- The paper introduces REVES, a novel two-stage recovery-centric framework that augments LLM revision using targeted revision and verification prompts paired with RL fine-tuning.
- The paper demonstrates significant gains on coding and math benchmarks, with improvements up to 17.6 points and state-of-the-art performance on challenging circle packing tasks.
- The paper reveals that enhancing sequential revision capabilities in LLMs transfers effectively to other test-time scaling algorithms, improving overall error correction and sample efficiency.
REVES: Recovery-Centric Data Augmentation for Test-Time Sequential Revision in LLMs
Introduction and Motivation
Modern LLMs are rarely correct on first attempt in high-complexity reasoning domains; practical deployments universally rely on iterative test-time improvement, such as sequential revision, tree search, or evolutionary strategies. However, most post-training finetuning protocols (e.g., RLHF, RLVR, GRPO) are optimized for single-shot performance, with theoretical and empirical evidence that these objectives are decoupled from effective multi-step revision policies. This paper formalizes test-time scaling (TTS) as a meta-RL problem, where the trained policy is invoked repeatedly under a TTS algorithm ϕ that orchestrates feedback-aware revision dynamics.
Crucially, the authors establish that improving sequential revision (SR) capability transfers to the entire class of revision-using TTS algorithms, including mind-evolution, MCTS, and adaptive tree search. This transfer property (Theorem~1) holds under mild coverage and monotonicity conditions and theoretically justifies focusing train-time optimization on SR. The authors prove a strong objective mismatch between single-shot and sequential-revision criteria (Theorem~2), showing that identical pass@1 policies may exhibit arbitrarily large SR performance gaps.
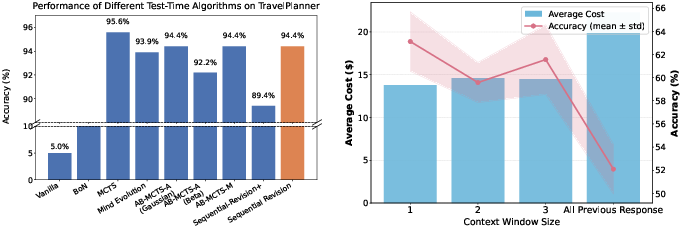
Figure 2: Sequential revision matches or surpasses Mind Evolution, MCTS, and AB-MCTS on TravelPlanner, and optimizing the Markov-revision policy yields optimal cost-accuracy tradeoff.
The REVES Framework: Theory and Algorithm
The paper introduces REVES (REvision and VErification–Augmented Training for Test-Time Scaling), a two-stage iterative protocol that performs continual, mistake-driven data augmentation specifically targeting the SR objective. The theoretical foundation centers on a hazard decomposition for the expected SR success probability, showing that the SR objective can be decomposed into a weighted sum of per-state one-step recovery probabilities (Lemma~1):
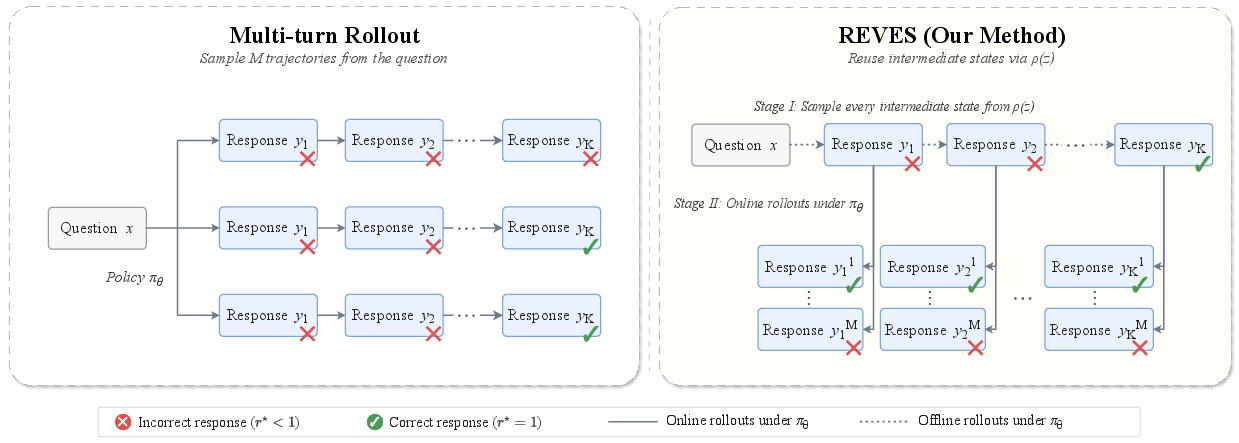
Figure 1: Schematic illustrating the hazard (per-state recovery) decomposition of the SR value; the outer trajectory provides visit weights and branches sample per-state recovery rates.
Rather than the high-variance, path-dependent credit assignment inherent to multi-turn RL, REVES explicitly converts each intermediate (near-miss) state along a successful SR trajectory into a pair of revision and verification prompts. This isolates the per-state gradient and directly upweights model capacity dedicated to local recovery and self-error-identification.
The practical REVES algorithm alternates between:
- Stage I: Data Augmentation
- Run SR under the current policy.
- For each trajectory that reaches a correct solution within budget, extract all intermediate (incorrect) states.
- For each such state, generate (a) revision prompts (asking the model to revise its previous answer with feedback) and (b) verification prompts (judging the correctness of a previous answer).
- Stage II: RL Optimization
- Train the policy via single-turn RL on the union of original and augmented prompt sets.
- The next epoch refreshes the augmentation using the improved policy.
This decoupling enables massively parallelized off-policy sample generation and eliminates long-horizon serial sampling in the inner loop, yielding favorable computational efficiency compared to naïve multi-turn RL.
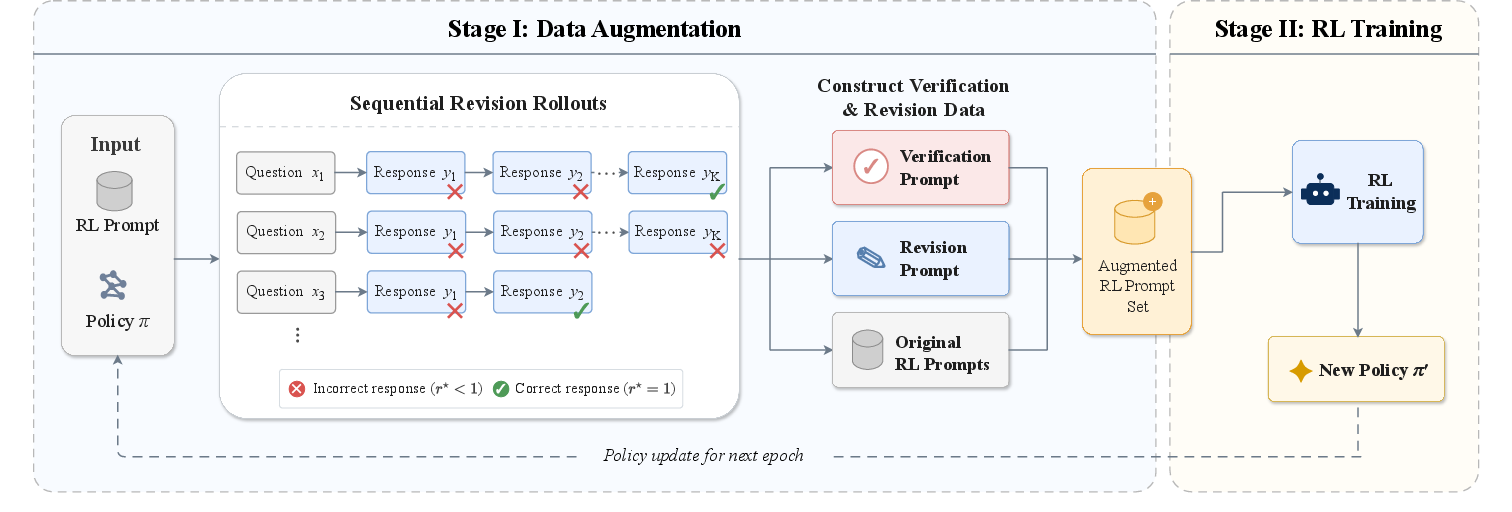
Figure 3: Overview of the REVES two-stage procedure: SR data augmentation followed by RL finetuning on the augmented prompt set.
Empirical Results
Coding and Math Benchmarks
REVES demonstrates robust, numerically prominent gains across coding (LiveCodeBench, CodeContest) and math (MATH500, AIME24/25) benchmarks. On LiveCodeBench, SR test-time scaling with a 7B model achieves +6.5 points over single-shot RL and +4.0 points over standard multi-turn RL. For mathematical reasoning, REVES yields substantial SR performance boosts—up to +14.6 and +17.6 points over the strongest single-turn and multi-turn baselines under oracle stopping.
Frontier Scientific Discovery—Circle Packing
On the notoriously difficult circle packing open benchmark (n=26), REVES matches previously reported SOTA solutions—achieving sum-of-radii $2.635983$—with the smallest base model (Qwen3-4B), and far fewer rollouts than larger evolutionary search systems (Qwen3-8B, Gemini-2.0 Pro/Flash ensemble). This demonstrates the scalability of recovery-centric training for open-ended symbolic optimization.
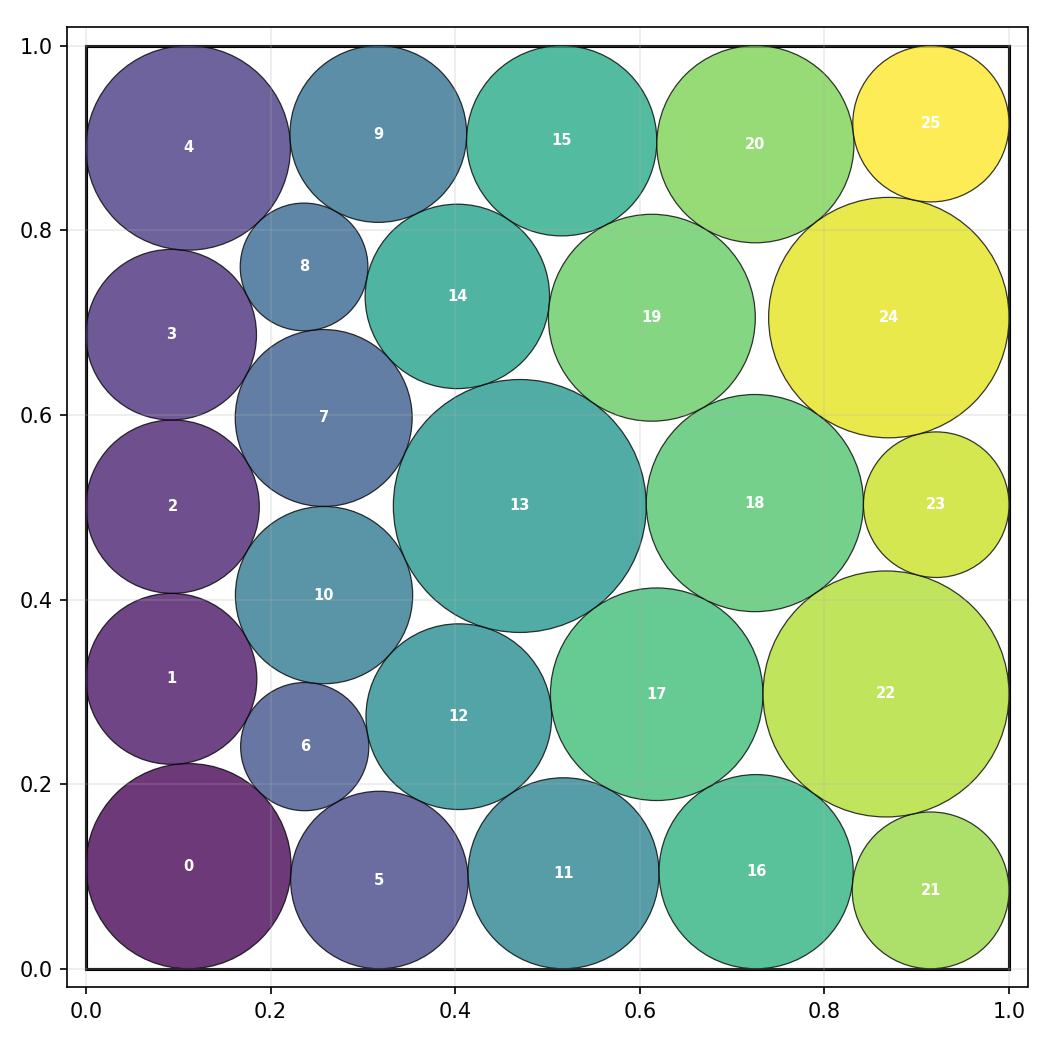
Figure 4: Circle packing solution found by REVES. The learned policy optimizes candidate placement and achieves SOTA radii sum.
Generalization: OOD Puzzles
Checkpoints trained only on math and code, when evaluated on out-of-distribution puzzles (n-queens, mini-sudoku), show strong generalization with sequential revision, outperforming comparable baselines.
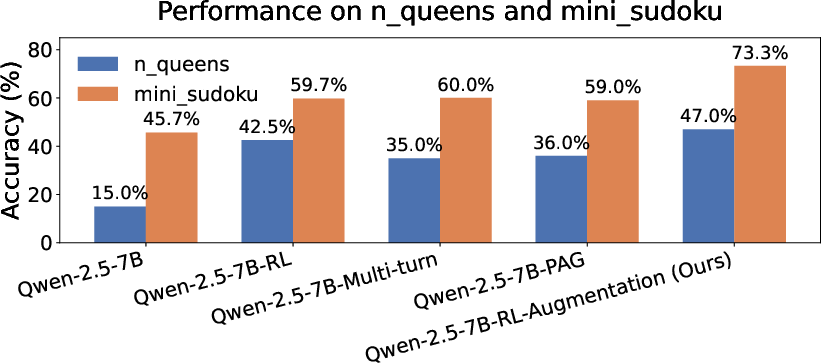
Figure 6: OOD puzzle benchmark results: REVES enhances sequential revision success even when facing unseen constraint satisfaction regimes.
Transfer to Other TTS Algorithms
REVES-trained policies increase the effectiveness not only of SR, but also MCTS, AB-MCTS, and evolutionary search methods. The empirical evidence supports the theoretical transfer bound: strengthening SR input revision performance elevates the performance ceiling for all revision-using algorithms.
Ablation and Analysis
Ablations confirm:
- Revision prompts primarily drive improved recovery capacity, while verification prompts significantly enhance confidence calibration and practical stopping (as measured by AUROC on confidence-vs.-correctness).
- Continual augmentation is essential: one-shot augmentation plateaus after initial errors are eliminated, while continual refresh aligns supervision with evolving policy weaknesses.
- Scaling augmentation budget monotonically increases sequential revision accuracy, confirming compute-vs-performance scaling law for recovery-centric data.
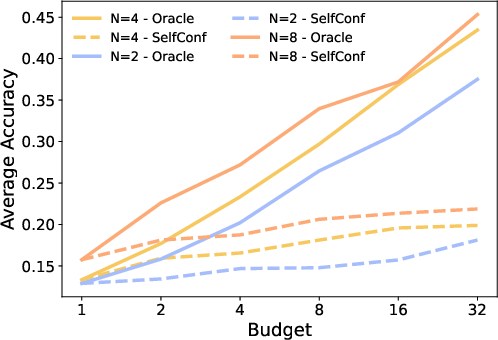
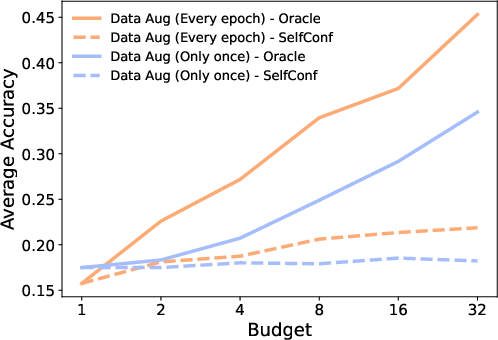
Figure 7: AIME24—accuracy as a function of augmentation budget and continual vs. one-shot augmentation.
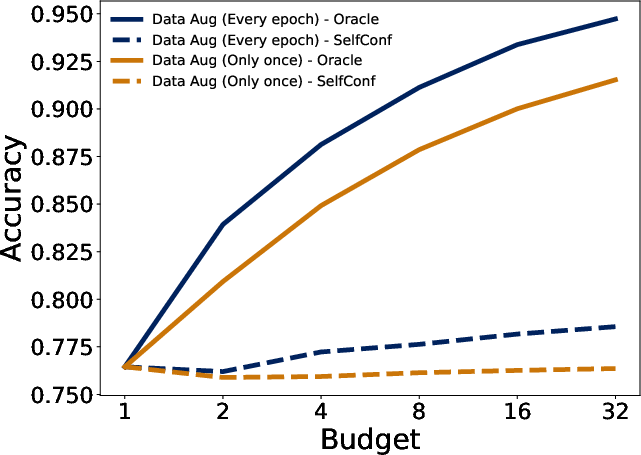
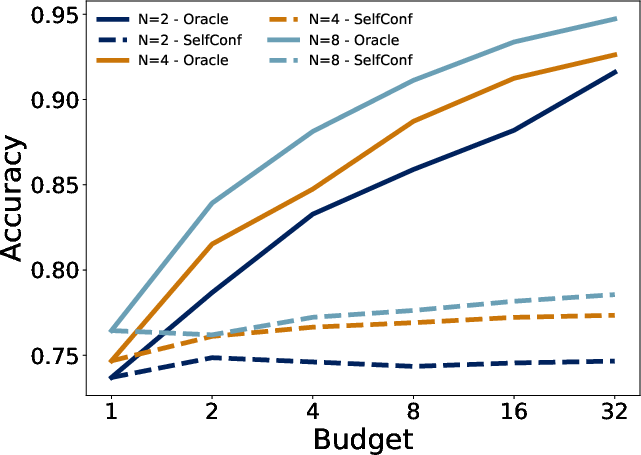
Figure 8: MATH500—impact of continual vs. one-shot augmentation, and revision budget on recovery success.
Practical and Theoretical Implications
The REVES framework establishes that standard single-shot RL objectives are fundamentally insufficient for training recovery-robust policies suitable for TTS-driven deployments. By explicitly identifying and targeting the per-state recovery probabilities central to multi-step reasoning, REVES improves both the local and global error-correction landscape.
It further demonstrates that targeted augmentation of revision and self-verification tasks can be implemented efficiently at scale, leveraging the structure of the test-time inference process, and that continual adaptation to on-policy weaknesses is required for persistent gains.
From a practical standpoint, methods like REVES directly enable smaller, compute-efficient models to approach SOTA performance on complex scientific and symbolic reasoning domains with less test-time sampling cost—bypassing the need for expensive large model deployment and extreme ensemble or search-based methods.
Conclusion
REVES pairs theoretical insights about the structure of multi-step revision objectives with efficient, recovery-focused data augmentation. The resulting models exhibit both increased test-time performance under sequential revision and improved transfer across the entire family of revision-using TTS algorithms. Empirically, this approach pushes sample efficiency and practical capability for math, code, OOD puzzles, and open scientific domains, setting a new standard for practical post-training alignment with iterative deployment dynamics.