- The paper introduces a comprehensive taxonomy and a 1,300-entry benchmark dataset for detecting hallucinated legal citations in AI-generated legal documents.
- It evaluates multiple models using agentic and non-agentic frameworks, reporting metrics such as a recall of 82.8% and an F1 score of 60.5% for GPT-5.
- The findings highlight critical verification challenges and policy implications, stressing the need for improved data access and robust automated legal citation checks.
Essay: Benchmarking Legal Hallucination Detection in AI-Generated Legal Documents
Introduction and Problem Framing
Automated citation verification in legal drafting has emerged as a critical task due to the increasing prevalence of hallucinated citations in attorney, judge, and pro se filings generated by LLMs. The paper "Who Checks the Citations? Benchmarking Legal Hallucination Detection" (2606.21155) addresses the systemic challenges posed by fabricated or misrepresented legal citations in court filings, underscoring the absence of consistent reduction in hallucination rates across successive model generations and the rising verification burden on courts and counsel. The study introduces a comprehensive taxonomy of legal citation hallucinations, proposes a new benchmarking dataset, and systematically evaluates agentic and non-agentic hallucination detection frameworks.
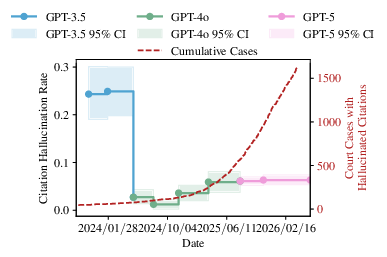
Figure 1: Hallucination rates in legal filings and model generations show no consistent decline, with a marked increase in court filings containing fabricated citations.
Taxonomy and Benchmark Dataset Construction
The authors develop a taxonomy for legal citation hallucinations grounded in real court failures:
- Non-existent citation: Fabricated case or incorrect reporter reference.
- Case name mismatch: Citation name inconsistent with canonical reference.
- Incorrect pincite: Pinpoint citation refers to irrelevant or unsupported content.
- Verbatim misquote: Language attributed to a case does not appear verbatim.
- Content misrepresentation: The cited legal proposition is not supported by the source.
This taxonomy forms the backbone of the LePhantomCite dataset, which comprises 1,300 legal brief excerpts with systematically injected errors covering all taxonomy categories. Citations are extracted and modified using state-of-the-art LLMs for segmentation and component extraction, ensuring high-fidelity hallucination injection.
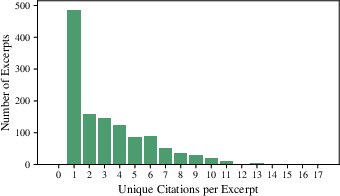
Figure 2: Distribution of unique citations per excerpt and count of hallucinated citations by category in the LePhantomCite dataset.
Experimental Setup and Model Evaluation
The study benchmarks five models—including GPT-5, GPT-OSS-120B, Qwen variants, Gemini 2.5 Flash, and Claude Code with Opus 4.8—using both non-agentic prompt-based and agentic verification harnesses (BOED, Reflexion), each equipped with legal database access and structured reasoning. The task is formulated as segment retrieval, specifically detecting hallucinated citations via relaxed substring matching. Metrics are precision, recall, and F1 score at the segment level.
GPT-5 under agentic verification achieves the highest recall (82.8%) and F1 (60.5%) in the BOED framework, while Claude Code attains superior precision and F1 via tool-efficient agentic verification but lower recall. All models notably struggle with subtle hallucination types, especially incorrect pincites (recall ≤ 25.5%) and content misrepresentation (recall ≤ 84.0%), reflecting structural impediments rooted in information access and database coverage.
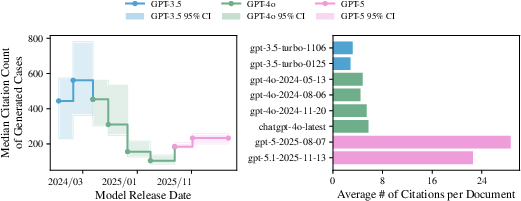
Figure 3: Newer GPT-4o models cite a more diverse set of cases, with increased citation counts per document; verification burden grows even as individual hallucination rates fluctuate.
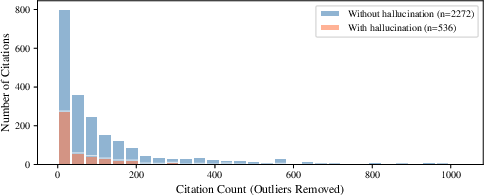
Figure 4: Citation distributions for hallucinated and non-hallucinated cases are indistinguishable, precluding reliance on landmark case knowledge for hallucination detection.
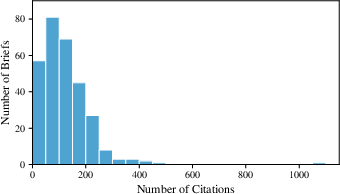
Figure 5: Most briefs contain fewer than 200 citations, reflecting manageable document sizes but potentially high diversity and density in citation patterns.
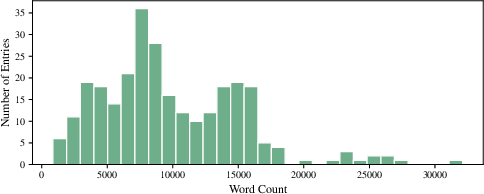
Figure 6: Word count variance across briefs is substantial, emphasizing context length challenges for agentic verification systems.
Error Analysis and Structural Impediments
A detailed error analysis reveals that information access constraints, such as the absence of official pagination in free repositories (e.g., CourtListener) and the restricted access to commercial legal databases (PACER, Westlaw, LexisNexis), limit the reliability of automated verification systems. Weaker models default to flagging citations missing from CourtListener as hallucinated, resulting in high false positive rates (up to 65.9%), whereas stronger agentic systems (GPT-5, Claude Code) leverage alternative web sources for corroboration and postpone verdicts when evidence is inconclusive.
Redundant action sequences, inefficient tool usage, and reliability failures further hamper agentic verification, particularly when exceeding the step budget or encountering ambiguous citation formats. Notably, agentic systems surfaced typographical and citation errors in pre-LLM briefs—errors missed by human authors—showcasing real utility beyond synthetic benchmark evaluation.
Policy and Access Implications
The verification burden, exacerbated by the Jevons paradox (as AI lowers the per-unit cost of legal drafting, total citation volume and verification demand grow), is especially acute for pro se litigants. These filers rely on LLMs for document generation but lack access to proprietary databases and often lack awareness of hallucination risks. Sanctions, dismissals, and mandatory AI disclosures have emerged as reactive responses, but structural reforms—including broader public access to legal databases, AI literacy interventions, and development of robust automated verification tools—are imperative to ensure equitable access to justice and responsible LLM deployment.
Practical and Theoretical Implications
Practically, the results demonstrate the necessity of treating legal citation verification as a primary concern in AI-assisted legal drafting, with agentic systems offering tangible improvements but facing critical bottlenecks. Theoretically, the findings suggest that hallucination detection is not solely a modeling problem but a data architecture and access problem, implicating infrastructural policy and database normalization.
Agentic frameworks with explicit belief representation and sequential information search are demonstrably superior but require improved resource allocation and reliability. Future research avenues include context scaling for long brief verification, minimizing redundant actions, and complementing synthetic benchmarks with naturally occurring court-filed examples.
Conclusion
Legal citation hallucinations persist across LLM generations, and verification burdens are compounding as filings grow in number and citation density. The taxonomy, benchmarking dataset, and agentic verification framework introduced in this work provide a rigorous foundation for developing and auditing citation checking tools. Strong numerical results show agentic recall improvements but highlight essential gaps in detecting subtle error categories. Equitable information access and targeted policy reform are prerequisites for scalable, reliable automated verification, without which AI remains a double-edged sword in access-to-justice contexts.
The continued advancement of agentic hallucination detection within open legal infrastructure will be central to mitigating systemic integrity risks and ensuring the responsible use of AI in legal practice.

