- The paper introduces Imagine-OPD, a framework that internalizes visual reasoning via on-policy self-distillation to improve fine-grained evidence extraction.
- The paper details a training method where a student model generates an imagination trace and a teacher with privileged views provides dense token-level supervision, boosting benchmark scores to over 76.
- The paper demonstrates that replacing explicit tool calls with a textual chain-of-thought yields significant efficiency gains, reducing inference times by 1.5–2.7×.
Internalizing Fine-Grained Visual Reasoning: The Imagine-OPD Paradigm
Background and Motivation
Contemporary MLLMs, such as Qwen3-VL and GPT-4o, achieve high accuracy on a range of vision-language tasks, but exhibit persistent deficits in fine-grained visual reasoning. The core challenge is that global image representations dilute small, task-critical cues amidst irrelevant background features, impeding models—especially those with limited parameter counts—from accurate localization and exploitation of decisive evidence.
The "Thinking with Images" (TWI) paradigm addresses this with explicit visual manipulations (e.g., cropping, zooming) as intermediate tool calls during reasoning. While this enables targeted inspection and improved access to localized evidence, it introduces substantial inference latency, redundant tool invocation, and potential generation of noisy or insufficient crops, especially when supervision is sparse or outcome-level.
The studied paper proposes a new approach termed "Thinking with Imagination" (TWIma). Here, visual inspection is internalized as an autoregressive textual reasoning process, obviating explicit visual tool calls at inference. Instead, the model "imagines" the result of closer inspection by indicating a region and generating a textual representation of what might be revealed under finer scrutiny, all without additional tool invocation.
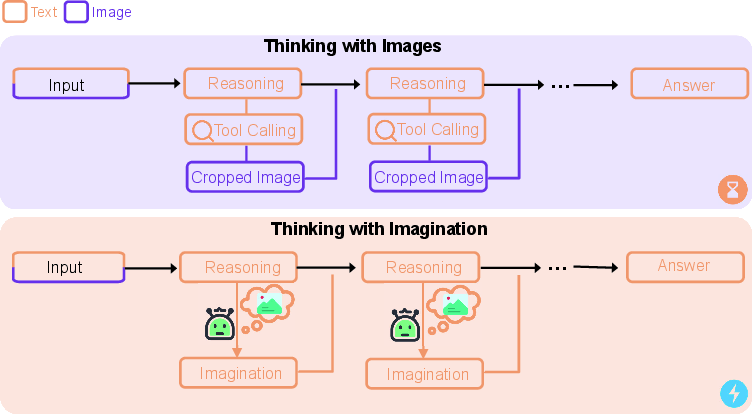
Figure 1: Comparison between explicit tool-based reasoning ("Thinking with Images") and the internalized imagination paradigm, which relies on textual representation of imagined inspection without explicit tool use.
Methodological Contributions
Imagine-OPD Framework
The central technical contribution is the Imagine-OPD (On-Policy Distillation) framework, which leverages an on-policy self-distillation protocol for end-to-end learning of the imagination-based reasoning process. Training proceeds as follows:
- A student model receives the original image-question input and generates its own stepwise imagination trace, interleaving textual reasoning with explicit imagination operations (region selection, local observation description).
- A teacher model—parameter-tied to the student and frozen—evaluates the same textual prefixes, but with access to privileged context in the form of zoomed evidence views (crops from annotated regions) and, for some variants, gold answers.
- Supervision is provided at the token level via a reverse KL divergence loss between student and teacher distributions, conditioned on the student's generated history.
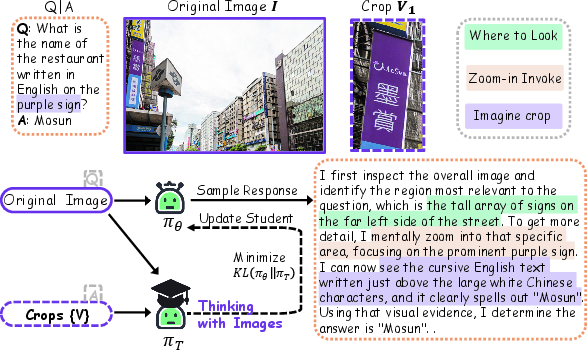
Figure 2: Imagine-OPD training: the student generates an imagination-based reasoning trace, and the fixed teacher evaluates this trace using privileged local evidence, providing dense, process-level supervision.
This approach combines the dense guidance and contextual alignment of on-policy distillation with the expressivity of textual imagination, without crafting high-quality imagination demonstrations or relying on external teacher models.
Experimental Validation
Benchmarks and Baselines
Imagine-OPD is evaluated on four vision-centric benchmarks: V*, HR-Bench-4K, HR-Bench-8K, and MME-RealWorld-Lite. It is compared to proprietary LMMs (e.g., GPT-4o, Gemini-2.5/3), open-source backbones (Qwen2.5/3-VL, Kimi-K2.5, InternVL3), and explicit tool-based reasoning approaches (Pixel-Reasoner, DeepEyes, TreeVGR-7B, Thyme).
Numerical Results
Strong quantitative claims are substantiated by the benchmark results:
- Imagine-OPD-4B improves the average benchmark score from 70.4 (Qwen3-VL-4B) to 76.7.
- Imagine-OPD-8B reaches 77.1, outperforming even 30B and 235B parameter open-source models and major commercial LMMs on average.
- Both Imagine-OPD-4B and 8B surpass all compared explicit "Thinking with Images" methods in average accuracy, while also reducing inference time by 1.5–2.7× due to single-pass inference on the original image.
- Imagination-based models outperform larger backbones and tool-augmented methods in both speed and accuracy (see Figure 3 in the paper).
Qualitative and Analytical Insights
Attention Allocation
Coverage analysis on TreeBench evaluates the fraction of attention mass that models allocate to evidence regions. Imagine-OPD demonstrably improves both accuracy and relative attention coverage versus parameter-matched baselines, confirming internalization of "where to look" as a function of the on-policy distillation objective.



Figure 3: Qualitative attention comparison. Imagine-OPD-4B intensifies attention on target evidence regions compared to the Qwen3-VL-4B baseline, leading to more grounded visual reasoning.
Ablation Findings
- Removal of privileged evidence views (retaining only answer hints) prompts a large drop in accuracy, substantiating the criticality of dense regional supervision in teacher trajectories.
- Self-proposed evidence boxes partially recover this deficit, but ground-truth annotation yields maximal gains, implicating future extension to weaker region supervision as a target for generalization.
- Attempting to use an online-updating teacher collapses training, emphasizing that stable, privileged reference teachers are essential for successful knowledge transfer in this on-policy setup.
Implications and Future Directions
Imagine-OPD operationalizes the hypothesis that explicit visual tool use is primarily valuable as an internal reasoning scaffold, and that the corresponding chain-of-thought can be fully internalized through dense, region-conditioned process-level supervision. The paradigm borrows the "local evidence amplification" of tool-augmented reasoning, but collapses the reasoning process to a single inference pass, solving efficiency bottlenecks and reducing error susceptibility to tool pipeline misalignment.
The implications for scalable, artifact-free MLLM deployment are substantial, especially for compute-constrained or real-time settings (edge devices, robotics). The methodology also highlights the broader promise of on-policy self-distillation with privileged teacher context as a scalable, annotation-efficient route to complex reasoning behaviors in LLMs and MLLMs.
Potential future directions include:
- Relaxing the reliance on ground-truth region annotation via weak supervision or unsupervised region proposal models.
- Extending imagination-based paradigms to richer visual manipulation (e.g., synthesis, counterfactual alteration, multimodal editing).
- Integrating latent-space visual imitation with interpretable textual imagination for increased model transparency and control.
Conclusion
Imagine-OPD represents a methodological advance in multimodal reasoning, demonstrating that chain-of-thoughts associated with explicit visual manipulation can be robustly internalized as imagination-based reasoning via on-policy self-distillation. This enables small- and medium-size models to attain strong fine-grained visual reasoning capacity while achieving substantial inference speed-ups, challenging the necessity of runtime tool invocation for visual evidence extraction (2606.08719).