Beyond Domains: Reusing Web Skills via Transferable Interaction Patterns
Abstract: LLM web agents are usually deployed as tool callers: each turn, the model reads a fresh page observation and emits one structured tool action. When every action is a low-level primitive, horizons grow quickly and so do policy-facing LLM completions, dominating latency and cost on benchmarks such as Mind2Web and WebArena. Recent systems therefore wrap repeated interaction fragments as web skills: callable tools built from successful trajectories or induced programs, so one call can replace several primitives. However, prior skill libraries are still triggered mainly by instruction similarity or coarse site metadata, which yields low skill reuse on held-out sites and leaves much of the potential step and token reduction on the table. We present SkillMigrator, an agent that learns reusable web skills and transfers them across sites by matching layout structure rather than specific element references. Each induced skill is stored as a transferable interaction pattern (TIP): the skill paired with a structural sketch of the snapshot at induction time. At test time, SkillMigrator retrieves TIPs by layout similarity and grounds their references on the live page. The rest of the stack is standard: accessibility-snapshot observations with stable references, and fixed tool calling over primitives plus skill invocations. Compared with the state-of-the-art approaches, SkillMigrator reduces the average LLM-action count on successful trajectories by 8-10% across both WebArena and Mind2Web at matched success rate.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about teaching AI “web agents” to get things done on websites more quickly and cheaply. Instead of asking a LLM to decide every tiny click and type step, the authors show how to reuse bigger “skills” (like “fill out a form and click submit”) across many different websites—even across very different types of sites. Their system, called SkillMigrator, looks at how a page is structured (its layout) to find and reuse the right skill, not just the words on the page.
The main questions the paper asks
- Can we build web skills that work not only on the same website or same kind of website (like shopping sites), but across totally different sites and domains (like forums, code sites, and stores)?
- Can reusing these skills cut down the number of times we need to call the LLM (which saves time and money) without making the agent worse at finishing tasks?
- Which parts of the system matter most for making this work?
How the method works (explained simply)
Think of a web agent like a helper following a recipe online. Today, many helpers ask their coach (the LLM) before every tiny step. That’s slow and costly. SkillMigrator helps the agent reuse “recipes” it has already learned.
The key idea is to store each learned skill as a TIP—a Transferable Interaction Pattern. You can think of a TIP like a reusable recipe card:
- What it does (intent): for example, “fill a labeled form and click submit.”
- How to do it (template): the general steps, like “fill the fields, then press the submit button.”
- What pieces it needs (slots): the items to fill, like title, body, or message, along with synonyms (title/headline/subject) so it recognizes them even if they’re named differently.
- A simple map of the page structure (layout sketch): a small, text-based outline of the page’s structure when the skill was learned—like a floor plan showing there’s a form, several text boxes, and a submit button.
At run time, SkillMigrator does three things:
- Find a matching skill: It compares the live page’s structure (its “floor plan”) and the current task text to its library of TIPs. If a TIP looks like a good match (high confidence), it chooses it; otherwise, it falls back to normal step-by-step control.
- Fill in values from the user’s instruction: It figures out what values go into each slot—like putting “Great fit!” in the “title” slot—by matching the words in the user’s request (and any provided details) to the skill’s slot descriptions and synonyms.
- Bind each slot to the right page controls: It matches the slots (like “title”) to actual fields on the page (like the text box labeled “Summary”) by checking role (is it a text box?) and name similarity. Then it runs the recipe: fill the fields and click the submit button.
If anything doesn’t match well enough, it safely backs off and asks the LLM for a single next step, rather than guessing.
Why focus on layout, not just words? Different sites can use different labels for the same idea. For example, “Title,” “Subject,” or “Summary” all mean something similar. But the layout—a form with labeled text boxes and a submit button—often stays similar. Matching by layout helps the agent spot when a learned skill will work on a new site, even if the words are different.
What they found and why it matters
The authors tested SkillMigrator on two tough benchmarks with many websites and tasks (WebArena and Mind2Web). They compared it to strong systems that also reuse web skills.
Main results:
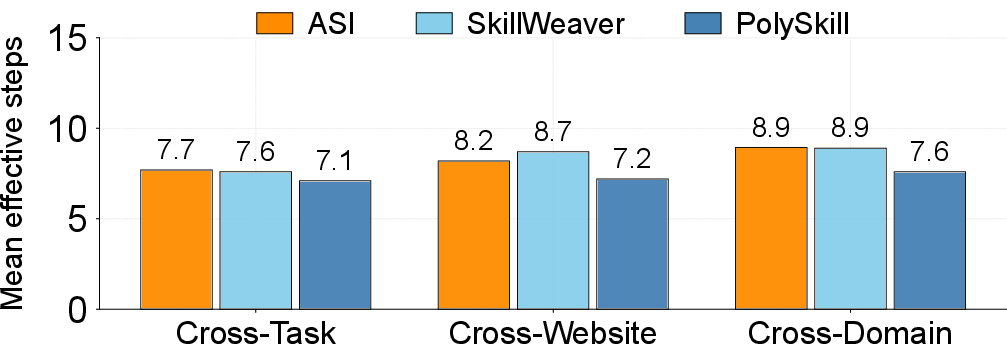
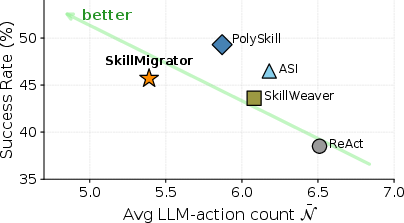
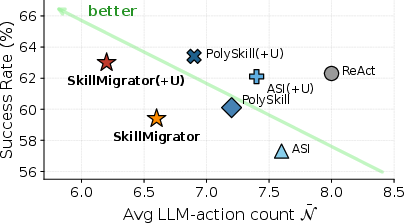
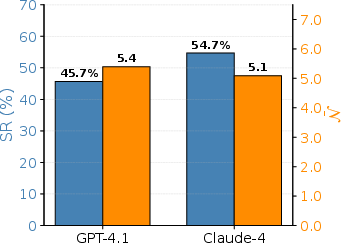
- It used fewer LLM actions per successful task—about 8–10% fewer—while keeping a similar success rate. Fewer LLM calls means lower cost and faster responses.
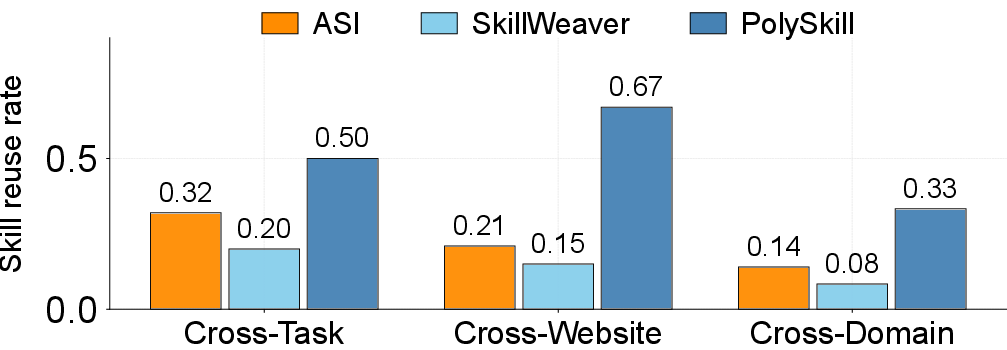
- It reused skills more often across different kinds of sites (cross-domain), not just on the same site or within the same type of site.
- It works well on its own and also stacks nicely with other skill systems: if no good layout match is found, it can hand off to another skill library or to the normal step-by-step mode.
What mattered most inside the system:
- The layout-based matching was crucial. Using only text (no layout) caused big drops in performance because pages with similar wording can behave differently.
- Having synonym lists for slots (like title/headline/subject) helped a lot when sites use different labels.
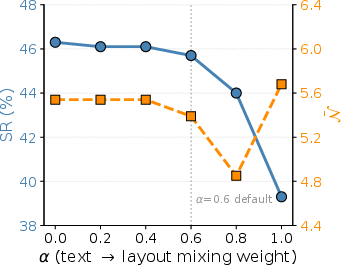
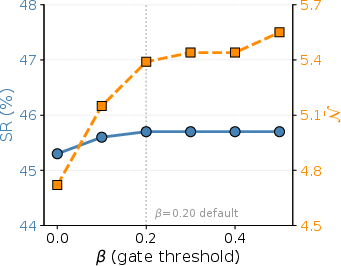
- A confidence gate (only use a skill if the match is strong enough) kept the agent from making bad guesses.
Why this is important and what it could lead to
- Faster, cheaper web automation: By cutting down repeated LLM calls, agents can complete tasks more quickly and at lower cost.
- More robust on new sites: Because it matches by structure, it can handle new websites—even in different domains—without retraining for each one.
- Plays well with others: SkillMigrator can act as a smart “retriever” on top of existing skill libraries, improving overall reuse.
In the future, this approach could help AI assistants do more complex online tasks reliably across the open web: booking trips, filling applications, managing accounts, and more—without needing to be retrained for each new site.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances cross-domain skill reuse on the web via transferable interaction patterns (TIPs). The following unresolved issues and limitations remain, each phrased to guide concrete future work:
- Reliance on accessibility snapshots only: no integration of visual/screenshot signals for sites with poor ARIA labels, canvas-based UIs, icon-only buttons, or mislabeled controls; quantify performance degradation and explore multimodal (vision + accessibility) retrieval and binding.
- Robustness to real-world DOM volatility: TIP matching assumes relatively stable tree structures; evaluate and harden against responsive layouts, A/B tests, user-specific widgets, ads, dynamically injected content, and mid-trajectory DOM mutations.
- Tree edit distance scalability: APTED on “small trees” is assumed; characterize retrieval latency and accuracy as DOM size grows, and develop scalable partial-matching or subtree indexing for large, complex pages.
- Library scaling and management: objective includes a library cost term but no concrete pruning, deduplication, or merging policy; design online compaction, versioning, conflict resolution across overlapping TIPs, and growth-control under (+Update).
- Fixed, frozen sentence encoder and linear score: investigate learned, end-to-end retrieval that jointly optimizes text–layout fusion, with trainable , learned gating , and calibration for different templates/sites.
- Template coverage and expressivity: operation templates mined by clustering may miss important patterns (e.g., pagination loops, conditional branching, multi-step navigation, wizards, drag-and-drop, file uploads, sliders, date pickers, rich text editors); extend to cover these and quantify coverage gaps.
- Slot value acquisition limits: dependence on an external planner’s instantiation dict and heuristic span extraction; assess failure modes on implicit/derived values, multi-field dependencies, transformations (e.g., unit conversions), and long-horizon cross-subtask references; add learned semantic parsers or clarification-question policies.
- Ambiguity in slot-to-control binding: Hungarian matching on embedding similarities can pick wrong fields when many are similar; incorporate structural constraints (grouping, proximity, “required” indicators), contextual cues, and multi-candidate verification before execution.
- Language and locale generalization: synonym pools and submit-button keyword lists appear English-centric; evaluate cross-lingual, mixed-locale, and right-to-left sites, and develop multilingual embeddings, locale-aware keywording, and iconography detection.
- Gating safety vs. efficiency: static threshold trades off SR and LLM-call savings; learn per-template/site adaptive gating, quantify false positive/negative rates, and add lightweight pre-execution checks to detect mismatches.
- Safety and rollback: no mechanisms to prevent or undo harmful actions (e.g., deletions, purchases, publishing); add dry-run checks, confirmation predicates, idempotence tests, or reversible execution strategies.
- Error handling and synchronization: deterministic plans lack robust waiting, retries, and recovery for asynchronous loads, transient failures, network delays, or off-screen elements; design standardized wait conditions and backoff/repair policies.
- Coverage of multi-page workflows: TIPs bind within a single snapshot; evaluate and extend to reusable patterns spanning page transitions (e.g., login + form + review), with stateful slot/element tracking across steps.
- Interaction granularity assumptions: focus on text-entry/click patterns; benchmark and extend to map interactions (panning/zooming), code editors, infinite scroll lists, table manipulations, and keyboard-driven UIs beyond Enter.
- Submit/button detection brittleness: reliance on global keyword pools and Enter; handle icon-only submits, composite buttons, shadow DOM, and custom event handlers; add event-observation feedback to confirm intended side effects.
- Poor-accessibility sites: quantify how missing/incorrect roles/names affect retrieval and binding; add fallbacks using visual text detection, DOM heuristics, or language-model-driven label inference.
- Retrieval precision across domains: layout similarity may overmatch generic forms; add negative constraints, type compatibility checks, and template-specific discriminative features to reduce spurious matches.
- Indexing and latency for large libraries: no discussion of vector + structural indices; build ANN indices for text descriptors and specialized indices for tree sketches, and report end-to-end retrieval latencies at scale.
- Evaluation breadth and external validity: experiments limited to Mind2Web/WebArena; test on live, evolving sites and additional domains (banking, healthcare, travel), including authenticated flows, CAPTCHAs, and paywalls.
- Metrics beyond LLM-action count: report wall-clock latency, token cost, memory footprint, and user-relevant success criteria (e.g., strict vs. lenient success, side-effect correctness), with statistical significance and error taxonomies.
- Negative impact analysis: quantify cases where SkillMigrator executes an incorrect skill versus safe fallback to primitives; provide safeguards or confidence diagnostics for operators.
- Composability policy: hybrid stacking with ASI/PolySkill is ad hoc; develop a learned meta-controller that routes among multiple libraries (and primitives) with uncertainty estimates and budget-awareness.
- Long-horizon credit assignment: no learning signal ties retrieval/binding choices to downstream success; explore offline logs or bandit feedback to refine retrieval, gating, and binding policies.
- Cross-device and viewport generalization: assess behavior under different screen sizes, zoom levels, and mobile UIs that alter accessibility structures and layout.
- Reproducibility and openness: clarify release of code, logs, mined templates, and TIP libraries; provide standardized evaluation harnesses to replicate results and compare future methods.
- Ethical and security considerations: analyze risks of adversarial pages crafted to trigger dangerous skills, enforce domain whitelists/blacklists, and implement permissioning/approval steps for sensitive operations.
Practical Applications
Overview
The paper introduces SkillMigrator, a web-agent method that stores and reuses reusable web skills as Transferable Interaction Patterns (TIPs). By matching layout structure (accessibility-tree skeletons) in addition to text, the agent retrieves, binds, and executes higher-level skills (e.g., “fill labelled form and submit”) across different websites and domains. In experiments on WebArena and Mind2Web, SkillMigrator reduces LLM-generated primitive actions by ~8–10% at comparable success rates and composes well with existing skill libraries.
Below are practical applications derived from these findings, organized by deployment horizon. Each item notes sectors, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed with today’s browser-automation stacks (e.g., Playwright/Selenium), accessibility-enabled sites, and existing LLM tool-calling agents.
- Cost-optimized web RPA retrieval layer
- Sectors: software, finance, e-commerce, HR, operations
- Tools/workflows: A “layout+text retrieval gate” that sits atop existing agents (e.g., ReAct, ASI, PolySkill) to trigger TIPs and cut LLM calls/latency
- Assumptions/dependencies: Access to accessibility snapshots with stable refs; websites allow automated access; library of TIPs mined from prior trajectories; gate thresholds tuned on held-out tasks
- Cross-site labelled form filler and submitter
- Sectors: government e-services, HR onboarding, customer support portals, education admissions, travel booking
- Tools/workflows: A generic “fill-and-submit” TIP for labelled textboxes + submit buttons across portals; parameterized by an instantiation dictionary (e.g., name, address, date)
- Assumptions/dependencies: ARIA-labelled inputs and buttons; login and CAPTCHA solved by separate flows; instruction parsing to values is reliable
- Multi-platform content and feedback publishing
- Sectors: marketing, e-commerce, community management
- Tools/workflows: Post announcements, create issues, submit reviews/comments across forums, shops, and trackers through a single TIP with slot synonyms (title/body/summary/comment)
- Assumptions/dependencies: Comparable interaction pattern (fill fields → submit), accessible names available; account/session handling in place
- Issue/bug/incident reporter across trackers
- Sectors: software/DevOps (GitHub/GitLab/Jira-like systems)
- Tools/workflows: TIP to “open new issue/ticket,” bind slots (title/description/type) and submit; integrates into chatops or runbooks
- Assumptions/dependencies: Consistent labels or synonyms; permissioned access
- CRM/Service desk update helper
- Sectors: contact centers, sales ops, ITSM
- Tools/workflows: TIPs for “update case,” “add note,” “change status,” reducing agent clicks/tokens; deploy as an agent copilot
- Assumptions/dependencies: CRM exposes accessible roles/names; careful governance for field binding
- E-commerce back-office automation
- Sectors: retail/e-commerce
- Tools/workflows: TIPs for “add product,” “update inventory,” “publish review moderation,” “export reports”
- Assumptions/dependencies: Admin portals with consistent labelled controls; anti-bot policies respected
- QA/regression test reuse across UI variants
- Sectors: software QA/Dev tooling
- Tools/workflows: Use TIPs to re-run core flows (e.g., create object, search and filter, checkout) across staging variants; flag if layout-distance exceeds threshold
- Assumptions/dependencies: Accessibility tree available in test builds; stable test data
- Accessibility-driven automation and audits
- Sectors: policy/compliance, public sector IT
- Tools/workflows: Because SkillMigrator relies on accessibility roles/names, it doubles as a smoke test for accessibility compliance (missing labels break TIP binding)
- Assumptions/dependencies: ARIA usage; internal policy permits automated testing
- Academic benchmarking and reproducible studies
- Sectors: academia (HCI, ML, web science)
- Tools/workflows: Cross-domain skill reuse benchmarks; ablation studies on layout-vs-text retrieval; open TIP libraries for reproducibility
- Assumptions/dependencies: Ethical data collection; benchmarks with accessible snapshots (e.g., BrowserGym/WebArena)
- Personal autopilot for repetitive web chores
- Sectors: daily life
- Tools/workflows: Browser extension that applies “form+submit,” “search+navigate,” “click-by-text” TIPs for scheduling, returns, reimbursements
- Assumptions/dependencies: User consent and credentials; site terms allow automation; CAPTCHAs handled separately
Long-Term Applications
These require further research, scaling, integration work, or ecosystem changes.
- TIP exchange standard and marketplaces
- Sectors: software ecosystem, RPA vendors
- Tools/workflows: Open TIP schema (intent, template, slot schema, tree sketch) akin to OpenAPI for web skills; marketplaces to share verified TIPs
- Assumptions/dependencies: Community adoption; security scanning and provenance to prevent malicious skills
- Deep integration with enterprise RPA/low-code suites
- Sectors: enterprise IT (UiPath, Automation Anywhere, Power Automate)
- Tools/workflows: Layout-aware skill retrieval as a built-in primitive; hybrid LLM+RPA orchestration to minimize token costs
- Assumptions/dependencies: Vendor APIs to import/export TIPs; governance for approval and monitoring
- Mobile and desktop app automation via accessibility trees
- Sectors: healthcare, finance, field operations
- Tools/workflows: Extend TIPs to iOS/Android (UIAccessibility) and desktop (WinUI, macOS AX), enabling cross-platform labelled-form and search flows
- Assumptions/dependencies: Stable accessibility APIs; app developer buy-in; input method and security constraints
- Vision-conditioned TIP retrieval for pixel-dominant UIs
- Sectors: media, design, legacy apps without ARIA
- Tools/workflows: Combine screenshots/vision models with layout sketches to handle non-accessible or canvas-heavy pages
- Assumptions/dependencies: Accurate OCR/vision grounding; higher compute budgets; robust de-duplication of visual false positives
- Autonomous, large-scale skill induction and maintenance
- Sectors: platform engineering, agentops
- Tools/workflows: Continuous mining of operation templates and synonyms; drift detection and auto-refresh of TIPs when UIs evolve
- Assumptions/dependencies: Data pipelines for collection/verification; human-in-the-loop curation for safety
- Governance, safety, and audit frameworks for web agents
- Sectors: policy/compliance, regulated industries
- Tools/workflows: Gate policies (thresholds, fallbacks), audit logs of slot bindings, allow/deny lists per site; risk scoring for skill execution
- Assumptions/dependencies: Clear organizational policies; integration with identity/access management and DLP
- Healthcare portal automations (e.g., referrals, prior auth)
- Sectors: healthcare
- Tools/workflows: TIPs for standardized forms across payer/provider portals; slot-binding with strict validation and consent
- Assumptions/dependencies: HIPAA/GDPR compliance, BAAs, anti-bot terms, robust authentication, high-precision binding to avoid harm
- Financial onboarding and KYC workflows
- Sectors: finance/fintech, insurance
- Tools/workflows: Multi-portal document upload, form entry, status checks; deterministic slot mapping with synonym pools
- Assumptions/dependencies: Compliance controls; anti-fraud and bot detection; multi-factor auth support
- Education and LMS automation
- Sectors: education
- Tools/workflows: TIPs for “create assignment,” “upload materials,” “grade release” across different LMSs
- Assumptions/dependencies: Vendor cooperation; accessibility conformity; academic integrity safeguards
- UI evolution monitoring and migration planning
- Sectors: product engineering
- Tools/workflows: Track TIP layout-similarity scores over releases to detect breaking changes; prioritize regression tests
- Assumptions/dependencies: Stable telemetry; integration with CI/CD; change thresholds calibrated per product
- General retrieval layer for tool-using agents beyond the web
- Sectors: robotics/RPA, software tools
- Tools/workflows: Apply “layout+intent” retrieval to invoke learned macros for CLI tools, IDEs, or API workflows; polymorphic reuse across tools
- Assumptions/dependencies: Comparable structural representations for non-web tools; standardized descriptors
- Government digital services at scale
- Sectors: public sector
- Tools/workflows: TIPs for benefits/tax/licensing forms across agencies; improved accessibility and automation-readiness
- Assumptions/dependencies: Policy decisions allowing automation, anti-abuse controls, standardized ARIA labeling across portals
- Agent cost-control and latency SLAs
- Sectors: agent SaaS, platforms
- Tools/workflows: Runtime budgets enforced by a TIP-first policy; automatic fallback, with SLO dashboards for token/latency savings
- Assumptions/dependencies: Reliable success-rate monitoring; robust gate tuning to avoid undue accuracy loss
Notes on feasibility across all items:
- Most gains depend on accessibility metadata (roles/names) and stable references; sites lacking these will see reduced benefits unless augmented with vision.
- Legal, ethical, and ToS constraints (e.g., CAPTCHAs, anti-bot policies) must be respected; sensitive domains (healthcare/finance) require strict governance.
- Robust instruction-to-slot parsing and synonym mining are prerequisites; failure here risks misbinding and incorrect actions.
- Skill libraries require ongoing curation; gate thresholds balance safety and savings and may vary by domain.
Glossary
- accessibility snapshot: A serialized capture of a webpage’s accessibility tree used as the agent’s observation at each timestep. "Playwright-style accessibility snapshot"
- accessibility tree: The structured hierarchy of UI elements (roles, names, states) exposed to assistive technologies and agents. "the agent-visible accessibility tree"
- action space: The set of all tool actions the agent can issue (e.g., click, fill, scroll), including skill calls. "from the action space "
- APTED: An algorithm for computing tree edit distance efficiently on ordered trees. "computed by APTED on small trees"
- ASI: A system of verified programmatic skills callable as high-level actions for web agents. "for ASI, SkillWeaver, and PolySkill"
- AWM: A textual workflow memory that logs reusable procedural knowledge for agents. "textual workflow memory (AWM"
- BrowserGym: A browser-based agent environment convention for observations and actions in web tasks. "We follow the BrowserGym and WebArena convention"
- DOM: The Document Object Model representing a page’s structure, whose specifics can hinder cross-site skill reuse. "tied to the specific interface, DOM structure, and interaction pattern"
- gate threshold (β): A scoring cutoff that decides whether to execute a retrieved skill or fall back to primitive control. "We open skill mode only if "
- Hungarian algorithm: A combinatorial optimization method used to solve assignment problems for slot-value and slot-control binding. "run a Hungarian solve"
- instantiation dict: A key–value dictionary of task-specific inputs parsed from the instruction to fill skill slots. "The planner forces each subtask to expose an instantiation dict "
- layout signal: A retrieval signal based on structural similarity between accessibility trees of pages. "The layout signal uses the live accessibility-tree structure"
- Mind2Web: A benchmark of web tasks spanning cross-task, cross-website, and cross-domain splits. "Mind2Web~\citep{deng2023mind2web} (cross-task, cross-website, cross-domain splits)"
- operation template: A parameterized plan type (e.g., search, fill-and-submit) that defines how a skill expands into primitives. " is the skill's operation template"
- Playwright: A browser automation framework whose accessibility snapshot format is used for observations. "Playwright-style accessibility snapshot"
- PolySkill: A skill framework using polymorphic cross-site abstractions to generalize across websites in a domain. "polymorphic cross-site abstractions (PolySkill"
- ReAct: A reasoning-and-acting prompting paradigm where the LLM iteratively plans and executes actions. "reasoning-and-acting paradigms such as ReAct"
- sentence encoder: A frozen embedding model that maps text to vectors for similarity-based retrieval. "Here is a frozen sentence encoder"
- skill library: A collection of reusable, callable skills that compress repeated interaction sequences. "recent web agents~\citep{wang2025inducing, zheng2025skillweaver, yu2026polyskill} are equipped with a skill library"
- SkillMigrator: A web agent that learns transferable skills and retrieves them by layout similarity for cross-domain reuse. "We propose SkillMigrator, a cost-effective web agent"
- SkillWeaver: A system that induces skill APIs from exploration for reuse as high-level actions. "self-induced skill APIs from exploration (SkillWeaver"
- slot-filling: The process of mapping task inputs to skill-defined fields, robust to paraphrases across domains. "We follow the cross-domain slot-filling view of \citet{liu2020coach,wang2021bridge}"
- slot schema: The set of named slots (with descriptors and synonyms) that a skill needs to bind before execution. " is the slot schema"
- stable element references: Consistent identifiers for page elements used to ground actions across observations. "accessibility snapshots with stable element references"
- temporally extended routine: A multi-step macro action encapsulating a recurring interaction pattern. "Each skill is a temporally extended routine"
- transferable interaction pattern (TIP): A stored skill paired with a structural sketch of its source snapshot for cross-site reuse. "Each induced skill is stored as a transferable interaction pattern (TIP): the skill paired with a structural sketch of the snapshot at induction time."
- tree edit distance (TED): A metric quantifying differences between two trees via node operations, used for layout matching. "The tree edit distance (TED) term"
- tree skeleton: A simplified, labeled accessibility-tree structure used to represent a page’s layout. "the induction-time tree skeleton~"
- WebArena: A benchmark of realistic, self-hosted web environments across multiple domains. "WebArena~\citep{zhou2024webarena} (812 executable tasks across shopping, admin, reddit, gitlab, map, multisite)"
- WebShop: An e-commerce interaction benchmark for evaluating web agents. "Recent benchmarks such as WebShop"
- WALT: A method that discovers and reuses website-specific tools for agents. "discovered website tools (WALT"
Collections
Sign up for free to add this paper to one or more collections.