Rubric-Guided Self-Distillation: Post-Training Without Rubric Verifiers
Abstract: Rubrics have emerged as an alternative to RLVR in open-ended domains where a single ground-truth final answer is not available. Existing rubric-based training methods rely on an LLM verifier that scores each rollout against rubrics. This introduces substantial training-time overhead, exposes optimization to verifier-specific biases, and reduces rubric feedback to a sparse end-of-trajectory signal. We propose Rubric-Guided Self-Distillation (RGSD), a verifier-free training method in which the base policy, conditioned on the rubric, serves as the teacher for the unconditioned student. RGSD distills the rubric-conditioned teacher distribution into the student token-by-token, replacing sparse trajectory-level rewards with dense per-token learning signals and removing the LLM judge from the training loop entirely. Across Qwen-2.5 (3B, 7B) and Qwen3-Thinking (4B, 8B) models on medical and science domains, RGSD achieves rubric satisfaction comparable to judge-based GRPO while using one on-policy rollout per prompt and no training-time verifier calls. Ablations show that raw rubrics provide a stronger teacher enrichment signal than self-generated reference responses, while a stronger GRPO judge can outperform RGSD in some settings, positioning RGSD as a complementary verifier-free alternative when verifier cost or reliability is the bottleneck.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to improve AI assistants on open‑ended tasks (like giving medical tips or explaining science) using checklists called rubrics. The new method, Rubric-Guided Self-Distillation (RGSD), skips expensive “judge” models during training and instead teaches the AI to internalize the rubric itself. The big idea: rather than grading each full answer at the end, the AI learns step by step, getting guidance at every word.
What questions does the paper ask?
- Can we train an AI to follow rubrics well without calling a separate “judge” model to grade every answer?
- Can we replace one big, end‑of‑answer grade with lots of tiny, word‑by‑word hints that are easier and cheaper to use?
- How does this new approach compare to a popular judge-based method (called GRPO) in quality, speed, and behavior (like answer length and accuracy)?
How the method works (in simple terms)
Think of two copies of the same AI:
- The teacher sees both the question and the rubric (the checklist of what a good answer should include).
- The student only sees the question (no rubric).
Training goes like this:
- The student writes an answer one word (really, “token”: tiny pieces of text) at a time.
- At each step, the teacher “whispers” how likely each next word should be, using the rubric as guidance.
- The student adjusts to match the teacher’s suggestions at every step.
Why this helps:
- It’s like getting feedback on every sentence as you write, not just a final grade at the end.
- It avoids calling a separate judge model for every answer, which is slow and costly.
- Over time, the student “internalizes” the rubric, so it follows the checklist even when it can’t see it.
Key terms in everyday language:
- Rubric: a weighted checklist describing what a good answer should do (cover facts, be clear, avoid making things up, etc.).
- Rollout: a sampled answer the AI writes during training.
- Per-token guidance: feedback at each small step (word/token) instead of a single end grade.
- Distillation: the student learns to behave like the teacher.
What’s different from the old way (GRPO)?
- GRPO asks the student to write many answers per question, then uses a judge to score them, and nudges the model using those scores. That’s like turning in multiple drafts and waiting for grades.
- RGSD writes one answer, gets step-by-step guidance from the rubric-aware teacher, and needs no judge at training time. That’s like having a tutor guiding you live.
What did they find?
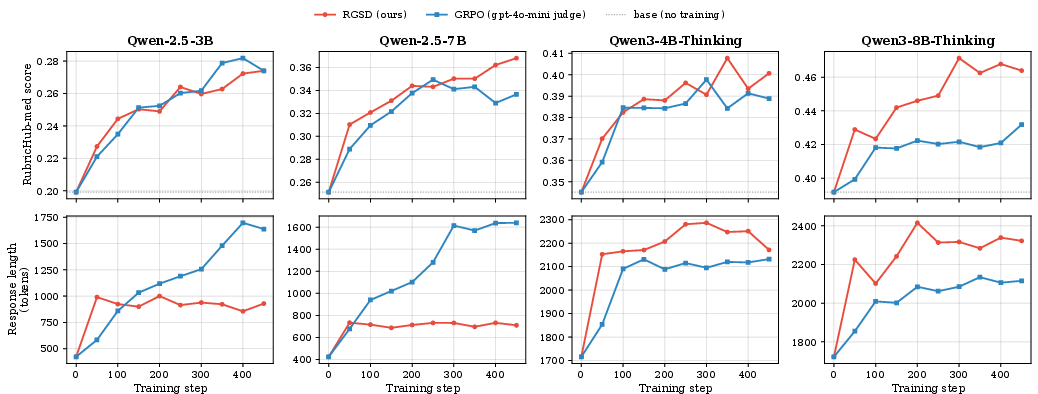
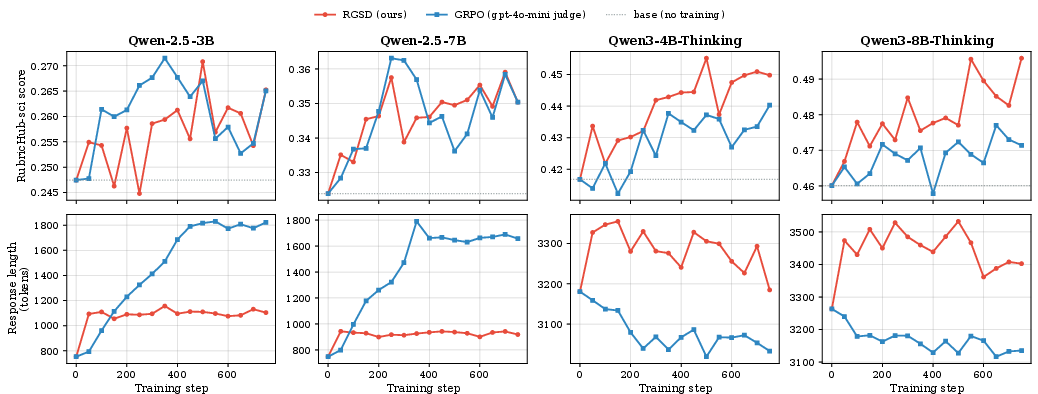
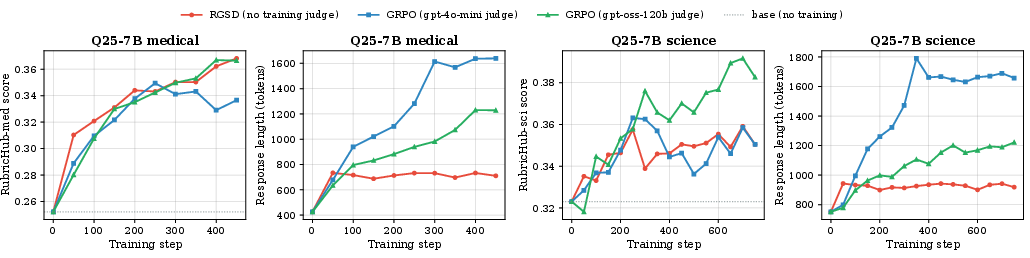
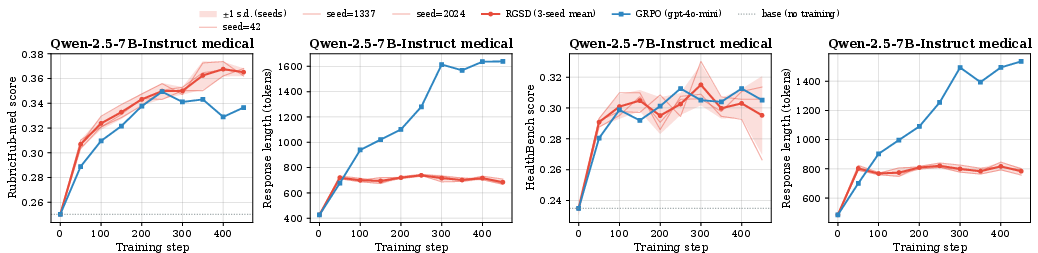
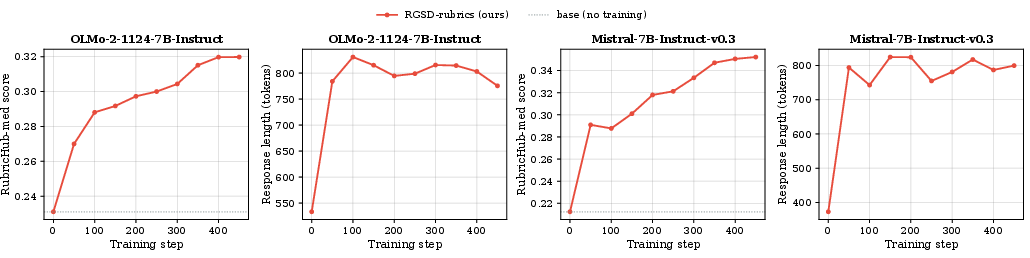
- Quality: Across four AI models and two domains (medical and science), RGSD reached about the same rubric scores as the judge-based method (GRPO). On average:
- Medical: RGSD +6.1 percentage points vs. GRPO +5.9 over the base models.
- Science: RGSD +4.9 vs. GRPO +4.5.
- In some cases GRPO did slightly better; in others RGSD did. Overall, they’re comparable.
- Cost and speed: RGSD used one answer per question and zero judge calls during training. In their setup, GRPO needed 16 answers per question and about a million+ judge calls total—much slower and more expensive.
- Answer length and truthfulness:
- With Qwen-2.5 models, GRPO answers got much longer over training, without clearly better scores.
- RGSD reached similar scores with shorter answers.
- An extra audit (LLM-based) suggested GRPO’s longer answers also contained more false claims, while RGSD increased false claims less. Shorter, focused answers can be safer.
- Why RGSD works: If you show the base model the rubric at test time, its score jumps a lot (by about 31–46 percentage points). RGSD captures a chunk of that improvement by teaching the student to act as if it “knows” the rubric, even when it doesn’t see it.
- Ablations (what-if tests):
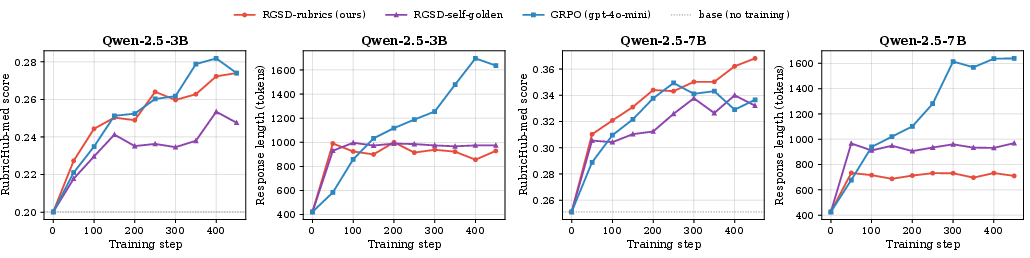
- Using the raw rubric as the teacher’s extra context worked better than using a single example “reference answer” as guidance.
- If you use a stronger, more expensive judge in GRPO training, GRPO can sometimes beat RGSD—especially in science—though it remains costlier and tends to produce longer outputs.
Why it matters
- Practical impact: RGSD gives you much of the benefit of rubric-based training without the heavy price and complexity of running a judge model for every answer. This is helpful when judge calls are expensive, slow, or unreliable.
- Safer, clearer answers: For some models, RGSD maintained or improved quality while keeping answers shorter and reducing the risk of adding extra, incorrect claims.
- Where to use which:
- Use RGSD when you want efficient training without a judge, and when your base model gets a big boost from seeing the rubric (a quick test can check this).
- Use judge-based GRPO (ideally with a strong judge) if maximizing the absolute rubric score is most important and you can afford the extra cost.
In short, this paper shows a new, judge-free training recipe that turns rubrics from end-of-essay graders into live, word-by-word guidance. It often matches the old approach while being cheaper and producing tighter, more reliable answers, making it a strong and practical alternative for training helpful AI assistants on open-ended tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of specific gaps and unresolved questions that future work could address to strengthen, stress-test, and generalize RGSD.
- External validity across domains: Evaluate RGSD beyond medical/science Q&A to multi-turn dialogue, tool-use, coding, agentic planning, and creative writing tasks where rubric criteria differ (e.g., safety, stylistic control, latency).
- Model family and scale generalization: Test on other architectures (Llama, Mistral, Gemma) and larger/smaller scales (≤1B, ≥70B) to assess scaling trends and family-specific behaviors (e.g., verbosity drift).
- Human-grounded evaluation: Replace or complement LLM-judge scoring with expert human ratings (clinical, scientific) to quantify judge-bias effects and establish external validity of rubric satisfaction gains.
- Cross-judge robustness: Systematically test transfer across multiple strong judges (frontier and open) to measure reward hacking and proxy gaps when the training signal is verifier-free but evaluation is judge-based.
- Compute accounting and efficiency: Provide full wall-clock, GPU-hours, and token-throughput comparisons vs GRPO, including the cost of teacher forwards, to substantiate efficiency claims across model sizes.
- Sensitivity to rubric quality/noise: Measure robustness when rubrics are incomplete, ambiguous, conflicting, outdated (e.g., medical guidelines), or adversarially perturbed; characterize failure modes and mitigation.
- Predictive value of the rubric-conditioning gap: Quantify how well the conditioning gap predicts downstream RGSD gains across tasks/models; derive actionable thresholds for choosing RGSD vs verifier-based RL.
- Hybrid training regimes: Explore semi-supervised variants that interleave RGSD with sparse verifier calls (e.g., occasional judge-checked rollouts) to correct drift and calibrate the student.
- Teacher quality limits: Analyze how teacher errors cap student performance; investigate co-training/EMA teachers or light teacher updates that preserve verifier-free training while improving targets.
- Distillation objective design: Ablate divergence choices (forward/reverse KL, JSD β), clipping levels, temperature scaling, and per-token weighting (e.g., rubric-criterion-aware weights) to optimize stability and quality.
- On-policy rollout exploration: Study effects of decoding temperature/top-p, single vs multiple rollouts, and scheduled sampling on coverage and learning signal diversity under RGSD.
- Length control and quality trade-offs: Introduce explicit length/conciseness regularizers or length-aware rubric criteria; test whether they reduce verbosity and false claims without hurting rubric satisfaction.
- Hallucination and factuality measurement: Replace LLM-based claim audits with human-verified or programmatically verifiable fact sets; report precision/recall of factual claims and calibration/abstention behavior.
- Safety and bias auditing: Evaluate toxicity, stereotype amplification, and unsafe advice under safety-focused rubrics; test robustness to rubrics that unintentionally incentivize risky content.
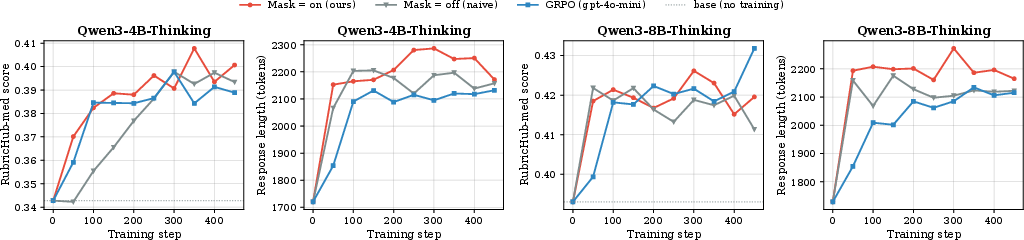
- Reasoning-trace handling: Beyond masking thinking tokens, study whether (and how) to distill reasoning structure without rubric leakage; measure effects on reasoning faithfulness and final-answer quality.
- Rubric echo and leakage: Quantify rubric references or paraphrases in student outputs (final tokens) and develop detectors/penalties to prevent rubric echo when the student lacks rubric context at inference.
- OOD rubric/criteria generalization: Test whether RGSD internalizes general principles vs specific rubric sets by introducing novel criteria or altered weights at evaluation.
- Multi-rubric and multi-objective settings: Investigate training with multiple rubrics per prompt (e.g., style, safety, correctness) and scheduling/weighting strategies for conflicting objectives.
- Data efficiency: Compare sample efficiency vs GRPO across epochs and dataset sizes; determine minimal data and rollout budgets needed for RGSD to match GRPO.
- Catastrophic forgetting: Measure retention of base-model capabilities (e.g., general knowledge, math) after RGSD and compare to GRPO; explore regularizers or multi-tasking to preserve skills.
- Diversity and mode collapse: Assess output diversity and coverage under RGSD’s per-token matching; test entropy regularization or stochastic teacher targets to prevent homogenization.
- Robustness to long/complex rubrics: Analyze context-window pressure and performance with lengthy criteria; explore rubric compression (e.g., keyphrase distillation) without losing guidance quality.
- Token-level credit shaping: Explore criterion-aware token masking/weighting to provide more targeted signals (e.g., highlight spans relevant to specific rubric items) instead of uniform per-token JSD.
- Inference-time control: Study techniques to enable optional rubric conditioning at inference (e.g., lightweight control tokens) and quantify consistency between conditioned vs unconditioned behavior.
- Theoretical grounding: Provide analysis connecting per-token distillation from rubric-conditioned teachers to improvements in expected rubric scores; characterize conditions guaranteeing improvement.
- Diagnostics beyond conditioning gap: Evaluate teacher–student top-k overlap and distributional divergence during training as early-stop or progress signals predictive of downstream gains.
- Comparison with alternative post-training: Benchmark against SFT on rubric-satisfying exemplars, DPO/preference learning with rubric-derived preferences, and OPSD variants to isolate where RGSD excels or lags.
- Integration with constraint decoding: Test whether soft distillation + hard decoding constraints (e.g., guided decoding keyed to rubric criteria) further improves satisfaction without judges.
- Continual/online settings: Assess RGSD in streaming or evolving rubric scenarios (rubrics change over time or are learned), including stability and adaptation speed.
- Reproducibility and variance: Extend multi-seed analyses across all configurations; report confidence intervals and failure cases to quantify stability under different random seeds and data shuffles.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams with access to rubric-graded data or existing SOPs/policies that can be translated into rubrics. Each item includes sector links, suggested tools/workflows, and feasibility notes.
- Cost-efficient post-training of domain assistants without verifier calls (healthcare, finance, legal, education, enterprise support, science)
- What: Replace judge-based GRPO with RGSD to fine-tune base models for open-ended tasks (e.g., clinical triage guidance, risk summaries, contract clause extraction, rubric-aligned tutoring, SOP-compliant support replies) using dense per-token distillation instead of scalar rewards.
- Tools/workflows: “NoJudgeTrain” pipeline (frozen rubric-conditioned teacher + on-policy student + clipped JSD), LoRA/PEFT adapters for quick iterations, mixed-precision inference for teacher forwards.
- Assumptions/dependencies: High-quality per-prompt rubrics; measurable rubric-conditioning gap for the base model; enough memory to run frozen teacher forwards during training.
- Rubric-conditioning gap as a go/no-go diagnostic (MLOps, model selection)
- What: Before training, forward the base model once with and without rubrics to estimate the “conditioning gap.” Use it to triage whether RGSD will likely yield meaningful gains on a given domain/dataset.
- Tools/workflows: “GapMeter” script to batch-score conditioning lift; dashboarding in Weights & Biases/Neptune.
- Assumptions/dependencies: A small rubric-graded validation slice; stable grading protocol for comparability.
- Conciseness-oriented post-training to curb verbosity drift (customer support, knowledge bases, documentation, healthcare)
- What: Prefer RGSD when GRPO induces long, claim-dense outputs without clear score gains. RGSD’s per-token supervision often reaches similar rubric satisfaction with shorter outputs.
- Tools/workflows: “LengthGuard” metric and gating; length-regularized early stopping; response-length distribution monitoring.
- Assumptions/dependencies: Same evaluation rubric across checkpoints; optional auxiliary audits for factuality if high stakes.
- Lower-risk alignment when verifiers are costly or unreliable (regulated industries, privacy-sensitive deployments)
- What: Eliminate training-time verifier calls to reduce exposure to judge biases, latency, rate limits, and privacy concerns (e.g., hospital or bank data).
- Tools/workflows: On-prem RGSD training; audit logs of rubric changes; rubric versioning in a “RubricBank.”
- Assumptions/dependencies: Rubrics encode the compliance/policy criteria faithfully; evaluation still needs a separate procedure (ideally stronger/held-out judge or human review).
- Rubric-internalization for instruction following and editorial style (marketing, technical writing, product, UX)
- What: Train models to internalize style guides, brand voice, or documentation templates as rubrics; deploy unconditioned models that adhere to those standards without runtime rubric prompts.
- Tools/workflows: “StyleRubricKit” to convert style guides into weighted criteria; batch RGSD with multi-task rubric datasets.
- Assumptions/dependencies: Clear, unambiguous style criteria; ability to avoid leaking rubric mentions in outputs.
- Classroom and LMS tutors aligned to grading rubrics (education)
- What: Encode assignment rubrics (thesis, evidence, clarity) and distill them into small/medium models for rubric-aligned tutoring and feedback generation.
- Tools/workflows: LMS integration for rubric ingestion; “TutorDistill” RGSD presets; response-length controls to prevent overlong feedback.
- Assumptions/dependencies: School/department rubrics available; data governance for student data.
- Enterprise SOP-aware support bots and agents (CX, ITSM, HR)
- What: Convert SOPs and escalation criteria into rubrics and apply RGSD so agents adhere to tone, coverage, safety, and escalation requirements.
- Tools/workflows: SOP-to-rubric converter; “ComplianceCheckpoints” with periodic RGSD refreshes as SOPs change.
- Assumptions/dependencies: SOPs are precise enough to be rubricized; periodic re-distillation when policies update.
- Safer medical and scientific helpers with claim audits (healthcare, R&D)
- What: Combine RGSD with a lightweight LLM-based claim-extraction/verification audit to detect emerging false-claim patterns as training proceeds.
- Tools/workflows: “AuditLite” pipeline (extract, deduplicate, verify claims); alerting when false-claim rate increases.
- Assumptions/dependencies: Audit is an LLM proxy—it should supplement, not replace, domain expert review in high-stakes settings.
- Practical recipe for reasoning models (software, research assistants)
- What: For “thinking” models, mask > … tokens during distillation to prevent rubric leakage; distill only final answers.
- Tools/workflows: “ThinkMask” loss hook for token masking; tokenizer-aware alignment utilities.
- Assumptions/dependencies: Correct identification of reasoning spans; stable formatting of thought tokens.
- Open-source ecosystem integration (engineering productivity)
- What: Implement RGSD trainers in TRL/HuggingFace with recipes for paired teacher/student context templates and clipped JSD loss.
- Tools/workflows: “rgsd_trainer.py” reference; config presets for Qwen-family models; unit tests that reproduce reported lifts.
- Assumptions/dependencies: License compatibility; accessible compute for teacher forward pass.
Long-Term Applications
These applications require further research, scaling, or productization—e.g., better rubric generation, hybrid reward schemes, or broader evaluation frameworks.
- Automated rubric induction and maintenance (all sectors)
- What: Learn to synthesize and version rubrics from policy corpora, SOPs, and high-scoring responses; auto-detect “missing criteria” and drift over time.
- Tools/products: “AutoRubric” (LLM + retrieval + weak supervision); rubric diffing and impact analysis.
- Assumptions/dependencies: Reliable extraction of criteria/weights; human-in-the-loop validation; governance around policy sources.
- Hybrid RGSD + verifier RL pipelines (AI training platforms)
- What: Use RGSD for most updates; selectively invoke stronger judges for “hard” prompts or to recalibrate. Or, EMA/co-training where the teacher slowly improves.
- Tools/products: “HybridAlign” scheduler that switches between RGSD and GRPO by uncertainty or gap metrics.
- Assumptions/dependencies: Cost-effective access to a stronger verifier; robust uncertainty estimates; stable teacher update rules.
- Multi-turn agents and tool-use with rubricized objectives (software, research assistants, workflow automation)
- What: Extend RGSD to agentic settings where tool-use success is partly verifiable and partly rubric-graded (e.g., completeness, safety, explanation quality).
- Tools/products: Agent frameworks with per-turn rubric states; stateful teacher conditioning on evolving rubrics.
- Assumptions/dependencies: Turn-level rubric design; partial programmatic verifiers; scalable state management.
- Compliance-first foundation models (finance, legal, healthcare)
- What: Pretrain/post-train families of models where jurisdictional policies are encoded as rubric bundles, then distilled for unconditioned compliance behavior at inference.
- Tools/products: “PolicyPacks” (jurisdiction × domain rubric sets), continuous RGSD as regulations change.
- Assumptions/dependencies: High-quality, legally vetted rubrics; auditable lineage from policy to rubric to model weights.
- Edge and on-device specialization via RGSD (mobile, healthcare edge, industrial)
- What: Run local teacher-student distillation to internalize site-specific rubrics (e.g., hospital protocols) without any external judge or data egress.
- Tools/products: Memory-efficient teacher inference; LoRA-only RGSD; streaming distillation for low-RAM devices.
- Assumptions/dependencies: Sufficient on-device compute; privacy/compliance constraints; stable local rubrics.
- Cross-modal rubric distillation (speech, vision-language, code)
- What: Generalize rubric-guided self-distillation to ASR quality criteria, VQA explanation norms, or coding standards (tests + rubric).
- Tools/products: Modality-appropriate rubric schemas; masking equivalents for hidden reasoning or intermediate artifacts.
- Assumptions/dependencies: Clear cross-modal criteria and evaluation signals; multi-modal teacher interfaces.
- Governance and standardization of rubric-based evaluation (policy, standards bodies)
- What: Establish best practices for rubric authoring, conditioning-gap diagnostics, and reporting; include rubric provenance in model cards.
- Tools/products: “RubricCard” spec; certification programs that audit rubric coverage, bias, and stability.
- Assumptions/dependencies: Community consensus; reproducible benchmarks with cross-judge validation.
- Safety and factuality portfolios beyond scalar rewards (safety research)
- What: Replace monolithic reward models with multi-criterion rubrics distilled into models; combine with post-hoc critics for claim verification and style conformance.
- Tools/products: “SafetyRubric Suites” covering refusal, harm, privacy, and bias; layered RGSD with safety-first criteria.
- Assumptions/dependencies: High-quality safety rubrics; robust red-teaming; scalable human oversight.
- Dynamic rubric-weighting and curriculum schedules (training science)
- What: Adaptively re-weight criteria during RGSD (e.g., emphasize high-signal criteria first) to accelerate convergence and improve transfer.
- Tools/products: “CurriculumRGSD” optimizer; meta-learning of criterion weights.
- Assumptions/dependencies: Reliable signals for criterion discriminativeness; stability under changing targets.
- Marketplace of rubric bundles and distillation checkpoints (ecosystem)
- What: Share standardized rubric sets and RGSD-tuned checkpoints for common domains (e.g., “Academic Writing v2,” “Customer Support Tone v1”).
- Tools/products: “RubricHub” package registry with licenses and provenance; evaluation leaderboards with cross-judge scoring.
- Assumptions/dependencies: Licensing/IP for rubrics; reproducible evaluation; community stewardship.
Notes on Feasibility and Risks
- RGSD is most effective when the base model shows a strong rubric-conditioning lift; if the lift is small, gains will be limited.
- Evaluation in the paper still relies on an LLM judge; for high-stakes domains, combine RGSD with human review and/or programmatic checks.
- Stronger judge-based GRPO can outperform RGSD in some settings. Choose RGSD when verifier cost/reliability is the bottleneck; pick GRPO with strong judges when maximizing rubric score justifies higher cost.
- For reasoning-trace models, ensure masking of thought tokens during distillation to avoid leaking rubric references into internal traces.
Glossary
- Ablation: Systematic removal or modification of components to assess their impact on performance. "Ablations show that raw rubrics provide a stronger teacher enrichment signal than self-generated reference responses, while a stronger GRPO judge can outperform RGSD in some settings"
- DAGGER: An imitation-learning algorithm (Dataset Aggregation) that iteratively collects expert corrections to improve a learner. "On-policy distillation traces back to imitation-learning work such as DAGGER"
- EMA: Exponential Moving Average; a technique to stabilize training by averaging model parameters over time. "and co-train teacher and student under EMA and trust-region regularization rather than freezing the teacher"
- Forward KL: The forward Kullback–Leibler divergence , often encouraging the student to cover the teacher’s support. "interpolating between forward KL () and reverse KL ()"
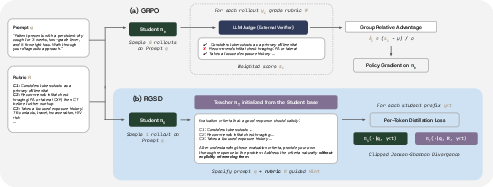
- GRPO: Group Relative Policy Optimization; an RL method that uses group-relative rewards to update policies. "GRPO uses the rubric as an external grading signal: it samples student rollouts per prompt, scores each rollout with an LLM judge, and converts the resulting scalar scores into group-relative policy-gradient updates"
- Group-relative policy-gradient updates: Policy-gradient updates computed relative to a group of rollouts rather than an absolute baseline. "group-relative policy-gradient updates"
- Jensen--Shannon divergence: A symmetric divergence between probability distributions; the paper uses a clipped variant as a distillation loss. "The student is trained with a clipped Jensen--Shannon distillation loss"
- LLM judge: A LLM used to evaluate responses against rubrics and provide reward signals. "removing the LLM judge from the training loop entirely"
- On-policy distillation: Distillation where the teacher supervises the student along trajectories generated by the student’s current policy. "introduced On-Policy Distillation, which distills a stronger teacher from the same model family into a student via a reverse-KL divergence under an on-policy student rollout"
- On-policy rollout: A trajectory sampled from the current model (student) policy during training. "We sample an on-policy rollout from the student"
- On-Policy Self-Distillation (OPSD): A distillation approach where teacher and student are the same model under different conditioning contexts. "introduce On-Policy Self-Distillation (OPSD), in which the teacher and student are the same model under different conditioning contexts"
- Privileged context: Additional information (e.g., rubrics) provided to the teacher but not the student to guide distillation. "RGSD instead uses the rubric as privileged teacher context"
- Programmatic verifier: An automatic checker that can definitively verify task outcomes (often unavailable in open-ended domains). "Structured rubrics have become a common evaluation primitive for tasks where there is no programmatic verifier"
- Proxy-reward gap: The mismatch between the training-time reward signal and the evaluation-time objective or judge. "These dynamics are consistent with a proxy-reward gap between the GRPO training judge (gpt-4o-mini) and the stronger evaluation judge (gpt-5.4)"
- Reasoning trace: The internal chain-of-thought tokens produced by reasoning models before the final answer. "the teacher's reasoning trace might subtly refer to specific rubric criteria even when the system prompt explicitly asks it not to"
- Reinforcement learning with verifiable rewards (RLVR): RL paradigm where rewards are automatically verifiable from outputs. "Reinforcement learning with verifiable rewards (RLVR) has driven much of the recent post-training progress on tasks where outcomes are automatically verifiable"
- Reward hacking: Exploiting idiosyncrasies or biases in the reward mechanism to achieve high scores without genuine improvement. "so reward hacking can persist even with capable verifiers"
- Reverse KL: The reverse Kullback–Leibler divergence , often leading to mode-seeking behavior in the student. "via a reverse-KL divergence under an on-policy student rollout"
- Rubric-conditioning gap: The performance lift when a base model is conditioned on rubrics versus not. "The +rubric lift measures the rubric-conditioning gap: the amount by which the same base model improves when given the rubric as privileged context"
- Scalar reward: A single numerical score summarizing multi-criterion evaluation, used as the RL reward. "reduces a multi-criterion assessment of a response to a single scalar reward"
- Self-distillation: Training a model to match outputs from itself under richer conditioning (here, rubric-conditioned teacher guiding an unconditioned student). "RGSD adopts On-Policy Distillation's dense per-token distillation and OPSD's self-distillation skeleton"
- Teacher distribution: The probability distribution over next tokens produced by the teacher, used as the distillation target. "matching a frozen rubric-conditioned teacher distribution"
- Trust-region regularization: A constraint on parameter updates to stay within a region where the approximation remains reliable. "under EMA and trust-region regularization rather than freezing the teacher"
Collections
Sign up for free to add this paper to one or more collections.

