- The paper proposes a unified framework that fuses context and relational information using a hierarchical hybrid graph index.
- The method integrates context-aware chunk retrieval with entity extraction to enable efficient multi-hop reasoning and improved factual accuracy.
- Empirical evaluations demonstrate notable gains in QA performance and scalability, highlighting the framework's adaptability to dynamic corpora.
Unified Context-Aware and Relation-Aware Graph Retrieval-Augmented Generation
Motivation and Background
Retrieval-Augmented Generation (RAG) represents a paradigm shift in leveraging LLMs by supplementing their parametric knowledge with external corpora and structured data. Existing approaches bifurcate into chunk-centric methods, which emphasize context preservation via hierarchical chunk grouping and summarization, and entity-centric (relation-aware) approaches, which construct explicit knowledge graphs from extracted entities and relations for multi-hop reasoning. However, both paradigms are fundamentally limited: chunk-centric methods lose explicit relational connectivity, rendering them suboptimal for logical inference, while entity-centric methods suffer from information loss during entity extraction, leading to degraded factual QA performance due to missing contextual details. Attempts to naïvely combine both approaches in hybrid graphs retain the separation between context and relations, resulting in incomplete knowledge fusion and failure to capture emergent semantics required by complex queries.
Hierarchical Hybrid Graph Indexing
To address this dichotomy, the proposed framework introduces a hierarchical index architecture over a hybrid graph that fuses context and relational information at multiple abstraction levels.
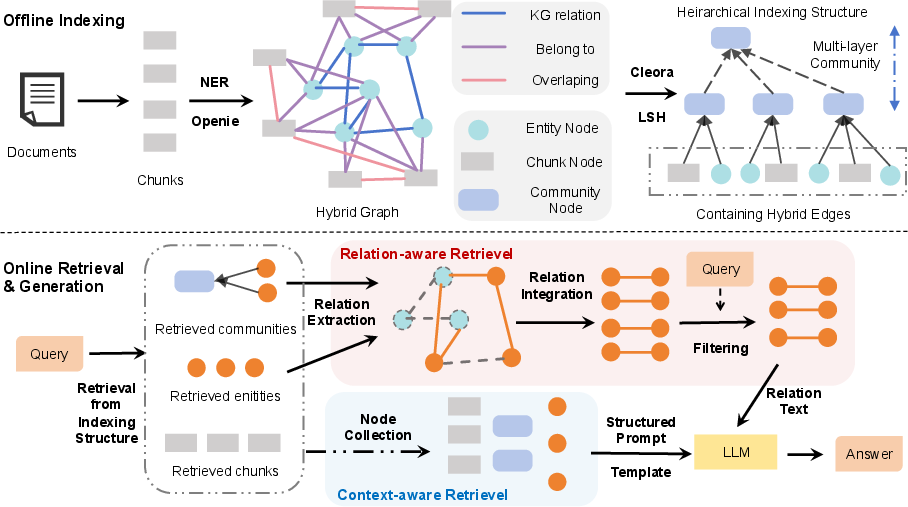
Figure 1: Overall architecture illustrating hierarchical hybrid graph index structures integrating chunk and entity nodes, multi-level clustering, and bi-level retrieval.
Hybrid Graph Construction
- Corpus is segmented into overlapping chunks, preserving granular context.
- Chunks are linked via shared entity counts, establishing semantic chunk-chunk edges.
- Entities and relations are extracted from each chunk using LLMs, forming the entity-level knowledge graph.
- Cross-layer edges connect entities to their containing chunks, producing a hybrid graph with chunk, entity, and relation nodes.
Hierarchical Indexing
Hybrid graph nodes (chunks and entities) are embedded using structure-aware methods (Cleora), then clustered via LSH across hyperplanes. Clustering buckets (communities) are recursively summarized using LLMs with structured prompts that demand simultaneous synthesis of context and relation, ensuring knowledge fusion. These summaries are re-embedded, treated as nodes in higher index layers, and the process is repeated, yielding multi-scale hierarchical abstraction encompassing leaf nodes (original chunks/entities), intermediate community summaries, and top-level semantic aggregations.
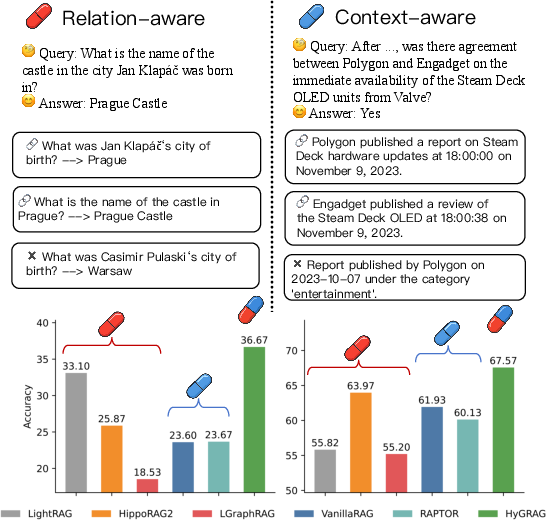
Figure 2: Method performance summary using Qwen3-8B, evidencing robust accuracy across relation-aware (MuSiQue) and context-aware (MultiHop-RAG) benchmarks, and detailed case analyses.
Bi-Level Retrieval and Efficient Generation
The retrieval strategy is fundamentally dual-stage:
- Context-aware retrieval: Similarity search across all levels (chunks, entities, community summaries) retrieves high-context and abstract nodes relevant to a query embedding.
- Relation-aware retrieval: Entities extracted from retrieved communities are expanded, and their associated triplets are filtered with embedding similarity, constructing a logically coherent set of relations for multi-hop reasoning.
The final context for LLM generation is structured as a prompt template integrating community summaries, retrieved chunks, entities, and filtered triplets. This ensures both factual grounding and logical completion.
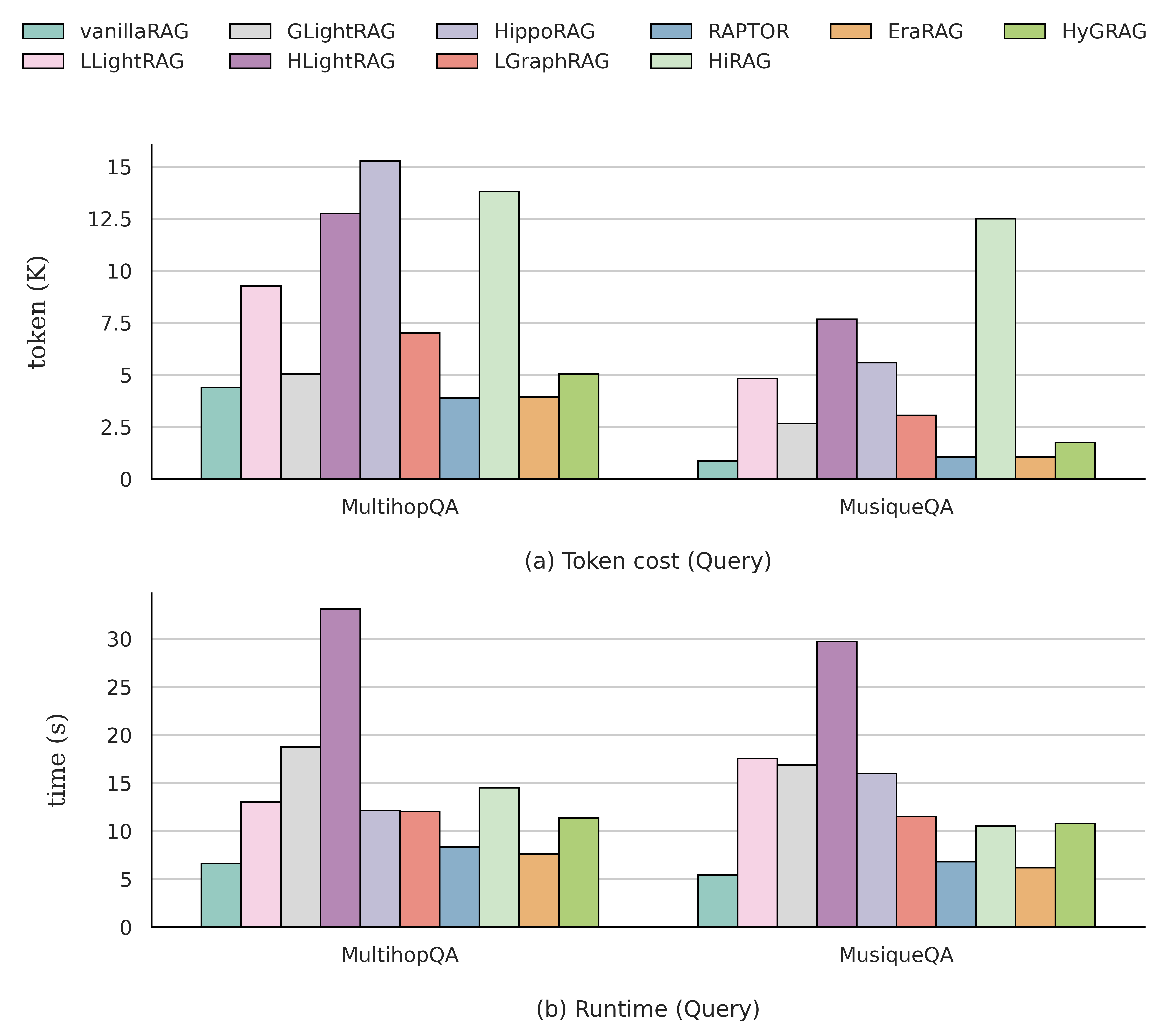
Figure 3: Query efficiency comparison, demonstrating superior retrieval speed and token usage, especially among relation-aware systems.
Dynamic Index Updates for Evolving Corpora
The hierarchical structure supports attachment-based incremental updates. New documents are segmented, entity- and relation-extracted, and summarized. Their representations are attached to the most similar communities in the index; only affected ancestors are re-summarized. This minimizes recomputation and preserves retrieval efficiency for large-scale, continually expanding datasets.
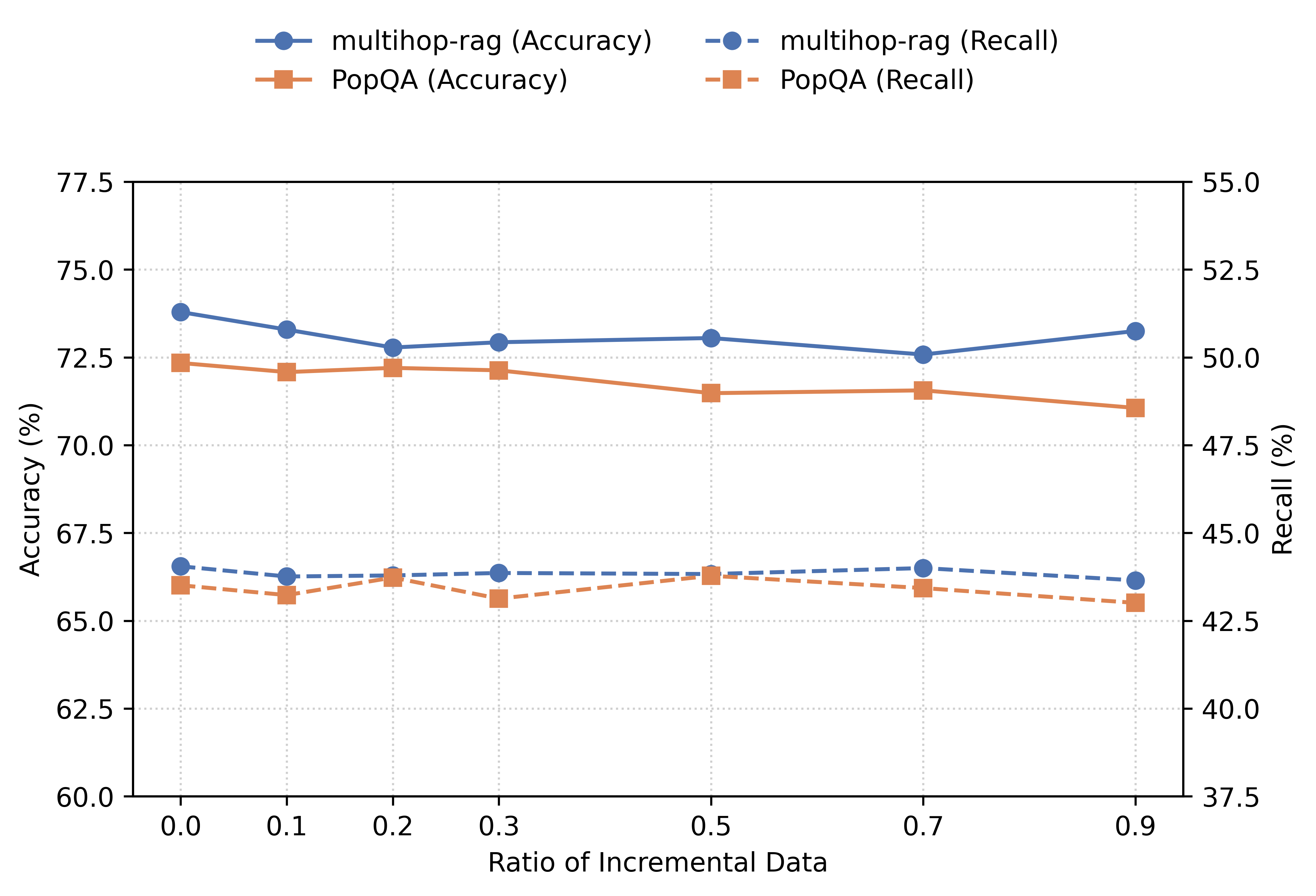
Figure 4: Corpus expansion performance, showing minimal degradation (∼1–2%) in QA accuracy and robust handling of incremental insertions.
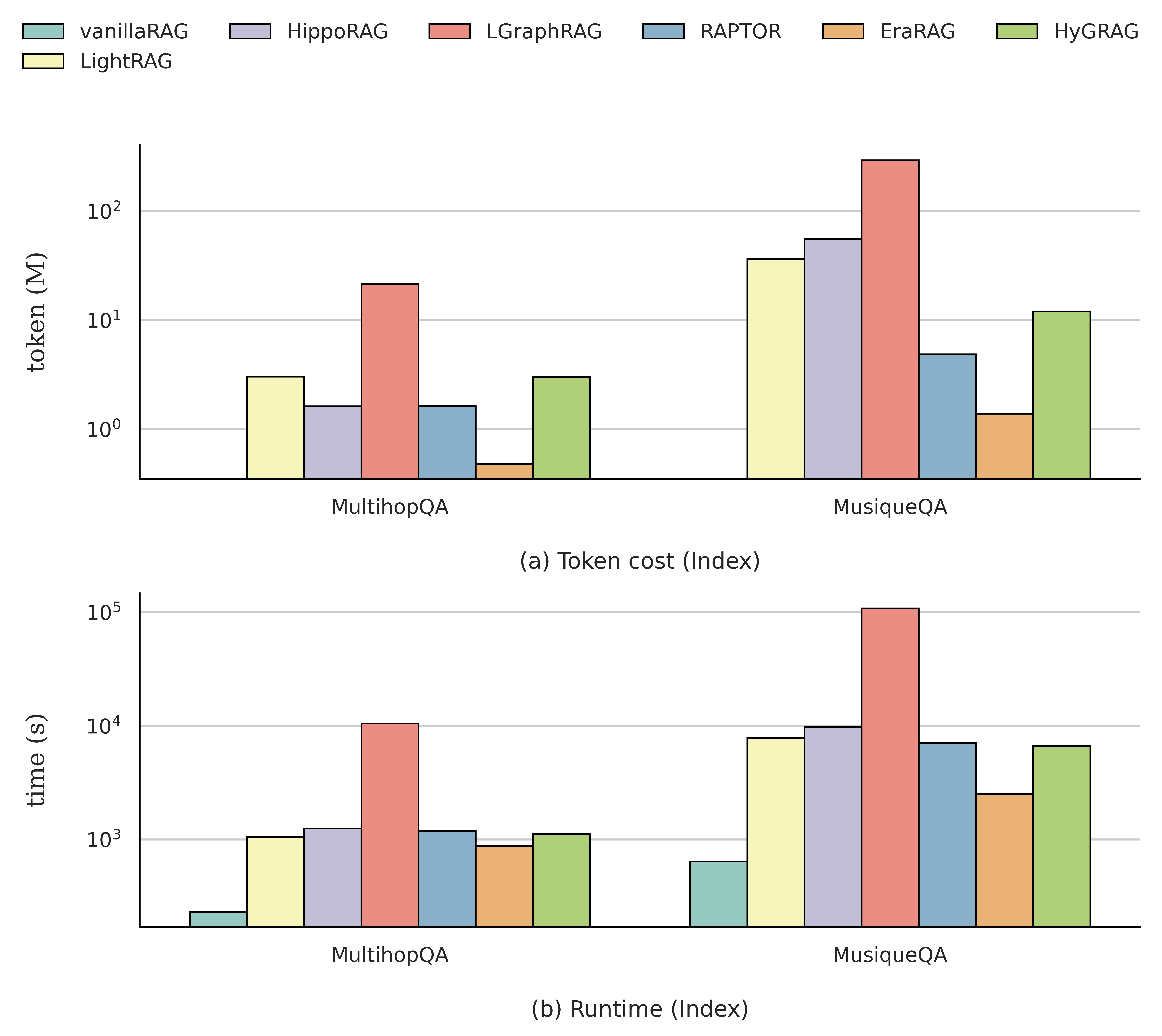
Figure 5: Corpus expansion indexing cost, evidencing practical reconstruction efficiency and competitive token consumption.
Empirical Evaluation
Static QA and Multi-Hop Reasoning
The framework consistently outperforms state-of-the-art baselines across PopQA, MuSiQue, MultiHop-RAG, HotpotQA, and QuALITY datasets. Notably:
- 6.2% gain in Factual Accuracy (PopQA)
- 9.7% gain in Multi-Hop Reasoning (MuSiQue, MultiHop-RAG)
- Up to 12.2% improvement on HotpotQA
- Maintains near-best or best Recall results, especially on entity-rich datasets
- Robust against changes in embedding models and backbone LLMs, demonstrating stability and adaptability
Ablation studies reveal that removing chunk-level structure causes the most severe performance drop, while entity/relation removal also reduces accuracy; community summaries primarily provide higher-order semantic aggregation.
Efficiency and Scalability
Both offline indexing and online retrieval are computationally efficient: hierarchical clustering is substantially faster than RAPTOR's GMM, and retrieval scales logarithmically with corpus size. The token cost of prompt construction is lower than concatenated baseline approaches, and the system maintains competitive speed and memory usage.
Qualitative Analysis and Interpretability
Case studies demonstrate superior performance in handling ambiguous or multi-hop queries, especially entity disambiguation and hidden relational inference. The framework enables LLMs to trace reasoning paths across contextual and relational axes simultaneously, yielding interpretable, evidence-grounded answers.
Implications and Future Directions
This unified framework advances retrieval-augmented LLMs by synergistically integrating context and relation-aware retrieval through hierarchical hybrid graph indexing. The approach transcends source document anchoring, enabling emergent knowledge synthesis and stable dynamic updates:
- Practical implications: robust multi-hop QA, scalable to evolving corpora, efficient memory and token use, adaptable to diverse embedding and LLM backbones
- Theoretical implications: highlights the necessity of knowledge fusion at abstraction levels beyond text or isolated entity graphs, advancing representation learning in hybrid structured-unstructured graphs
- Future work: integration with GNNs for richer hybrid representations, further reduction of LLM-induced hallucinations, and application to broader tasks (explainable reasoning, scientific QA, etc.)
Conclusion
The unified context- and relation-aware hierarchical RAG framework yields substantial improvements (up to 9.7% for multi-hop reasoning), achieving both retrieval completeness and high efficiency. Its hierarchical knowledge fusion, bi-level retrieval, and attachment-based update mechanisms enable scalable, interpretable, and robust retrieval-augmented generation, constituting a significant advancement for practical QA and dynamic knowledge-intensive tasks (2606.18075).