- The paper introduces Visual-OPSD, a cross-modal self-distillation method that transfers generative visual reasoning knowledge into a text-only student model.
- It achieves a 14× inference speedup and notable spatial reasoning accuracy improvements by leveraging token-level JSD distillation.
- Empirical results close the teacher–student knowledge gap, enabling efficient multimodal reasoning without costly visual thought generation.
Visual-OPSD: Cross-Modal On-Policy Self-Distillation for Efficient Unified Multimodal Reasoning
Background and Motivation
Unified multimodal models (UMMs) have demonstrated emergent interleaved chain-of-thought (CoT) reasoning abilities by alternating text outputs with generated "visual thoughts" (VTs) through intermediate diffusion-based image synthesis. Spatial reasoning tasks benefit from these intermediate visual representations; however, their inference cost is prohibitive—each VT incurs 50 denoising steps, leading to an order-of-magnitude latency increase relative to text-only inference. Critically, controlled interventions reveal that removing or noising these VTs at inference has negligible impact on accuracy across multiple spatial and general benchmarks, except in cases where VTs offer unique high-quality cues.
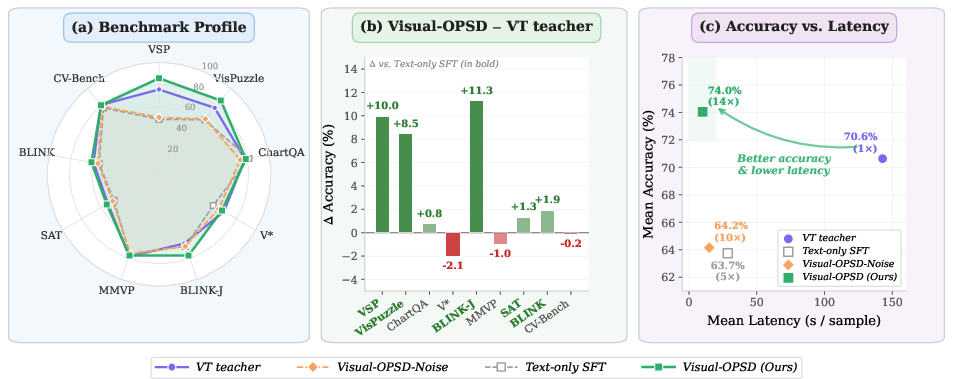
Figure 1: Visual-OPSD achieves accuracy comparable to its VT-generating teacher with a 14× reduction in latency, attaining strong per-task gains and improving the accuracy–latency Pareto.
Empirical analyses show that visual generation training modifies model completion distributions, with VT-conditioning producing significant divergences measurable by KL diagnostics. This suggests that internal representations established along the generative pathway encode reasoning knowledge beyond pixel-level visual information. Visual-OPSD leverages this observation by transferring the semantic signal from generation-trained pathways into a text-only student, closing the performance gap with drastically improved efficiency.
Methodology
Cross-Modal On-Policy Self-Distillation (Visual-OPSD)
Visual-OPSD introduces a cross-modal self-distillation protocol in which teacher and student share identical weights but differ by conditioning context. The teacher receives privileged VT images alongside the problem input; the student only sees the image and question. Both operate along the student’s on-policy trajectory—completion tokens are generated by the student and scored by both, with token-level JSD distillation (β=0.5 by default) as the learning signal.
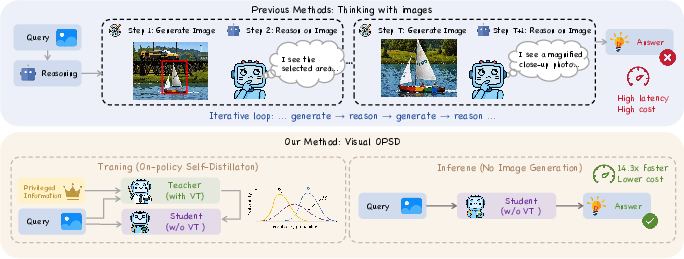
Figure 2: Visual-OPSD distills the generative pathway into a text-only student using cross-modal on-policy self-distillation, outperforming prior iterative visual CoT protocols while eliminating image generation at inference.
This framework exploits the distributional gap induced by the privileged channel, formalized and measured via average per-token KL divergence. Empirical results exhibit substantial KL divergence, with spatial reasoning tasks particularly enriched. Visual-OPSD marginalizes over VT noise during distillation, pushing the student distribution toward a denoised reference distribution that approximates the teacher’s knowledge without inheriting pixel-level artifacts.
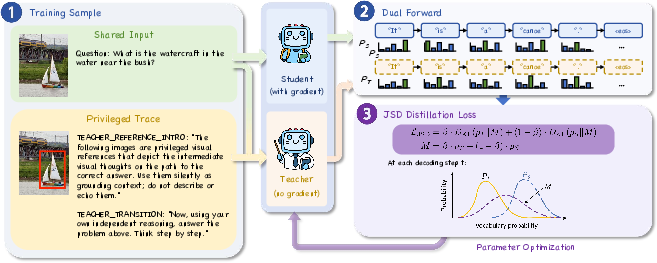
Figure 3: Visual-OPSD pipeline: the student operates with image and question only, while the EMA teacher is conditioned on privileged visual thoughts. Distillation occurs via per-token JSD on shared completions along on-policy student rollouts.
Training Details and Theory
On-policy sampling ensures the alignment of trajectories. Attempts by the student to enter generation mode are intercepted to maintain text-only rollouts. The training objective is pure trajectory-averaged JSD, computed on completion tokens. Per-token clipping and top-K token restriction are used for memory and stability. Analytical decomposition confirms that distribution-level distillation across noisy VTs drives the student toward a mean-noise, task-relevant signal, resulting in students sometimes exceeding their teachers, particularly on complex spatial tasks.
Experimental Results
Visual-OPSD is evaluated on nine benchmarks spanning spatial reasoning and general VLM tasks. It is compared against ThinkMorph (interleaved CoT VT teacher), text-only SFT, and a noise control.
- Performance: Visual-OPSD outperforms its generative teacher on 6/9 benchmarks (+3.4pp average accuracy improvement), with major gains on spatial reasoning: +10.0 (VSP), +8.5 (VisPuzzle), +11.3 (BLINK-J).
- Efficiency: Achieves 14.3× speedup (10.0s/sample vs 142.8s for ThinkMorph).
- Compression: Output sequences are ~2× shorter than baselines; inference efficiency is amplified by concise reasoning traces.
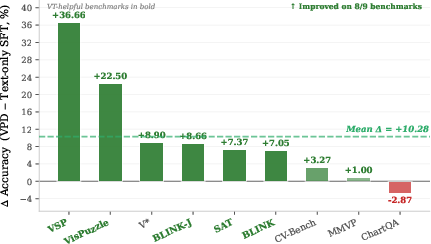
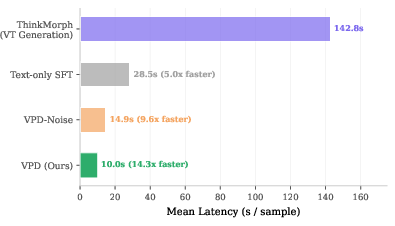
Figure 4: Generation knowledge transfer is most pronounced in spatial reasoning tasks; Visual-OPSD achieves the highest accuracy among open 7–8B models and is significantly faster than VT-generative teachers.
VT information quality scaling confirms the transfer mechanism: replacing real VT images with Gaussian noise eliminates the gains, supporting that distilled knowledge is semantic, not a regularization artifact.
Analysis and Case Studies
Per-Sample Analysis
Visual-OPSD achieves superior performance by reasoning directly from the input image and question, avoiding pitfalls associated with VT dependency. Cases illustrate that generative VTs can introduce noise, reinforce errors, strip relevant context, or destabilize reasoning. Visual-OPSD, having internalized the generative pathway’s signal at the distribution level, sidesteps these issues.
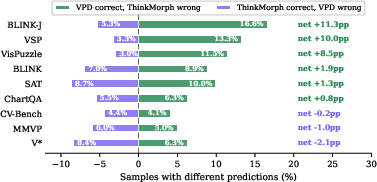
Figure 5: Visual-OPSD wins substantially more samples on VT-useful spatial tasks compared to ThinkMorph; on benchmarks favoring VT-rich cues, the deficit is minimal and near-symmetric.
Cases where high-quality VTs are genuinely helpful for fine-grained perception and annotation are noted as failure modes for Visual-OPSD, indicating the boundary for VT-independent reasoning.
Knowledge Transfer Verification
Token-level KL analyses show that generation knowledge transfer is non-uniform, concentrating on spatially informative tokens (relations, quantitative values, object labels). Post-distillation, Visual-OPSD closes 58.4% of the teacher–student distributional gap, supporting effective internalization of generative reasoning knowledge. Noise controls close <4% and show negligible performance improvement.

Figure 6: Per-token KL diagnostic reveals selective concentration of generation knowledge on spatially informative tokens.
Implications and Future Directions
Visual-OPSD establishes that cross-modal OPSD can bridge generative–understanding pathways within UMMs, distilling implicit reasoning knowledge into efficient inference protocols. The principle holds substantially beyond visual modalities, with prospective applicability to audio–language and tool-conditioned systems. The method's success suggests next steps integrating on-demand VT conditioning for perceptually demanding tasks and broader adaptation to architectures like Chameleon, Emu3, and Janus-Pro.
Conclusion
Visual-OPSD demonstrates that the visual generation pathway in UMMs encodes task-relevant reasoning knowledge, dissociable from pixel-level VT artifacts and distillable into text-only inference via cross-modal on-policy self-distillation. The student achieves superior spatial reasoning performance, concise outputs, and substantial efficiency gains. The mechanism is verified via strong numerical results, careful ablation, per-token diagnostics, and rigorous theoretical analysis. Extensions to other modalities and hybrid inference strategies present promising future directions for efficient multimodal reasoning systems.