- The paper's main contribution is introducing a gradient-free teacher guidance via prompt reformulation (BCQ and NCQ) to improve learning on hard questions.
- It leverages a prompt replay buffer to focus repeatedly on challenges within the student's zone of proximal development, enhancing knowledge distillation.
- Empirical results demonstrate consistent gains across diverse tasks and student scales, addressing the overfitting and generalization issues in traditional methods.
Zone of Proximal Policy Optimization: A Gradient-Free Approach to Teacher Guidance
Introduction and Motivation
Zone of Proximal Policy Optimization (ZPPO) (2606.18216) addresses a core deficiency in current approaches to knowledge transfer from large teacher models to smaller student models. In both vision-LLMs (VLMs) and LLMs, knowledge distillation is the standard technique for compressing teacher expertise into efficient students. However, in regimes with high student--teacher capacity gaps, logit-matching-based distillation deteriorates: the small student overfits to the teacher's sharp modes, with generalization notably impaired on tasks out-of-distribution from the training corpus. Reinforcement learning (RL)—notably via PPO and group-relative policy gradients—avoids logit imitation by optimizing directly on student rollouts, but fails on "hard" questions where no student rollout succeeds, yielding zero advantages and no learning signal. Injecting a teacher response directly into the RL gradient violates the on-policy assumption, causing policy drift.
ZPPO's central thesis is that the teacher should appear in the prompt, not the policy gradient. Inspired by Vygotsky's "zone of proximal development," ZPPO proposes that guidance be restricted to cases where the student cannot yet solve a problem unaided, but can do so with modest, prompt-based teacher support. This approach enables retention of full on-policy training at the response level, even as the prompt context leverages both teacher competence and student error patterns.
Figure 1: (a) ZPPO’s motivation: logit imitation by small students is brittle; injecting teacher rollouts into on-policy RL gradients induces drift. (b) BCQ introduces a correct teacher response and a wrong student response as anonymized in-prompt candidates. (c) NCQ aggregates student failures to highlight shared error patterns.
ZPPO Architecture and Algorithmic Innovations
ZPPO introduces three synergistic components: BCQ (Binary Candidate-included Question), NCQ (Negative Candidate-included Question), and a prompt replay buffer.
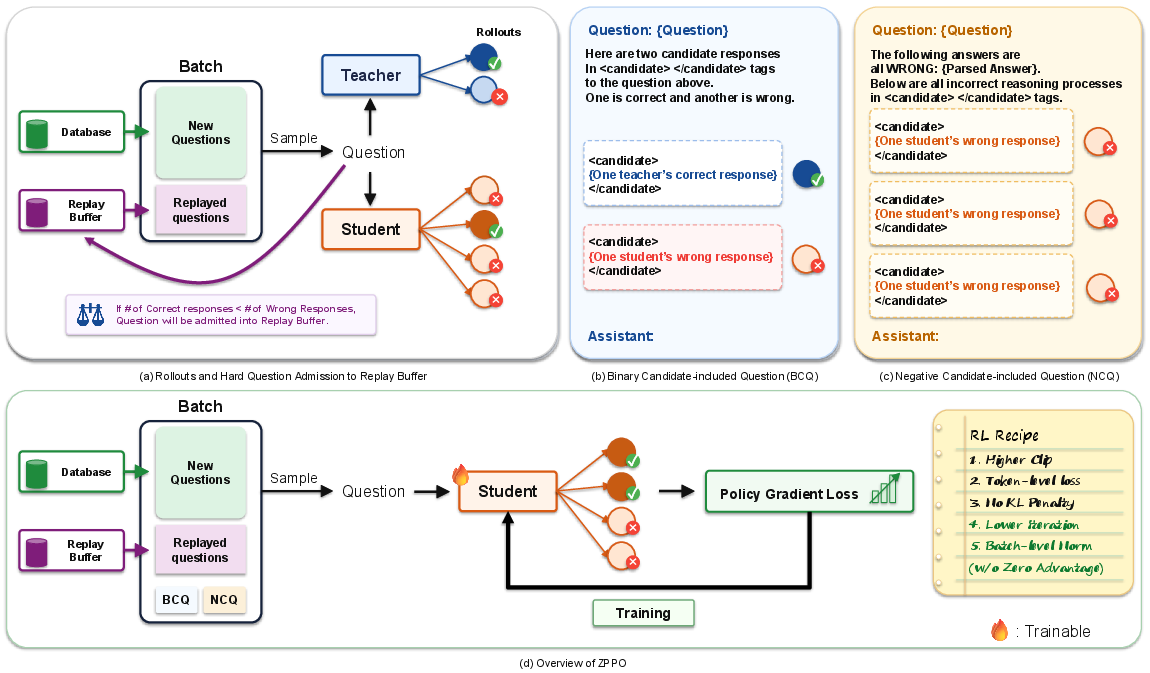
Figure 2: Overview of ZPPO’s pipeline: (a) Hard questions enter the prompt replay buffer; (b) BCQ prompts are constructed from correct teacher and wrong student responses; (c) NCQ aggregates the student’s failed rollouts; (d) All are integrated into the RL post-training batch.
When a "hard" question (mean student rollout accuracy rˉx<0.5) is encountered:
- BCQ: When the teacher has a correct response for a hard question, a BCQ prompt is synthesized by pairing this correct teacher response with a wrong student response. Both are anonymized and shuffled, and the student must discriminate which is correct based on the prompt context. Crucially, the student's response is generated by its own current policy, so all policy gradients remain purely on-policy.
- NCQ: For each hard question, all wrong student rollouts are aggregated, their errors explicitly surfaced in the prompt, and the student is asked to avoid these failure patterns and find a correct solution. Again, only student-generated responses are produced and used for gradient updates.
This reformulation means teacher responses and student failure patterns inform the learning process only through prompt augmentation, not as explicit loss targets or gradient terms.
Prompt Replay Buffer
To operationalize focus within the student's zone of proximal development, a prompt replay buffer is maintained:
Empirical Results and Analysis
Generalization and Scale
ZPPO is evaluated on Qwen3.5 backbone models with student sizes 0.8B, 2B, 4B, and 9B, distilled from a 27B teacher. Post-training is conducted on a 77K-item multimodal RL dataset, with evaluation on a rigorous 31-benchmark suite covering 16 VLM, 10 LLM, and 5 video reasoning tasks.
Main findings:
- Distillation degrades generalization on out-of-corpus tasks: Classical off- and on-policy distillation yield minimal improvements, often reducing performance on tasks such as LLM and video benchmarks that are not included in training.
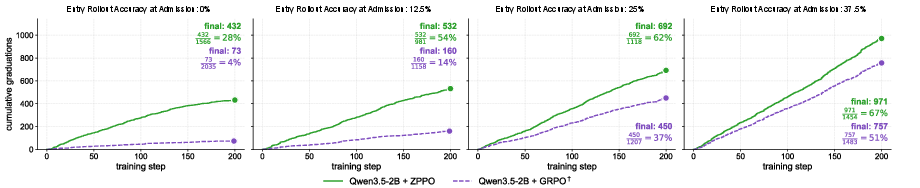
- Replay without reformulation is insufficient: Prompt replay alone (as per GRPO†) does not recover the learning signal lost on the hardest questions.
- ZPPO consistently improves generalization across student scales and all benchmark categories: For the most constrained (0.8B) student, ZPPO achieves a +9.3 percentage point (pp) gain on VLM benchmarks and a +6.8pp gain on LLM/video benchmarks over the best non-ZPPO baseline. Even at 9B, ZPPO sustains nontrivial gains.
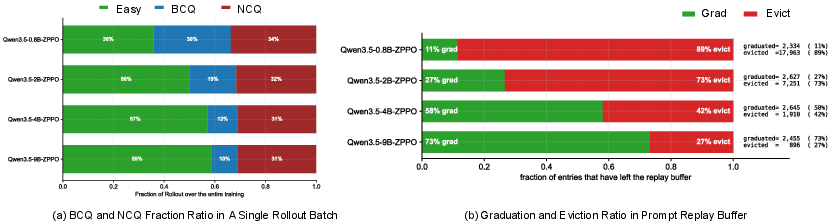
Figure 4: (a) Training batch composition illustrating the proportion of plain, BCQ, and NCQ prompts per step; (b) Ratio of prompt “graduation” versus FIFO eviction, reflecting ZPPO’s focus on hard question mastery.
Component Ablation and Mechanistic Insights
Explicit ablations elucidate the respective contributions of BCQ, NCQ, and the prompt replay buffer:
- Each component alone yields modest improvement; their combination (i.e., full ZPPO) is super-additive. In particular, replay amplifies the impact of BCQ and NCQ by re-exposing questions near the student's proximal zone with fresh candidate construction on each step.
- Scaling effects: BCQ’s contribution diminishes as student capability approaches the teacher’s, because "hard" questions increasingly cannot be solved by the teacher either (removing BCQ’s applicability), whereas NCQ's error pattern aggregation remains effective.
RL Recipe Design
ZPPO's empirical efficacy also depends on design choices unrelated to prompt reformulation:
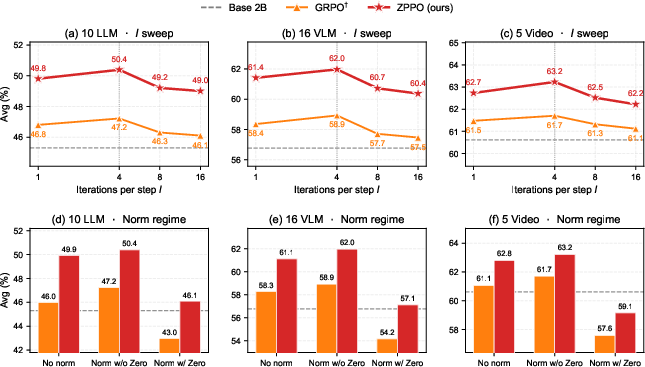
Figure 5: RL recipe ablation analyzing (a–c) number of policy gradient iterations per step and (d–f) batch-level advantage normalization choices across benchmark families.
- Four iterations per rollout step (I=4) balances policy drift and sample efficiency, outperforming higher or lower values.
- Advantage normalization, excluding zero-advantage groups ('Norm w/o Zero'), is critical for stable training; including zeros shrinks the batch std, artificially inflating advantage magnitudes.
Teacher Size Effects
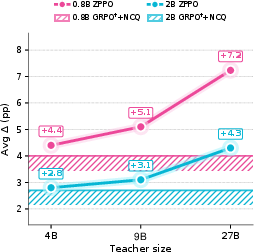
Figure 6: Average ZPPO gain (Δ, pp) as a function of teacher size across student scales.
- ZPPO’s improvement scales with the teacher/student capacity gap: When the teacher is substantially larger than the student, BCQ can be constructed for more hard questions; with small teachers or large students, BCQ’s impact collapses and only NCQ contributes.
Positioning Relative to Prior Work
ZPPO diverges from a broad body of work on knowledge distillation for LLMs and VLMs [gou2021knowledge, hinton2015distilling, sanh2019distilbert, gu2024minillm]:
- Prior methods largely match student outputs (logits, hidden states) to teacher distributions. These approaches struggle with high-capacity gaps, leading to memorization and over-sharp, un-generalizable student distributions [kim2026does, song2026survey, li2026rethinking].
- RL-based post-training pipelines (PPO, GRPO, DAPO) sidestep logit imitation but discard hard questions with all-wrong rollouts, missing precisely those examples where support is most valuable [shao2024deepseekmath, yu2025dapo].
- Recent hybrid algorithms [xu2025kdrl, xu2026rlkd] reintroduce teacher responses for hard questions, but by inserting them into the policy gradient: this maintains the drift problem.
Prompt replay, curriculum learning, and hint scaffolding enhance sample efficiency, but do not provide structural support for reasoning between correct and incorrect rationales at training time [zhan2025exgrpo, li2025staying, zhang2025stephint]. ZPPO’s BCQ/NCQ decouple teacher guidance from the gradient pathway entirely, such that all policy updates remain on-policy.
Practical and Theoretical Implications
Practical impact:
- ZPPO enables the construction of small, mobile-suitable VLMs/LLMs that are not narrow specialists but retain broad generalization, even beyond the training corpus. This is critical in resource-bound deployment scenarios—e.g., mobile, AR/VR, and robotics—where compute, memory, and power budgets are tightly constrained.
- The regime where teacher assistance is delivered only via prompts harmonizes with privacy, interpretability, and robustness requirements, since no external response distribution is forcibly injected into the optimization pathway.
Theoretical implications:
- ZPPO operationalizes a formal version of the zone of proximal development—a classic human-learning principle—within gradient-based deep learning. It raises broader questions about the optimal locus for guidance: should teacher information be in the gradient, in the prompt, in scores/rewards, or elsewhere?
- The structural limitation of ZPPO is dictated by teacher coverage: no signal is recovered on questions that neither the teacher nor current student can solve (i.e., the zone collapses to NCQ-only). Overcoming this—e.g., via synthetic teacher ensembles or curriculum-aware prompt construction—remains an open challenge.
Limitations and Future Directions
- Teacher-bounded guidance: ZPPO’s efficacy is fundamentally bounded by teacher capability; BCQ is unavailable when both teacher and student fail. Expanding the zone, potentially through synthetic or composite teachers, is a key future direction.
- Interaction with dynamic sampling: ZPPO’s focus on all-wrong samples contrasts with dynamic sampling, complicating integration. Sequential or stacked approaches may be productive.
- Scope and extensibility: ZPPO focuses solely on post-training for small VLMs/LLMs, and does not address architectural compression, robustness, or multi-phase training. It is orthogonal and potentially complementary to approaches targeting these axes [lee-etal-2024-collavo, 10.1007/978-3-031-72967-6_16, lee2025genrecal].
Conclusion
ZPPO provides a methodologically rigorous scheme for teacher-to-student competence transfer that avoids logit imitation and gradient drift, addressing the brittleness of distillation and the blind spot of policy-gradient RL for hard questions. By confining teacher guidance to the prompt, ZPPO ensures student learning remains on-policy and enables robust, broadly generalizable small models suitable for real-world, resource-constrained deployments. Extending teacher-bounded learning signals and harmonizing ZPPO with other post-training advancements constitute important avenues for future research.