- The paper introduces a multi-task framework leveraging global (GRePPI) and adaptive (ARePPI) recalibration to enhance inference efficiency using proxy data.
- It employs nonlinear recalibration mappings to achieve significant variance reduction, outperforming traditional affine transformations.
- Empirical studies, including a large-scale LLM auditing case, demonstrate reduced CI widths and lower MSE in sparse-label regimes.
Multi-Task Prediction-Powered Inference for AI Evaluation and Social Science
Motivation and Problem Setting
The paper "Prediction-Powered Inference Across Many Tasks for AI Evaluation & Social Science Research" (2605.29249) addresses a key challenge in modern statistical analysis: constructing valid, efficient inference across numerous related tasks with sparse high-quality labels. These tasks arise in settings such as LLM evaluation over varying prompts, demographic subgroups, or models, as well as in survey-based social science research where questions, populations, or measurement conditions yield distinct tasks. While abundant proxy measurements (e.g., model predictions, automated scores) are available, task-specific ground-truth labels (e.g., human annotations) are costly and limited.
Prediction-powered inference (PPI) utilizes proxy data to enhance estimation and inference in statistically robust ways. However, conventional approaches treat each task independently, failing to capitalize on shared structure (such as systematic bias patterns or annotation relationships) across related tasks. This deficiency is especially pronounced in the low-label regime, where variance in bias correction becomes the primary bottleneck.
Methodological Advances: GRePPI and ARePPI
To address these limitations, the paper introduces a principled multi-task PPI framework, enabling information-sharing across related tasks via cross-task recalibration:
- Globally Recalibrated PPI (GRePPI): The method fits a recalibration function (mapping proxy predictions to improved surrogate outcomes) using labeled data from all tasks except the target task, then performs task-specific bias correction to maintain valid per-task inference. This leave-one-task-out construction exploits consistent proxy–ground-truth relationships while anchoring validity within the target task's labels.
- Adaptive Recalibrated PPI (ARePPI): Where task heterogeneity is pronounced, ARePPI employs cross-validated blending of global and local recalibration functions. By optimizing correlation with target outcomes, it adaptively balances global information with task-specific recalibration.
The theoretical results assert that only nonlinear recalibration mappings (e.g., using isotonic regression or highly nonparametric models) can provide variance reduction beyond power-tuned PPI. Affine recalibrations (linear rescaling/shifting) cannot improve asymptotic efficiency, a claim rigorously proved and quantified by characterizing the optimal surrogate transformation.
Statistical and Geometric Analysis
The detailed geometric analysis demonstrates that under the finite-population mean estimation regime, power-tuning minimizes estimator variance according to the correlation between proxy and ground-truth outcomes. The key findings are:
- The optimal estimator variance V⋆(s) depends solely on the squared correlation between proxy and recalibrated surrogate outcomes.
- Affine recalibrations (linear transformations) are invariant in terms of efficiency; only nonlinear mappings exploiting true functional structure can yield further gains.
- The maximum achievable variance reduction is bounded by the difference between regression R2 and the simple correlation squared, quantifying benefits of nonlinear recalibration.
Case Study: Auditing LLM Behavior During the 2024 U.S. Election
The authors conduct a substantial empirical case study using the dataset of [largescale2025cen], comprising daily queries of 12 LLMs over 186 election-related base questions and 22 prompt variations, with special focus on demographic and political identity steering. Tasks correspond to model–prompt pair comparisons, each task consisting of the mean "deep meaning similarity" between response pairs as measured by human annotators.
A large-scale annotation effort yields nt=40 labeled pairs per task over ∣T∣=72 tasks, resulting in 14,400 human annotations. Model predictions (surrogates) are procured via calibrated prompts. Evaluation metrics include confidence interval (CI) widths, mean squared error (MSE), and empirical coverage.
Application of GRePPI and ARePPI yields the following strong numerical results:
- CI Width Reduction: Both GRePPI and ARePPI achieve sharper confidence intervals than classical, single-task PPI or RePPI, especially when labels are scarce, indicating successful exploitation of cross-task structure. This is evident in the reduction in Wald confidence interval widths.
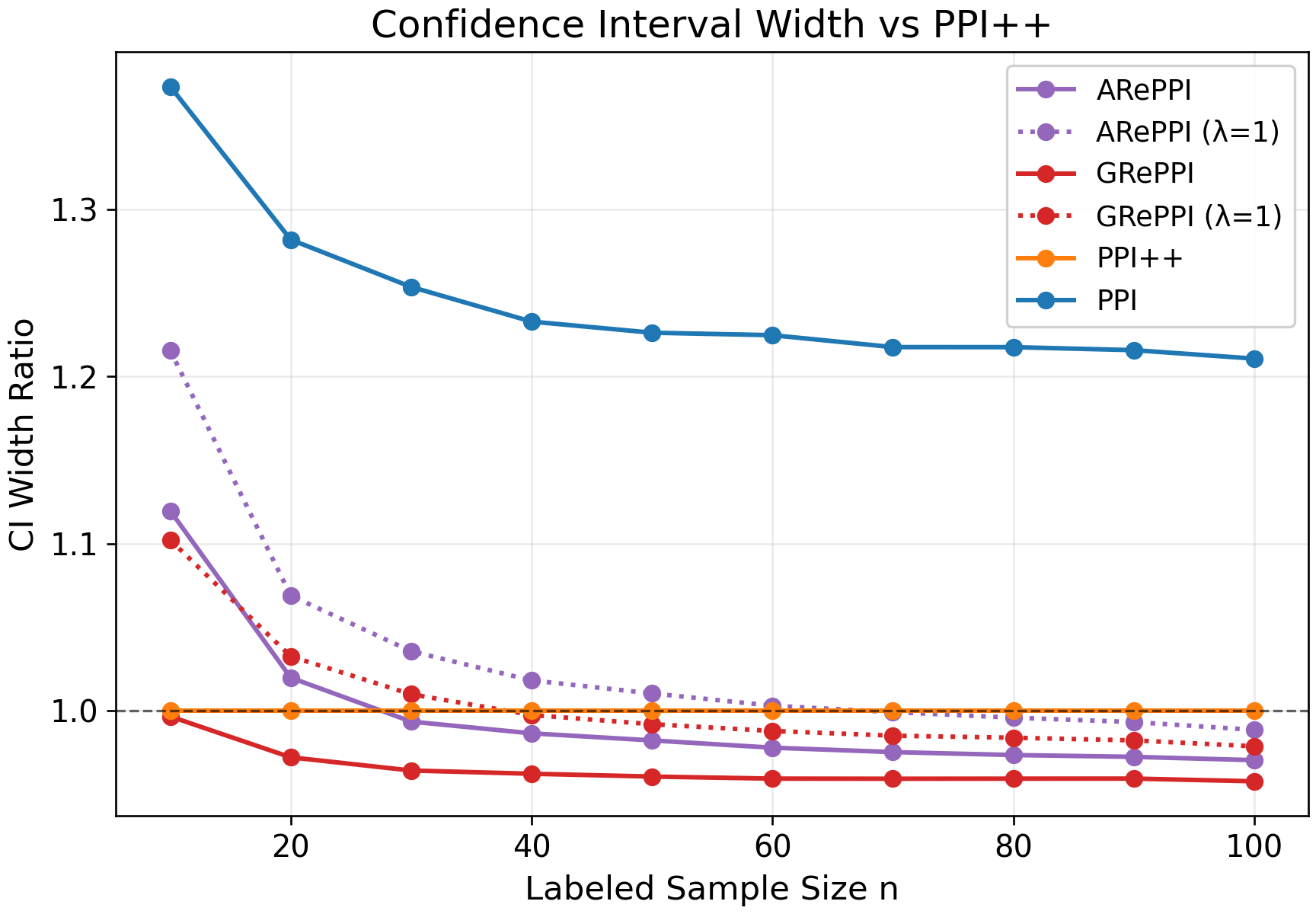
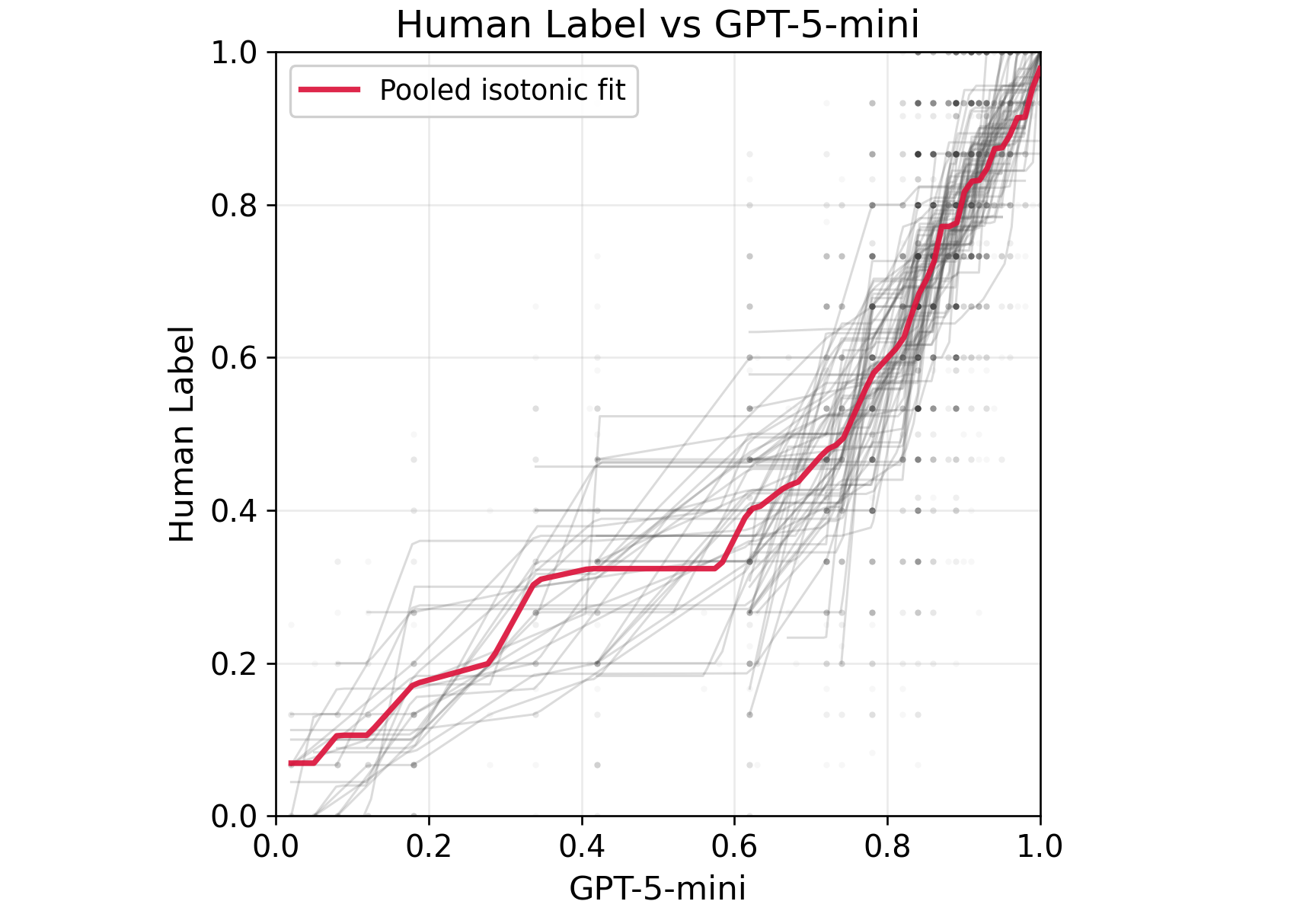
Figure 1: Wald CI widths without power tuning for human-annotated data, showcasing sharper CIs for GRePPI and ARePPI relative to baselines.
- Semi-Synthetic Evaluation: On synthetic and semi-synthetic benchmarks, GRePPI attains lowest MSE and CI widths, provided the nonlinear relationship between surrogate and ground-truth is present. Coverage issues arise at low sample sizes when power-tuning is used, as empirical variance estimates are overly optimistic; setting λ=1 improves coverage.
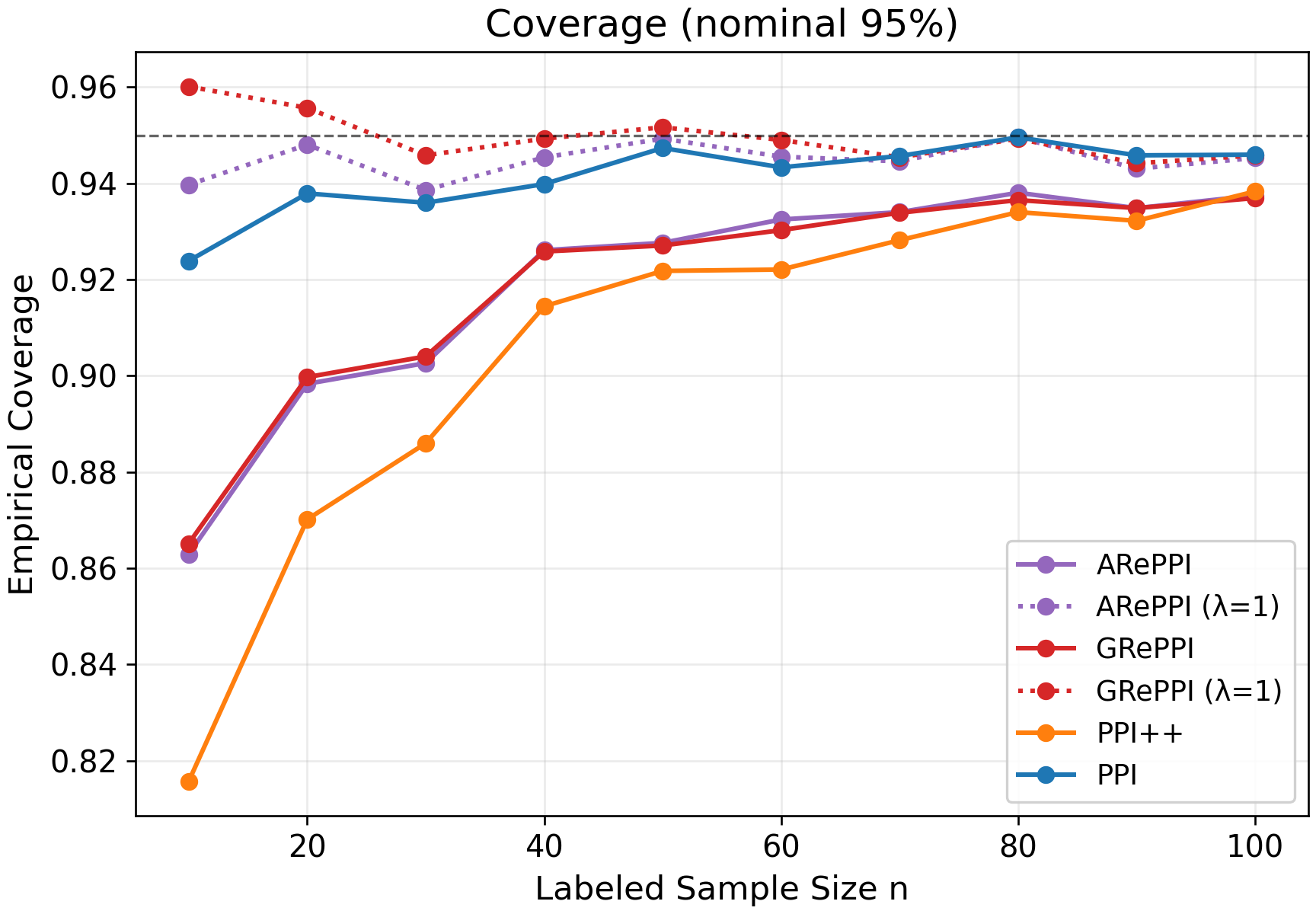
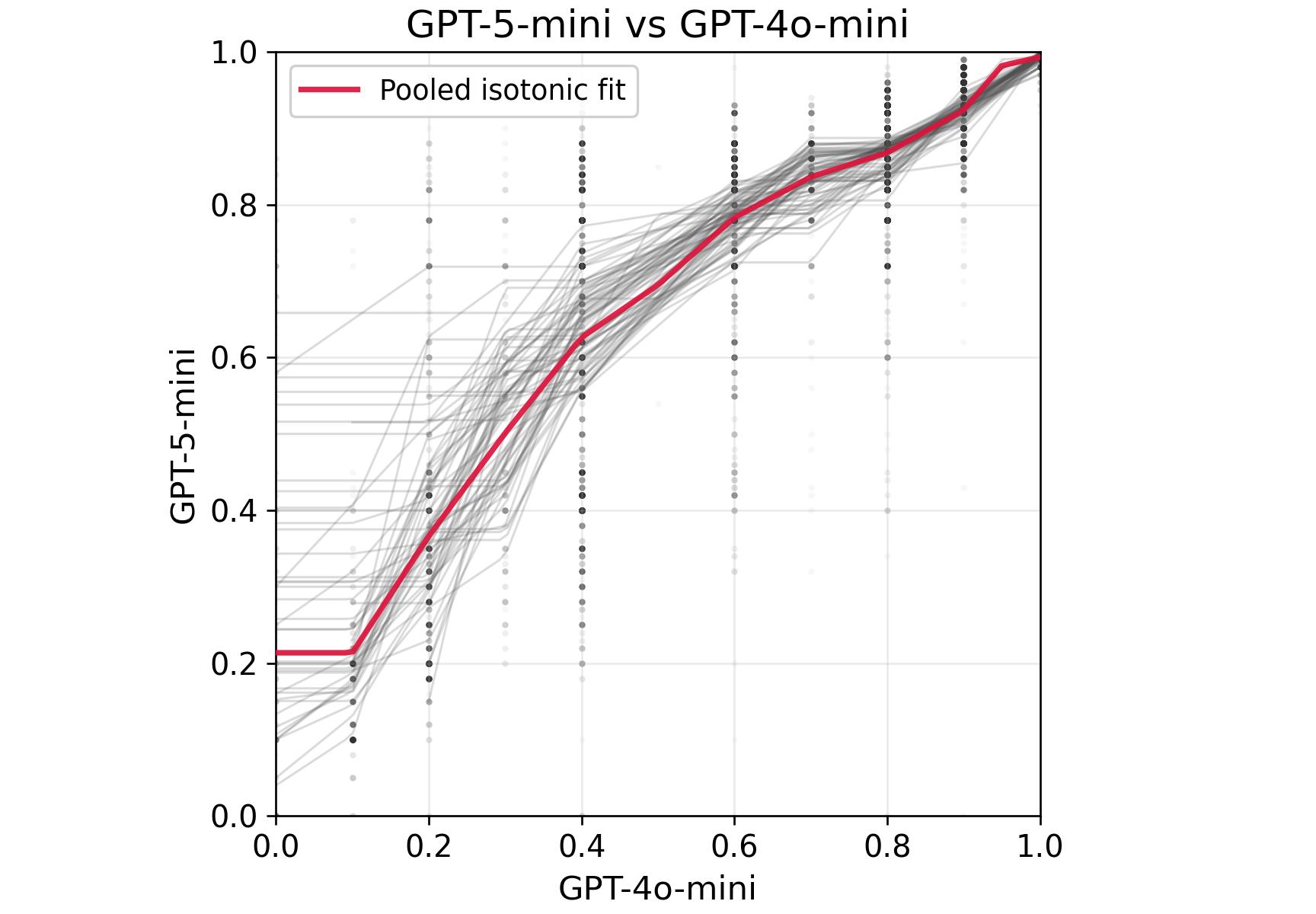
Figure 2: CI widths for semi-synthetic tasks, with GRePPI outperforming classical and locally recalibrated methods.
Figure 3: CI width across synthetic tasks, illustrating the influence of labeled data amount and method adaptation.
- Task Heterogeneity and Method Adaptation: Experiments manipulating task heterogeneity confirm that ARePPI gains prominence in heterogeneous settings, as indiscriminate pooling can disrupt inference, while locally adaptive recalibration is robust.
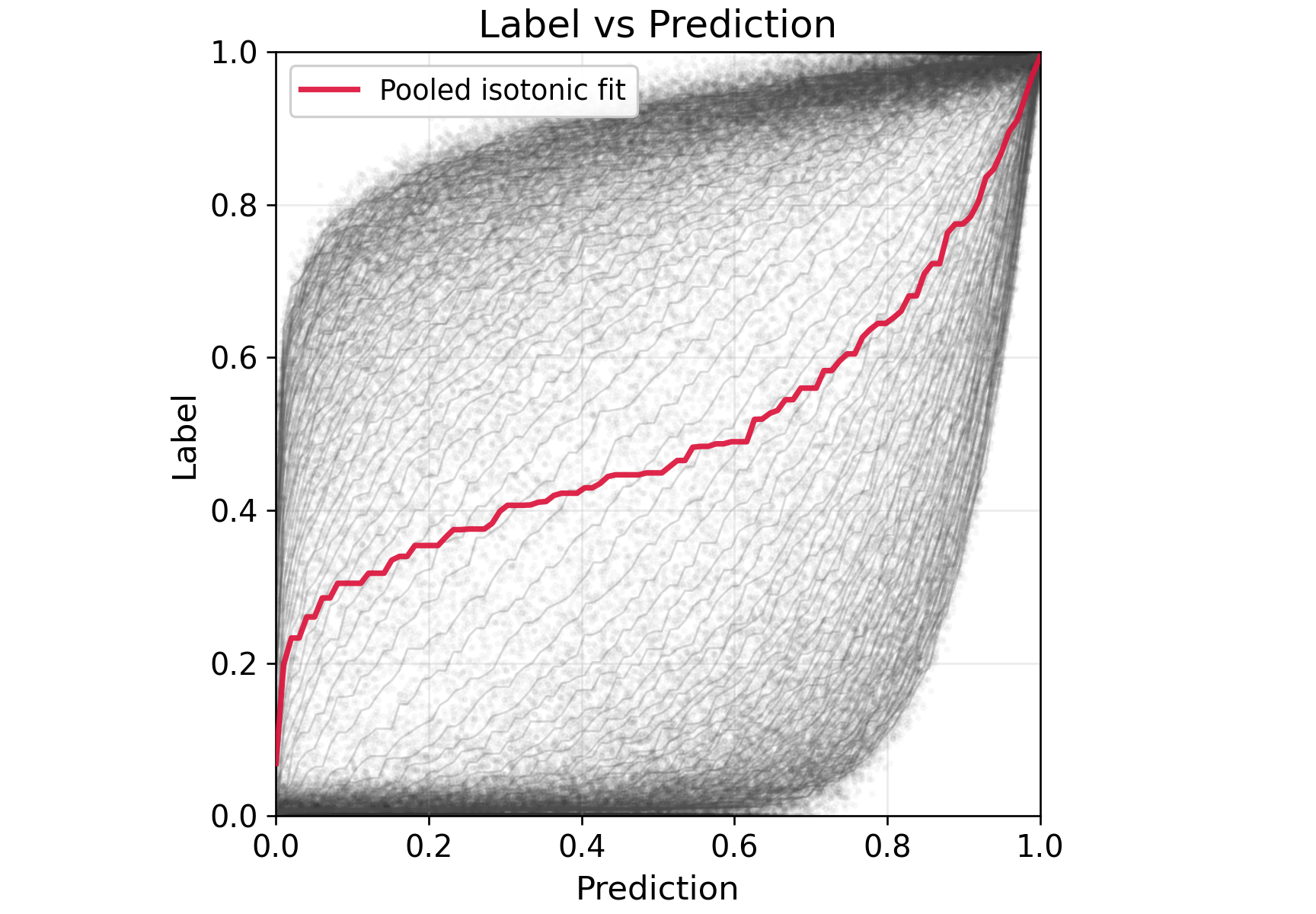
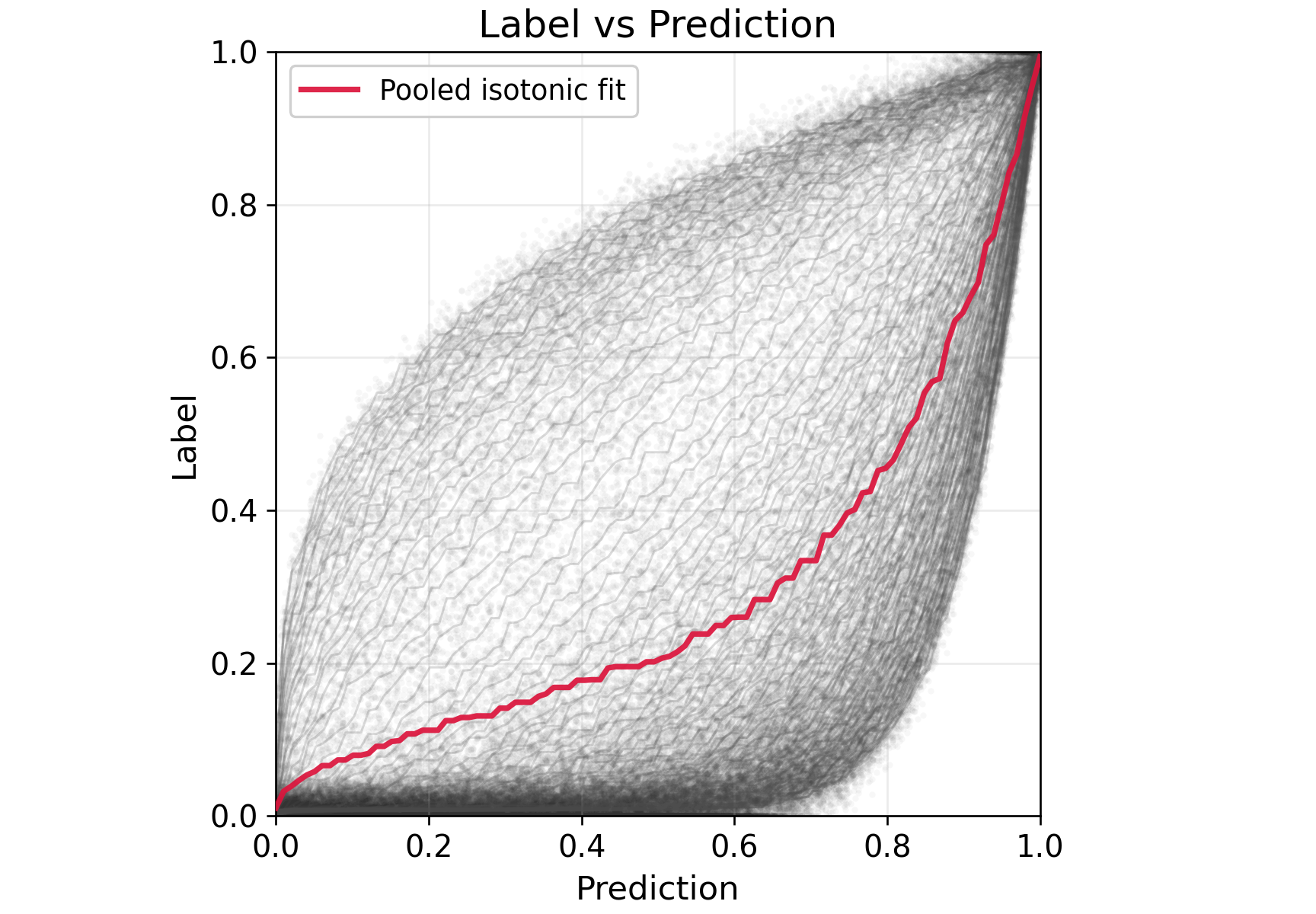
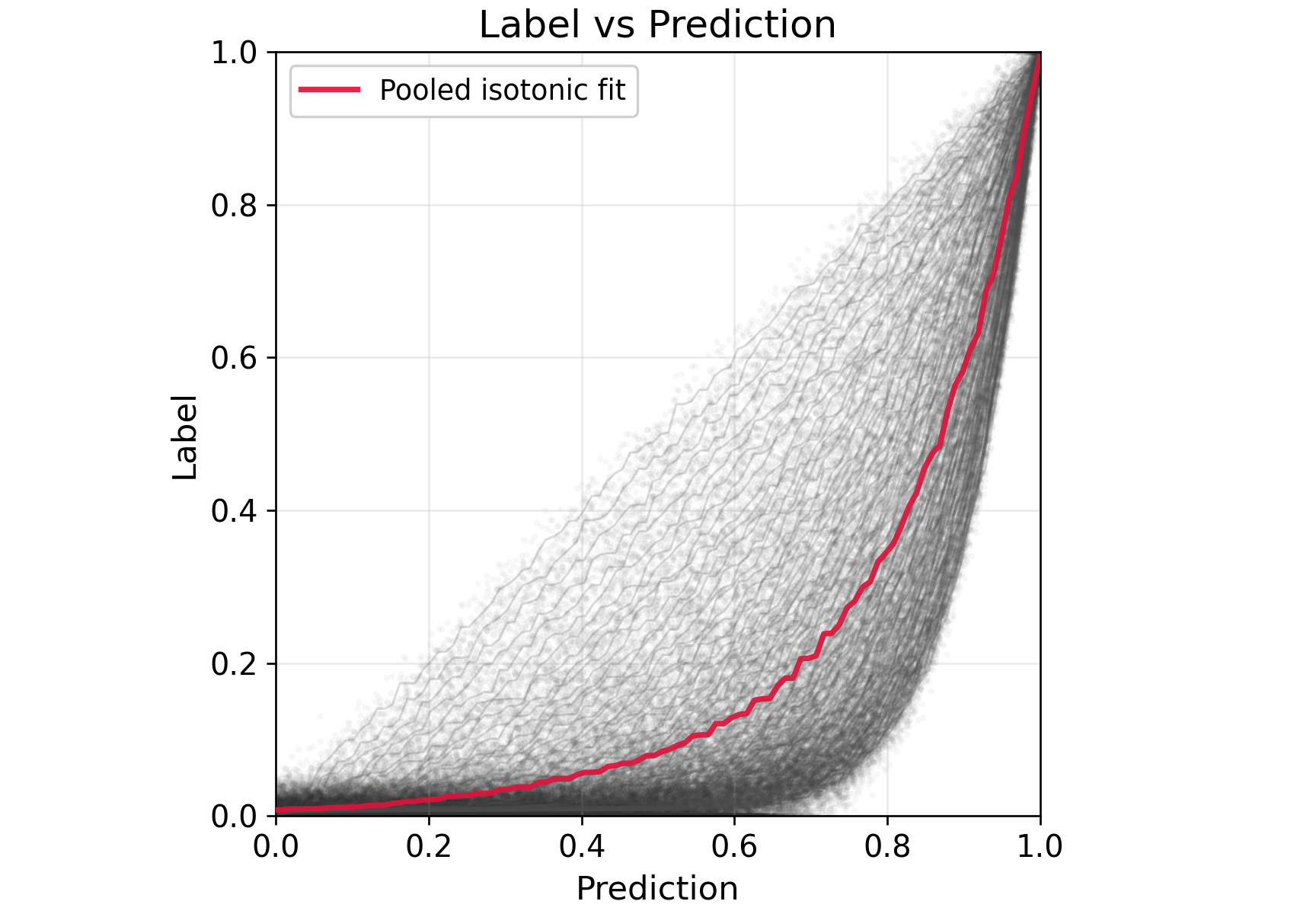
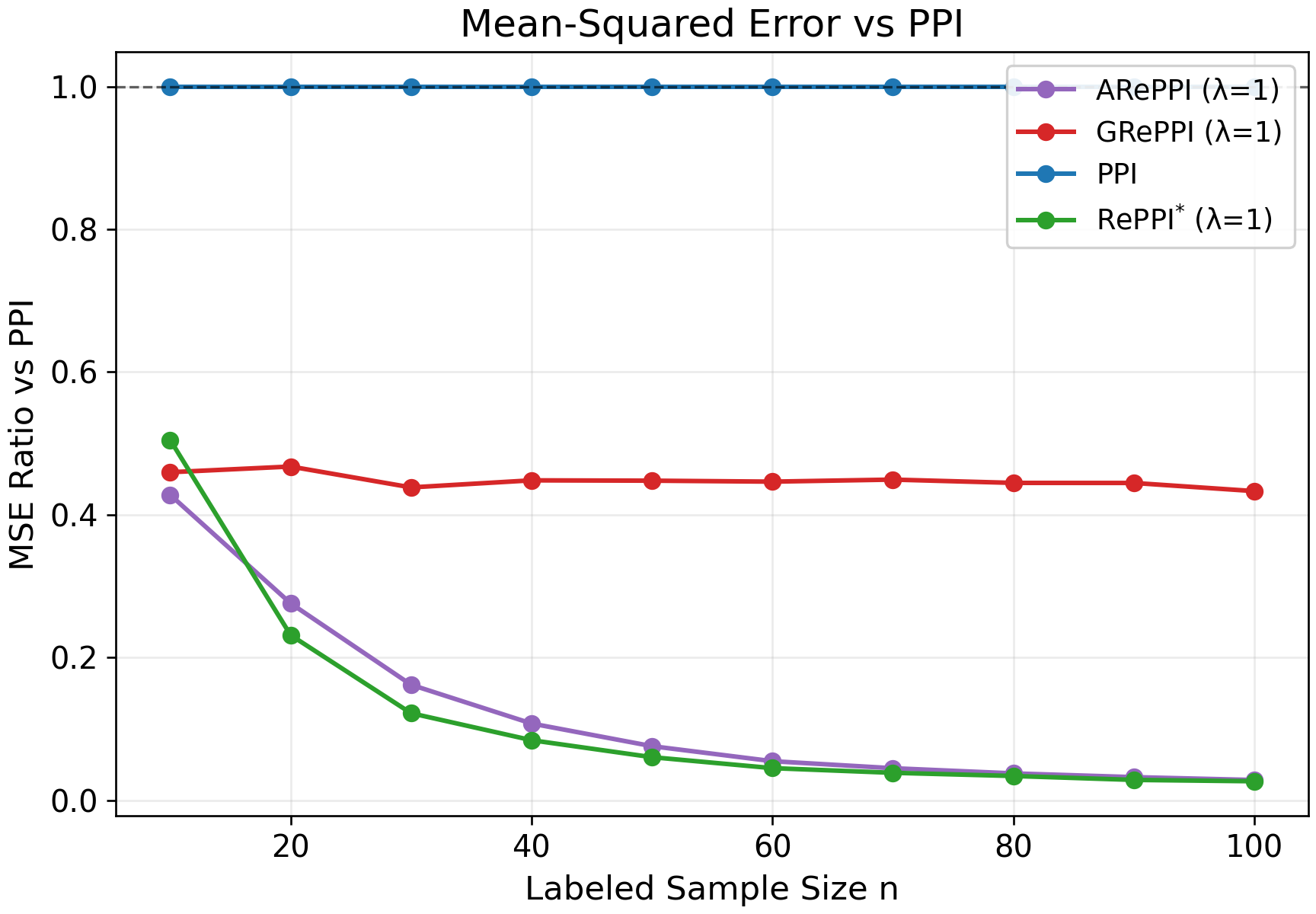
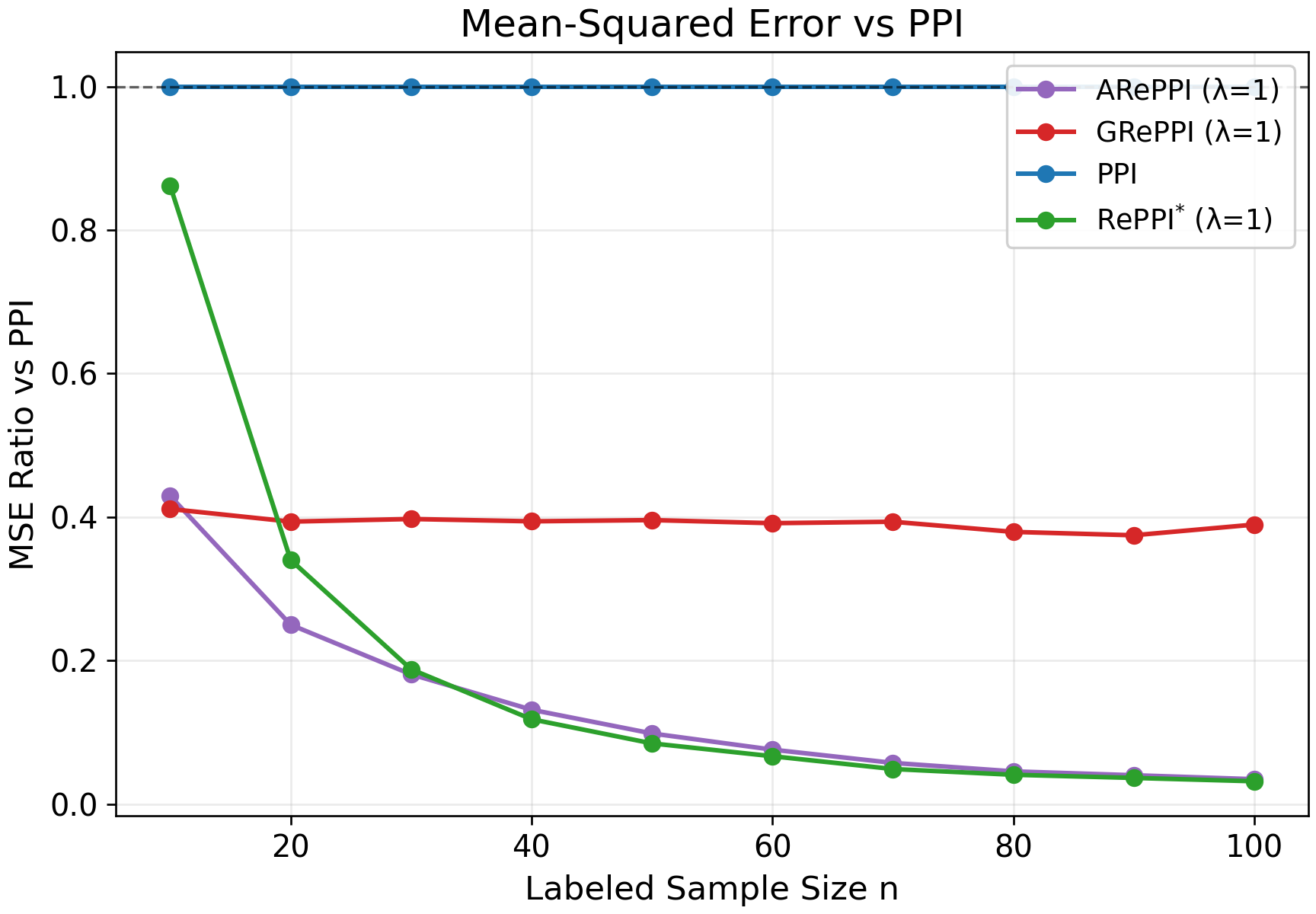
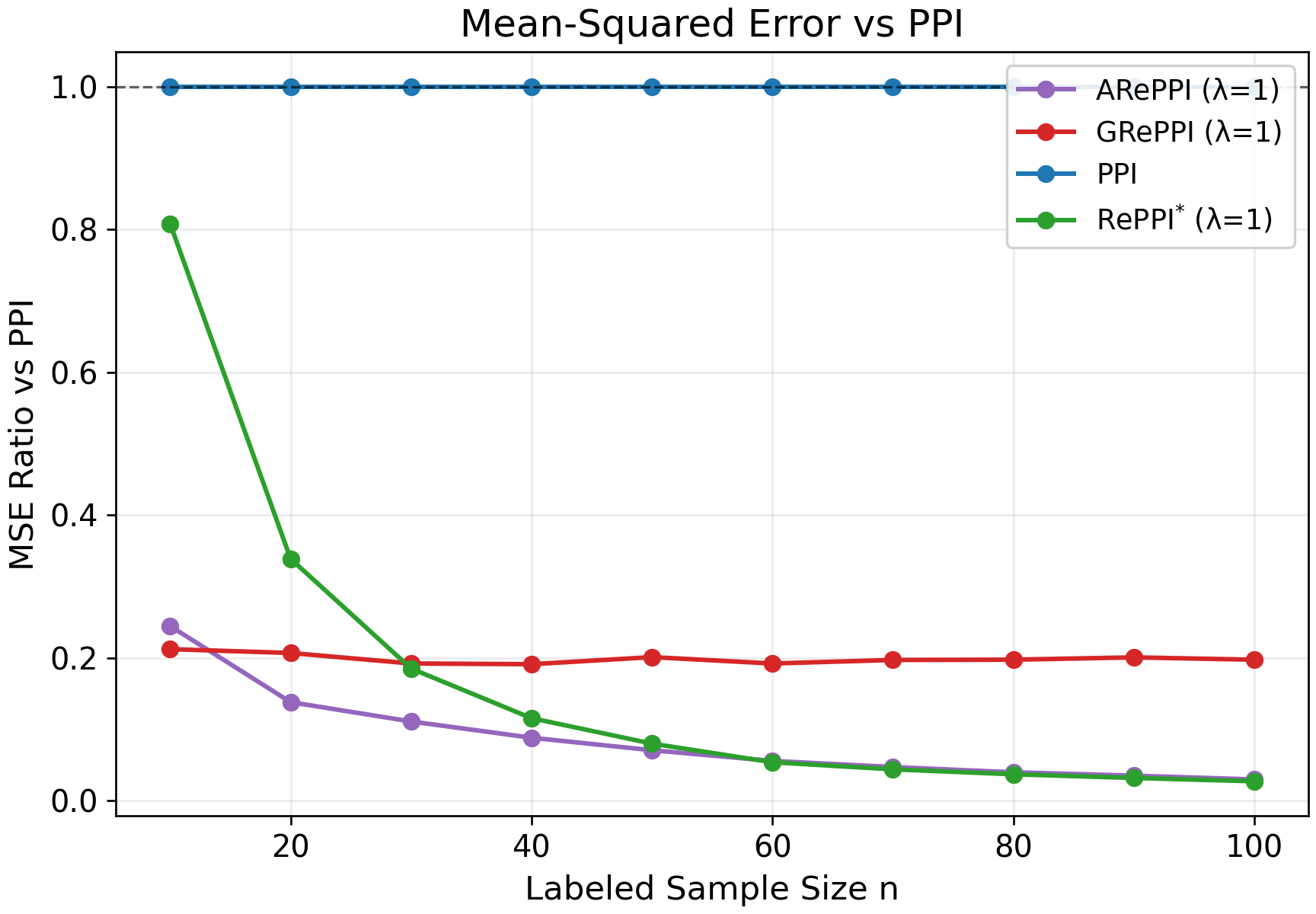
Figure 4: Synthetic task heterogeneity p∈[1/10,10], highlighting nonlinear surrogate–outcome relationships.
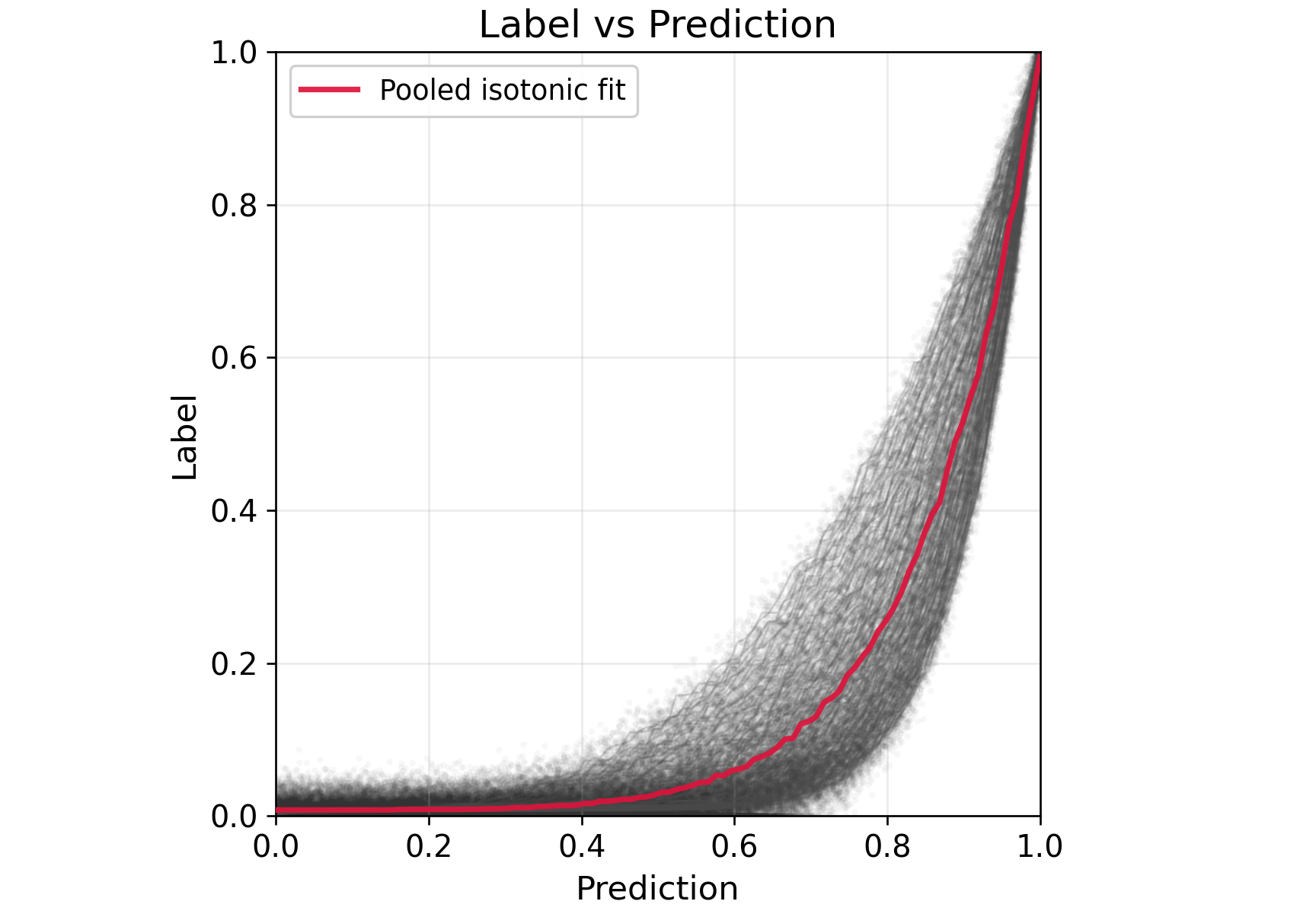
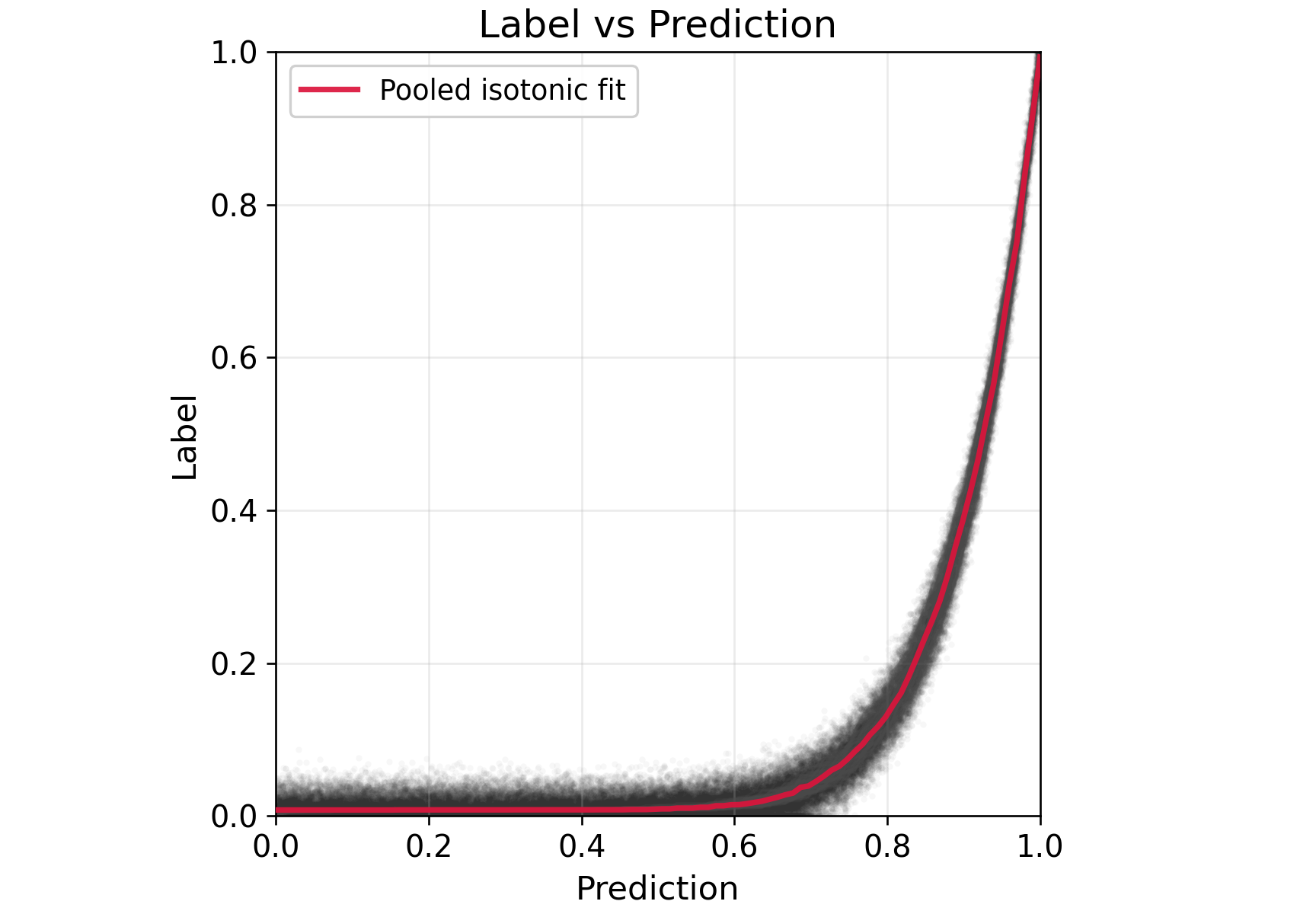
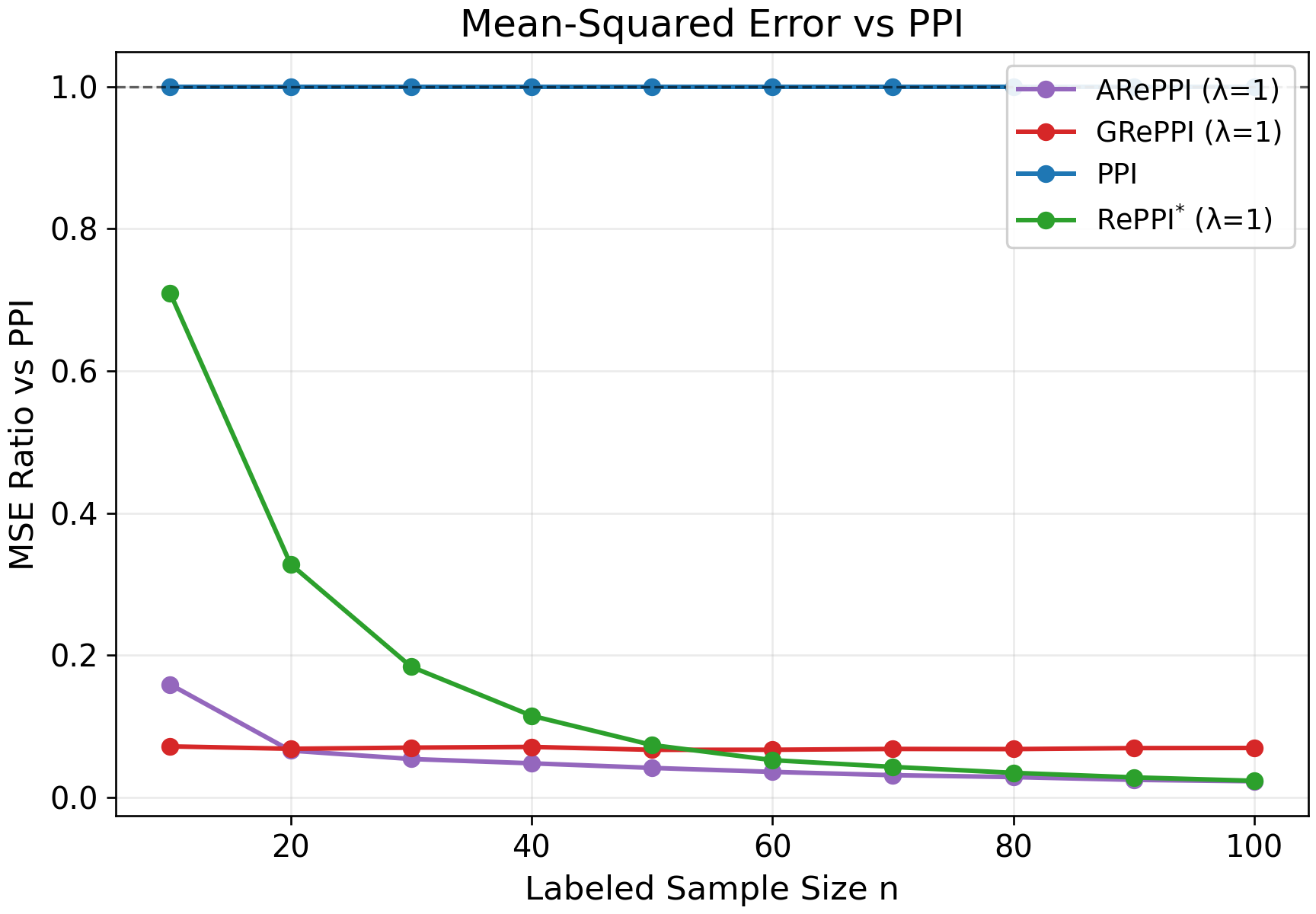
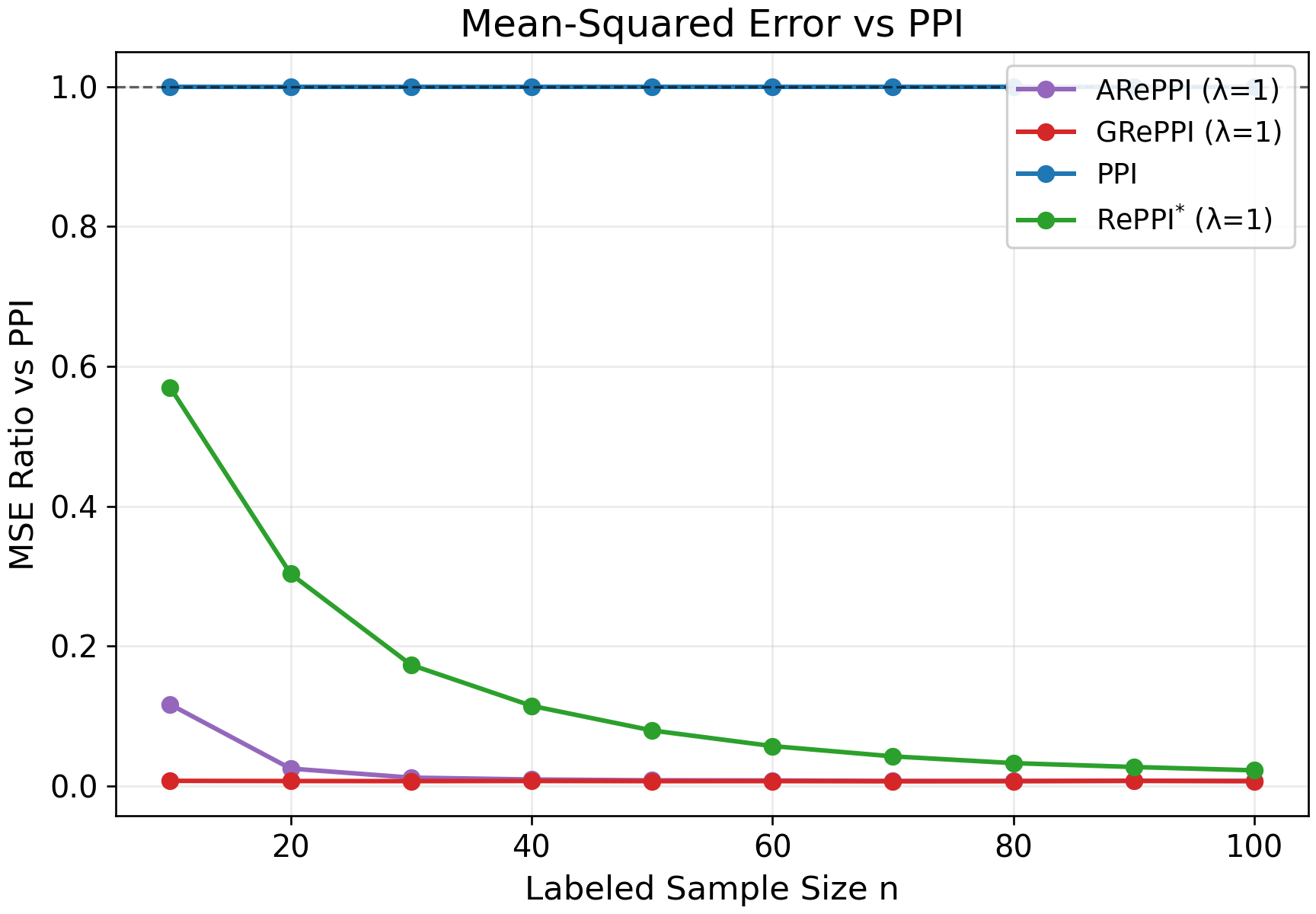
Figure 5: Synthetic task homogeneity p∈[3,10], exhibiting tighter fits and improved efficiency for GRePPI/ARePPI.
Implications and Future Directions
Practically, the developed multi-task PPI framework enables more statistically efficient AI audits and social science investigations, especially when budgets for ground-truth labeling are constrained. It is robust to task heterogeneity, and its theoretical guarantees delineate the clear operational requirements for meaningful cross-task power gain: specifically, the presence of nonlinear shared structure.
Theoretically, the results unify empirical Bayes and design-based survey sampling perspectives, connecting PPI estimators to classical difference and GREG estimators. The affine-invariance principle establishes clear boundaries of achievable statistical efficiency. Extensions of these methods could be immediately applied to hypothesis testing (via CI–test duality) or embedded within more adaptive strategies for task similarity.
In future AI evaluation, especially in domains where annotation costs are high, leveraging multi-task recalibration as proposed will provide more powerful yet valid statistical inference. Additionally, principled guidelines for mapping continuous similarity scores to operational auditor judgments will be vital, and further research on automated calibration methods—potentially using richer auxiliary data and domain-specific model architectures—stands to benefit both AI robustness assessment and nuanced survey-based research.
Conclusion
This paper establishes a rigorous framework for multi-task prediction-powered inference, proving both theoretically and empirically that nonlinear cross-task recalibration enables substantial efficiency gains in sparse-label regimes. The GRePPI and ARePPI methods outperform classical and locally recalibrated approaches by leveraging global and adaptive surrogate–ground-truth structure, respectively. The explicit geometric and statistical characterizations provide actionable criteria for practitioners seeking valid, efficient inference across related evaluation tasks. The framework is poised for immediate impact in AI auditing, social science, and broader domains requiring inference with limited ground-truth labels and abundant proxies.

