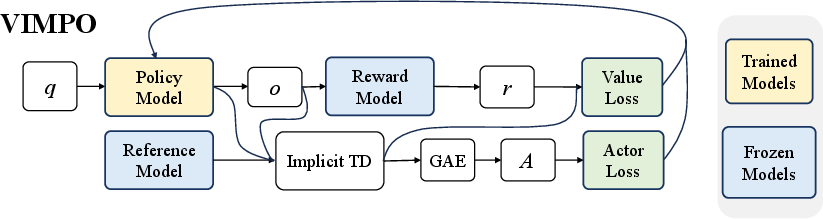
VIMPO: Value-Implicit Policy Optimization for LLMs
Abstract: Reinforcement learning with verifiable rewards has become a central tool for improving the reasoning ability of LLMs, but current methods face a trade-off between simplicity and credit assignment. Group-relative methods such as GRPO avoid training a critic, but typically assign a trajectory-level advantage to every token. Actor-critic methods provide denser learning signals, but require a learned value function with its own training instability. We introduce VIMPO, a critic-free policy optimization method that derives a policy-implied value function from the optimality conditions of KL-regularized reinforcement learning. For autoregressive generation, the resulting value recurrence can be written in terms of policy-reference log-ratios and anchored by the terminal condition that no future reward remains at the end of a trajectory. This gives a simple value loss that incorporates outcome-level verifiable rewards without training a critic. The same derivation also yields a critic-free actor advantage, allowing VIMPO to separate reward incorporation through the value loss from policy improvement through a PPO-style actor update. On mathematical RLVR benchmarks, VIMPO improves over GRPO across MATH-500, AIME 2024, AIME 2025, and OlympiadBench, with especially larger gains on competition-style evaluations. Under noisy rewards, VIMPO retains a consistent advantage over GRPO, suggesting that policy-implied value optimization can provide finer credit assignment while preserving the practical simplicity of critic-free training.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train LLMs so they get better at step-by-step reasoning (like solving math problems). The method is called VIMPO. It aims to keep training simple while still figuring out which parts of a long answer were actually helpful or harmful—a problem known as “credit assignment.”
What questions were they trying to answer?
- Can we give “token-level” feedback (i.e., feedback for each small step or word in an answer) without training an extra, fragile helper model called a “critic”?
- Can we keep training stable and simple like older methods, but still tell the model exactly where it did well or poorly?
- Will this make models better at hard, competition-style math questions, even when some rewards (scores) are noisy or wrong?
How does VIMPO work? (Explained simply)
Imagine the model writing a solution one word at a time:
- “Credit assignment” is deciding which words or steps improved the final answer and which didn’t.
- Many existing simple methods give the same thumbs-up or thumbs-down to every word in the whole answer. That’s easy, but not very precise.
- More advanced methods train a separate “critic” to score each step, but that critic can be hard to train and sometimes destabilizes learning.
VIMPO’s idea: get step-by-step feedback without training a critic.
Here’s the everyday-language version of what VIMPO does:
- The model has a “reference buddy” (a frozen, older version of itself). At each word, VIMPO checks how much the current model prefers that word compared to its buddy. Think of this as a “log-ratio” that measures how different the current choice is from the buddy’s choice.
- If the final answer is correct, the method encourages the sum of these differences (over the whole answer) to match the final score (after centering by the group average, so it’s fair). If the answer is wrong, it pushes in the other direction.
- Crucially, it uses a simple rule at the end of the answer: “there’s no future reward left,” which acts like a boundary condition. That lets VIMPO build an internal “value” signal (how good things look from each step) directly from the model’s own probabilities and the final score—without training a separate critic.
- VIMPO then uses that internal value signal to create a token-level “advantage” (how helpful a token was), and plugs it into a standard, stable update rule similar to PPO (a popular reinforcement learning method).
In short: VIMPO uses the model’s own behavior versus a reference buddy to infer per-step feedback, ties it to the final result, and updates the model in a stable way—no extra critic network needed.
Key terms in simple words:
- Policy: the model’s rule for choosing the next word.
- Reference model: a frozen “buddy” model used for comparison.
- KL (Kullback–Leibler) term: a gentle nudge to not drift too far from the buddy’s style too fast.
- Advantage: a score that says how much a particular step helped the final outcome.
- PPO-style update: a tried-and-true way to adjust the model without making overly big, unstable jumps.
What did they test, and how?
They trained small LLMs to solve math problems using verifiable rewards (a checker says correct/incorrect at the end). They compared VIMPO to a popular critic-free method called GRPO. They tested on multiple math benchmarks:
- MATH-500
- AIME 2024
- AIME 2025
- OlympiadBench
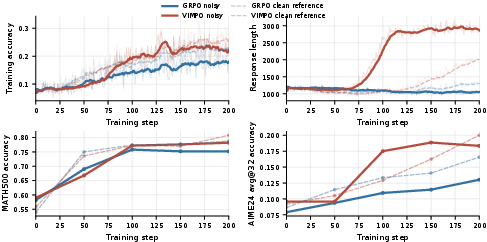
They also ran “noisy reward” tests, where some of the correctness signals were deliberately flipped (wrong), to see which method is more robust.
What did they find?
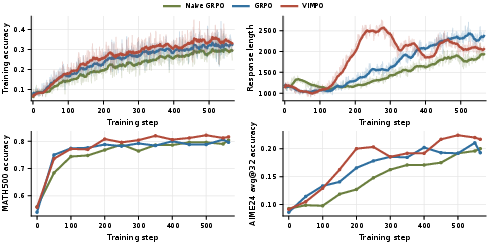
- VIMPO beat GRPO on all tested math benchmarks, especially on harder, competition-style tests (like AIME 2025).
- VIMPO learned faster and reached higher accuracy during training.
- When rewards were noisy (some labels wrong), VIMPO dropped less in performance than GRPO—so it was more robust.
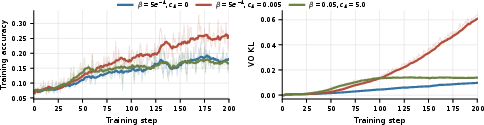
- Ablation studies (turning pieces on/off) showed that:
- The “value-only” part already helps learning.
- Adding the PPO-style actor update makes it learn faster, but you need to tune its strength.
- Using too-strong settings can slow further gains by holding the model too close to the reference too long.
Why this matters: VIMPO gives precise, token-level learning signals like actor–critic methods, but without the extra critic model and its training headaches.
Why is this important?
- Better feedback per step: The model learns which parts of long answers actually mattered, improving reasoning quality.
- Simpler training: No separate critic network to train and stabilize.
- More robust: Handles noisy or imperfect scoring better, which is common in real-world training.
- Practical gains: Stronger performance on tough math tasks suggests this approach could help other step-by-step reasoning jobs (like coding or logic puzzles) that also have clear verifiers.
Limitations and next steps
- They keep the “stay close to the buddy” setting fixed; adapting it over time might work even better.
- Computing the full “how different am I from my buddy” score can be expensive; faster approximations would help.
- Tests focused on math and a specific model size; it’s still unknown how well this scales to bigger models or other tasks (like code or tool-use).
Bottom line
VIMPO is a new, critic-free way to train reasoning in LLMs. It cleverly turns the model’s own probabilities—compared to a reference buddy—into per-step feedback tied to the final result, then updates the model with a stable rule. This yields better accuracy and robustness than a popular simple baseline, while staying easier to manage than full actor–critic setups.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research:
- Theory: No convergence or monotonic-improvement guarantees for minimizing the combined objective L_V + c_A L_A after substituting the optimal-policy identities with the current policy π. Clarify conditions under which VIMPO provably improves expected return.
- Bias/variance of estimators: The “zero-mean” argument relies on expectations under π. Characterize the bias introduced when using π instead of π, and quantify the variance of both the value-loss residual and the actor advantage relative to GRPO and actor-critic baselines.
- Initial value anchor: V̂0 is set to the group-mean return. Analyze the bias-variance trade-offs of this estimator as a function of group size G, and compare against alternative baselines (e.g., per-prompt moving averages, EMA, control variates, or a lightweight learned baseline).
- Truncation and timeouts: The terminal condition Vπ(s_T)=0 assumes natural EOS termination. Specify how to handle length-capped or truncated trajectories, tool-call failures, or other non-rewarding terminations (e.g., bootstrapping rules, partial targets).
- Discounting: Experiments fix γ=1. Evaluate behavior for γ<1 with long horizons, variable sequence lengths, and early stopping; study sensitivity and best practices for choosing γ in RLVR.
- KL dependence: The value and advantage rely on exact full-distribution KL at every token. Assess scalable approximations (e.g., top-k/top-p KL, sampled KL, cached reference logits) and their impact on stability, bias, and performance.
- Reference policy management: The reference is frozen and β is fixed. Develop and evaluate schedules for β and c_A, criteria for periodically updating the reference, and trust-region-like schemes; study how these choices affect stability and asymptotic performance.
- Actor update without reward signals: The actor advantage is reward-free and may drive policy drift when c_A is large. Characterize regimes where this drift harms returns, propose safeguards (e.g., adaptive c_A, reward-gated updates), and provide diagnostics for detecting drift.
- Value-loss gradient control: The value loss is an un-clipped squared error of cumulative log-ratios minus centered reward. Investigate gradient clipping, robust losses (Huber/quantile), or per-token weighting to prevent rare large residuals from destabilizing training.
- PPO design choices: Explore sensitivity to PPO clip range, entropy bonus, advantage normalization windows, and GAE λ; compare the proposed one-step TD to multi-step variants empirically.
- Dense/step rewards: The method is specialized and evaluated primarily with terminal outcome rewards. Validate correctness and performance on shaped, stepwise, or partially dense rewards; clarify how the separation of reward incorporation (value loss) and actor update should adapt.
- Non-i.i.d. reward noise: Robustness is tested only under i.i.d. label flips. Evaluate structured/bias noise (e.g., systematic verifier bias, adversarial spurious patterns), delayed-verifier errors, and reward-hacking susceptibility.
- Stochastic environments: The derivation assumes deterministic transitions (autoregressive decoding). Extend the identity and training rules to stochastic transitions (e.g., tool use, retrieval, API calls) and evaluate empirically.
- Generality beyond math RLVR: Validate transfer to other verifiable domains (code, theorem proving, program synthesis with test suites, formal reasoning) and to tasks with partial or proxy verifiers.
- Scale-up and systems cost: Quantify wall-clock throughput, memory footprint, and token-level compute overhead vs GRPO and actor-critic PPO/VAPO, especially with full KL; provide scaling studies at 7B/14B+ scales.
- Stronger baselines: Compare against tuned actor-critic baselines (PPO/VAPO), and recent critic-free/value-based methods (e.g., DAPO with dynamic sampling/filtering, TBRM, ROVER, FIPO), to disentangle objective gains from implementation details.
- Statistical robustness: Report multiple seeds, confidence intervals, and statistical tests; study run-to-run variability and failure modes under identical hyperparameters.
- Exploration dynamics: Analyze how the reward-free actor advantage affects exploration vs exploitation, especially early in training; compare to entropy bonuses and KL-trust-region constraints.
- Token-level credit fidelity: Empirically verify that high-advantage tokens correspond to causally important reasoning steps (e.g., via ablations, perturbation tests, or human annotations), not just stylistic or length-related artifacts.
- Length control and early stopping: Provide principled handling of response-length dynamics (length penalties, adaptive stopping criteria) to prevent learning length as a proxy for reward.
- Prompt/context tokens: Clarify whether KL is computed over prompt vs response tokens; study the impact of excluding/including prompt tokens on stability and sample efficiency.
- Hyperparameter surfaces: Beyond β and c_A, systematically map sensitivity to group size G, batch size, learning rate, optimizer, advantage normalization statistics, and temperature/sampling strategies.
- Off-policy/replay data: Explore reusing past trajectories or offline logs with importance sampling in VIMPO’s log-ratio framework; characterize stability and bias under off-policy mixtures.
- Safety and alignment side-effects: Assess whether optimizing log-ratio-driven objectives induces verbosity, sycophancy, or other undesirable behaviors; evaluate broader alignment and harmlessness metrics alongside reasoning performance.
- Multiple correct forms and partial credit: For problems with equivalent answers or formatting variability, study how verifiers and reward definitions interact with VIMPO’s targets; design robust reward extraction to avoid penalizing correct-but-different outputs.
- Reference selection: Investigate how the choice of reference (e.g., SFT vs base, distilled vs larger teacher) affects learning dynamics and final performance; consider adaptive mixtures or ensembles of references.
- Integration with preference data: Examine how VIMPO interacts with offline preference optimization (DPO/IPO/ORPO/KTO) and whether policy-implied value training can bridge online RLVR and offline preference fine-tuning in a unified pipeline.
Practical Applications
Overview
VIMPO is a critic-free reinforcement learning method for LLMs that delivers token-level credit assignment without training a separate value network. It derives a policy-implied value from KL-regularized optimality conditions and a terminal boundary condition, and uses a closed-form, log-ratio-based advantage for PPO-style updates. Empirically, it outperforms GRPO on mathematical RL with verifiable rewards and is more robust to noisy reward labels. Below are actionable applications and workflows that leverage these findings.
Immediate Applications
The following applications can be prototyped or deployed now, assuming access to verifiable reward signals, a frozen reference model, and existing RLHF/RLVR infrastructure.
- Software engineering: RLVR upgrade for reasoning-intensive copilots
- Use case: Replace GRPO with VIMPO in existing pipelines that fine-tune code/maths copilots (e.g., code generation validated by unit tests, math solvers validated by checkers).
- Sector: Software; Education.
- Tools/products/workflows: “VIMPO trainer” modules for TRL/TRLX/veRL; CI/CD fine-tuning loops that run unit tests as verifiers; dataset curation with pass/fail verifiable signals.
- Assumptions/dependencies: High-quality verifiers (unit tests/math checkers); ability to compute full-distribution KL against a frozen reference; group sampling per prompt; hyperparameter tuning (β, c_A).
- SQL and analytics assistants with execution-time verifiers
- Use case: Fine-tune SQL/analytics LLMs with reward = query executes + passes asserts/constraints (e.g., row counts, invariants).
- Sector: Software; Finance; Business Intelligence.
- Tools/products/workflows: Sandboxed DB harness; assertion libraries; “SQL-RLVR” training loops integrating VIMPO value loss + PPO actor.
- Assumptions/dependencies: Safe database sandbox; robust, fast verifiers to keep training throughput high; flaky-query handling.
- Noise-robust RLVR for flaky or imperfect verifiers
- Use case: When tests/checkers have nontrivial false positives/negatives, switch to VIMPO for better stability than GRPO.
- Sector: Software QA; Code Intelligence; Evaluation Infrastructure.
- Tools/products/workflows: “Noisy-Reward-Resilient” training option that routes actor updates through policy-implied log-ratio advantages while value loss absorbs outcome-level noise.
- Assumptions/dependencies: Reward corruption is bounded; batch-level advantage normalization; careful monitoring of reward noise and length dynamics.
- Math tutoring and assessment systems with auto-grading
- Use case: Fine-tune math tutors on verifiable problem sets; generate worked solutions with improved accuracy and robustness.
- Sector: Education.
- Tools/products/workflows: Tutor models trained on curated, auto-gradable math data; step-wise correctness checks; validation harnesses (e.g., MATH-500/AIME-style setups).
- Assumptions/dependencies: Verifiable grading for problems; guardrails to avoid teaching-to-the-test; compute budgets for group rollouts.
- Enterprise copilots constrained by rule engines
- Use case: Post-train models to comply with internal policy/rule engines (e.g., template adherence, format compliance, PII removal), where pass/fail is verifiable.
- Sector: Policy/Compliance; Enterprise Software.
- Tools/products/workflows: “Compliance-RLVR” where reward = passes rule-based validators; continuous VIMPO fine-tuning to reduce manual audits.
- Assumptions/dependencies: High-coverage rule engines; auditable logs; frozen or periodically updated reference model; controlled KL to preserve house style.
- Lightweight RLVR without a critic model
- Use case: Reduce system complexity by removing the value network while retaining token-level credit signals.
- Sector: MLOps; Research; Startups.
- Tools/products/workflows: Training stacks that maintain only policy + frozen reference; parameter/compute savings; simpler failure modes than actor-critic.
- Assumptions/dependencies: Exact KL adds overhead (full next-token distributions); benefit-cost depends on model size and sequence length.
- Academic benchmarking for credit assignment in LLM RL
- Use case: Study fine-grained credit assignment and RLVR stability without confounding critic learning.
- Sector: Academia.
- Tools/products/workflows: Public VIMPO implementations; standardized noisy-reward stress tests; ablation suites (β/c_A schedules).
- Assumptions/dependencies: Comparable evaluation pipelines; reproducible seeds; transparent logging of KL, lengths, and token-level signals.
Long-Term Applications
These applications are promising but need further research, scaling, domain-specific verifiers, or algorithmic extensions (e.g., approximate KL, adaptive schedules, reference updates).
- Tool-augmented agents with verifiable subgoals
- Use case: Multi-tool chains where each subgoal has a checker (file exists, API returns expected schema, formal property holds); train with VIMPO to assign token-level credit across long tool sequences.
- Sector: Software; Operations; DevOps.
- Tools/products/workflows: “Subgoal-RLVR” frameworks that define compositional verifiers per tool call; GAE-style aggregation over tool steps.
- Assumptions/dependencies: Reliable, fast subgoal verifiers; logging across tools; careful handling of partial observability and latency.
- Healthcare decision support under rule-based/knowledge verifiers
- Use case: Clinical coding (ICD/CPT), formulary checks, dose calculators, order-set compliance against guidelines encoded as rules.
- Sector: Healthcare.
- Tools/products/workflows: “Clinical-RLVR” pipelines with deterministic validators; offline replay via de-identified cases; safety gating and human-in-the-loop review.
- Assumptions/dependencies: High-precision verifiers; regulatory approval; rigorous safety monitoring; privacy-preserving infrastructure; domain shift controls.
- Finance and compliance copilots with deterministic controls
- Use case: Report drafting, reconciliation, spreadsheet formula generation, rule-constrained narratives validated by deterministic checks (balance invariants, policy constraints).
- Sector: Finance; Compliance; Audit.
- Tools/products/workflows: Rule engines and ledger checks as verifiers; “Audit-Ready RLVR” with training logs for traceability.
- Assumptions/dependencies: Robust rule coverage; strong governance; liability and model risk management; auditable KL/reference schedules.
- Robotics and embodied planning via simulator-verified rewards
- Use case: High-level plan/program synthesis for robots validated in simulators (collision-free, task completion).
- Sector: Robotics.
- Tools/products/workflows: Simulator-as-verifier loops; token-level advantages to encourage key reasoning/planning tokens; curriculum from simple to complex tasks.
- Assumptions/dependencies: Fast, faithful simulators; bridging sim-to-real; verifiers that reflect real-world constraints; alignment with low-level controllers.
- Energy, logistics, and operations optimization via simulation verifiers
- Use case: Propose schedules or control sequences validated by power grid/building/logistics simulators (meets constraints, objective improves).
- Sector: Energy; Supply Chain; Smart Buildings.
- Tools/products/workflows: “Sim-RLVR” stacks wrapping domain simulators; batched scenario verifiers; annealed β/c_A to control policy shift.
- Assumptions/dependencies: Scalable simulators; accurate metrics; long horizons may require hierarchical objectives and better credit propagation.
- Scalable VIMPO for frontier models
- Use case: Apply VIMPO at 70B+ scales where critic-free stability and dense token-level signals are desirable.
- Sector: Foundation Models; Cloud AI.
- Tools/products/workflows: Approximate/candidate-set KL; periodically updated reference policies; schedule adaptation for β and c_A; KV-cache reuse for reference.
- Assumptions/dependencies: Efficient KL approximations preserving centering properties; reference-update protocols; robust memory/throughput engineering.
- Standards and policy: Verifiable-reward alignment and auditability
- Use case: Regulatory frameworks encouraging verifiable-reward training to reduce reliance on subjective labels; audit trails for training decisions.
- Sector: Policy/Regulation; Governance.
- Tools/products/workflows: Training artifacts that log verifier decisions, group baselines, KL budgets, and advantage normalization; compliance dashboards.
- Assumptions/dependencies: Agreed-upon verifiers and benchmarks; incentives for transparency; privacy/security of logs.
- Education at scale with verified assessments
- Use case: National or district-wide tutoring/assessment systems where tasks have automated verifiers (math, physics problems with checkable outputs).
- Sector: Education.
- Tools/products/workflows: Curriculum-aligned verifier banks; adaptive VIMPO schedules (stronger regularization early, relaxed later); bias/fairness audits.
- Assumptions/dependencies: Coverage of verifiable tasks; avoidance of narrow test gaming; equitable access and monitoring.
Cross-cutting assumptions and dependencies
- Verifiable rewards are available and sufficiently informative; tasks without reliable checkers are out-of-scope.
- Frozen reference models and β/c_A schedules meaningfully constrain learning early but may need adaptation or reference updates later.
- Exact full-distribution KL can be costly for long sequences/large vocabularies; approximate KL or candidate-set methods may be required for scaling (risking changed centering properties).
- Group sampling per prompt and outcome-only rewards fit VIMPO’s current strengths; extensions may be needed for dense, non-terminal rewards.
- Current evidence is strongest in mathematical reasoning; domain transfer (code, tool use, healthcare, robotics) requires empirical validation.
Glossary
- Action-value function: The expected return from taking an action in a state and following a policy thereafter. Example: "we use the standard finite-horizon expected-return action-value function:"
- Actor-critic methods: RL methods that learn a policy (actor) and a value function (critic) jointly. Example: "Actor-critic methods such as PPO and VAPO retain a learned value function"
- Advantage: A baseline-centered signal indicating how much better an action is than average at a state. Example: "assign a trajectory-level advantage to every token."
- Advantage normalization: Rescaling advantages to zero mean and unit variance before optimization to stabilize updates. Example: "before applying the PPO surrogate we normalize the detached advantages over valid response tokens"
- Autoregressive generation: Generating tokens sequentially where each token depends on previous ones. Example: "For autoregressive generation, the resulting value recurrence can be written in terms of policy-reference log-ratios"
- Baseline (group baseline): A reference value subtracted from returns to reduce variance, computed over a group of rollouts for the same prompt. Example: "replacing the learned state-dependent baseline with a sample-based group baseline"
- Bellman-consistency objective: A training objective enforcing that values satisfy Bellman relationships along trajectories. Example: "This gives a critic-free Bellman-consistency objective"
- Bellman equation: A recursive relationship linking value and action-value via immediate reward and next-state value. Example: "The deterministic transition collapses the Bellman equation to:"
- Bellman recurrence: The step-by-step recursive formulation of the value across tokens or time. Example: "The terminal condition closes the Bellman recurrence"
- Bellman residual: The difference between both sides of the Bellman equation, measuring temporal-difference error. Example: "the per-token log-ratio against the reference policy is a Bellman residual plus a KL correction."
- Clipped PPO surrogate: The PPO objective that clips probability ratios to limit destructive policy updates. Example: "the negative clipped PPO surrogate"
- Credit assignment: Determining which actions or tokens contributed to outcomes to allocate learning signal appropriately. Example: "current methods face a trade-off between simplicity and credit assignment."
- Critic: The learned value function estimating expected returns for states or state-action pairs. Example: "avoid training a critic"
- Critic-free: Methods that do not learn a separate value model but still optimize the policy. Example: "a critic-free policy optimization method"
- Deterministic-transition MDP: An MDP where the next state is fully determined by the current state and action. Example: "model autoregressive generation as a deterministic-transition MDP"
- Direct Preference Optimization (DPO): A method that optimizes policy via preference comparisons using log-ratios against a reference. Example: "DPO shows that the optimal policy of a KL-regularized preference objective can be expressed through a log-ratio against a reference policy"
- Entropy-regularized soft value: A value definition that incorporates an entropy term to encourage exploration. Example: "the entropy-regularized soft value used in Path Consistency Learning and soft Q-learning"
- FIPO: A method that refines GRPO’s signal using future KL information. Example: "FIPO re-weights the GRPO advantage using a future-KL factor"
- Frozen reference model: A fixed reference policy used to measure KL or log-ratios during training. Example: "against a frozen reference model."
- Generalized Advantage Estimation (GAE): A technique to compute low-variance, multi-step advantage estimates. Example: "generalized advantage estimation"
- GRPO: A group-relative, critic-free method that estimates advantages using groups of rollouts per prompt. Example: "Group-relative methods such as GRPO avoid training a critic"
- KL divergence: A measure of how one probability distribution differs from a reference distribution, used as a regularizer. Example: "KL correction"
- KL-regularized reinforcement learning: RL that includes a KL penalty to a reference policy to constrain updates. Example: "the optimality conditions of KL-regularized reinforcement learning."
- KL reward penalty: Penalizing the policy’s deviation from a reference via a KL term added to the reward/objective. Example: "disable the KL reward penalty"
- Log-ratio (policy-reference log-ratio): The logarithm of the probability ratio between the policy and the reference for a sampled token. Example: "policy-reference log-ratios"
- Monte Carlo estimate: An estimate computed by averaging sampled outcomes (e.g., returns) over rollouts. Example: "a Monte Carlo estimate of the initial value"
- Path Consistency Learning: A method enforcing multi-step consistency between values and policies. Example: "Path Consistency Learning trains policies and values by enforcing multi-step consistency conditions"
- Policy-implied TD advantage: An advantage computed from policy-reference log-ratios and KL terms without a learned critic. Example: "we define the policy-implied TD advantage"
- Policy-implied value (function): A value computed from the policy’s log-ratios and KL, anchored by terminal conditions, without a learned critic. Example: "train a policy-implied value function without requiring a separately learned critic"
- PPO (Proximal Policy Optimization): A widely used actor-critic algorithm with clipped updates. Example: "PPO remains the standard actor-critic algorithm for policy optimization"
- PPO-style actor update: Applying PPO’s clipped surrogate and advantage to update the policy parameters. Example: "a PPO-style actor update"
- Reference policy: The fixed policy used to compute KL penalties and log-ratios relative to the current policy. Example: "the reference policy"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL setting where rewards are computed by verifiable procedures (e.g., solution checkers). Example: "Reinforcement Learning with Verifiable Rewards~(RLVR)"
- Rollout: A sampled trajectory generated by the policy for a given prompt. Example: "groups of rollouts for the same prompt"
- Soft Q-learning: An RL method that incorporates entropy regularization into the value and policy updates. Example: "soft Q-learning derives policy updates from entropy-regularized Bellman equations"
- Stop-gradient operator: An operation that prevents gradients from flowing through a term during backpropagation. Example: "where denotes the stop-gradient operator."
- Temporal-difference (TD) advantage: The one-step difference r + γV(s′) − V(s), used as an advantage signal. Example: "a closed-form one-step temporal-difference advantage"
- Token-level credit assignment: Assigning learning signal at the granularity of individual tokens rather than whole sequences. Example: "token-level credit assignment"
- Value function: The expected cumulative reward from a state under a policy. Example: "retain a learned value function"
- Value loss: A loss term used to train the value estimate or its implied counterpart. Example: "This gives a simple value loss"
- Value recurrence: A recursive formula expressing value at each step via previous values and per-step terms. Example: "the resulting value recurrence can be written in terms of policy-reference log-ratios"
- Verifiable rewards: Rewards computed by deterministic, checkable procedures (e.g., programmatic validators). Example: "Reinforcement learning with verifiable rewards has become a central tool"
- Zero-mean signal: A signal with expectation zero, often used to reduce variance and stabilize learning. Example: "Zero-mean signal."
Collections
Sign up for free to add this paper to one or more collections.

