- The paper introduces a principled surrogacy framework grounded in surrogate endpoint theory to enable valid causal inference on human ATEs using LLM-generated outcomes.
- The methodology leverages multi-draw surrogacy to mitigate LLM stochasticity, demonstrating that increasing replication reduces bias and mean squared error.
- Practical diagnostics and empirical validations, including nonparametric calibration on headline A/B tests, underscore the necessity of human pilot studies.
Statistical Surrogacy Foundations for LLM-Based A/B Testing
Introduction
The use of LLMs as proxies for human participants in A/B testing has rapidly become both technically feasible and economically attractive. However, leveraging LLM outcomes for causal inference concerning human populations introduces substantial identification challenges. "Statistical Foundations of LLM-based A/B Testing: A Surrogacy Framework for Human Causal Inference" (2606.17165) develops a principled framework, grounded in surrogate endpoint theory, that rigorously specifies the assumptions, estimation strategy, and diagnostic procedures necessary for LLM-generated outcomes to support valid causal inference on human average treatment effects (ATEs).
The paper models experiments with randomized assignment W∈{0,1} (control/treatment), covariates X, and human outcome Y, with Y∗ denoting an outcome stochastically generated by an LLM, conditioned on (W,X). The LLM surrogate framework considers two samples:
- The experimental (human) sample, with both (W,X,Y∗,Y) observed;
- The artificial (LLM) sample, with only (W,X,Y∗) observed.
The fundamental question is: under what conditions can inference on the human ATE, τ=E[Y(1)−Y(0)], be carried out using only LLM data?
Identification Theory: Surrogacy and Comparability
Perfect distributional equivalence between LLM and human outcomes is too strong and rarely plausible. The paper hence introduces a surrogacy perspective, mirroring classical surrogate endpoint literature, and rigorously formalizes the conditions for point identification:
- Surrogacy (Prentice Criterion): Y⊥W∣X,Y∗ (i.e., conditional on covariates and the surrogate, treatment has no further effect on the human outcome);
- Comparability: The conditional distribution of Y given X0 is invariant across human and LLM samples, i.e., X1, where X2 indexes the sample.
Under these assumptions, the calibration function X3, learned on the human sample, enables unbiased estimation of the human ATE from the artificial sample via
X4
(Figure 1)
Figure 1: Sampling distribution of the calibrated ATE (blue) versus the raw LLM ATE (orange), illustrating removal of bias via calibration.
This reduction elucidates that distributional shifts in the relationship between the LLM surrogate and human outcome are absorbed by the nonparametric calibration, aligning LLM-based estimates with the estimand of interest.
Stochasticity and Multi-Draw Surrogacy
A key technical contribution is the explicit analysis of LLM stochasticity. Since LLM outputs are inherently noisy, single-draw surrogates introduce both variance inflation and, critically, attenuation bias in the calibrated estimator—a direct analog to classical measurement error.
To address this, the paper develops and proves multi-draw surrogacy theorems. When X5 independent LLM draws are averaged per unit, the surrogate approaches the latent conditional mean, restoring identification and attenuating estimator bias as X6. This yields an operational guideline: increasing replication count X7 both improves efficiency (reducing MSE as X8) and debiases ATE estimation. These findings are supported by extensive simulation.
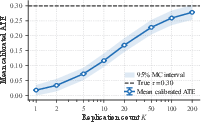
Figure 3: Averaging X9 LLM draws per unit asymptotically restores surrogacy when only the latent mean contains treatment signal.
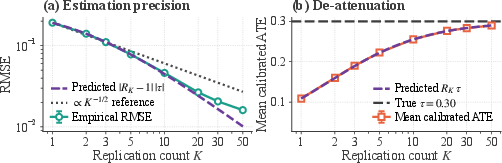
Figure 5: RMSE of the estimator drops as Y0 and mean estimate approaches the true ATE as Y1 increases, confirming variance reduction and debiasing.
Diagnostics: Falsification and Sensitivity Analysis
The framework distinguishes between empirical diagnostics that can falsify necessary assumptions and those that merely assess plausibility:
- Surrogacy Falsification Test: On held-out historical data, the fitted calibration function Y2 must recover per-arm means; significant residuals indicate failure.
- Comparability Sensitivity Bound: The worst-case impact of lack of distributional overlap between experimental and artificial samples is quantified by a tight bound (function of total variation distance and outcome range), providing robust assessment when identification fails.
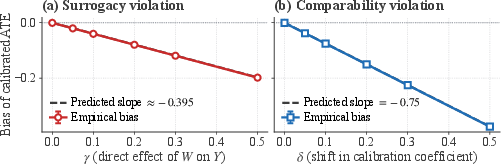
Figure 6: Bias of the calibrated ATE scales linearly with the violation magnitude of surrogacy (direct effect of Y3) and comparability (shift in calibration slope).
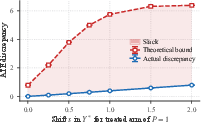
Figure 2: Theoretical worst-case bound holds strictly above observed ATE discrepancies under deliberate overlap violations.
Empirical Study: Upworthy Headline Experiments
The framework is validated on the Upworthy Research Archive [matias2021upworthy], consisting of thousands of live headline A/B tests.
Comprehensive diagnostics confirm absence of LLM memorization, robustness to shifting test populations, and validate recovery of synthetic treatment effects.
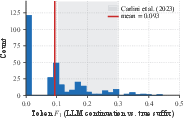
Figure 7: Token-level F1 assessment rules out LLM memorization of Upworthy headlines.
Practical Implications for Experimentation
The calibration-plus-surrogacy method subsumes LLM design (training regimen, prompt template, temperature) and replication count into the experimental workflow. The calibration function can and should be fit flexibly, but LLM stochasticity sets a lower bound on replication requirements for bias and variance. Diagnostics on historical data can only falsify surrogacy for past treatments, not verify it for novel ones—implying that human experimentation remains essential for new interventions. The work further discusses the trade-off in sizing human pilot studies versus purely LLM-based simulation based on risk and impact.
Conclusion
This work rigorously specifies when and how LLM-generated outcomes can be used for human causal inference in A/B testing. The statistical surrogacy formalism exposes the precise role of LLM calibration, the essential nature of surrogacy and comparability, and quantifies the implications of LLM stochasticity and finite draws. Importantly, the framework demonstrates that LLM-based causal inference is not a turnkey replacement for human experimentation: diagnostics can only falsify, not verify, key identification assumptions, making human experiments indispensable for genuinely novel treatment effects. Further directions include relaxing SUTVA, handling multiple outcomes/agents, and extending estimation to long-term surrogate settings.