Abstract: Prediction-powered inference integrates a small gold-standard dataset with large pseudo-labeled data, whose labels are generated by machine learning methods, to enhance statistical inference. In modern applications, multiple data sources and diverse machine learning methods often give rise to multiple pseudo-labeled datasets, each encoding potentially different aspects of the underlying information. However, how to optimally combine multiple data sources and machine learning methods for statistical inference remains unclear. To address this problem, we propose a multi-source prediction-powered inference method by aggregating multiple pseudo-labeled datasets together, where the aggregation weights are estimated by minimizing the asymptotic volume of the resulting confidence region. We study both homogeneous settings, where the source and target distributions coincide, and heterogeneous settings, where distributional discrepancies arise between source and target distributions, including covariate shift and domain shift. Theoretically, we establish the asymptotic normality of the proposed estimator and show that the resulting confidence-region volume is asymptotically equivalent to the oracle optimal volume within the proposed weighting class. We further characterize when our method yields smaller confidence regions compared with both classical target-only inference and single-source prediction-powered inference. Simulation studies and a real-data application on dual-energy X-ray absorptiometry measured high body fat prevalence show that MPPI can reduce confidence-region volume while maintaining inferential validity in the settings considered.
The paper introduces the MPPI procedure that integrates multiple pseudo-labeled datasets to minimize the asymptotic volume of confidence regions.
It employs optimal weighting across heterogeneous sources, ensuring robust calibration and maintaining nominal type I error rates.
Empirical evaluations on simulated and real-world health survey data demonstrate narrower confidence intervals and enhanced inference power.
Multi-Source Prediction-Powered Inference: A Technical Synthesis
Introduction and Motivation
The paper "Multi-Source Prediction-Powered Inference" (2606.21232) presents a unified statistical inference framework integrating multiple pseudo-labeled datasets, each constructed using heterogeneous ML sources, to enhance parameter inference when a small gold-standard labeled (target) dataset is available. The methodological centerpiece is the Multi-Source Prediction-Powered Inference (MPPI) procedure, which leverages targeted weights for optimal aggregation, aiming to minimize the asymptotic volume of resulting confidence regions. This unifies and generalizes prior PPI-style estimators under both homogeneous and heterogeneous distributional regimes.
Methodological Framework
The inference target is the minimizer ∗ of an expected loss with respect to the target distribution P covered by a gold-standard labeled sample. The observable data consist of one labeled target dataset (size N0) and S unlabeled source datasets (sizes Ns), each equipped with a pretrained ML pseudo-labeler f(s) and possibly distinct source distributions Q(s). For each source, the approach constructs a pseudo-labeled prediction dataset, then calibrates the associated empirical risk via a rectification term using target labels.
The fundamental MPPI estimator is a weighted minimization of a composite risk:
θ(w)=argθ∈Θmin[w0R(0)(θ)+s=1∑SwsMR(s)(θ)],
where the vector w resides on the simplex, and MR(s)(θ) is the modified risk utilizing both pseudo-labeled and genuine target-labeled samples for calibration. Unlike parameter or predictor averaging, this criterion operates at the loss level, maintaining population interpretation for the resulting estimator.
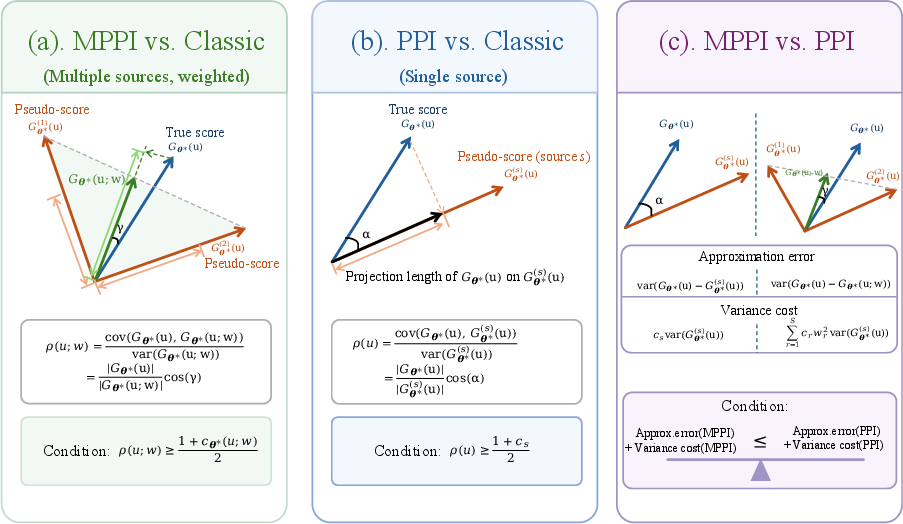
Figure 1: The comparisons among MPPI, PPI, and classic inference, highlighting improved efficiency from optimal aggregation.
Weight selection is performed to directly minimize the log-determinant of the asymptotic covariance matrix of P0, thus shrinking the volume of Wald-type confidence regions. Optimization is handled via a specialized iterative algorithm (Algorithm 1 in the text), converging rapidly in empirical studies.
Extensions to Distributional Shift
Covariate Shift
Under covariate shift, each P1 differs only in covariate margins—conditional response distributions are preserved. Source risks are importance-weighted using estimated density ratios P2. Cross-fitting is employed to prevent overfitting in nuisance parameter estimation and maintain separation between alignment and inference, crucial for asymptotic normality.
Domain Shift
When domain shift is present, source and target covariates are related by unknown, measure-preserving transport maps, possibly nontrivial and not restricted to marginal changes. Empirical source risks are aligned via estimated transports (P3, P4), and rectified using target data. Again, weighting is optimized using plug-in estimates of the covariance under the induced alignment.
Theoretical Properties
Under standard regularity, identifiability, and stable source-target alignment (density ratio or transport estimation), the MPPI estimator enjoys asymptotic normality at a P5 rate, with the covariance matching that of an oracle estimator using the population-optimal weights:
P6
Plug-in confidence regions have nominal frequentist coverage and their volume approaches that of the oracle, as substantiated by explicit corollaries linking empirical and oracle determinants.
Theoretical comparison with classical (target-only) and single-source PPI estimators is formalized via interpretable sufficient conditions. Specifically, efficiency gains arise when the aggregated pseudo-label directional score is more closely aligned with the true-label score, while variance costs due to pseudo-label noise remain subdominant. In cases where sources are complementary, MPPI can achieve reductions in confidence region width unattainable by any source in isolation.
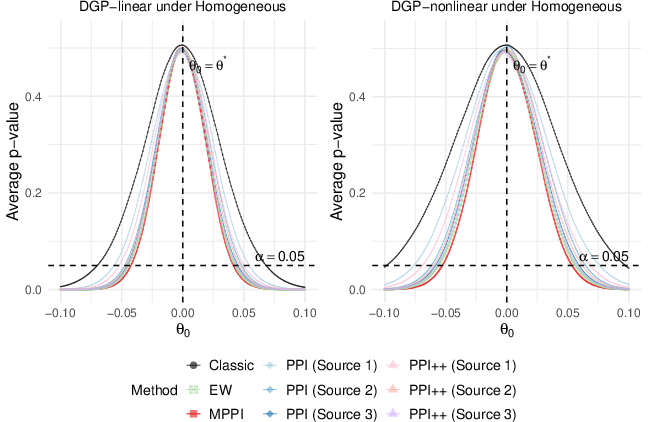
Figure 2: The relationship between P7 in P8 and P9-values for mean inference (homogeneous case), illustrating type I error control and sharper discrimination with MPPI.
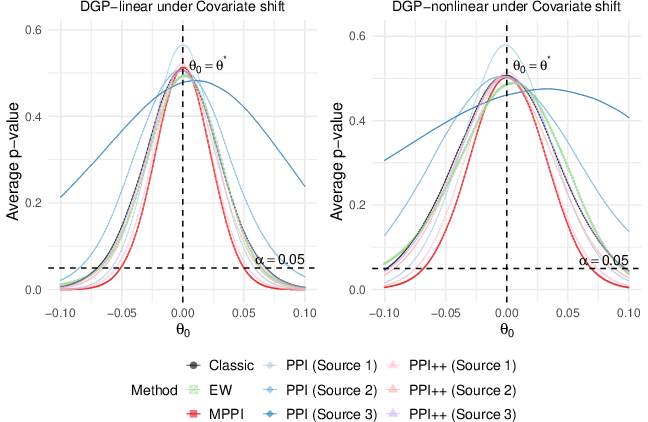
Figure 3: Covariate shift N00-value curves; aggregation via MPPI improves sensitivity compared to single-source methods, particularly when some sources are misaligned.
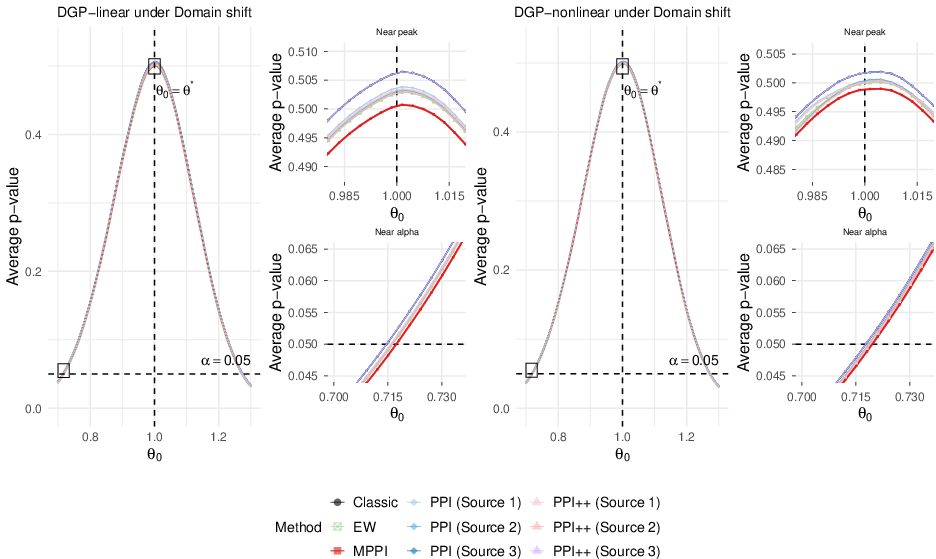
Figure 4: Domain shift setting; MPPI maintains robust inferential performance across shift, with N01-value behavior comparable or superior to alternatives.
Empirical Evaluation
Simulation studies encompass mean and regression inference under all aforementioned regimes. In all empirical configurations, MPPI systematically delivers confidence regions with competitive or strictly smaller volume than all baselines (target-only, single-source PPI, PPI++). Type I error rates are consistently maintained at the nominal level, and hypothesis tests possess higher power with MPPI, highlighting its efficacy in integrating heterogeneous, complementary sources.
Table 1 details weight allocations, revealing that MPPI correctly upweights informative sources and downweights weak or misaligned ones, adapting to both homogeneous and heterogeneous settings.
A real-world application on U.S. health survey data for DXA-measured high body fat prevalence reconstructs reliable inference from small, labeled samples by leveraging large, auxiliary (pseudo-labeled) sources. MPPI gives narrower confidence intervals for prevalence without inflating type I error, confirming practical benefit over classical or naive pooling approaches.
Practical and Theoretical Implications
The proposed MPPI framework generalizes prior work by accommodating multiple, possibly misspecified or partially aligned sources. The formal results elucidate mechanistic determinants of when multi-source aggregation is beneficial, with score-alignment and variance balance at the core. Practically, MPPI is applicable in biomedical, environmental, and high-dimensional applications where pseudo-labels are abundant but target labels remain scarce.
Theoretically, MPPI extends the classical transfer learning paradigm by addressing confidence region optimality, not only point estimation or prediction, and by integrating rigorous cross-fitting and alignment steps into the inferential pipeline.
Conclusion
Multi-Source Prediction-Powered Inference provides a principled framework for leveraging multiple, heterogeneous pseudo-labeled datasets to enhance statistical inference on target parameters. The approach attains asymptotically optimal confidence region volume in both homogeneous and shifted-distribution contexts, with formal guarantees and strong empirical performance. Future directions include extensions to decision-theoretic objectives and frameworks accommodating generatively synthesized auxiliary data.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.