SierpinskiCam: Camera-Controlled Video Retaking with Sierpinski Triangle Pattern Cues
Abstract: Generating novel renderings of a scene along user-defined camera trajectories from a single monocular video, dubbed video retaking, is a compelling but difficult problem in content creation and visual effects. Existing geometry-guided approaches reconstruct a 4D representation from the source video and render it along the target trajectory to condition video diffusion models. However, this guidance degrades as the target camera departs from the source trajectory, leaving newly revealed regions sparse or entirely missing. We propose SierpinskiCam, which addresses this limitation by augmenting geometry-based guidance with Sierpinski dome texture cues that contains rich trackable features even under large viewpoint changes. We further introduce a reference video conditioning mechanism that appends source-video tokens to the target-token sequence and separates the two streams with negative RoPE indices, enabling appearance grounding without architectural modification or per-video adaptation. Extensive experiments show that SierpinskiCam achieves significant gains in camera controllability, geometric consistency, and video quality across diverse and challenging retaking scenarios. Project page: https://hyelinnam.github.io/SierpinskiCam/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces SierpinskiCam, an AI method that lets you “re-film” an existing video from a new camera path without changing what’s in the scene. Imagine you recorded a skateboarding trick from one angle and later wish you had filmed it from a moving drone. SierpinskiCam takes your original video and creates a new version that looks like it was captured with the new camera motion you choose.
The key questions the researchers asked
- How can we make the AI follow a user’s chosen camera path exactly, even when that path shows parts of the scene the original video never saw?
- How can we keep the look and motion of the original video (the people, objects, lighting, etc.) without mixing it up when the views don’t line up perfectly?
How SierpinskiCam works (in simple terms)
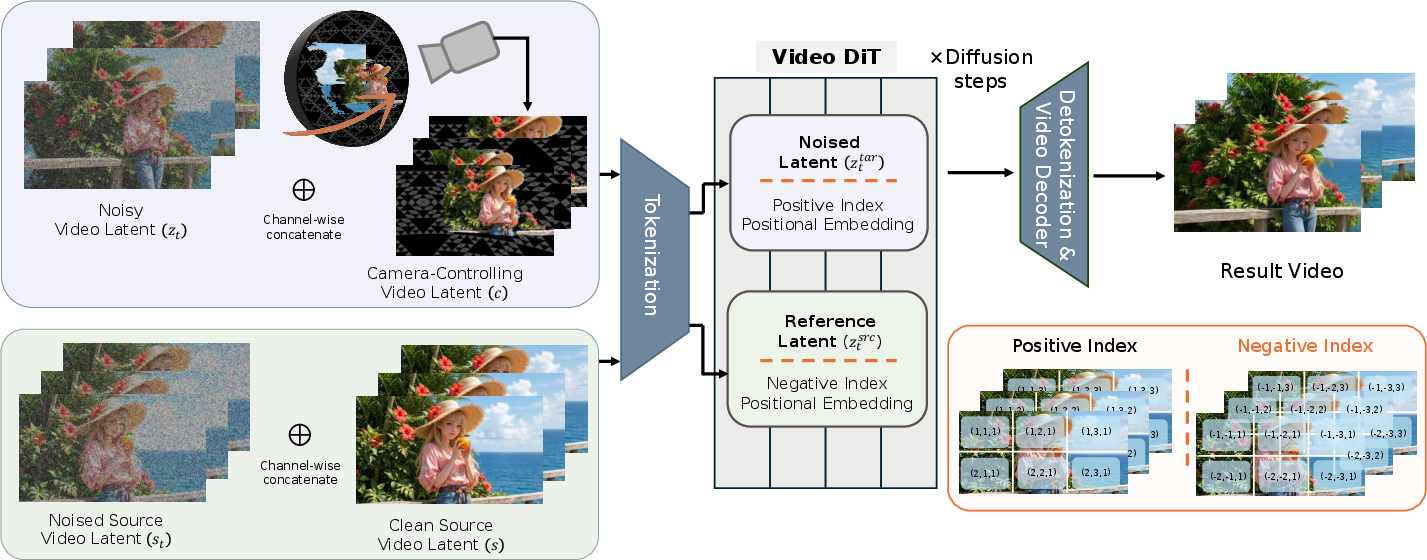
The system builds on a modern video-making AI called a video diffusion model. You can think of this type of AI as a careful artist that starts with a noisy, messy video and repeatedly cleans it up to produce a sharp, realistic video. SierpinskiCam gives this artist two helpful guides:
- A “geometric guide” that says where the original pixels should appear from the new camera angle.
- A “pattern guide” that gives the camera something to track when the geometric guide runs out.
Here are the two main tricks they use:
- A virtual dome with a Sierpinski triangle pattern for camera control
- Analogy: When you film in a room with wallpaper full of sharp shapes, it’s easy to tell how the camera moved because the pattern flows across the screen.
- Problem: When you change the camera path a lot, parts of the new view were never visible in the original video. The usual “warp” from the original frames becomes sparse (lots of black or empty areas), so the AI loses track of how the camera is supposed to move.
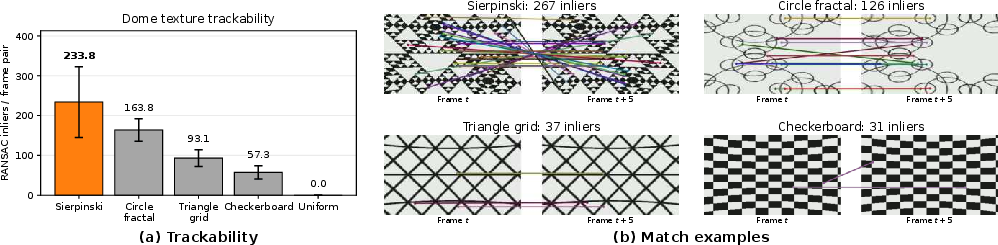
- Solution: They place a virtual spherical dome around the scene with a high-contrast Sierpinski triangle fractal pattern (a repeating triangle pattern at many sizes). This pattern is easy for the AI to “track” at both near and far distances. Wherever the original warped content is missing, the dome’s pattern fills in, giving strong clues about how the camera should move. It’s like giving the camera a reliable background grid that moves correctly with the camera, so the AI doesn’t get lost.
- NegRoPE: Keeping the original video as a reference without confusing positions
- Analogy: Imagine two groups of students sitting in two different classrooms. If both rooms number seats the same way, a teacher reading a list might confuse “Seat 12 in Room A” with “Seat 12 in Room B.” A fix is to label one room with positive seat numbers and the other with negative seat numbers so there’s no mix-up.
- In the model, video frames are broken into small “tokens” with position labels (like seat numbers) using a system called RoPE (rotary position embeddings). If the original (source) and new (target) videos share the same kind of position labels, the AI can mistakenly match them by position instead of by meaning (e.g., confusing a hand in the source with a wall in the target just because they’re both “at position (x,y)”).
- Their trick, NegRoPE, assigns the source video tokens negative position labels and the target video tokens positive labels. This cleanly separates their “coordinate systems,” so the model attends to the right content (what things look like) rather than getting tricked by matching positions.
Putting it together
- First, they estimate rough 3D information from the original video (like a depth map) and “warp” what they can to the new camera.
- Wherever the warp can’t fill in, the patterned dome supplies strong motion cues.
- The diffusion model then uses both the camera-control video (warp + dome pattern) and the source video (with NegRoPE) to generate a high-quality retake that follows your chosen camera path and keeps the scene’s look and motion.
What they found and why it matters
The researchers tested SierpinskiCam on many videos and compared it to other leading methods.
- Better camera following: It sticks to the user’s chosen camera path more accurately, especially on big viewpoint changes where other methods often drift or “hallucinate” wrong content.
- More consistent geometry: The shapes and layout of the scene stay more stable and believable over time.
- Good visual quality: The videos look clean and coherent, not just technically correct.
- People preferred it: In user studies, viewers liked SierpinskiCam’s results more than other methods, especially for accurate camera motion and stable appearance.
- The Sierpinski pattern really helps: They compared different background patterns (like checkerboards) and found the Sierpinski triangle pattern produced the strongest, most reliable tracking cues across distances.
In short, the combination of a trackable dome pattern and the NegRoPE reference trick gave the AI clearer signals, leading to better results.
Why this is useful and what could come next
- For creators and filmmakers: You can “re-shoot” a scene with different camera moves—like swoops, pans, or orbits—after the fact, saving time and enabling creative camera work that wasn’t possible during the original recording.
- For VFX and virtual production: It’s easier to match shots, explore alternatives, or fix mistakes without reshooting.
- Plug-in potential: The Sierpinski dome cue can help other camera-control systems too, not just this one.
Limitations and future directions
- The method still depends on estimating some 3D information from the original video and on the strength of the video generation model. If the original video is very complicated or the 3D estimates are poor, results can degrade.
- As 3D estimation and generative video models improve, SierpinskiCam’s results should get even better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Domain generalization: The model is trained primarily on synthetic MultiCamVideo and static RealEstate10K subsets; robustness on diverse, real-world dynamic scenes (handheld footage, outdoor lighting, clutter, low light, fast motion) is not systematically evaluated.
- Dependence on 4D proxy quality: Sensitivity to errors in monocular depth, camera estimation, and sparse track quality is not quantified; failure modes under severe non-rigid motion, occlusions, and depth bias remain unclear.
- Camera-pose evaluation reliability: Camera controllability on DAVIS relies on post-hoc tracking (VGGT) of generated videos without ground-truth poses; the accuracy, failure rates, and bias of this evaluation protocol are not validated (e.g., against controlled captures with known GT or fiducials).
- Extreme trajectory shifts: Performance under very large baselines, full 360° orbits, extreme roll/pitch, and trajectories with rapid accelerations/jerk is not isolated and analyzed.
- Intrinsics control: How to condition and faithfully follow changes in camera intrinsics (FOV/zoom, lens distortion, rolling shutter) is not addressed; the method assumes fixed intrinsics in practice.
- Long-horizon and high-resolution scaling: Stability and controllability beyond 49 frames and at higher resolutions (e.g., 1080p/4K) are not studied; memory/latency implications of token concatenation at scale are unreported.
- Computational cost: The inference-time and training-time overheads from token concatenation and additional controls (e.g., point tracks, dome rendering) are not measured or optimized.
- NegRoPE generality: The approach is validated on DiT with RoPE; applicability to architectures with different positional schemes (e.g., ALiBi, learned 2D PE, hybrid CNN–Transformer models) and to other VDM backbones is untested.
- NegRoPE theory and behavior: A deeper analysis of why negative indices reduce spurious positional correlations (beyond the conjugacy observation), and when they might hinder beneficial cross-attention, is missing.
- Alternative source-injection designs: A controlled, apples-to-apples comparison with specialized reference-attention modules (e.g., TrajectoryCrafter’s Ref-DiT) under the same backbone and training budget is absent.
- Multi-reference conditioning: How to handle multiple source videos (different views, times, or modalities) and resolve conflicts/consistency across them is not explored.
- Reference-free mode: The paper notes training with samples “without a reference,” but does not evaluate performance when no source video is provided at inference (camera-only retaking).
- Sierpinski dome parameterization: Sensitivity to dome radius, placement relative to proxy geometry, texture tiling (16×16 grid), recursion depth, color/contrast, and sphere vs. other surfaces is not reported; automatic calibration is absent.
- Pattern leakage: The frequency and severity of Sierpinski pattern leakage into generated content (e.g., ghost textures, unintended edges, interference with fine details) are not measured; mitigation strategies (pattern dropout, masking schedules, learned gating) are not studied.
- Texture design space: Only hand-crafted patterns are tested; learned or optimized textures (e.g., differentiable texture search targeting controllability vs. leakage), blue-noise/aperiodic patterns, or content-adaptive/dynamic textures are unexplored.
- Interaction with scene materials: Effects on scenes with glass, mirrors, water, and highly reflective/transparent surfaces (where dome cues could incorrectly appear as reflections/refractions) are not analyzed.
- Occlusion/disocclusion handling: The binary warp mask and hard compositing of dome cues do not account for uncertainty in proxy visibility; probabilistic masks or learned blending of 3D vs. texture cues are not investigated.
- Complementarity scheduling: How to adaptively weight or schedule 3D proxy vs. dome cues over time (e.g., early vs. late denoising steps, view-dependent sparsity) is not explored; fixed compositing may be suboptimal.
- Robustness to content-pattern interference: Potential confusion when real scenes contain strong, high-contrast fractal/periodic patterns similar to the dome texture is not discussed.
- Dynamic and non-rigid subjects: The method’s ability to disentangle camera motion from complex object motion (articulation, crowds, deforming cloth) beyond DAVIS-like cases lacks targeted stress tests and metrics.
- Lighting and exposure control: Control or preservation of exposure, white balance, motion blur, and lighting changes along the retake trajectory is not modeled.
- Data efficiency and fine-tuning needs: How much LoRA data/training is required, and whether performance transfers zero-shot without per-backbone fine-tuning, remain unclear.
- Safety and failure characterization: Comprehensive qualitative failure analysis (e.g., when dome dominates, when proxy fails, when NegRoPE under-attends) and corresponding quantitative diagnostics are missing.
- Cross-task applicability: Extension to related tasks (multi-view video synthesis, 360° video retiming, stereo retaking, VR/AR capture pipelines) is hinted but not empirically validated.
- Reproducibility details: Precise hyperparameters for dome rendering (anti-aliasing, gamma, color palette), pattern generation seeds, and their effects on results are not fully specified, limiting replicability and ablation breadth.
Practical Applications
Immediate Applications
Below are actionable, sector-linked uses that can be deployed now with available video diffusion backbones and standard GPUs.
- Film/TV and VFX: camera retakes from single shots
- Add virtual dolly, crane, orbit, or push-in/out moves to existing footage without reshoots; generate alternative framings for directors’ cut or preview.
- Tools/workflow: “Camera Retake” effect in Adobe After Effects/DaVinci/NUKE; input a clip and a path, output a retaken sequence.
- Assumptions/dependencies: quality depth/track estimation (e.g., DepthAnything-V3, SpaTracker-V2); access to a DiT video model (e.g., Wan) and GPUs; rights to alter footage; acceptance of plausible completion in unseen regions.
- Social media and creator tools: reframing and stylized camera moves
- Convert landscape videos to vertical with dynamic punch-ins, pans, and orbits that preserve original scene motion; generate B-roll from one take.
- Tools/products: mobile “Retake” filter in TikTok/CapCut/Instagram Reels; batch conversion in YouTube Shorts workflows.
- Assumptions/dependencies: on-device/offline GPU or cloud API; user-provided camera paths or presets; content disclosure guidelines.
- Advertising and e-commerce: product-shot re-angles
- Produce alternate angles/trajectories for unboxing or product demos from a single capture to A/B test creatives.
- Tools/workflow: plug-in for creative suites with trajectory presets (spin, glide, reveal).
- Assumptions/dependencies: acceptable visual plausibility of unseen surfaces; brand/legal sign-off.
- Virtual production (previz and postviz)
- Rapidly explore candidate camera paths on captured plates; generate on-set previews when reshooting is costly.
- Tools/workflow: integrate into previs tools; path-authoring UI exporting to SierpinskiCam backend.
- Assumptions/dependencies: offline execution; human supervision for artifact triage.
- Game and XR content authoring
- Re-direct cutscenes or trailers to alternate camera moves; create parallax-friendly clips for 3DoF+ displays or lightweight 6DoF illusions.
- Tools/products: DCC plug-ins (Unreal/Unity tool that exports a clip and imports a retaken video).
- Assumptions/dependencies: tolerance for generative completion; consistent art style grounding.
- Education (film and media studies)
- Demonstrate how different camera trajectories change storytelling using a single classroom clip.
- Tools/workflow: lesson plan with “same scene, different camera” examples; path library (dolly-in, truck-left, arc).
- Assumptions/dependencies: institutional GPUs or cloud credits; basic operator training.
- Sports and broadcast (non-officiating creative replays)
- Produce creative alternate angles for highlight packages from a single camera feed (clearly labeled as AI-retaken).
- Tools/workflow: editorial add-on that ingests replay clips and predefined paths.
- Assumptions/dependencies: not for officiating or analysis; strict labeling/watermark policies.
- Postproduction QA: camera-controllability benchmarking
- Use Sierpinski dome cues to stress-test adherence to prescribed camera paths when evaluating video generators.
- Tools/workflow: internal test harness reporting RotErr/TransErr/ATE.
- Assumptions/dependencies: pose estimation (e.g., VGGT) for evaluation.
- Research and model engineering: plug-in conditioning
- Retrofit existing explicit retake pipelines with Sierpinski dome cues to improve camera adherence; adopt NegRoPE for reference-video conditioning without new modules.
- Tools/workflow: add a textured-dome compositor and token-concat with NegRoPE to DiT backbones; LoRA fine-tuning.
- Assumptions/dependencies: backbone uses RoPE; training code access; datasets like MultiCamVideo/RealEstate10K.
- Reference-preserving video edits
- Apply appearance-preserving edits (e.g., tone, wardrobe continuity) using NegRoPE to inject a reference video while generating new camera moves.
- Tools/products: “Reference Lock” switch in video editors that appends source tokens with NegRoPE.
- Assumptions/dependencies: RoPE-based transformer; careful prompt/control balance to avoid overfitting.
- Controlled-capture and tracking: pattern design transfer
- Use Sierpinski-like fractal marker backgrounds on LED walls or green screens to improve feature tracking and solve robustness (independent of generative models).
- Tools/workflow: pattern plates/panels for on-set tracking; VFX match-move pipelines.
- Assumptions/dependencies: ability to display/print patterns; aesthetic acceptance in pre-viz or hidden plates.
- Policy and compliance: labeling and provenance
- Institute automatic watermarking/labels for “AI-retaken camera motion,” with logs of paths used.
- Tools/workflow: embed C2PA metadata and invisible watermarks at export.
- Assumptions/dependencies: organizational policy adoption; watermark robustness.
Long-Term Applications
These require further research, scaling, or productization beyond current lab conditions.
- Interactive 4D scene navigation from a single video
- Turn ordinary videos into semi-navigable scenes for VR/AR, allowing users to scrub and slightly move the viewpoint consistently.
- Tools/products: “Light VR” viewer for mobile; web players with constrained 6DoF.
- Assumptions/dependencies: stronger 4D reconstruction from monocular, robust temporal consistency, efficient inference.
- Single-camera multicam for live production
- Synthesize additional “virtual cameras” from one camera feed for dynamic broadcasts (e.g., concerts), reducing rig count.
- Tools/workflow: near-real-time inference pipeline with latency budgets; operator safety rails.
- Assumptions/dependencies: low-latency accelerators; high reliability; legal clarity on disclosure.
- Sports analytics and officiating (caution)
- Generate tactical “sky-cam” or endzone-like perspectives from field-level clips for coaching review.
- Tools/workflow: analytics dashboards with uncertainty overlays; cross-check with calibrated data.
- Assumptions/dependencies: rigorous validation against ground truth; explicit prohibition in adjudication unless certified.
- Robotics and autonomy: data augmentation
- Create controlled camera-trajectory variations from logged videos to stress-test perception stacks under different egomotions.
- Tools/workflow: egomotion augmentation library producing retaken sequences for training/validation.
- Assumptions/dependencies: careful bias management; simulators may still be superior for corner cases.
- Teleoperation and remote inspection
- Offer operators “peek” viewpoints for situational awareness by retaking live video with user-steered virtual camera paths.
- Tools/workflow: operator UI streaming a retaken view with path joysticks.
- Assumptions/dependencies: latency/compute constraints; clear uncertainty communication; risk management.
- Cultural heritage and archival media enhancement
- Produce guided “walk-around” experiences from historical footage for museum exhibits.
- Tools/products: kiosk apps with docent-curated camera paths; interactive retrospectives.
- Assumptions/dependencies: curatorial oversight; ethical display and disclosure.
- Smartphone cameras with live “post-capture” camera moves
- Capture once, choose camera motion later; phones propose cinematic paths from a single clip.
- Tools/workflow: on-device NPU acceleration; path presets and haptic previews.
- Assumptions/dependencies: efficient distillation/quantization of video DiTs; battery and thermal budgets.
- Training-time architectural methods using NegRoPE
- Generalize NegRoPE to multi-source conditioning (e.g., multi-style reference, multi-shot continuity) in video and multimodal transformers.
- Tools/workflow: extend DiT training recipes with negative index bands for each source stream.
- Assumptions/dependencies: theoretical/empirical study of attention behavior; compatibility with non-RoPE models.
- Generative cinematography assistants
- Co-pilot suggests or auto-synthesizes camera paths matching beats in an edit; retakes scenes to emphasize action or dialog.
- Tools/products: NLE assistant with beat-detection and path synthesis; search over retake candidates with ranking.
- Assumptions/dependencies: robust aesthetic scoring; user control and reversibility.
- Standards and certification for generative camera control
- Establish metrics, benchmarks, and disclosure standards for “camera-accurate” generative video used in media and public communication.
- Tools/workflow: public RotErr/TransErr/ATE leaderboards; certification schemas; C2PA extensions.
- Assumptions/dependencies: industry consortia participation; cross-vendor agreement.
- Medical and technical training visualizations (non-diagnostic)
- Retake procedural videos to show alternate angles for teaching (e.g., surgery steps, lab techniques).
- Tools/workflow: training LMS modules with instructor-defined paths and annotations.
- Assumptions/dependencies: strict non-diagnostic use; expert validation; privacy safeguards.
- E-commerce 3D-like browsing from videos
- Let shoppers rotate and glide around a product demo captured once; reduce need for multi-angle shoots.
- Tools/products: storefront widget generating controllable clips per SKU.
- Assumptions/dependencies: risk of hallucinating unseen backsides; disclosure and review flows.
- Synthetic data generation for SLAM/VIO research
- Use Sierpinski-like fractal domes in simulated environments to benchmark and train feature tracking across scales.
- Tools/workflow: dataset generators that toggle dome patterns for pose-estimator stress tests.
- Assumptions/dependencies: transferability to real-world scenes; bridging sim-to-real gaps.
Notes on feasibility and cross-cutting dependencies:
- Dependence on high-quality monocular depth and tracking; failures in textureless, reflective, or fast-motion scenes degrade results.
- Requires RoPE-based transformer backbones for NegRoPE; non-RoPE models need alternative position disentanglement.
- Compute and licensing: large DiT video models and VAE encoders/decoders; potential IP restrictions around base models and datasets.
- Ethical and legal: clear labeling, watermarks, and provenance; avoid misleading uses in news, legal evidence, or safety-critical contexts unless validated and approved.
Glossary
- 3D point cloud: A set of points in 3D space representing scene geometry, typically reconstructed from depth. Example: "dense 3D point clouds reconstructed from monocular depth"
- 3D point tracks: Temporally linked 3D points that trace features across frames to capture motion and correspondence. Example: "sparse 3D point tracks"
- 4D representation: A spatiotemporal scene model (3D over time) reconstructed from video for rendering along new views. Example: "reconstruct a 4D representation from the source video"
- 6-DoF: Six degrees of freedom describing 3D pose (3D translation and 3D rotation). Example: "such as 6-DoF parameters"
- Absolute Trajectory Error (ATE): A metric measuring overall deviation between predicted and target camera trajectories. Example: "For camera controllability, we report Rotation Error (RotErr), Translation Error (TransErr), and Absolute Trajectory Error (ATE)."
- Camera frustum: The pyramidal volume defining what the camera can see; objects can enter or leave this volume as the camera moves. Example: "leave the camera frustum"
- CLIP: A vision-language similarity metric used to assess semantic alignment of generated frames. Example: "CLIP~\cite{radford2021learning}"
- Complex conjugate: In RoPE, using a negative index yields the complex conjugate rotation of a positive index, affecting attention scores. Example: "is equal to the complex conjugate of the rotary embedding of index n."
- Cross-attention: An attention mechanism that conditions one token stream on another (e.g., reference-video features). Example: "introduces a dedicated Ref-DiT cross-attention module"
- DepthAnything-V3: A monocular depth estimation model used to build dense geometric proxies. Example: "DepthAnything-V3~\cite{lin2025depth}"
- DINO: A self-supervised visual representation used as a perceptual similarity metric. Example: "DINO~\cite{oquab2023dinov2}"
- Diffusion Transformer (DiT): A transformer architecture for diffusion models operating on tokenized latents. Example: "diffusion transformer (DiT) models"
- Dyn-MEt3R: A metric for evaluating geometric consistency in dynamic scenes. Example: "Dyn-MEt3R~\cite{park2025steerx}"
- Extrinsics: Camera pose parameters (rotation and translation) relating camera to world coordinates. Example: "extrinsics, and intrinsics"
- FID: Fréchet Inception Distance, a distribution-level metric for image/video quality. Example: "FID"
- Forward splatting: Rendering by projecting source pixels forward into the target view, often producing sparse coverage. Example: "The source pixels are then forward-splatted from the estimated source cameras to the target camera trajectory"
- Generative prior: The learned distribution in a generative model that guides plausible synthesis of content. Example: "provide a strong generative prior for realistic appearance"
- Intrinsics: Camera internal parameters (e.g., focal length, principal point) defining projection from 3D to image. Example: "extrinsics, and intrinsics"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method for large models. Example: "fine-tuned via LoRA (rank 64, lr , 100 epochs)"
- Lowe's ratio test: A criterion for robust feature matching by comparing nearest-neighbor descriptor distances. Example: "match descriptors with Lowe's ratio test"
- MEt3R: A metric for geometric consistency between frames or with input video. Example: "per-frame MEt3R~\cite{asim2025met3r}"
- Monocular depth: Depth estimated from a single camera without stereo or LiDAR. Example: "dense 3D point clouds reconstructed from monocular depth"
- NegRoPE (Negative RoPE): Assigning negative spatial RoPE indices to separate source and target positional spaces in attention. Example: "assigning them negative spatial RoPE indices (NegRoPE)"
- Patchified latent tokens: VAE latents split into fixed-size patches and tokenized for transformer processing. Example: "RoPE is applied to patchified latent tokens"
- Plücker rays: A camera-ray parameterization (Plücker coordinates) used to encode trajectories for control. Example: "such as 6-DoF parameters, Plücker rays, or learned embeddings"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-level reconstruction metric. Example: "PSNR"
- RANSAC: A robust estimator to find model-inlier sets under outliers in feature matches. Example: "count geometrically consistent inliers using RANSAC~\cite{fischler1981ransac}"
- Ref-DiT: A dedicated cross-attention module for conditioning on a reference video within a DiT backbone. Example: "introduces a dedicated Ref-DiT cross-attention module for reference-video conditioning."
- Reference-video conditioning: Supplying features from a source/reference video to guide generation. Example: "for reference-video conditioning."
- RoPE (Rotary Position Embedding): A positional encoding that encodes relative positions via complex rotations in attention. Example: "Rotary Position Embedding (RoPE)"
- Rotation Error (RotErr): A metric measuring rotational deviation of the generated camera trajectory from the target. Example: "Rotation Error (RotErr)"
- Sierpinski fractal triangle pattern: A self-similar, multi-scale triangular texture used as a robust camera-motion cue. Example: "a Sierpinski fractal triangle pattern"
- SIFT: Scale-Invariant Feature Transform, a local feature descriptor for matching across views. Example: "extract SIFT features"
- SpaTracker-V2: A method for computing sparse, reliable 3D point tracks across frames. Example: "SpaTracker-V2~\cite{xiao2025spatialtrackerv2}"
- Spherical coordinates: Angular/radial coordinates used to map points on a dome for texture sampling. Example: "converted to spherical coordinates and used to sample a 2D texture"
- Token concatenation: Combining source and target token sequences into one transformer input for joint attention. Example: "Our method also uses token concatenation, but makes it architecture-preserving and position-aware"
- Translation Error (TransErr): A metric measuring translational deviation of the generated camera trajectory from the target. Example: "Translation Error (TransErr)"
- VAE encoding: Encoding frames into a latent space using a Variational Autoencoder before tokenization. Example: "after VAE encoding and patchification"
- VBench: A benchmark suite for evaluating various aspects of visual quality in generated videos. Example: "we use VBench~\cite{huang2024vbench} for visual quality"
- VGGT: A method used to estimate camera poses for evaluating camera controllability. Example: "with metrics computed using camera poses estimated via VGGT~\cite{wang2025vggt}"
- Video diffusion models (VDMs): Diffusion models specialized for video generation and editing. Example: "video diffusion models (VDMs)~\cite{kong2024hunyuanvideo, yang2024cogvideox, wan2025wan}"
- Video retaking: Re-rendering an existing video from a new camera trajectory while preserving content and dynamics. Example: "dubbed video retaking"
- Validity mask: A binary mask indicating which warped pixels are valid when projecting source content to the target view. Example: "where is the forward-warp validity mask"
Collections
Sign up for free to add this paper to one or more collections.

