- The paper introduces SGDR, a dynamic retrieval framework that selects web agent skills based on evolving page state and task goals.
- It employs sliding-window skill extraction with dual representations to create adaptable, parameterized routines for web automation.
- Empirical evaluations on WebArena demonstrate SGDR's ability to improve task success rates and decrease execution steps compared to static methods.
Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
Introduction and Motivation
The proliferation of web automation agents has intensified the demand for systems capable of handling diverse, multi-step web tasks using LLMs. Many recent approaches exploit the recurrent structure of web procedures by endowing agents with reusable "skills"—parameterized procedural knowledge mined from solving earlier tasks. However, most prior methodologies for online skill learning restrict skill invocation to a static, task-level phase: a fixed set of skills is retrieved at the start of each task, then held constant for the episode duration. This task-level reuse paradigm is suboptimal in the highly interactive context of web navigation, where the usefulness of specific skills heavily depends on the agent's current page context as much as the overarching task description.
To address this limitation, the paper introduces State-Grounded Dynamic Retrieval (SGDR), a novel framework for online skill learning that enables dynamic, stepwise skill selection grounded both in the evolving web state and the task goal. SGDR operates within a sequential-task setting where only knowledge accrued from prior executions is available; the skill library is continually updated as the agent processes new tasks. This dynamic, adaptive retrieval paves the way for substantially more effective exploitation of prior knowledge, elevating overall web agent competence in challenging, realistic settings.
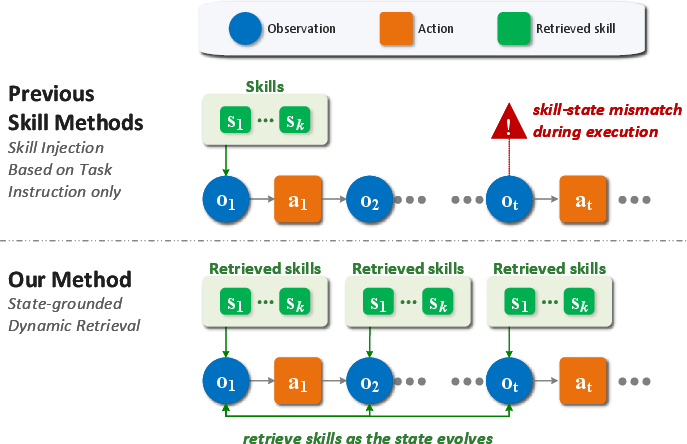
Figure 1: SGDR replaces static, task-level skill injection with step-level, state-conditioned dynamic retrieval for improved adaptability.
Methodology
SGDR operates in a lifelong, online regime: tasks are presented sequentially, and the agent can only access or induce skills from successful completions of earlier tasks. Skills—extracted as sub-trajectories—are incrementally added to a growing library that is maintained and utilized per domain to avoid cross-domain interference.
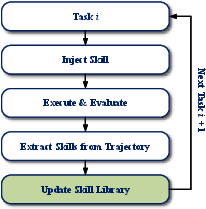
Figure 2: Agents sequentially solve tasks, update skill libraries based on evaluator-judged successful trajectories, and reuse induced skills when solving future tasks.
Sliding-Window Skill Extraction and Dual Representation
SGDR departs from prior formulations by extracting skills at an intermediate granularity. After the successful completion of a task, the trajectory is divided into overlapping segments via sliding windows of variable length (L={2,3,4,5}). Each segment is evaluated for reusability using an LLM, favoring segments callable from a single page state and parameterizing over variable arguments (e.g., element IDs or input values). Each extracted skill features a dual representation: a natural language description for retrieval, and executable code for direct invocation in the browser environment. Empirical routines manifest as succinct, parameterized Python functions paired with context-rich operational descriptions.
State-Grounded Dynamic Skill Retrieval and MMR Reranking
A defining aspect of SGDR is its retrieval process. Rather than static task-level selection, skills are dynamically retrieved at every execution step. The retrieval query is constructed by fusing (a) a task goal embedding and (b) a summarized embedding of the current web state (rendered via LLM) with a balanced relevance scoring:
scoret(sk)=αcos(ϕ(g),ϕ(dk))+(1−α)cos(ϕ(rt),ϕ(dk))
where g is the task spec, rt is the step-wise state summary, dk is the k-th skill's description, and ϕ(⋅) is an embedding function.
To prevent redundancy and encourage coverage over distinct procedures, a Maximal Marginal Relevance (MMR) reranker iteratively selects a set of diverse, relevant skills as candidates for execution at each step:
MMRt(sk)=λscoret(sk)−(1−λ)sk′∈Atmaxsim(dk,dk′)
where At is the active set of already selected skills, and sim is embedding cosine similarity.
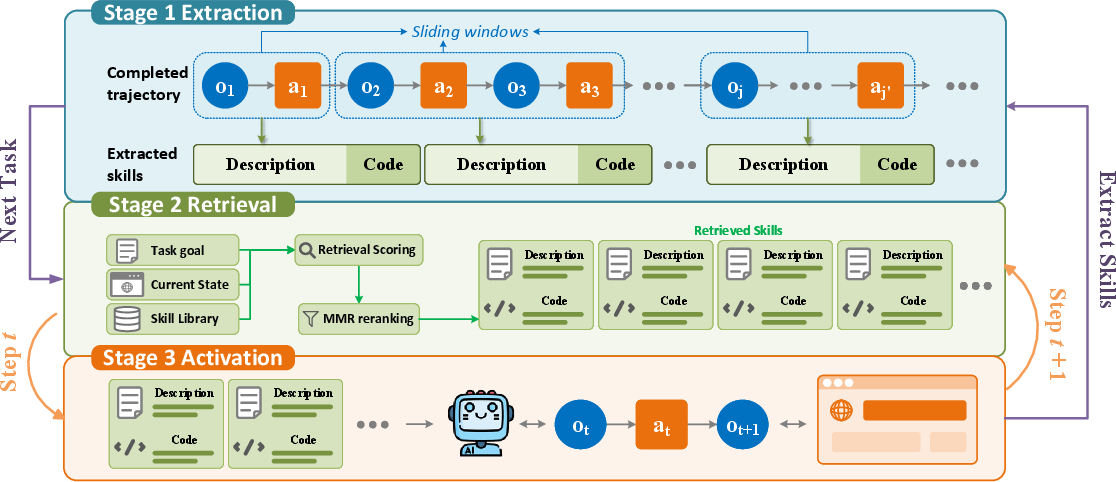
Figure 3: Completed trajectories are segmented and filtered; skills are dynamically retrieved using task and state queries, reranked for diversity with MMR, and injected for step-level decision-making.
Skill Injection and Agent Execution
At each decision point, only the dynamically identified skills are exposed to the backbone LLM for immediate consideration. This approach lets the agent adaptively surface the most relevant routines given both the immediate web state and the overall goal, streamlining execution by elevating higher-level skills as needed and eschewing irrelevant options.
Experimental Evaluation
Setup
Evaluations are conducted on WebArena, a challenging multi-domain web agent benchmark. Experiments cover five realistic domains, e.g., Shopping, Admin, Reddit, Gitlab, Map, using both GPT-4.1 and Qwen3-4B as backbone LLMs. Competing baselines include static memory methods (AWM, ASI, CER) and a skill-free variant (Vanilla). All methods operate under equivalent online constraints, with skill accumulation limited to experience preceding the current task.
Main Results and Claims
SGDR consistently outperforms all baselines on average task success rates and execution efficiency. With GPT-4.1, SGDR achieves a success rate of 37.5%, a 10.6% relative improvement over the strongest baseline (CER); with Qwen3-4B, SGDR registers a 24.3% success rate, outpacing CER by 10%. The advantage is pronounced across four of five evaluated domains, especially for tasks with strong procedural regularity. SGDR also yields a notable reduction in average step count per task, indicating its ability to leverage multi-step skill abstractions to shortcut primitive action sequences.
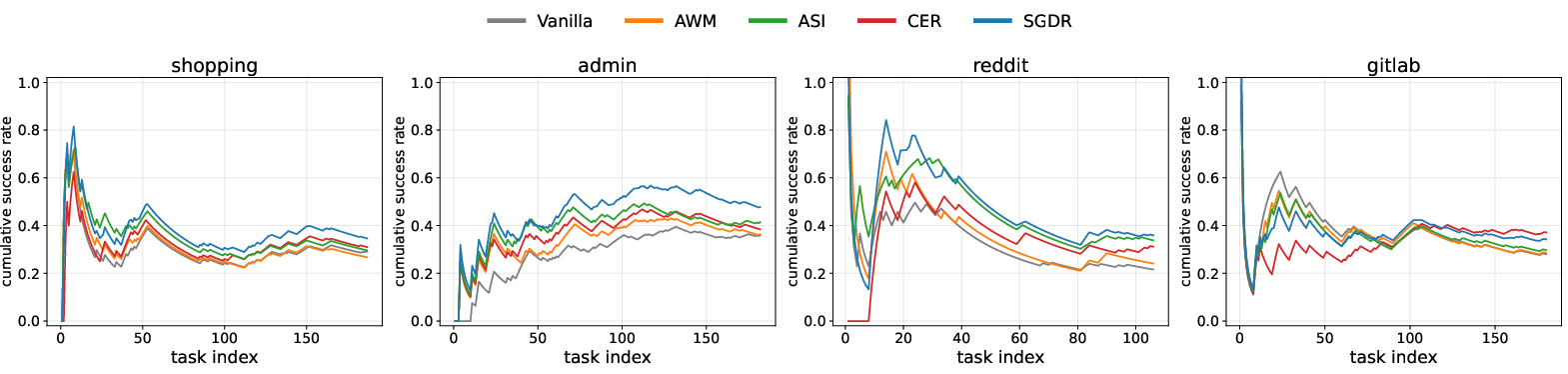
Figure 4: SGDR maintains superior cumulative success rates across task streams and domains, confirming dynamic retrieval's effectiveness.
Ablation and Analysis
Ablations demonstrate that combining both task and state information in retrieval yields higher success than either signal alone, optimal at scoret(sk)=αcos(ϕ(g),ϕ(dk))+(1−α)cos(ϕ(rt),ϕ(dk))0. MMR reranking enhances performance over top-scoret(sk)=αcos(ϕ(g),ϕ(dk))+(1−α)cos(ϕ(rt),ϕ(dk))1 relevance-only selection by reducing redundant activation. Intermediate-grained sliding window skills outperform both trajectory-level and atomic-action skills, confirming the importance of procedural granularity for adaptive reuse.
Case Studies and Qualitative Insights
Qualitative examples highlight that SGDR induces skills which abstract over element IDs and content values, yielding parameterized routines applicable to new page instances. Such skills enable the agent to perform complex web operations (e.g., submitting driving directions, posting comments, adding items to wishlists) with succinct, context-invariant routines, provided the necessary UI context is available at decision time.
Implications and Future Directions
SGDR advances the paradigm of continual web automation agents by aligning skill retrieval with the realities of highly interactive web environments. By grounding retrieval in both static task specifications and dynamically observed web states, SGDR surmounts the brittleness of prior static methods and supports genuinely adaptive reuse. These improvements are especially salient for scalable lifelong web agents operating in open-ended, realistic deployment streams.
On the theoretical side, SGDR demonstrates that non-parametric, evaluator-driven extraction and retrieval can robustly bootstrap reusable procedural abstractions, even without environment reward signals or end-to-end fine-tuning. Future explorations could integrate parametric (gradient-based) skill learning with dynamic non-parametric components, extend state summarization to richer modalities (e.g., vision for multimodal web tasks), or deploy SGDR as an interface for model fine-tuning or persistent agent personalization over time.
Conclusion
SGDR represents a robust evolution in the online learning of reusable procedural knowledge for web agents. By extracting, representing, and dynamically retrieving skills in a state-conditioned manner, it outperforms static reuse paradigms in both success rate and efficiency. Its framework enables more adaptive, generalizable web agent behavior, substantiating the need for stepwise, state-aware retrieval as digital assistants scale to more interactive and dynamic environments.