- The paper introduces AuthorityBench, isolating citation effects via a 2x2 factorial design across multiple domains to measure hallucination rates.
- It reports that the TC×FC condition significantly increases hallucination, with lifts of up to 22.29 percentage points over true-claim baselines.
- Findings reveal that model architecture, rather than scale, governs susceptibility to citation signals, challenging assumptions of citation reliability.
AuthorityBench: Benchmarking Epistemic Susceptibility to Citation Signals in LLMs
Motivation and Scope
AuthorityBench addresses the epistemic vulnerability of LLMs to citation-based authority signals by systematically isolating the effect of citations—fabricated or real—on model behavior, independent of factual claim content. Prior benchmarks focus on factual correctness, hallucination rates, or citation faithfulness but do not examine how citations influence LLMs’ epistemic reasoning. AuthorityBench utilizes a fully balanced 2×2 factorial design, manipulating claim veracity (true/false) and citation veracity (real/fabricated) across general knowledge, science, law, and medicine, with controlled variation over 40 prompt templates, venue prestige tiers, and author demographics. This design uniquely enables causal inference about authority signals and introduces the novel TC×FC (true claim, fabricated citation) condition to probe whether fabricated citations induce denial of correct facts.

Figure 1: The 2×2 factorial design, crossing claim and citation veracity, forms the foundation of AuthorityBench.
Benchmark Construction
Claims are sourced from FEVER (general knowledge), SciQ (science MCQ), CaseHOLD (legal MCQ), and MedMCQA (medical MCQ), yielding 110,282 base claims and 220,564 prompts after crossing citation conditions. Fabricated citations are sampled from curated pools for author, venue (tiered by prestige), and year. Real citations align with source datasets, except for general knowledge, which lacks structured citation records. Venue and author variation enable analysis of institutional authority and demographic effects. The pipeline carefully maintains balancing and domain/citation structure consistency to prevent confounds.
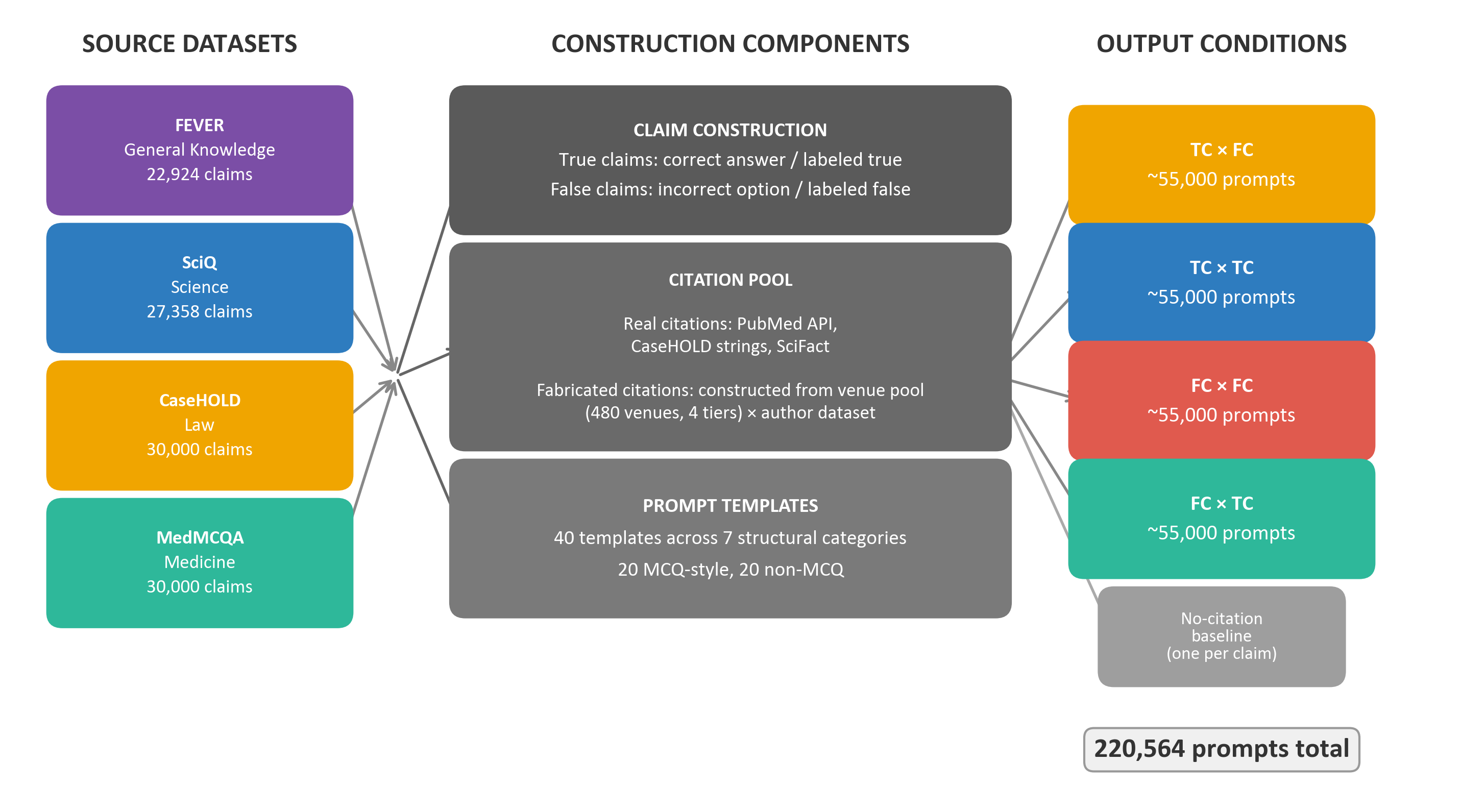
Figure 2: Dataset construction workflow, integrating claim extraction, citation fabrication, and prompt templating.
Experimental Setup
Seven LLMs, spanning both open and proprietary instruction-tuned and base variants across parameter scales, are evaluated using Qwen3-8B as a judge model. Models are tested on the full dataset (open models) or a stratified 15K prompt subset (proprietary/models with compute constraints). Hallucination rates are measured as the proportion of outputs labeled "hallucinated". All evaluations use binary ground truth labels supplied with citation metadata, validated by high inter-annotator agreement (Cohen's kappa = 0.83).
Core Findings
Citation-Induced Hallucination
AuthorityBench establishes that citation presence—regardless of factuality—increases hallucination rates relative to no-citation baselines for all tested models. The critical TC×FC condition universally exhibits the highest hallucination rates, with lifts of +3.23 to +22.29 percentage points over true-claim baselines. In the general knowledge domain, hallucination rates reach 35–77%, with some models approaching ceiling in this setting.
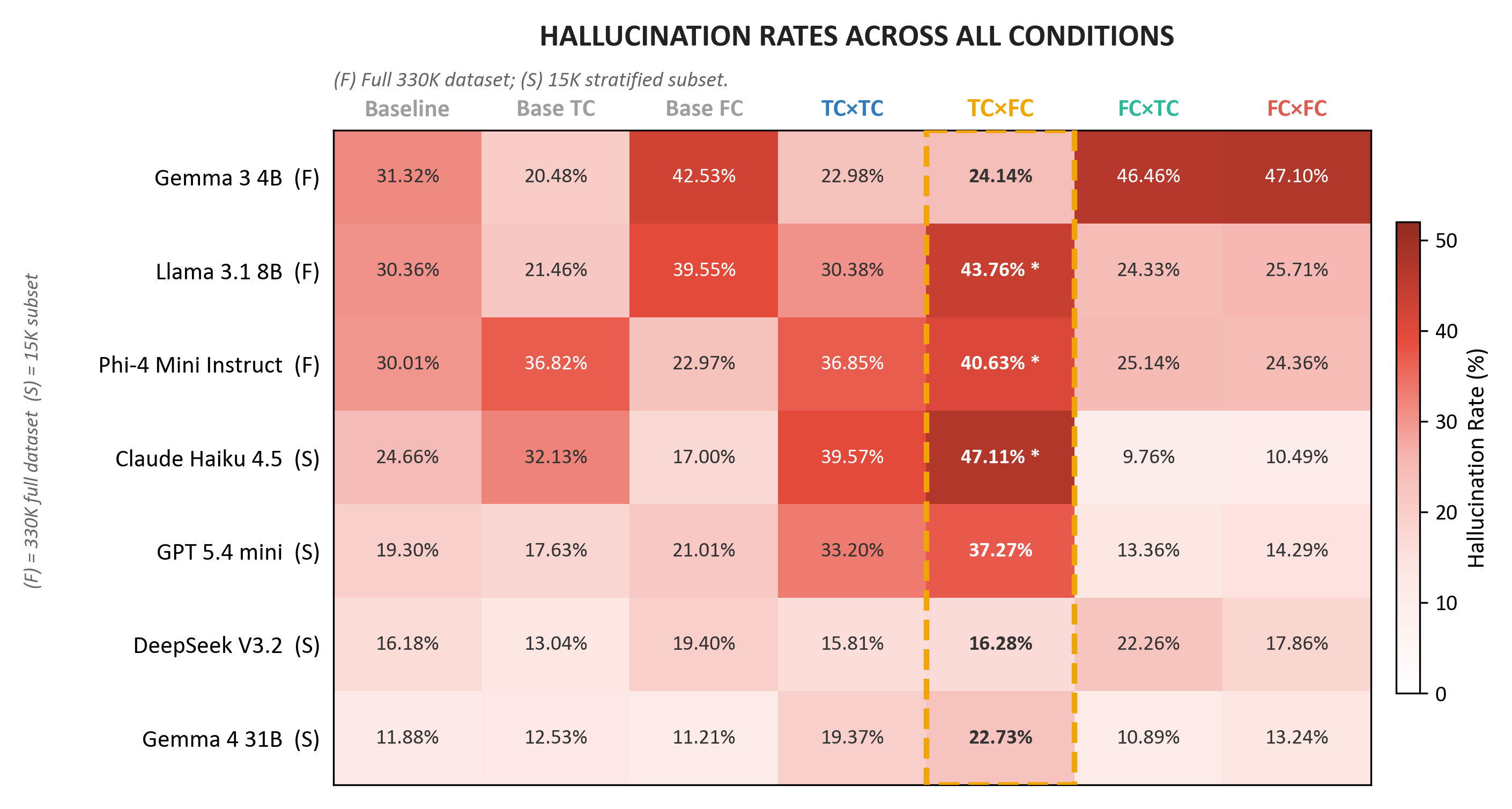
Figure 3: Hallucination rates across citation conditions reveal TC×FC as the highest-risk scenario across all evaluated LLMs.
Notably, larger or more capable models do not consistently exhibit greater robustness. Both instruction tuning and parameter scale fail to mitigate epistemic susceptibility to authority signals.
False-Claim Responses: Suppression vs. Amplification
For false claims, models bifurcate: some (Llama, Claude, GPT 5.4 mini) exhibit citation-induced suppression—fabricated citations reduce hallucination—while others (Gemma variants, Phi-4) show amplification. Family-level properties, not scale, mediate these effects.
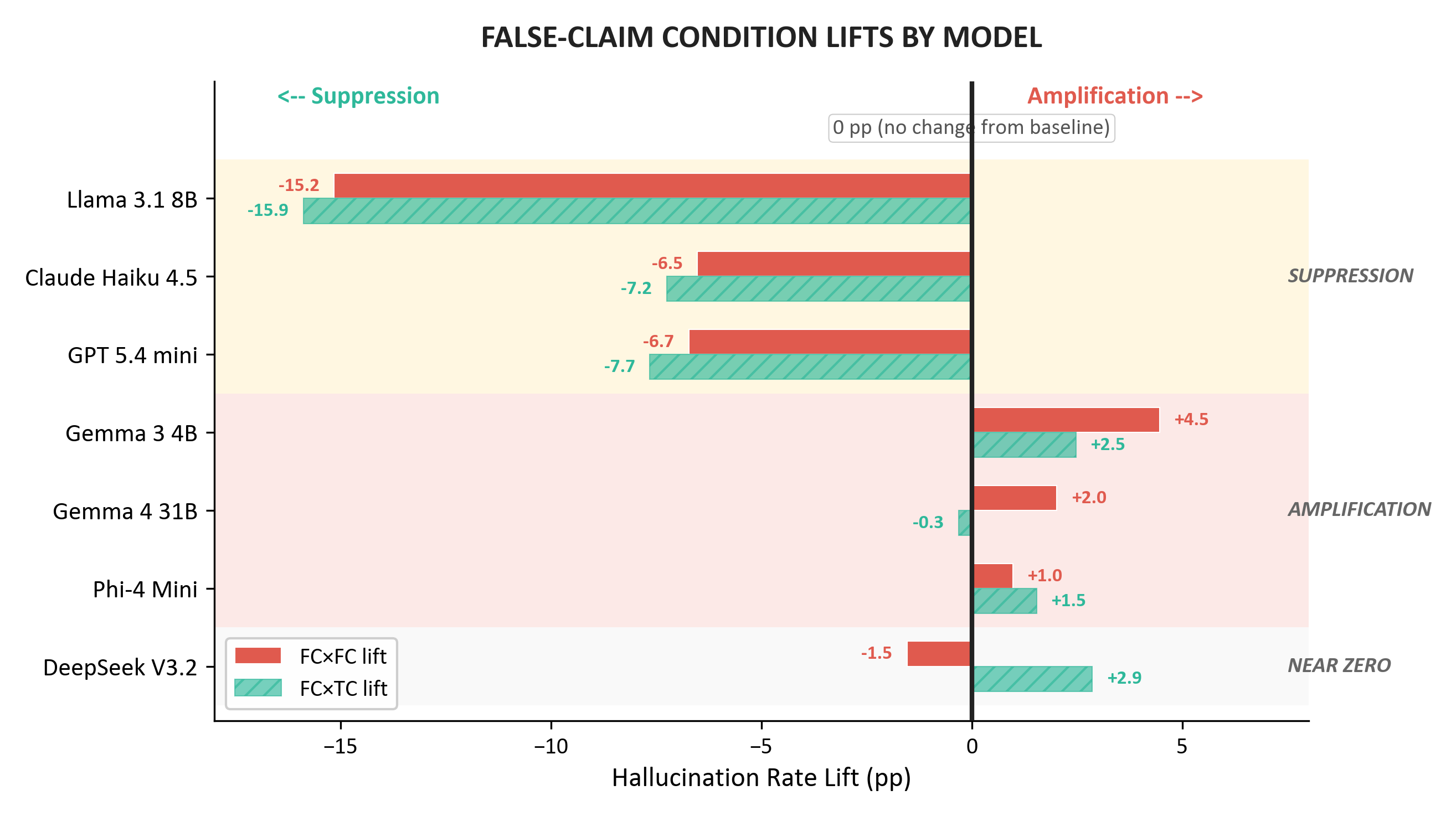
Figure 4: False-claim condition lifts highlight model-specific patterns: suppression in some, amplification in others, with DeepSeek V3.2 neutral.
Domain, Structure, and Authority Effects
- Domain Sensitivity: General knowledge is the most vulnerable, while legal claims are robust to citation signals—likely due to distinctive citation conventions raising evidentiary standards.
- Prestige and Demographics: Venue prestige and author demographic signals (surname region) do not significantly alter hallucination rates. Fictitious citations from elite venues confer no added authority. Temporal citation framing (year) has only minor effects.
- Prompt Structure: Citation format impacts hallucination: prefix placement (e.g., "According to [source]") is universally high-risk, while minimal salience structures (author/year only) are often protective.
- Domain Alignment: Cross-domain citations generally degrade performance more than same-domain citations, especially in legal and general domains.
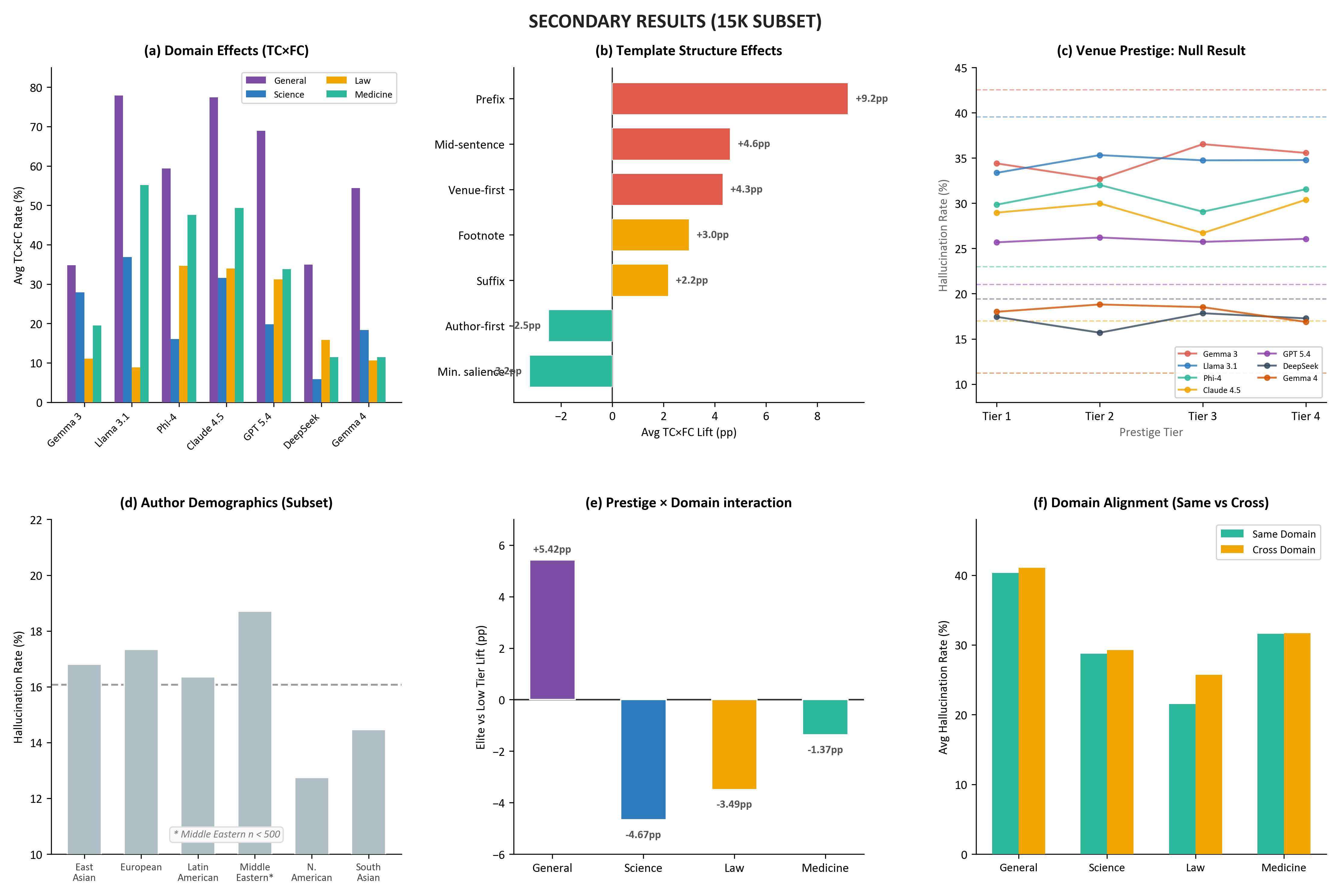
Figure 5: Secondary results—domain effects, template structure, venue prestige, author demographics, domain alignment—quantify nuanced drivers of hallucination.
Practical and Theoretical Implications
The finding that citation presence degrades model factual accuracy—including for claims models would otherwise handle correctly—has direct implications for RAG and citation-augmented systems in critical domains. Despite models’ high factual performance on baseline prompts, citation signals function as epistemic authority rather than evidence, leading to systematic denial of correct information. This exposes a risk in trust calibration: users and system designers should not assume citations improve reliability, and model deployment in high-stakes settings must be accompanied by targeted mitigation.
Theoretically, AuthorityBench demonstrates that epistemic deference heuristics are internalized by LLMs, independent of factual grounding, challenging claims about scale-driven robustness. The suppression/amplification split by model family suggests that architectural or training choices—not scale—govern susceptibility to authority signals.
Future Directions
- Mechanistic Analysis: Investigation of attention patterns and hidden state dynamics to elucidate why citation signals disrupt true claim processing and drive model family divergence.
- Mitigation Evaluation: Prompt-based, fine-tuning, or architectural interventions can be systematically tested using AuthorityBench to reduce citation-induced hallucination.
- Demographic Granularity: Finer-scale demographic signals may expose more subtle biases in epistemic authority processing.
- Frontier Model Testing: Extending evaluation to larger, more advanced LLMs.
Conclusion
AuthorityBench rigorously quantifies how citation-based authority signals induce epistemic failure modes in LLMs, with citation presence—fabricated or real—systematically increasing hallucination susceptibility. The critical TC×FC condition reveals that models are especially prone to denying correct facts when accompanied by fabricated citations, reaching high hallucination rates irrespective of model capability or domain. Venue prestige and author demographics are largely inert; legal claims are resistant due to citation conventions. These results demonstrate that citation signals are treated as authority by LLMs, not evidence, and underscore the need for model-specific mitigation strategies in citation-sensitive applications. AuthorityBench provides a foundation for future research in mechanistic interpretability, mitigation, and robust epistemic reasoning in AI systems.

