity metrics and verifier scores to adaptively choose mode and budget; escalate to parallel if sequential stalls.
- Products: “Exploration Scheduler” for agent frameworks.
- Dependencies/risks: non-trivial policy tuning; monitoring overhead.
- Hardware and serving optimizations for multi-sample parallelism
- Idea: specialized batching/kernels, KV-cache strategies, and cluster schedulers optimized for N-way sampling and aggregation.
- Sectors: cloud providers, enterprise MLOps.
- Dependencies/risks: engineering effort; vendor support.
- Sector-specific deployments with robust verifiers
- Healthcare: parallel differential diagnoses with guideline-based and retrieval-based scoring, clinician-in-the-loop.
- Legal: parallel brief generation with case-law consistency and citation verifiers.
- Engineering/energy: parallel design options scored by simulation constraints.
- Dependencies/risks: high-stakes verification, regulation, liability frameworks, auditability.
- Policy and governance
- Idea: standards for reporting test-time compute and sampling strategies in evaluations; best-practice recommendations to use parallel sampling for safety red teaming.
- Dependencies/risks: community consensus; coordination across standards bodies.
- Education research and tools
- Idea: tutors that produce multiple solution paths and teach consensus-building; diversity-aware pedagogy for reasoning.
- Dependencies/risks: cognitive load for learners; need for alignment with curricula.
- Benchmarks and diagnostics for exploration
- Idea: include diversity metrics (e.g., embedding similarity) and “thinking-token” budgets in benchmarks; release datasets that reward exploration rather than repetition.
- Dependencies/risks: benchmark design consensus; compute requirements.
- “Parallel Reasoning as a Service” APIs
- Idea: hosted endpoints exposing N-sample generation with pluggable aggregators/verifiers and diversity controls; configurable for domains (code, math, planning).
- Dependencies/risks: per-domain verifier integration; cost transparency; security posture.
Notes and global assumptions:
- Findings generalize across tested LRMs (Qwen3, DeepSeek-R1-Distill, Gemini 2.5) on math and code; different domains/models may vary.
- Aggregation quality is pivotal: majority vote works for discrete answers; test-based scoring works for code; other domains need reliable verifiers.
- Compute and latency overheads are the main practical constraints; careful N and batching are essential.
- High-quality feedback (e.g., private tests) may be infeasible in production; use as a north star for research.
Glossary
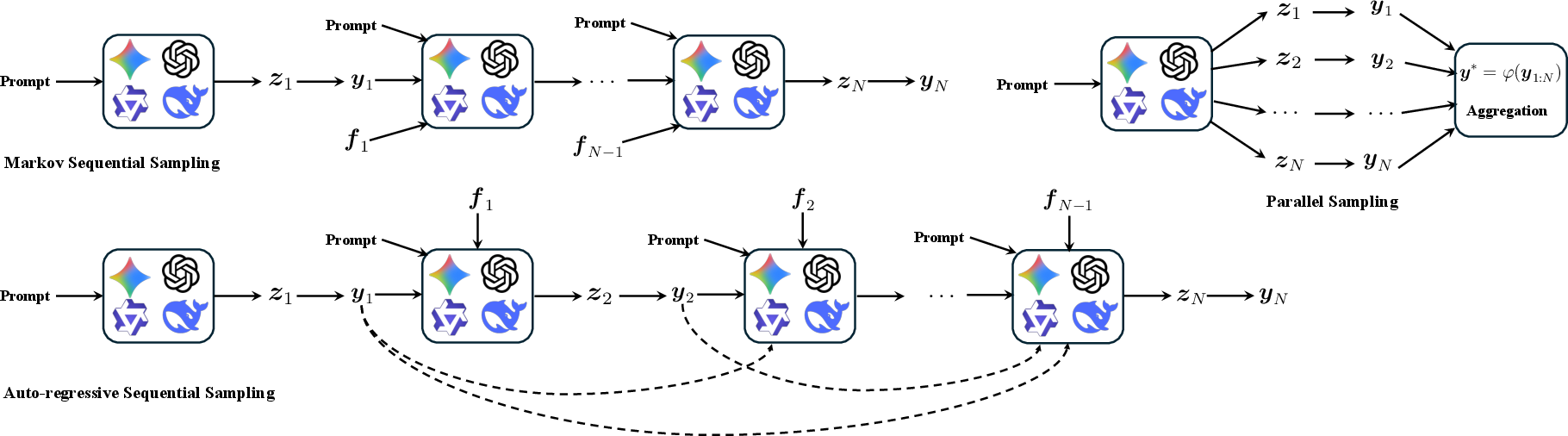
- Aggregation operator: A function that combines multiple candidate solutions into a single final answer. "Then an aggregation operator is adopted to select the final solution:"
- Attention maps: Visual representations of how attention heads distribute focus over input tokens during generation. "In this section, we provide mechanistic analysis by visualizing the attention maps to understand how previous solutions affect the exploration in sequential sampling."
- Auto-regressive sequential sampling: A scheme where each new solution is generated conditioned on the entire history of previous solutions within the context. "We term the above context management auto-regressive sequential sampling, which arranges full history in the context."
- Best-of-N aggregation: An aggregation strategy that selects the highest-scoring solution among N sampled candidates based on a reward or verifier signal. "For parallel sampling, we use best-of-N aggregation to select solutions."
- Cosine similarity: A measure of similarity between two vectors (e.g., embeddings) based on the cosine of the angle between them. "measure the cosine similarity (ranged from -1 to 1) among solutions."
- Feedback prompt: An auxiliary instruction inserted between rounds to encourage refinement or further attempts. "there is another feedback prompt promoting LRMs to enter the next round of sampling."
- Induction head: A specific attention head behavior that copies or references previous patterns to generate current tokens. "In mechanistic literature, induction head is a special attention head in Transformers, which looks back to previous instances when generating current tokens"
- In-context learning: The ability of a model to learn patterns and perform tasks using context provided in the prompt without parameter updates. "and regarded as the primary source of in-context learning."
- Inverse test-time-scaling: A phenomenon where increasing test-time compute (e.g., longer thinking) can worsen performance. "may result in inverse test-time-scaling or overthinking."
- Majority voting: An aggregation method where the most frequently proposed answer among samples is selected as final. "Both sampling approaches use majority vote aggregation."
- Markov sequential sampling: A sequential sampling variant that conditions only on the most recent previous solution (first-order Markov assumption). "we also consider a simpler context management called (first-order) Markov sequential sampling, which only considers the last history"
- Mechanistic analysis: An approach that inspects internal model components (e.g., attention patterns) to explain behaviors. "In this section, we provide mechanistic analysis by visualizing the attention maps to understand how previous solutions affect the exploration in sequential sampling."
- Overthinking: Generating excessively long or complex reasoning that degrades answer quality. "may result in inverse test-time-scaling or overthinking."
- Parallel sampling: Generating multiple solutions independently and then aggregating them. "Parallel sampling. We independently sample multiple thinking traces and solutions"
- Perfect verifier: An idealized evaluator that can always identify the correct solution among candidates. "requires a perfect verifier to select the best solution."
- Private tests: Hidden evaluation cases used to assess correctness beyond publicly visible examples. "There are large amounts of private tests, which are hidden from LRMs."
- Public tests: Example test cases provided with a problem that can be used during development or debugging. "public tests are provided to serve as example input and output."
- Running errors: Execution feedback (e.g., exceptions, wrong answers) from running code solutions against tests, used to guide refinement. "use running errors on public tests by prompting ``The above code is incorrect and got the following error: {RUNNING_ERRORS}. Please re-answer the question based on the running errors.''"
- Self-refinement feedback: A prompt that asks the model to critique and improve its prior answer. "We consider two feedback prompts:
Please re-answer.'' andPlease review your previous response and find problems with your answer. Based on the problems you found, improve your answer.'' (self-refinement feedback)" - Sequential sampling: Generating a series of solutions where each depends on previous outputs. "Sequential sampling. The -th thinking trace and solution depend on previous sampling output."
- Thinking traces: The intermediate reasoning tokens or chain-of-thought produced before final answers. "By scaling the thinking traces, LRMs demonstrate improved performance."
- Thought summaries: Compressed representations of long thinking traces inserted into context to save space. "compress thinking traces into thought summaries."
Collections
Sign up for free to add this paper to one or more collections.

