- The paper's main contribution is formulating a MOE-PPI framework that optimally aggregates expert predictions to minimize estimator variance and ensure safe expert expansion.
- It establishes theoretical guarantees such as bias decay and Berry-Esseen bounds, ensuring oracle-level interval coverage and lower variance.
- Empirical results validate reduced interval widths, enhanced label efficiency, and robust performance under misspecification across various inferential tasks.
Prediction-powered Inference by Mixture of Experts: A Technical Summary
Motivation and Framework
This work introduces a mixture-of-experts (MOE) powered semi-supervised inference scheme, specifically tailored for the prediction-powered inference (PPI) paradigm. The context is modern semi-supervised learning, where labeled samples are scarce and expensive but unlabeled samples are abundant. The PPI framework uses a powerful predictor to impute responses for unlabeled covariates and rectifies bias using labeled sample residuals. However, the predictive performance of any single expert is susceptible to distribution shift and unknown model mismatch.
This paper formalizes a general MOE-PPI architecture where, given K predictors {fk(⋅)}k=1K, the inference target is estimated using an optimally weighted mixture Fβ(x)=∑k=1Kβkfk(x). The central principle is to select β to minimize the variance of the PPI estimator, thus maximizing efficiency while retaining robustness. The MOE-PPI approach adapts automatically to expert quality, guarantees performance at least as good as the strongest individual predictor, and is safe against expansion of the expert pool.
Theoretical Guarantees
The MOE-powered inference applies to several classical inferential tasks:
- Population mean estimation
- Quantile estimation (using smoothed indicators)
- Linear regression coefficients
- Logistic regression parameters
- General M-estimation
In each scenario, the MOE estimator is constructed by minimizing sample variance, and coverage guarantees for confidence intervals are established via non-asymptotic theory. The authors rigorously prove:
- The bias of the MOE estimator decays as O(n−1), dominated by the estimator's standard deviation for realistic sample sizes.
- Berry-Esseen bounds for interval coverage hold, yielding valid confidence intervals with widths approaching those of the oracle combination.
- The MOE estimator always achieves variance no larger than the PPI estimator with any single expert—this is a best-expert guarantee.
- The variance does not increase if new predictors are added, ensuring safe expert expansion.
Numerical Results
Variance Reduction and Robustness
Across mean, quantile, and regression inference tasks, MOE ranks at or beyond PPI-best (using oracle selection among experts), and consistently outperforms conventional estimators—especially for misspecified nonlinear models. The following visual quantifies the variance reduction for various tasks and predictor regimes:
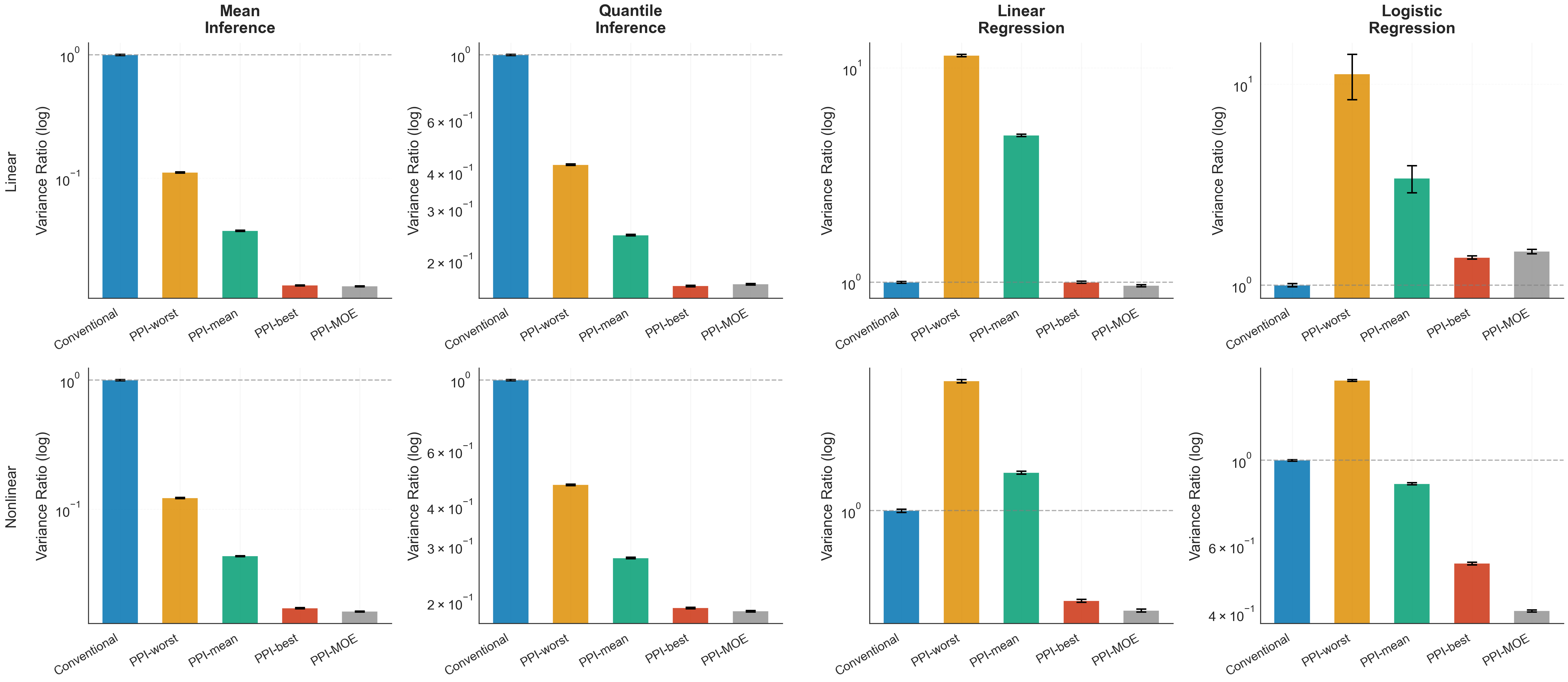
Figure 1: Variance reduction under Linear and Nonlinear regimes across inference tasks.
Robust adaptation by MOE becomes evident in nonlinear and misspecified settings, where conventional PPI with a single expert may lose its efficiency.
Scaling with Sample Size
As the ratio of unlabeled (N) to labeled (n) samples grows, the mean-inference variance approaches the labeled-data floor but improves rapidly in the intermediate regime. The variance decomposes into rectified and imputed components:
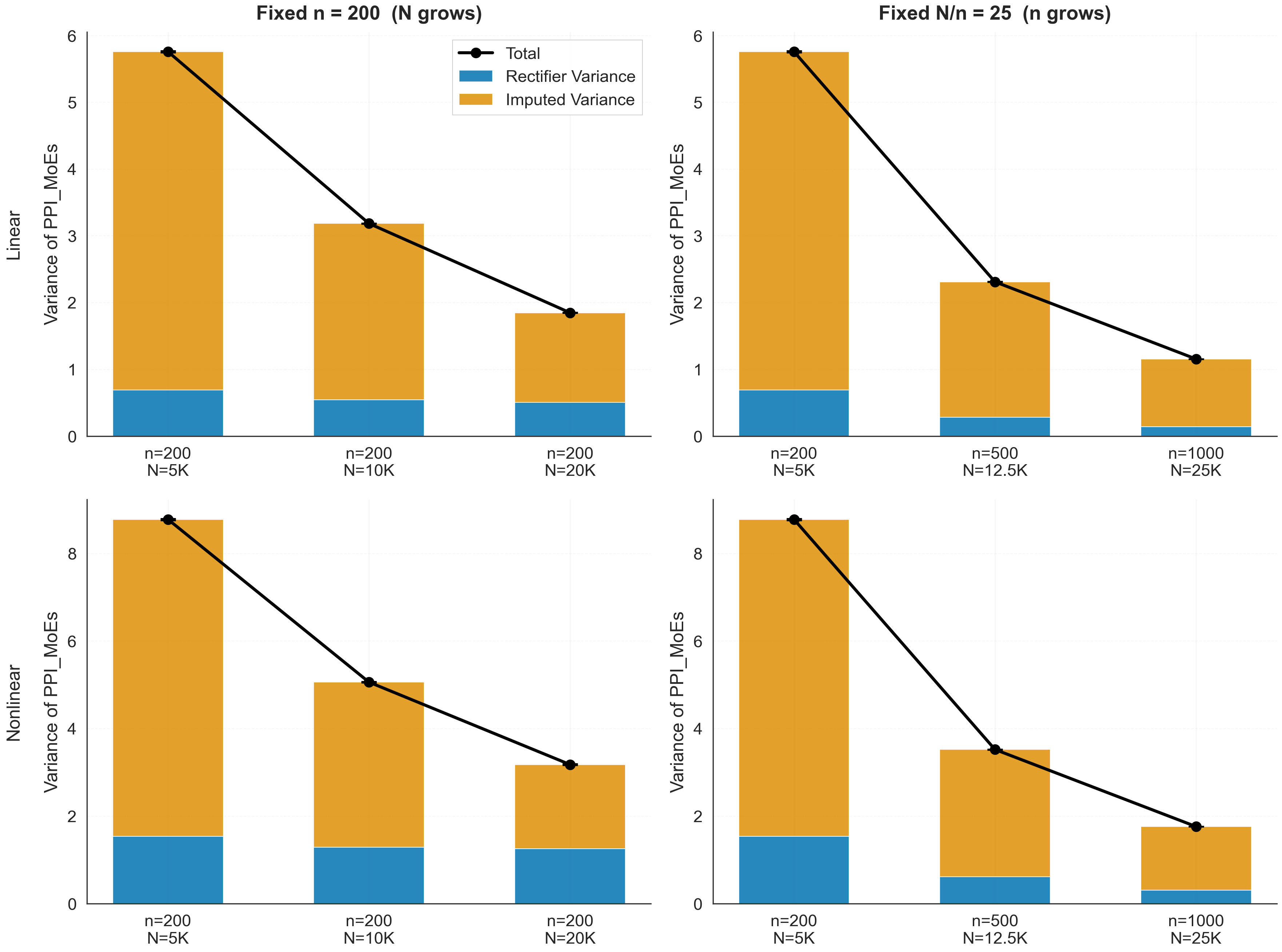
Figure 2: Effect of the growth rates of n and N on mean-inference variance.
Coverage, Interval Width, and Label Efficiency
Coverage probabilities remain near nominal with MOE, while interval width is substantially reduced, even under misspecification and moderate sample sizes:
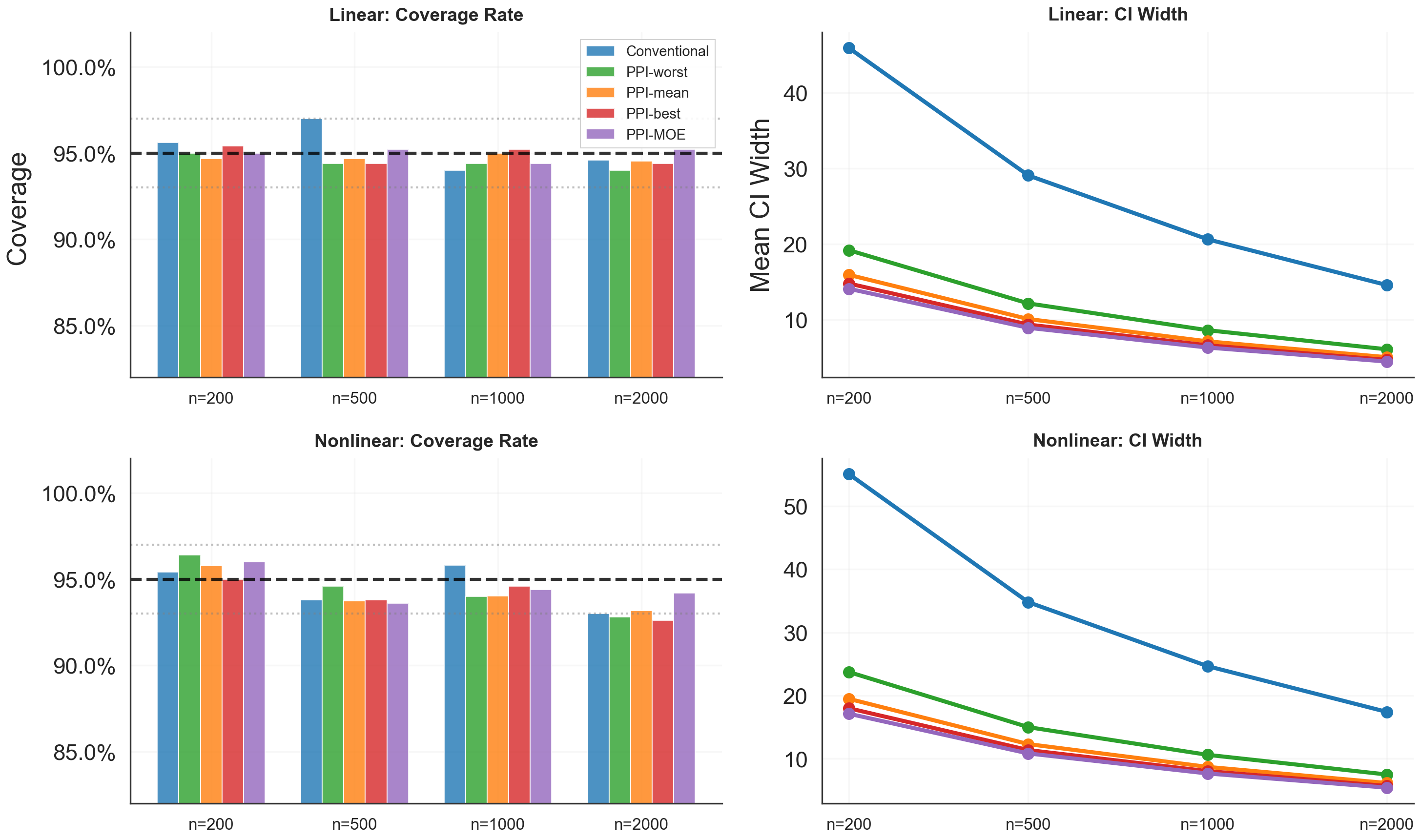
Figure 3: Coverage and confidence-interval width under linear and nonlinear settings.
MOE achieves lower width ratios than averaging or worst-case PPI, and adapts closely to the best-performing baseline without requiring oracle knowledge.
A critical operational advantage is label efficiency: MOE requires substantially fewer labeled samples to reach a fixed target power in mean hypothesis testing.
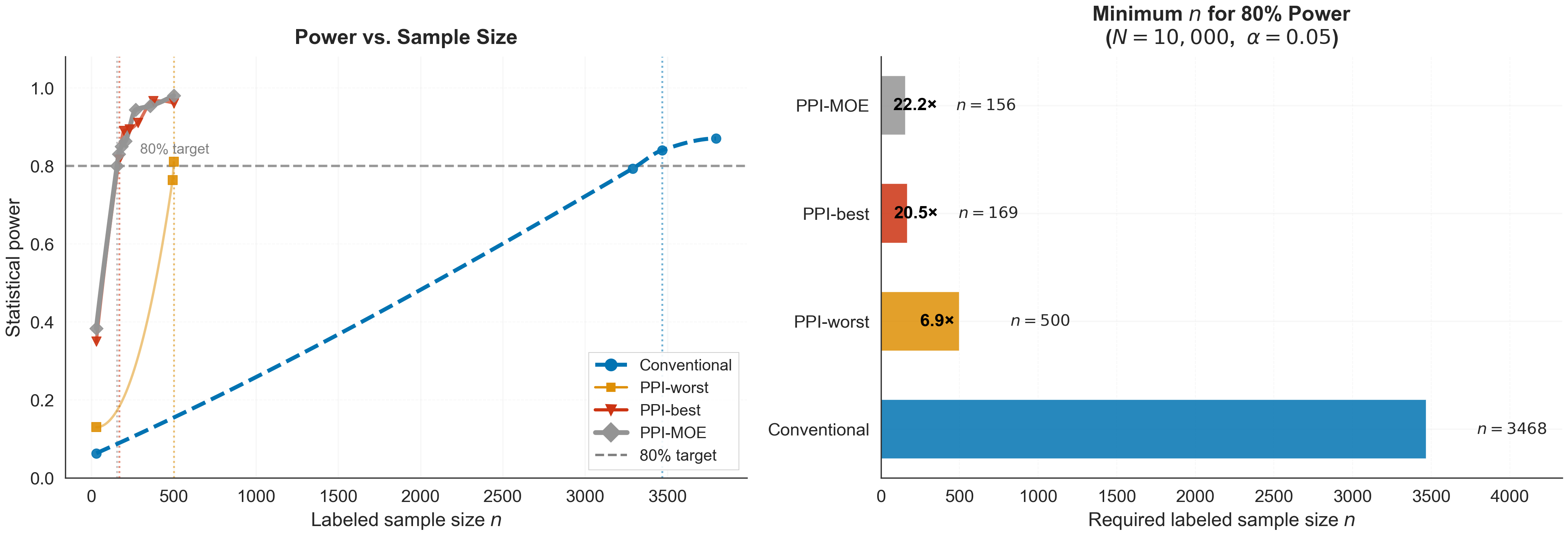
Figure 4: Sample-size efficiency for mean inference under the linear setting.
Empirical evaluation on California Housing and Bike Sharing datasets confirms the variance and power advantages of MOE-powered inference over both conventional and naive PPI approaches:
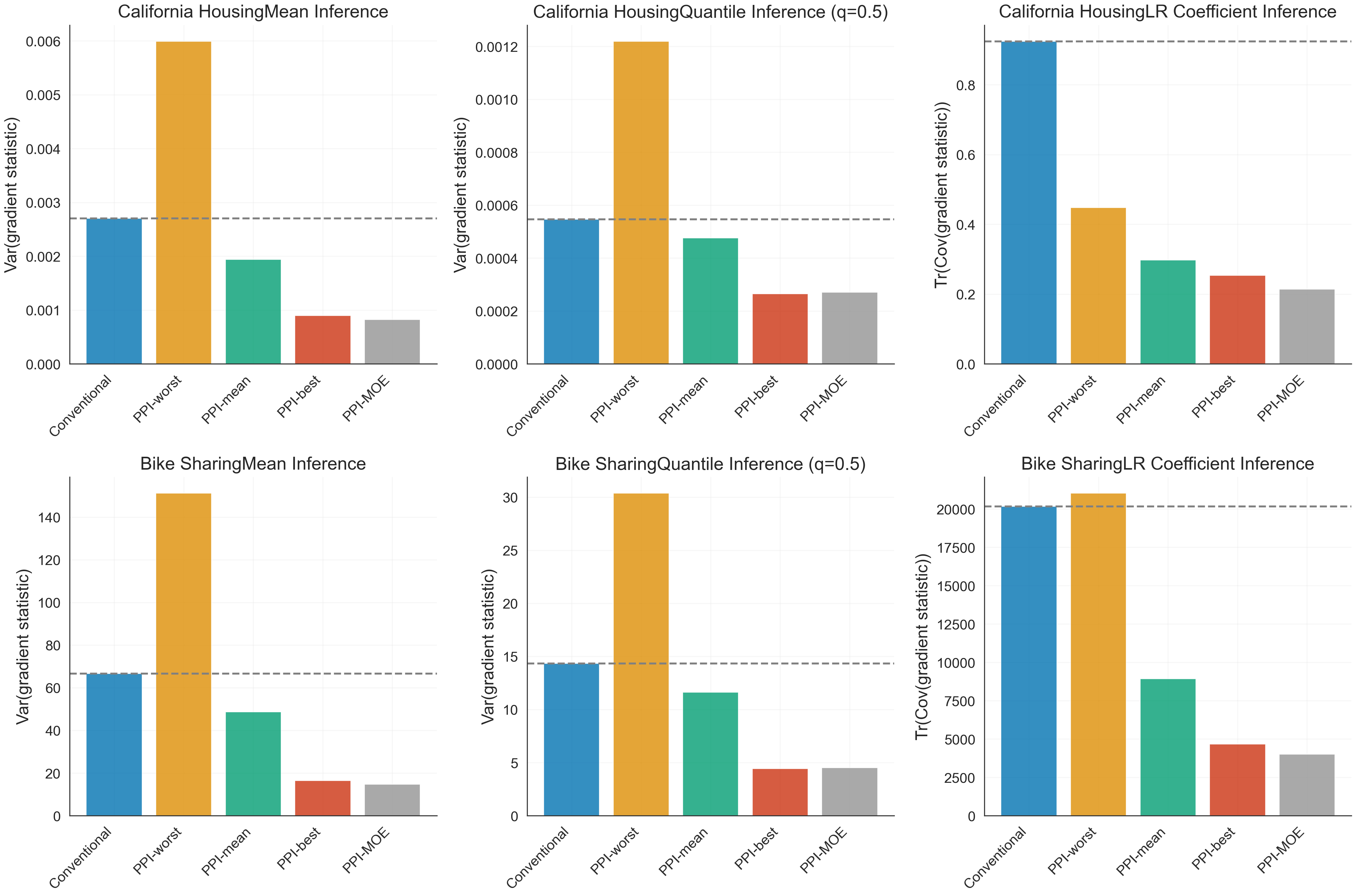
Figure 5: Real-data variance comparison across inference tasks.
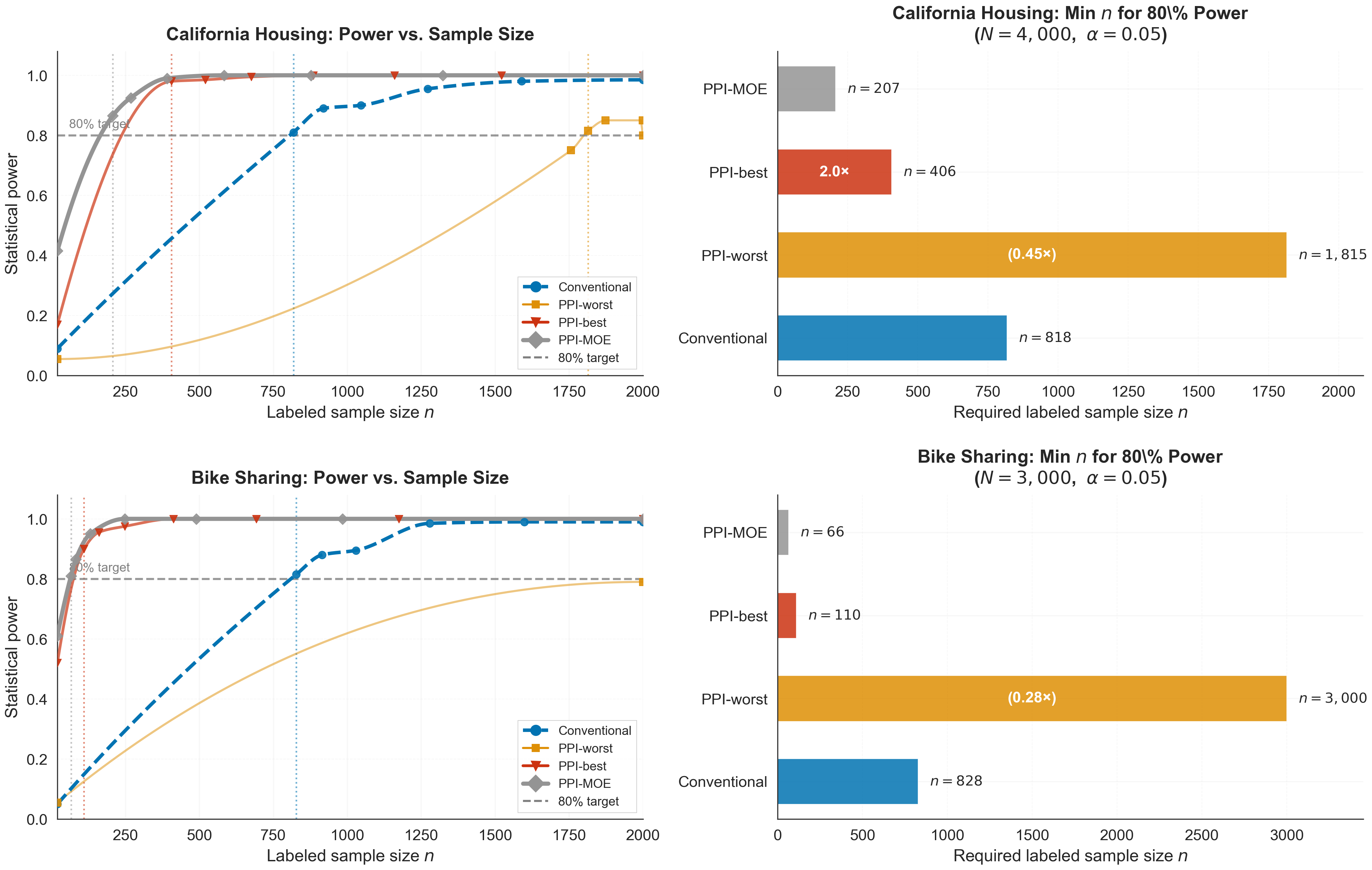
Figure 6: Real-data power analysis and minimum labeled sample size for 80% power.
MOE attains operational gains in sample power, facilitating effective inference with dramatically fewer labeled samples.
Practical Implications and Future Directions
The MOE-powered PPI framework offers a systematic method for leveraging a pool of predictors in semi-supervised inference, providing both variance reduction and robustness without demanding prior knowledge of expert quality. It is flexible and general, encompassing diverse inferential problems and models.
Theoretical guarantees, together with empirical results, support the conclusion that MOE aggregation is not only optimal in expectation but also robust to practical issues such as model misspecification, expert expansion, and small sample sizes.
From a practical standpoint, MOE-PPI is particularly relevant as the ecosystem of publicly available prediction tools diversifies and evolves. The framework enables safe deployment and continuous integration of new predictors, minimizing variance and maximizing efficiency for semi-supervised statistical inference.
Open problems include extending MOE weighting from global (constant) weights to local (covariate-dependent) weights—enabling domain-aware specialization and further variance reduction. However, localized weighting introduces bias and estimation challenges which require refined theoretical analysis, especially to guarantee interval coverage and normal approximation under high-dimensional conditions.
Conclusion
Prediction-powered inference via mixture-of-experts constitutes a principled advancement for semi-supervised inference, enabling adaptive, robust, and efficient aggregation of multiple prediction tools. This approach guarantees best-expert performance and safe expansion, validated both theoretically and empirically across diverse inference tasks. The framework is poised for further extension, offering a scalable solution to inference problems in the era of heterogeneous and rapidly evolving AI prediction systems (2604.27892).

