- The paper presents ViGOS, a framework that decouples visual perception and answer-conditioned reasoning to prevent shortcut behaviors in multimodal on-policy self-distillation.
- ViGOS enforces structured rollouts with image-only supervision for descriptive segments and controlled answer guidance for reasoning, significantly reducing the Privileged Answer Leakage Rate.
- Empirical results across diverse benchmarks demonstrate that ViGOS improves image grounding and reasoning performance, offering a robust solution for multimodal model alignment.
Decoupling Perception and Reasoning in Multimodal On-Policy Self-Distillation: An Analysis of ViGOS
Introduction
Multimodal LLMs (MLLMs) have demonstrated remarkable success in tasks requiring integrated perception and reasoning. However, training protocols adapted from unimodal LLMs, such as on-policy self-distillation (OPSD), can induce undesirable shortcut behaviors in the multimodal context. The OPSD paradigm, effective for unimodal LLMs by providing dense, on-policy, token-level supervision from a privileged teacher (with access to the reference answer), introduces shortcut risks when applied to MLLMs. Specifically, the privileged answer conditioning can dominate the multimodal reasoning trajectory, causing models to follow the answer signal before grounding responses in visual evidence. This deficit is empirically validated in shortcut-sensitive benchmarks and through attribution diagnostics.
The paper "Seeing Before Reasoning: Decoupling Perception and Reasoning for Shortcut-Resilient Multimodal On-Policy Self-Distillation" (2606.19120) proposes ViGOS: a modified OPSD framework which decouples visual perception from answer-conditioned reasoning supervision, enforcing a training protocol that first grounds responses in explicit visual description before permitting answer-guided reasoning. This essay provides a comprehensive technical summary and critical analysis of ViGOS, emphasizing its empirical advantages, shortcut mitigation mechanism, and implications for multimodal alignment.
Shortcut Induction in Vanilla Multimodal OPSD
The fundamental risk in extending vanilla OPSD to MLLMs is illustrated by the shortcut pathway: supervision is dominated by the privileged answer, circumventing the need for the model to ground early response segments in the image (Figure 1).
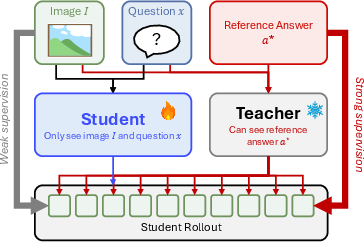
Figure 1: Shortcut risk in vanilla OPSD for MLLMs; privileged answer information conditions the rollout at all positions, potentially bypassing image grounding.
The authors introduce the Privileged Answer Leakage Rate (PALR), a diagnostic metric quantifying the proportion of the token-level teacher signal attributable to the privileged answer (as opposed to the image). PALR analyses on Qwen2.5-VL demonstrate that, in vanilla OPSD, a substantial fraction of the correction applied to reasoning and answer tokens is answer-driven rather than image-driven (17.26% on 3B and 26.01% on 7B for the reasoning-answer segment, Figure 2).
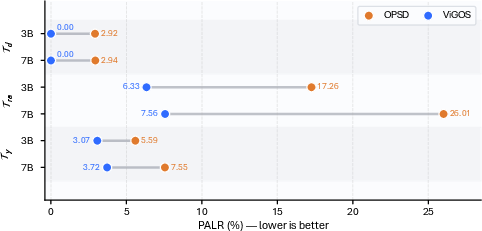
Figure 2: PALR diagnostic results on Qwen2.5-VL; lower is better, reflecting reduced shortcut behavior.
This demonstrates that dense, answer-conditioned supervision introduces a shortcut that compromises the intended image-grounded reasoning, confounding the distinction between perception (extracting visual facts) and high-level reasoning (inferring the answer).
ViGOS: Decoupled Visual Grounding and Reasoning Supervision
ViGOS addresses shortcut risk by enforcing a structured sequence in student model rollouts: first, an explicit visual description (d), then detailed chain-of-thought reasoning (r), and finally the boxed answer (a); that is, y=(d,r,a). Crucially, supervision is decoupled by segment (Figure 3):
- The visual description d is supervised using an image-only perception teacher, who never sees the question or privileged answer.
- The reasoning and answer segments (r, a) are supervised by a privileged reasoning teacher, conditioned on both the task and reference answer.
- If the rollout deviates from the required structure, a reference teacher acts as a fallback to regularize output format, but never provides dense answer supervision for image-description tokens.
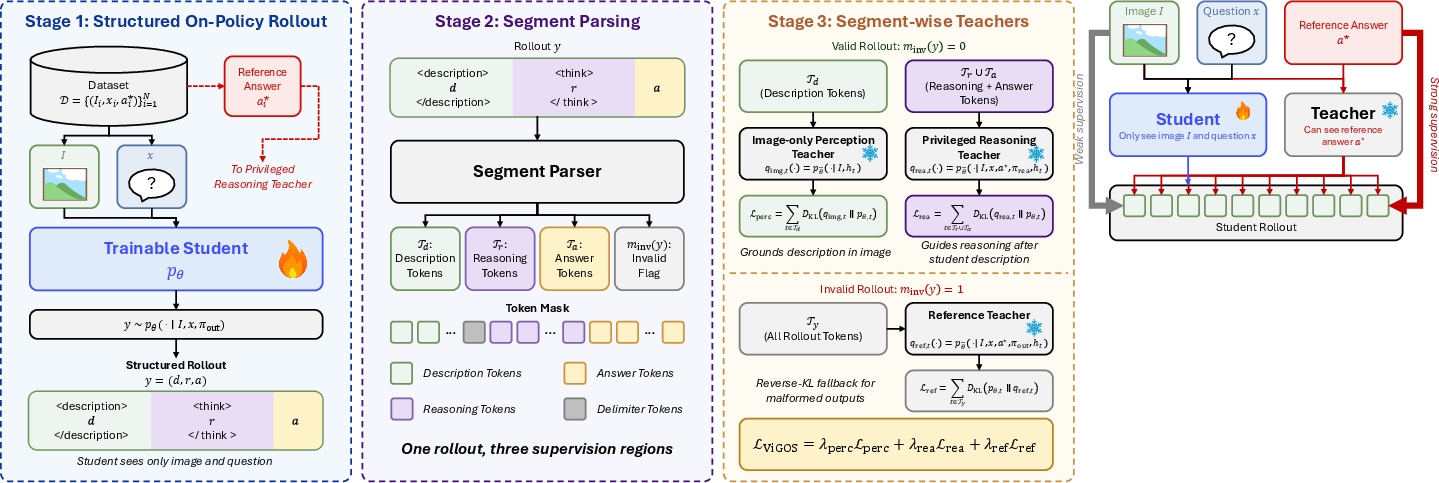
Figure 3: Training pipeline of ViGOS, illustrating the cascade of student rollout, parsing, and role-specific teacher supervision.
This segmentation ensures that early response segments cannot be directly shaped by the answer. The PALR for reasoning-answer segments drops significantly under ViGOS (6.33% for 3B and 7.56% for 7B), and it is identically zero for description segments since the perception teacher cannot benefit from the answer (Figure 2). Thus, ViGOS operationalizes true image-first grounding before reasoning, disabling shortcuts through privileged answer leakage.
Empirical Analysis and Benchmark Evaluation
The empirical evaluation covers broad vision-language and reasoning tasks, including MM-Vet, MMMU, MathVerse, MathVista, spatial grounding (MMSI, RealWorldQA, CV-Bench), and prior-sensitive stress tests (ViLP).
- On standard benchmarks, ViGOS achieves comparable or superior Pass@5 and Avg@5 to both vanilla OPSD and competitive RL-based methods. Gains are most salient on image-grounded benchmarks (RealWorldQA, MMSI, CV-Bench, MathVista), demonstrating effective alignment of reasoning with perceptual evidence.
- On prior-sensitive evaluation (ViLP), where high image grounding and retention of useful priors must be balanced, ViGOS achieves the highest image-sensitive Score while maintaining competitive Prior (Table 1; Figures 4 and 5).
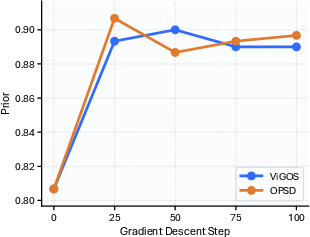
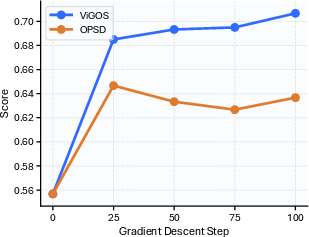
Figure 4: Step-wise comparison between OPSD and ViGOS on ViLP. ViGOS robustly improves image-grounded Score while keeping prior accuracy.
Ablation on the decoupled supervision components demonstrates:
- The perception teacher is necessary for maximizing image-to-text alignment in descriptions.
- The privileged reasoning teacher is crucial for effective solution derivation from visual evidence.
- The reference fallback is essential for maintaining output format robustness without re-introducing shortcut risk by overusing privileged supervision in malformed rollouts.
Token-level PALR visualization further confirms that post-ViGOS, the descriptive segments become highly image-driven, while answer-conditioned reasoning is selectively applied only after image evidence is available (Figure 5).
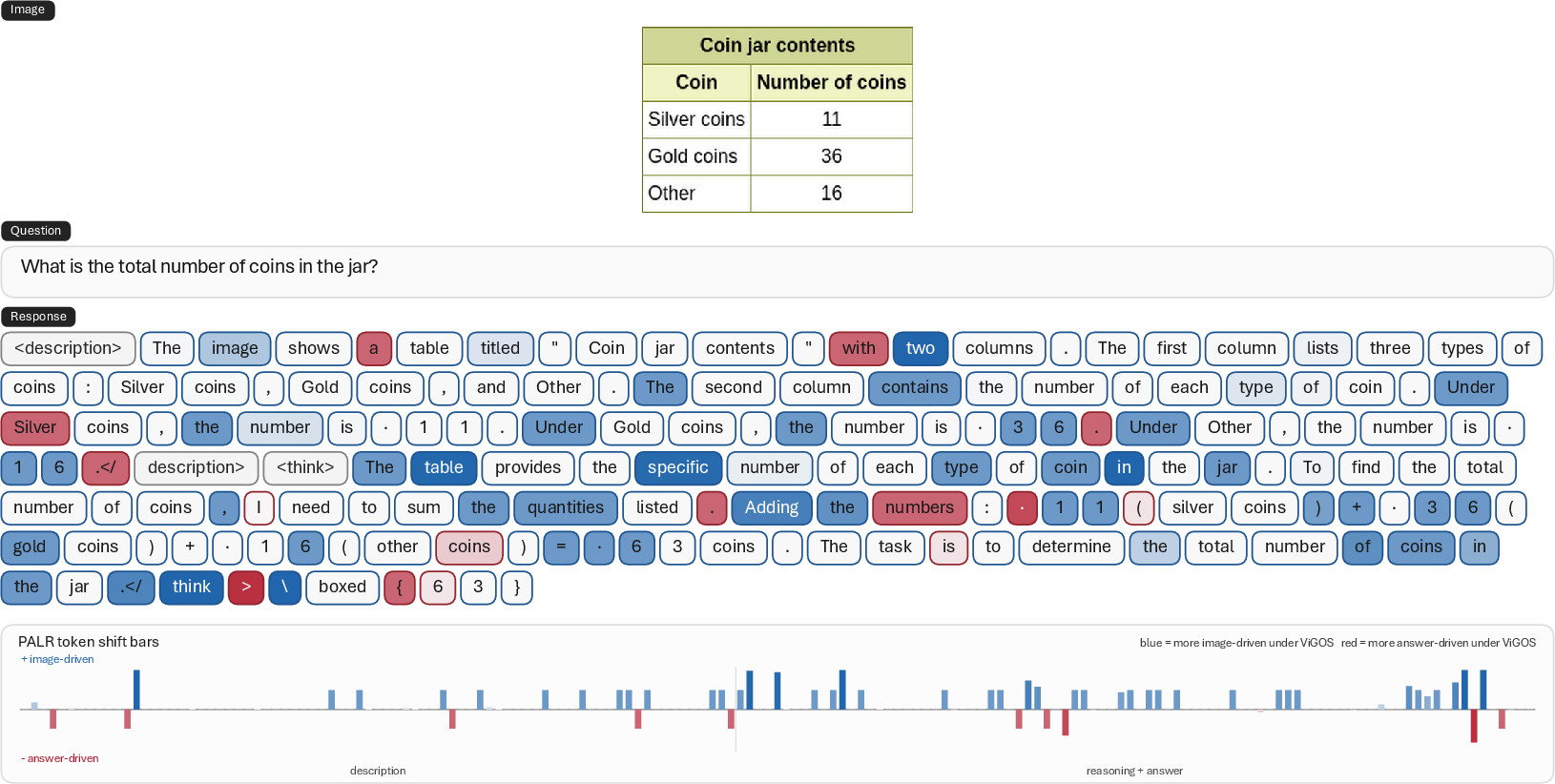
Figure 5: Token-level PALR shift example on Qwen2.5-VL-7B; ViGOS transitions visual evidence tokens to image-driven supervision while preserving controlled answer guidance for reasoning.
Theoretical Implications and Future Directions
ViGOS offers a clear demonstration that structured rollout and segment-specific supervision can mitigate answer-conditioned shortcut induction in multimodal training. By enforcing a decoupling between perception (grounded in visual evidence) and downstream reasoning (guided by reference answers), ViGOS robustly impedes prior- and answer-driven biases that degrade calibration and interpretability.
- Practical Implication: ViGOS' modular supervision protocol is directly applicable to post-training MLLM pipelines, enabling high image-grounded accuracy and improved transparency in visual reasoning pipelines.
- Model Alignment: The approach illuminates the need for explicit interfaces (e.g., visual descriptions) in structured MLLM reasoning, suggesting that "chain-of-sight" may become a necessary precursor to chain-of-thought for robust multimodal alignment.
- Limitations: The method introduces marginal computational overhead (multiple teacher forward passes per rollout) and assumes the completeness and correctness of visual self-description. The quality of image-only perception teachers can itself bottleneck overall accuracy.
- Extensions: Further research could investigate end-to-end, self-improving perception modules, integration with RL-based reward models that penalize shortcut artifacts, and application to video or multi-image reasoning settings.
Conclusion
ViGOS operationalizes a principled solution to the core shortcut problem in multimodal on-policy self-distillation by decoupling perception from reasoning. Structured rollouts and role-specific teacher inference provide robust image grounding, drastically reducing answer-conditioned shortcut induction, and maintaining high performance across both canonical and shortcut-sensitive benchmarks. This provides strong empirical and theoretical evidence that the decoupling of perception and reasoning is a fundamental requirement for scalable, interpretable, and robust MLLM post-training (2606.19120).